Чтобы оценить целесообразность разработки системы для оптимизации поиска по логам, мы воспользовались вот этой таблицей с XKCD:
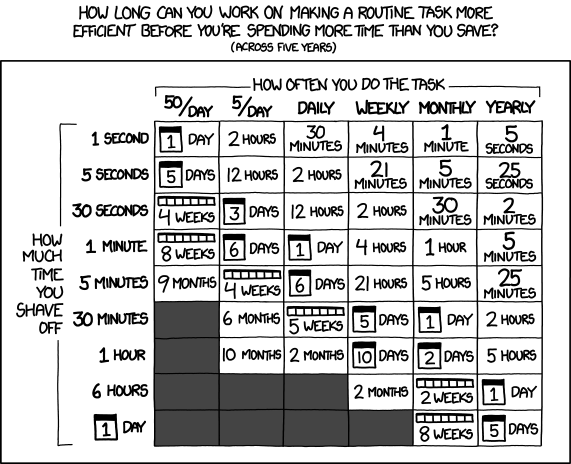
(на самом деле нет, но нам она все равно нравится).
Итак, мы всерьез взялись за оптимизацию. Итогом нашей работы стала разработка системы, благодаря которой мы можем поднять историю действий примерно в 100 000 (сто тысяч, это не опечатка) раз быстрее. Мы разработали big-data сервис, который позволяет хранить петабайты информации в структурированном виде: каждому ключу у нас соответствует лог каких-то событий. Хранилище устроено так, что оно способно работать и на самых дешевых SATA-дисках, и на больших многодисковых хранилищах с минимальным количеством процессорного времени, при этом оно полностью fault-толерантно — если вдруг какая-то машина выйдет из строя, это ни на что не влияет. Если в системе заканчивается место, в нее просто добавляется сервер или несколько: система автоматически увидит их и начнет записывать данные. Чтение данных происходит почти моментально.
В чем подвох?
Зачем это нужно? Допустим, у пользователя что-то не работает. Чтобы воспроизвести ошибку, нам нужно знать всю предысторию: куда человек заходил, на какие кнопки и ссылки кликал. Также логи бывают необходимы для принятия решений в таких случаях, как взлом аккаунта пользователя, когда важно разделить действия пользователя и злоумышленника.
Соответственно, на скорость поиска по логам «завязана» скорость ответа технической поддержки сервиса.
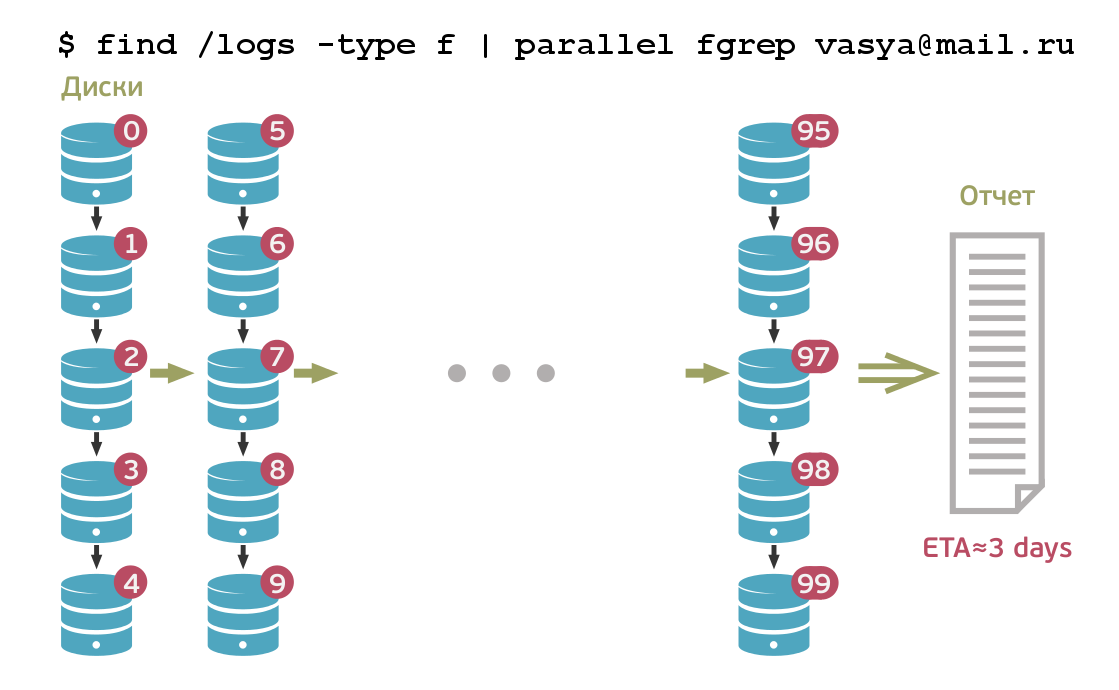
За рабочий день большой системы может накопиться несколько терабайт логов, особенно учитывая, что в нашей компании много «сложносочиненных» сервисов. Допустим, пользователь зашёл в почту, почта обратилась в базу данных, база — в систему хранения, та тоже записала логи… Чтобы понять, что делал пользователь, все эти данные нужно собрать в кучу. Для этого используется старая добрая команда grep, от которой пошло слово «грепать». Для решения проблемы одного пользователя мы грепаем, например, терабайт. Этот процесс может занимать несколько часов. Мы озаботились этой проблемой и стали думать, как обрабатывать эти данные гораздо быстрее.
Проблема в том, что полноценных отдельных систем для хранения и обработки логов, соответствующих нашим задачам, пока не существует. Например, Hadoop (как и любая другая реализация MapReduce) может параллельно грепать логи и собирать воедино результаты. Но, поскольку в Почте и Облаке Mail.Ru объём логов, которые нужно хранить, оценивается в петабайт, даже параллельная обработка такого объёма потребует большого количества времени. Кроме того, при грепе за сутки надо пройтись по нескольким терабайтам, а при грепе за неделю этот объем может вырасти и до десятка терабайт. Плюс, если нужно грепать по большому количеству разных логов, то для решения всего лишь одной проблемы может потребоваться греп нескольких десятков терабайт логов.
Жёсткие диски могут линейно записывать информацию со скоростью около 100 Мбит/сек. Однако быстрая запись подразумевает неструктурированность, неоптимальность размещения информации. А для быстрого чтения файлов необходимо, чтобы они были определённым образом структурированы. Нам же требовалось обеспечить высокую скорость обоих процессов. В логах постоянно сохраняется большой объем информации, при этом нам нужно быстро собирать статистику по конкретному пользователю, чтобы оперативно решать возникающие у него проблемы, обеспечивая качественную техническую поддержку.
Можно было бы пойти по самому простому пути, организовав хранение логов в базе данных. Но это очень и очень дорогое решение, поскольку оно требует использования SSD-дисков, шардирования БД, создания реплик. Мы же хотели найти решение, которое позволило бы нам работать с максимально дешёвым хранилищем на медленных дисках огромного объёма.
С учетом всех этих факторов было решено с нуля написать систему, позволяющую ускорить процесс грепания. Кстати, насколько мы знаем, аналогов у нее нет не только в России, но и в мире.
Как мы это сделали?
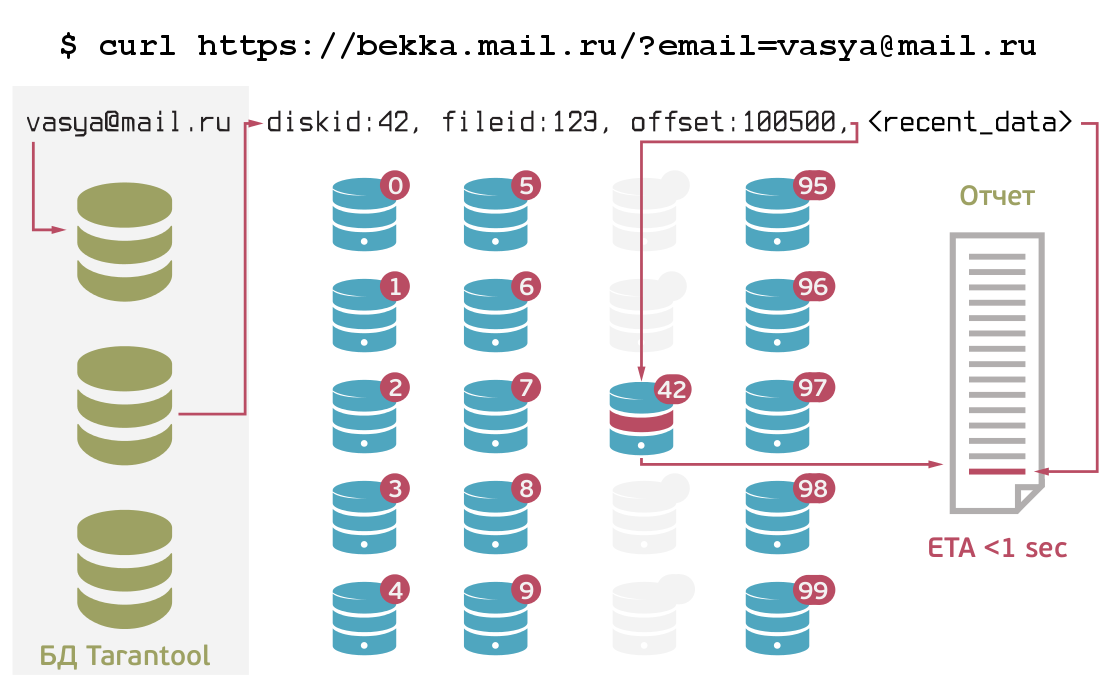
Система, которую мы для этого создали, устроена следующим образом. С точки зрения программиста она выполняет, по сути, две операции: создание записи по конкретному пользователю (ID и время) и получение всей истории по конкретному пользователю.
Запись осуществляется в нашу БД Tarantool. В ней вся информация всегда сохраняется в один файл, а чтение осуществляется из памяти. База шардирована на несколько инстансов. Сами логи хранятся на многодисковых серверах. Поскольку Tarantool всё хранит и в памяти, и на диске, понятно, что бесконечно это продолжаться не может. Поэтому периодически запускается процесс, который группирует по пользователям данные из Tarantool и записывает их в файлы на серверах, а в БД ставит ссылку на эти данные.
Таким образом, в Tarantool хранится лишь недавняя история по пользователям (соответственно, ее можно быстро извлечь). А «старые» данные складируются на дисках в одном большом файле, хорошо структурированном и пригодном для быстрого чтения. Благодаря этому всю историю по любому пользователю можно получить за считанные секунды. Для сравнения: до этого грепание недельного периода по одному пользователю занимало около трёх дней.
На каждом диске хранится несколько файлов, в которые подряд записывается вся информация по разным пользователям. Чтобы Tarantool не переполнялся, делается следующее: процесс, который последовательно читает все эти файлы, берёт информацию о пользователе из файла целиком, добавляет к нему то, что есть в Tarantool, и записывает всё это опять в конец файла. Вся эта система ещё и шардирована и реплицирована, то есть серверов может быть сколько угодно, потому что каждый раз, когда мы перезаписываем заново историю пользователя, мы записываем её всегда на два диска, которые выбираются произвольно. После успешной парной записи ссылка сохраняется в Tarantool. Таким образом, если даже один из серверов упадет, то информация не пропадает. При добавлении нового сервера он прописывается в конфигурацию системы, после чего на него автоматически начинаются сохраняться новые данные.
Сейчас эта система используется в Почте и Облаке Mail.Ru. В ближайшее время мы планируем внедрить её в «Mail.Ru для бизнеса», а потом постепенно и на остальных проектах.
Как это работает?
Мы осуществляем поиск по логам в двух типах случаев. Во-первых, для решения технических проблем. Например, пользователь жалуется на то, что у него что-то не работает, и нам нужно быстро посмотреть всю историю его действий: что он делал, куда заходил и так далее. Во-вторых, если у нас возникает подозрение, что произошел взлом ящика. Как я уже говорил выше, в этом случае история нужна для того, чтобы разделить действия пользователя на его собственные и совершенные злоумышленником.
Приведу несколько примеров того, насколько эффективна созданная нами система.
Довольно частый кейс: пользователь жалуется на пропажу писем из почтового ящика. Мы поднимаем историю и смотрим, когда и из каких программ он их удалял. Допустим, мы видим, что письма были удалены с такого-то IP-адреса через POP3, из чего делаем вывод, что пользователь подключил себе POP3-клиент и выбрал опцию «Скачать все письма и удалить их с сервера» — то есть на самом деле письма были удалены пользователем, а не «пропали сами». Благодаря нашей систематизированной системе хранения логов мы можем установить этот факт и продемонстрировать его пользователю в считанные секунды. Экономия времени админов и саппорта – гигантская.
Другой пример: мы получаем жалобу от пользователя, который не может открыть письмо. Подняв все логи по этому пользователю, мы можем буквально в течение нескольких секунд посмотреть, когда и какие серверные вызовы делались, какими юзер-агентами, что происходило со стороны клиента. Благодаря этому мы можем легче и, главное, гораздо быстрее установить, в чем же проблема.
Еще случай — пользователь жалуется на то, что не может войти в почтовый ящик. Мы начинаем искать причину — выясняется, что аккаунт был автоматически заблокирован за рассылку спама. Тут нужно разобраться, кто именно спамил – сам пользователь или кто-то другой от его имени, а для этого придется проанализировать всю историю использования ящика за длительный период (возможно, неделю, месяц или даже больше). Заглянув в историю, мы видим, что, начиная с определённой даты, в его ящик заходили из подозрительного (т.е. «неродного» для пользователя) региона. Очевидно, что его просто взломали. Причём сбор данных и анализ занял не сутки, а несколько секунд: сотрудник техподдержки просто нажал на кнопку и получил исчерпывающую информацию. Пользователь поменял пароль от ящика и снова получил к нему доступ.
Одним словом, наша система ежедневно экономит нам кучу времени, при этом позволяя сократить время ответа пользователю – по-моему, это win. О других способах ее применения мы расскажем в следующих постах.
ссылка на оригинал статьи http://habrahabr.ru/company/mailru/blog/238569/
Добавить комментарий