В этой статье я хочу продемонстрировать несколько сценариев, которые здорово могут выручить вас в подобных ситуациях. Примеры я буду брать не самые сложные, но показательные, на основе которых можно построить что-то более хитрое.

Думаю, многим знакомы ситуации, когда нужно поменять формат дат в большом тексте, нормализовать отступы и пробелы в документе, подсчитать встречаемость слова в текстовом фрагменте; преобразовать xml-документ или ответ сервера в класс для десериализации, сконвертировать участок кода одного языка программирования в другой… Каждый поступает в подобных случаях по-разному: ищет соответствующие утилиты, пишет свои, а кто-то действует в лоб!
Самые отважные начинают осваивать регулярные выражения… А ещё более смелые пробуют подстановки. Да, порог вхождения у этих инструментов очень высокий, но эффективность при грамотном применении бьёт все рекорды!
Одним из факторов, тормозящих изучение языка регулярных выражений, я считаю некоторую недоработанность существующих в данной области программ и сред разработки.
Поэтому однажды я решил создать свой текстовый редактор с реджексами и подстановками.
Называется он Poet (сайт: poet.of.by), и именно с помощью него мы будем сегодня творить маленькие чудеса!
Подсчёт совпадений
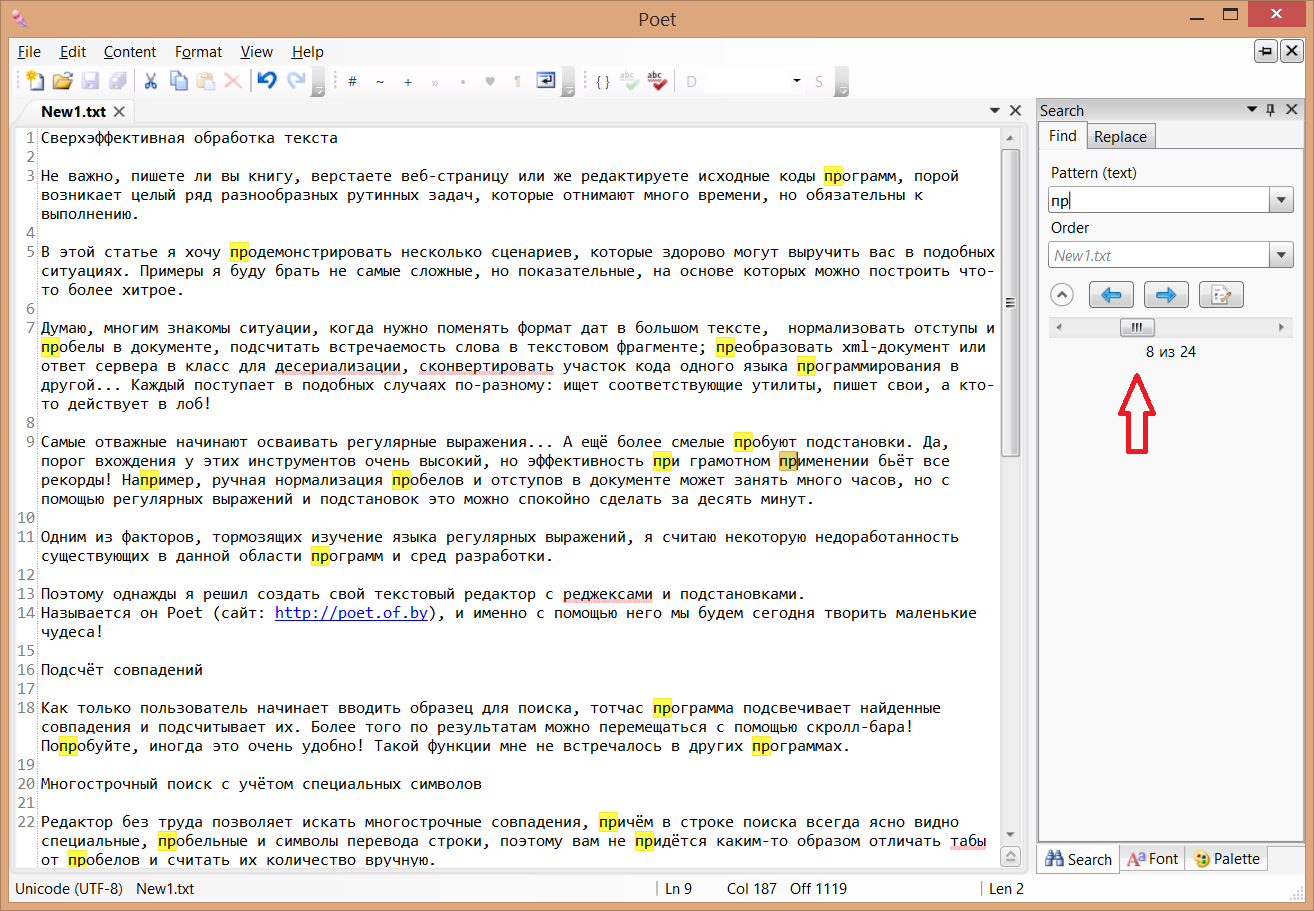
Как только пользователь начинает вводить образец для поиска, тотчас программа подсвечивает найденные совпадения и подсчитывает их. Более того по результатам можно перемещаться с помощью скролл-бара! Попробуйте, иногда это очень удобно! Такая функция мне не встречалось в других программах.
Многострочный поиск с учётом специальных символов
Редактор без труда позволяет искать многострочные совпадения, причём в строке поиска всегда ясно видно специальные, пробельные и символы перевода строки, поэтому вам не придётся каким-то образом отличать табы от пробелов и считать их количество вручную.

Преобразование дат
Включим использование регулярных выражений и подстановок.

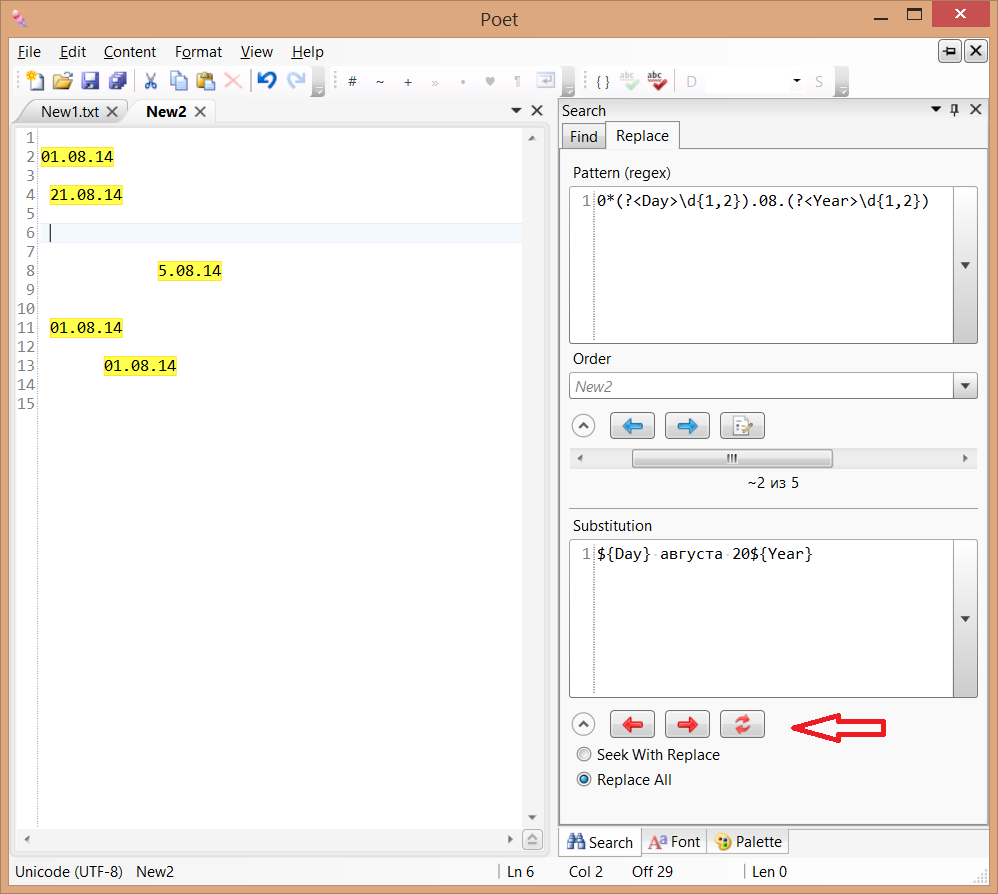
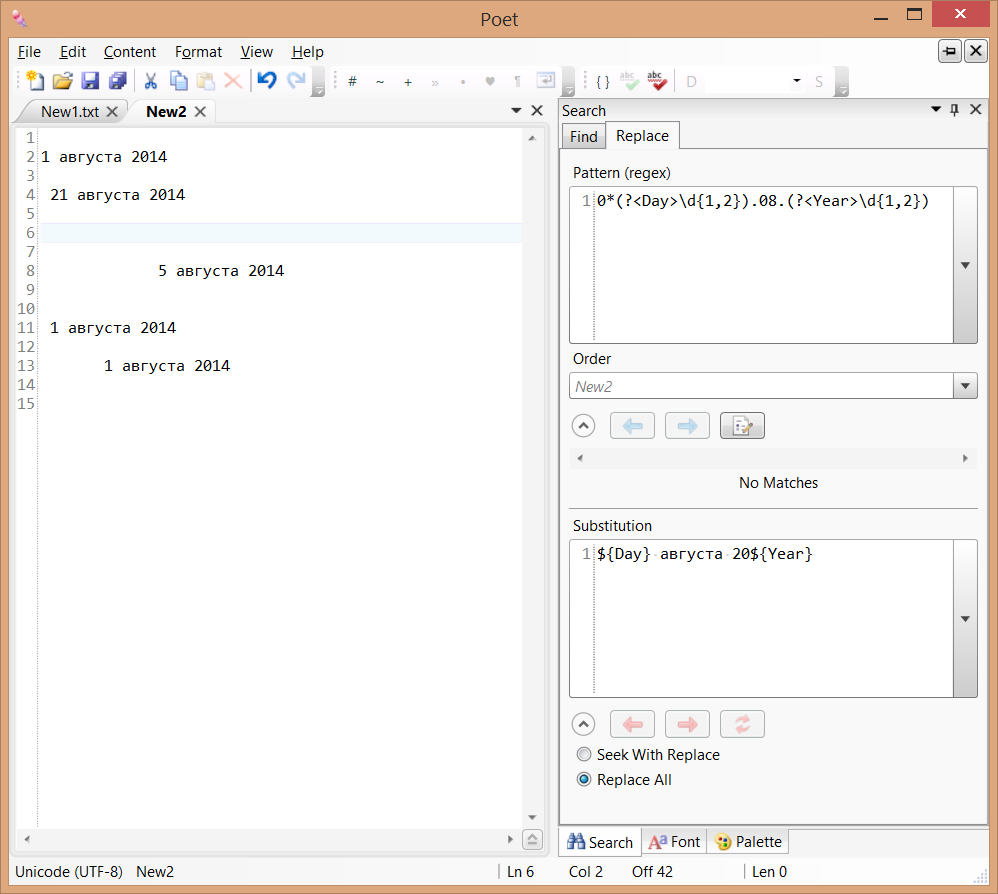
Если, к примеру, мы хотим привести в документе даты формата 01.08.14 к виду 1 августа 2014, то нам потребуется небольшое регулярное выражение и простая подстановка:
0*(?<Day>\d{1,2}).08.(?<Year>\d{1,2})
${Day} августа 20${Year}
Смена форматов
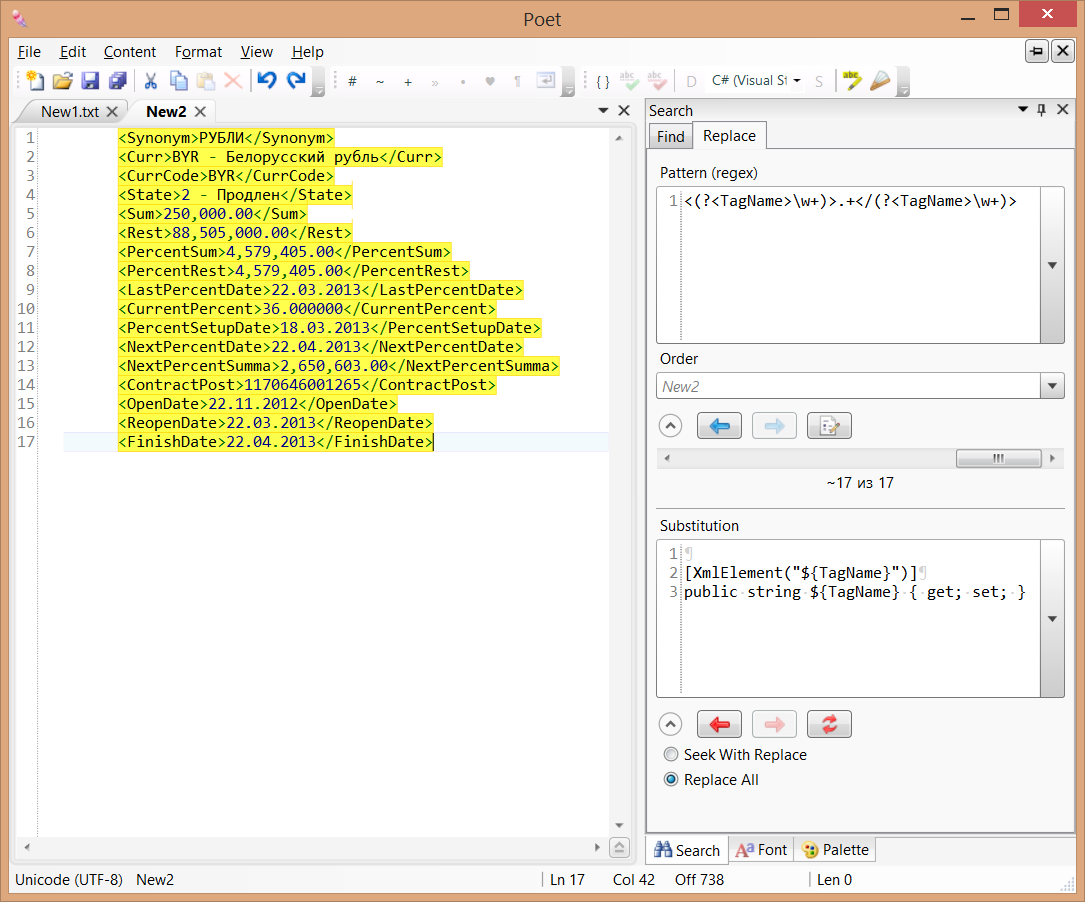
Как-то раз у меня возникла необходимость создавать C# классы по xml-ответу сервера.
<?xml version="1.0" encoding="UTF-8"?> <Result> <Deposit> <Synonym>РУБЛИ</Synonym> <Curr>BYR - Белорусский рубль</Curr> <CurrCode>BYR</CurrCode> <State>2 - Продлен</State> <Sum>250,000.00</Sum> <Rest>88,505,000.00</Rest> <PercentSum>4,579,405.00</PercentSum> <PercentRest>4,579,405.00</PercentRest> <LastPercentDate>22.03.2013</LastPercentDate> <CurrentPercent>36.000000</CurrentPercent> <PercentSetupDate>18.03.2013</PercentSetupDate> <NextPercentDate>22.04.2013</NextPercentDate> <NextPercentSumma>2,650,603.00</NextPercentSumma> <ContractPost>1170646001265</ContractPost> <OpenDate>22.11.2012</OpenDate> <ReopenDate>22.03.2013</ReopenDate> <FinishDate>22.04.2013</FinishDate> </Deposit> </Result> Это также делается довольно просто:
<(?<TagName>\w+)>.+</(?<TagName>\w+)>
[XmlElement("${TagName}")] public string ${TagName} { get; set; }

Сейчас моя основная задача — привлечь ваше внимание к применению регулярных выражений и подстановок а также дать почувствовать их мощь. Надеюсь, вас зацепила эта тема!
P.S. Элементы языка регулярных выражений, подстановки в регулярных выражениях.
ссылка на оригинал статьи http://habrahabr.ru/post/231929/
Добавить комментарий