В комментариях к прошлому посту был поднят весьма важный вопрос – а будет ли вообще выигрыш в производительности от выгрузки вычислений на интегрированную графику, по сравнению с выполнением только на CPU? Конечно, он будет, но нужно соблюдать определенные правила программирования для эффективных вычислений на GFX+CPU.
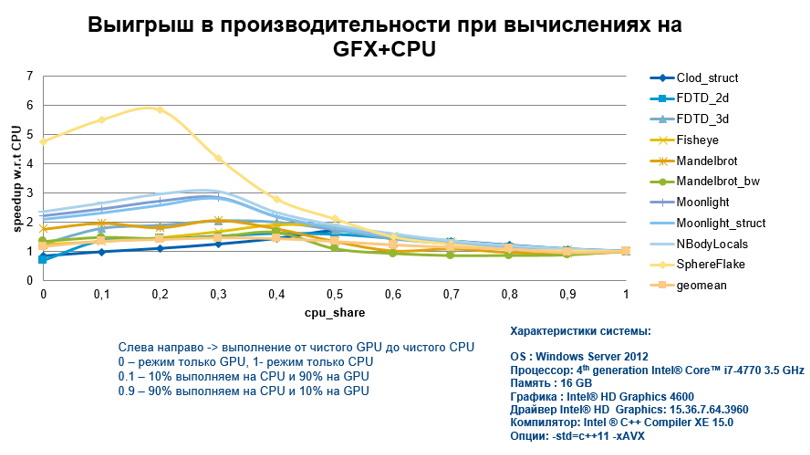
В подтверждение моих слов, сразу представлю график ускорения, получаемого при выполнении вычислений на интегрированной графике, для различных алгоритмов и с разной долей вовлеченности CPU. На КДПВ мы видим, что выигрыш более чем весомый.
Многие скажут, что тут вообще непонятно, что это за алгоритмы и что там с этим кодом делали, чтобы получить такие результаты.
Поэтому рассмотрим, как добиться таких впечатляющих результатов для эффективного выполнения на GFX.
Для начала, попробуем собрать все особенности и способы вместе, учитывая наши знания о специфике самой железки, а затем перейдем к реализации на конкретном примере с помощью Intel Graphics Technology. Итак, что делать, чтобы получить высокую производительность:
- Увеличиваем итерационное пространство за счет использования вложенных cilk_for. В результате имеем больший ресурс для параллелизма и большее количество потоков на GPU может быть занято.
- Для векторизации кода (да, для GPU она так же очень важна, как и для CPU), который будет оффлоадиться, используем директиву pragma simd или нотацию массива Intel®Cilk™ Plus.
- Используем ключевое слово __restrict__ и __assume_aligned() для того, чтобы компилятор не создавал различные версии кода (code paths). Например, он может генерировать две версии для работы с выровненной и не выравненной памятью, что будет проверяться в рантайме и исполнение пойдёт по нужной «ветке».
- Не забываем, что pin в директиве pragma offload позволяет избегать оверхеда от копирования данных между DRAM и памятью карты и позволяет использовать общую память для CPU и GPU.
- Отдаем предпочтение работе с 4-байтными элементами, чем 1- или 2-байтными, потому что операции gather/scatter с таким размером намного эффективнее. Для случая с 1,2 байтами они намного медленнее.
- Ещё лучше – это избегать gather/scatter инструкций. Для этого, используем структуру данных SoA (Structure of Arrays) вместо AoS (Array of Structures). Здесь всё предельно просто – данные лучше хранить в массивах, тогда доступ к памяти будет последовательным и эффективным.
- Одна из наиболее сильных сторон GFX – это свои 4 KB регистрового файла у каждого потока. Если локальные переменные будут превышать этот размер – придется работать с гораздо более медленной памятью.
- При работе с массивом int buf[2048], выделенного в регистровом файле (GRF), в цикле вида for(i=0,2048) {… buf[i] … } будет осуществляться индексированный доступ к регистру. Для того, чтобы работать с прямой адресацией, делаем развертку цикла (loop unrolling) с помощью директивы pragma unroll.
Теперь давайте посмотрим как всё это работает. Не стал брать самый простой пример умножения матриц, а немного его модифицировал, используя нотацию массива Cilk Plus для векторизации, и оптимизацию сache blocking.
Решил честно изменять код и смотреть, как меняется производительность.
void matmul_tiled(float A[][K], float B[][N], float C[][N]) { for (int m = 0; m < M; m += TILE_M) { // iterate tile rows in the result matrix for (int n = 0; n < N; n += TILE_N) { // iterate tile columns in the result matrix // (c) Allocate current tiles for each matrix: float atile[TILE_M][TILE_K], btile[TILE_N], ctile[TILE_M][TILE_N]; ctile[:][:] = 0.0; // initialize result tile for (int k = 0; k < K; k += TILE_K) { // calculate 'dot product' of the tiles atile[:][:] = A[m:TILE_M][k:TILE_K]; // cache atile in registers; for (int tk = 0; tk < TILE_K; tk++) { // multiply the tiles btile[:] = B[k + tk][n:TILE_N]; // cache a row of matrix B tile for (int tm = 0; tm < TILE_M; tm++) { // do the multiply-add ctile[tm][:] += atile[tm][tk] * btile[:]; } } } C[m:TILE_M][n:TILE_N] = ctile[:][:]; // write the calculated tile to back memory } } } Плюсы подобного алгоритма с блочной работой с матрицами понятен — мы пытаемся избежать проблемы с кэшем, и для этого изменяем размеры TILE_N, TILE_M и TILE_K. Собрав этот пример компилятором Intel c оптимизацией и размерами матриц M и K равными 2048, а N — 4096, запускаю приложение. Время просчета составляет 5.12 секунд. В этом случае мы использовали только векторизацию средствами Cilk’а (причем, набор SSE инструкций по дефолту). Нам нужно реализовать и параллелизм по задачам. Для этого можно воспользоваться cilk_for:
cilk_for(int m = 0; m < M; m += TILE_M) ... Пересобираем код и снова запускаем на выполнение. Ожидаемо, получаем почти линейное ускорение. На моей системе с 2 ядерным процессором, время составило 2.689 секунд. Пришло время задействовать оффлоад на графику и посмотреть, что мы можем выиграть в производительности. Итак, используя директиву pragma offload и добавляя вложенный цикл cilk_for, получаем:
#pragma offload target(gfx) pin(A:length(M)) pin(B:length(K)) pin(C:length(M)) cilk_for(int m = 0; m < M; m += TILE_M) { cilk_for(int n = 0; n < N; n += TILE_N) { ... Приложение с оффлоадом выполнялось 0.439 секунды, что весьма неплохо. В моем случае, дополнительные модификации с unroll’ингом циклов не показали серьёзного прироста в производительности. А вот ключевую роль сыграл алгоритм работы с матрицами. Размеры TILE_M и TILE_K были выбраны равными 16, а TILE_N — 32. Таким образом sizeof(atile) составил 1 KB, sizeof(btile) — 128 B, а sizeof(ctile) — 2 KB. Я думаю, понятно, к чему я всё это сделал. Правильно, общий размер 1 KB + 2 KB + 128 B оказался меньше 4 KB, а значит мы работали с самой быстрой памятью (регистровом файлом), доступной каждому потоку на GFX.
Кстати, обычный алгоритм работал намного дольше (порядка 1.6 секунд).
Ради эксперимента, я включил генерацию AVX инструкций и ещё несколько ускорил выполнение только на CPU до 4.098 секунд, а версии с Cilk’ом по задачам — до 1.784. Тем не менее, именно оффлоад на GFX позволил существенно увеличить производительность.
Я не поленился, и решил посмотреть, что может отпрофилировать VTune Amplfier XE в подобном приложении.
Собрал код с дебаг информацией и запустил Basic Hotspot анализ с галочкой ‘Analyze GPU usage’:

Интересно, что для OpenCL там есть отдельная опция. Собрав профиль и полазив по вкладкам Vtune’а, нашёл такую информацию:
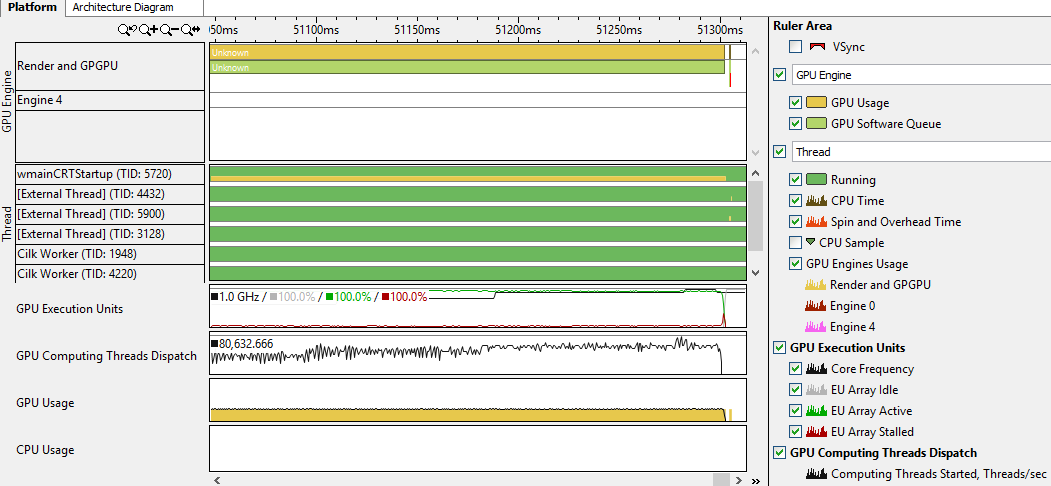
Сказать, что я почерпнул из этого много полезного я не могу. Тем не менее, увидел, что приложение использует GPU, и даже заметил на временной шкале момент, когда начался оффлоад. Кроме этого, есть возможность определить, насколько эффективно (в процентах) были использованы все ядра на графике (GPU EU) по времени, да и в целом оценить использование GPU. Думаю, что при необходимости стоит покопаться здесь подольше, особенно если код был написан не вами. Коллеги заверили, что всё-таки можно найти много полезного с помощью VTune при работе с GPU.
В итоге стоит сказать, что выигрыш от использования оффлоада на интегрированную в процессор графику есть, и он весьма существенен, при соблюдении определенных требований к коду, о которых мы и поговорили.
ссылка на оригинал статьи http://habrahabr.ru/post/253425/
Добавить комментарий