В практике java программиста бывает, что очень хочется изменить поведение программы или «подхачить» пару классов без перепаковки приложения, собрать метрики или протестировать java приложение в недрах сторонней библиотеки или jdbc драйвера без исходного кода. Существует несколько способов сделать это. Я расскажу про open source проект aspectj-scripting, который позволяет решать такие задачи в jvm.

Рассказ про aspectj-scripting будет в нескольких публикациях. Начнем с практики! Под катом модификация поведения maven-changes-plugin без его пересборки и перекомпиляции для выгрузки списка задач из JIRA в файлы xml и json
Но прежде чем рваться в бой, предполагаю вы в общих чертах знакомы с теорией аспектно-ориентированного программирования, работали с библиотекой AspectJ или другими AOP фреймворками. Интересно ваше мнение в комментариях, насколько верно мое предположение и стоит ли мне подробнее описать базовые вещи в следующих публикациях.
Важное примечание: Aspectj-scripting в текущем виде не будет работать под JEE или OSGI контейнерами. Но при этом микросервисы и standalone java приложения отлично уживаются и работают с его агентом.
Aspectj-scripting — это инструментирующий java агент на основе AspectJ Load-time weaving(LTW) который позволяет описывать аспекты на скриптовом языке MVEL, загружать и инстанцировать классы из maven репозитариев в рантайме, использовать синтаксис AspectJ для описания pointcut и поддерживает life cycle для скриптовых аспектов.
Теперь пару слов про деталь для обработки напильником. Одна из удобных функций maven-changes-plugin — генерация отчета о новых фичах в релизе, исправленных ошибках на основе информации из JIRA, github или track.
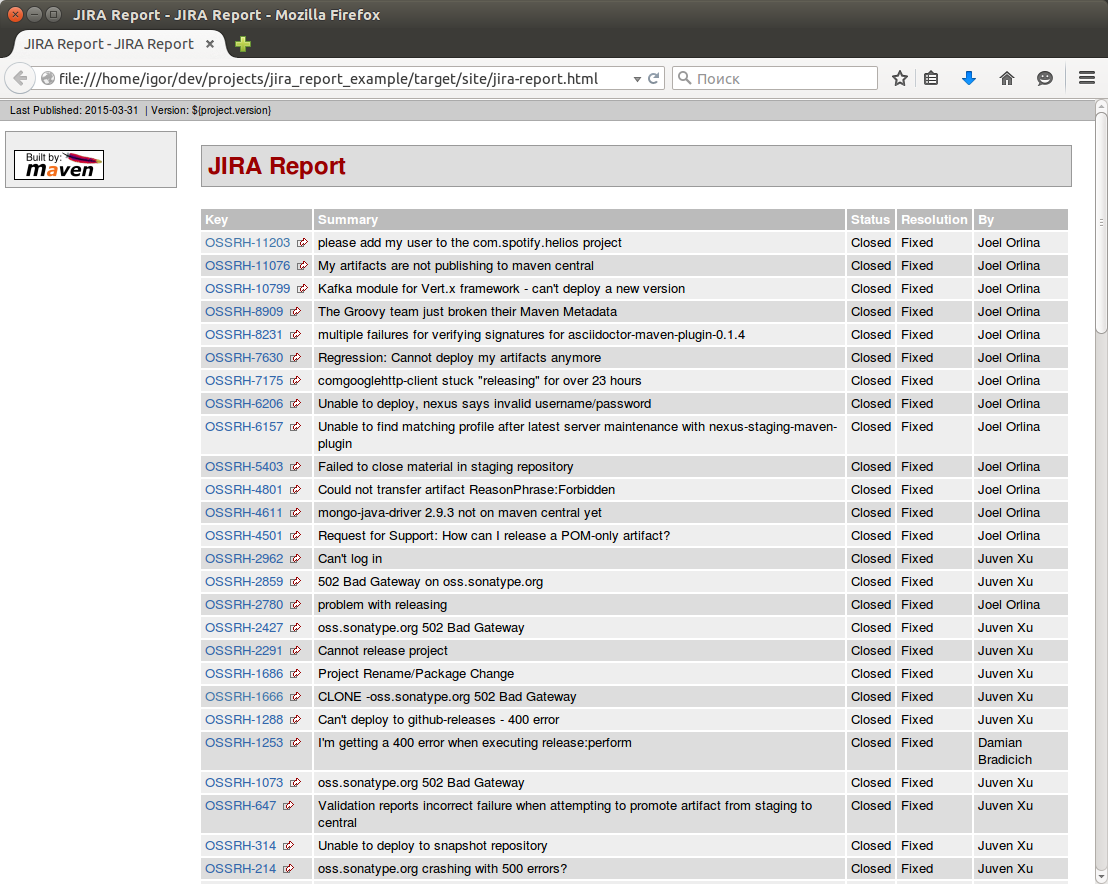
И все бы устраивало в maven-changes-plugin, если бы этот плагин сохранял не только html отчет, но и исходные данные из которых он его стоит. На основе этих данных из JIRA и логах системы контроля версий для конкретного бранча можно сделать отличные release notes. Избежать ручной работы и не бояться что что-либо ускользнуло при составлении отчета только на основе JIRA.
Изучение кода плагина показало, что раньше, до использования REST сервисов JIRA была возможность генерации такого файла в формате XML. Но в версии 2.11 для REST и jql запросов такой возможности нет. Но при этом из метода org.apache.maven.plugin.jira.AbstractJiraDownloader.getIssueList() возвращается список задач и было бы отлично его сериализовать и сохранить в файл.
Сказано — сделано! Пишем конфигурацию для агента в файле aspect.xml. А после описания процесса расскажу это работает.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <configuration> <aspects> <name>org.maven.plugin.changes.Dump</name> <type>AROUND</type> <pointcut>execution(* org.apache.maven.plugin.jira.AbstractJiraDownloader.getIssueList(..))</pointcut> <artifacts> <artifact>com.google.code.gson:gson:2.3.1</artifact> <classRefs> <variable>GsonBuilder</variable> <className>com.google.gson.GsonBuilder</className> </classRefs> </artifacts> <artifacts> <artifact>com.thoughtworks.xstream:xstream:1.4.8</artifact> <classRefs> <variable>XStream</variable> <className>com.thoughtworks.xstream.XStream</className> </classRefs> </artifacts> <artifacts> <artifact>commons-io:commons-io:2.4</artifact> <classRefs> <variable>FileUtils</variable> <className>org.apache.commons.io.FileUtils</className> </classRefs> </artifacts> <process> <expression> import java.io.File; res = joinPoint.proceed(); gson = new GsonBuilder().setPrettyPrinting().create(); FileUtils.writeStringToFile(new File("report.json"), gson.toJson(res)); xstream = new XStream(); xstream.alias("issue", org.apache.maven.plugin.issues.Issue); FileUtils.writeStringToFile(new File("report.xml"), xstream.toXML(res)); res; </expression> </process> </aspects> </configuration> Для предпочитающих json есть возможность описывать конфигурацию в этом формате. Мне же удобнее многострочные описания аспектов делать в xml.
Скачиваем aspectj-scripting-1.0-agent.jar в директорию, где лежит наш pom.xml файл
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.github.igor_suhorukov</groupId> <artifactId>jira_report_example</artifactId> <packaging>jar</packaging> <version>1.0-SNAPSHOT</version> <issueManagement> <system>jira</system> <url>https://issues.sonatype.org/browse/OSSRH</url> </issueManagement> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-changes-plugin</artifactId> <version>2.11</version> <configuration> <useJql>true</useJql> <jiraUser>***РЕАЛЬНЫЙ ЛОГИН***</jiraUser> <jiraPassword>***И ПАРОЛЬ***</jiraPassword> </configuration> </plugin> </plugins> </build> </project> Выставляю в консоле переменную окружения для maven, чтобы загружался aspectj-scripting агент в jvm и использовал конфигурацию из aspect.xml
export MAVEN_OPTS="-Dorg.aspectj.weaver.loadtime.configuration=config:file:aspect.xml -javaagent:aspectj-scripting-1.0-agent.jar" После этого запускаю maven плагин
mvn changes:jira-report И в той же директории после BUILD SUCCESS уже находятся два файла со списком задач из JIRA: report.json, report.xml
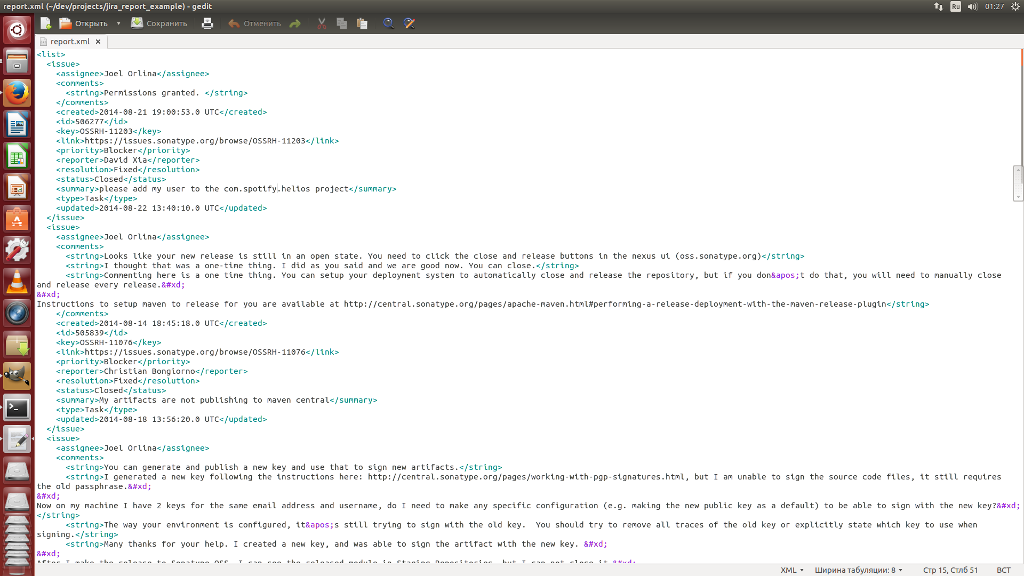
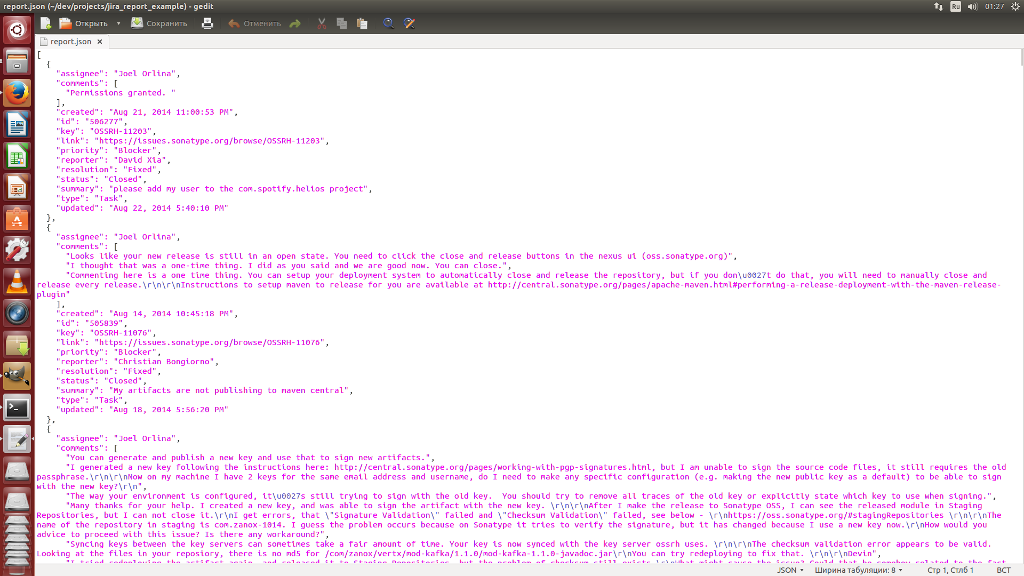
Итак, как это получилилось. В первую очередь org.maven.plugin.changes.Dump будет вызываться как around аспект при вызове метода getIssueList(), указанного в pointcut аспекта.
<type>AROUND</type> <pointcut>execution(* org.apache.maven.plugin.jira.AbstractJiraDownloader.getIssueList(..))</pointcut> С помощью библиотеки Sonatype Aether из центрального maven репозитария будут скачаны 3 артефакта и их транзитивные зависимости com.google.code.gson, com.thoughtworks.xstream, commons-io. Для каждого артефакта с помощью библиотеки dropship будет создан свой изолированный classloader.
<artifacts> <artifact>com.google.code.gson:gson:2.3.1</artifact> <classRefs> <variable>GsonBuilder</variable> <className>com.google.gson.GsonBuilder</className> </classRefs> </artifacts> <artifacts> <artifact>com.thoughtworks.xstream:xstream:1.4.8</artifact> <classRefs> <variable>XStream</variable> <className>com.thoughtworks.xstream.XStream</className> </classRefs> </artifacts> <artifacts> Из класслоудеров загружаются классы и сохраняются в переменные GsonBuilder, XStream и FileUtils. Эти переменные доступны в MVEL скрипте, синтаксис которого сильно напоминает java. Скрипт позволяет манипулировать этими классами и сериализовать результат метода getIssueList() в XML и JSON формат, записать результаты в файлы.
res = joinPoint.proceed(); // это результат работы перехватываемого метода org.apache.maven.plugin.jira.AbstractJiraDownloader.getIssueList() //тип List<org.apache.maven.plugin.issues.Issue> gson = new GsonBuilder().setPrettyPrinting().create(); //инстанцируем класс для работы с json FileUtils.writeStringToFile(new File("report.json"), gson.toJson(res)); //преобразуем список pojo в json и сохраняем с помощью commons-io в файл report.json xstream = new XStream(); //инстанцируем класс для работы с xml xstream.alias("issue", org.apache.maven.plugin.issues.Issue); //конфигурируем его FileUtils.writeStringToFile(new File("report.xml"), xstream.toXML(res)); //преобразуем список pojo в xml и сохраняем с помощью commons-io в файл report.xml res; //возвращаем вызвавшему методу результат из getIssueList() Агент доступен как артефакт в центральном maven репозитарии
Указываем jvm на java агент при старте и его конфигурацию. Конфигурация может загружаться с http сервера или файла. Агент скачивает зависимости из maven репозитария, инструментирует код и перехватывает вызов метода из плагина, сохраняет список задач из JIRA в json и xml формате. Вот и вся магия!
Надеюсь, что aspectj-scripting будет полезен для ваших проектов!
ссылка на оригинал статьи http://habrahabr.ru/post/254571/
Добавить комментарий