Вы еще не сохраняете десятки миллионов событий в день? К вам еще не забегают менеджеры с кричащим вопросом — когда твой дорогущий кластер на «надцати» машинах посчитает агрегированную статистику по продажам за неделю (а в глазах читается: «чувак, ребята на php/python/ruby/go решают задачу за час, а ты со своей Бигдатой тянешь время днями, доколе?»)? Вы еще не вскидываетесь ночью в холодном поту от кошмара: «разверзлось небо и на вас, ваших коллег и весь нафиг город вывалилось огромная куча… Бигдаты и никто не знает, что с этим всем теперь делать»? 🙂
Есть еще интересный симптом — в компании скапливается много-много логов и кто-то, по фамилии, отдаленно звучащей как «Сусанин», говорит: «коллеги, а в логах на самом деле сокрыто золото, там есть информация о путях пользователей, о транзакциях, о группах, о поисковых запросах — а давайте это золото начать извлекать»? И вы превращаетесь в «извлекателя» добра из терабайт (и их десятков) информационного водопада под мотивирующие советы: «а разве нельзя в потоке получать ценную для бизнеса информацию, зачем гонять часами кластера?».
Если это не о вас, тогда и не заходите под кат, ибо там — треш и жесткий технологический трепет…
Зря вы зашли под кат. Но мужчины — не отступают и бьются до конца. На самом деле, цель поста: сориентировать читателя и сформировать ему минимальный и эффективный «армейский паек» знаний и умений, которые пригодятся на самом сложном начальном этапе внедрения Бигдаты в компании.
Итак, разминка.
Что знает и чего еще не знает разработчик

Говоря «по чесноку» мы, разработчики, бываем двух видов (я вижу, что пунктов ниже три):
- с математическим образованием
- с техническим образованием
- гуманитарии
В ВУЗе обычно (не все, конечно, говорю за себя) мы боремся с гормональным взрывом, знакомимся с красивыми девушками, спим на парах, кодим ночью что хотим, учимся перед сессией и в конце концов запоминаем список книг, куда нужно если что — глянуть. И еще в ВУЗе мы можем встретить преподавателей или коллег, которые своей энергией, отношением к делу, стремлением к компетенции и жизненной позицией могут стать нашими ориентирами на всю жизнь и подогревать нас и мотивировать в различных обстоятельствах (ну вот, снова довел себя до слез).
Если после ВУЗа системно тратить по паре часов в день на теорию в метро (автобусе, маршрутке) и по 8 часов на практику «проектирования и создания программного обеспечения» и прочитать минимально необходимые для общей грамотности книжечки, то вы выдохните с чувством выполненного долга лет в 40, а если еще и спать ночами — то лет в 50. Вот что я имею в виду:
— взрослые языки программирования на уровне спецификаций (C++, java, C#)
— пару популярных языков типа PHP, Python, Go
— понять и… простить все нормальные и «ненормальные» формы SQL
— книжечки по шаблонам проектирования (GoF, Fauler и др)
— книжечки в стиле «Эффективный …»
— понять, как работает unix — изнутри
— понять сетевые протоколы на уровне RFC (чем отличается TCP от IP знают еще не все)
— как работает… компьютер! спускаясь до операционки и ее системных вызовов, проходя мультипроцессорные системы с их кэшами и мьютексами и спинлоками и до уровня микросхем
— провалить 10 программных проектов на ООП
— удалить код и единственный экземпляр бэкапа данных в пятницу вечером (говорят раза 3 нужно это сделать, чтобы наработать мозоль в мозгу)
Коллеги, это только то, что касается «проектировать ПО и писать хороший код».
А математика для разработчика — это отдельный мир. Дело в том, что, чтобы хорошенько понять рассматриваемые ниже алгоритмы и подстраивать их под нужды компании — нужно, как бы помягче сказать, неплохо разбираться в следующих областях математики:
— теория вероятностей с поддтанцовками в виде моделей Маркова (иначе PageRank не поймете как работает, не поймете байесовскую фильтрацию, не поймете кластеризацию LSH)
— комбинаторика, без которой сложно понять теорию вероятностей
— теория множеств (чтобы понять теорию вероятностей, и хотя бы чтобы понять Jaccard-расстояние в коллаборативке, но встречается повсеместно)
— линейная алгебра (коллаборативная фильтрация, сжатие размерностей, матрицы co-occurence, eigenvectors/values — это не векторы, придуманные Евгением!!)
— математическая статистика (даже не знаю где в Бигдате ее нет)
— машинное обучение (тут математический трэш и ад, начиная с примитивных перцептронов, продолжая «stochastic gradient descent» и не заканчивая нейронными сетями)
А если вам повезет столкнуться с кластеризацией данных (сгруппируй похожих Покупателей, Товары и т.п.), то:
— для понимания старого и доброго k-means в евклидовых пространствах ничего не потребуется, кроме того, что он не работает без лома и грубой силы на «больших данных» 🙂
— для понимания c-means в неевклидовых пространствах, возможно потребуется дополнительная чашечка кофе (хотя он тоже не работает с большими данными)
— а вот для понимания популярной сейчас спектральной кластеризации (тут я сознательно упростил и даже чуть извратил «power iteration clustering»), при которой мы перемещаем данные из одного пространства в другое (т.е. нужно кластеризовать рога, а вы кластеризуете копыта и получается даже ничего), вы скорее всего выпрыгнете в окошко с бесполезным томиком «Алгоритмы на C++» Седжвика 🙂
Ну да, конечно можно и не разбираться и скопипастить. Но если вам придется адаптировать и смешивать алгоритмы под свои нужды — фундаментальные знания, безусловно, нужны и тут лучше всего наверно работать совместной командой, у участников которой достаточно знаний чтобы понимать, куда идти.
Нужен аналитик?
И вы спросите — а нужен проекту математик, который живет математикой, спит с математикой и наизусть помнит доказательство теоремы Пифагора 20 способами и с постером «Бином Ньютона» над ложем — для понимания и организации процесса работы с Бигдатой? А он хороший код писать умеет — быстро, в релиз? А он не будет зависать перед монитором на 15 минут с гримасой ужасного страдания, созерцая быстро сделанный объектно-дизориентированный алогичный, но сексуальный хак? Ответ на этот вопрос мы знаем — ибо невозможно (кроме гениев и джедаев) одинаково хорошо преуспеть в служении светлой и темной сторонам.

Видимо поэтому умные от природы дяденьки и тетеньки усердно занимаются Computer Science и пишут только им понятные, написанные языком формул статьи, а трудолюбивые от природы разработчики лишь успевают поцеловать перед сном так и не открытый, но стоящий на самом видном месте дома многотомник Кнута 🙂
Ну конечно бывают и исключения! А еще говорят, что люди иногда самовозгараются и он них остается кучка пепла.
Алгоритмы
Итак, коллеги, перечислим, с чем вам придется столкнуться в первых боях с Бигдатой.
Коллаборативная фильтрация
Алгоритмы это области сначала кажутся очень очень простыми и хорошо «идут под водочку с огурчиками».
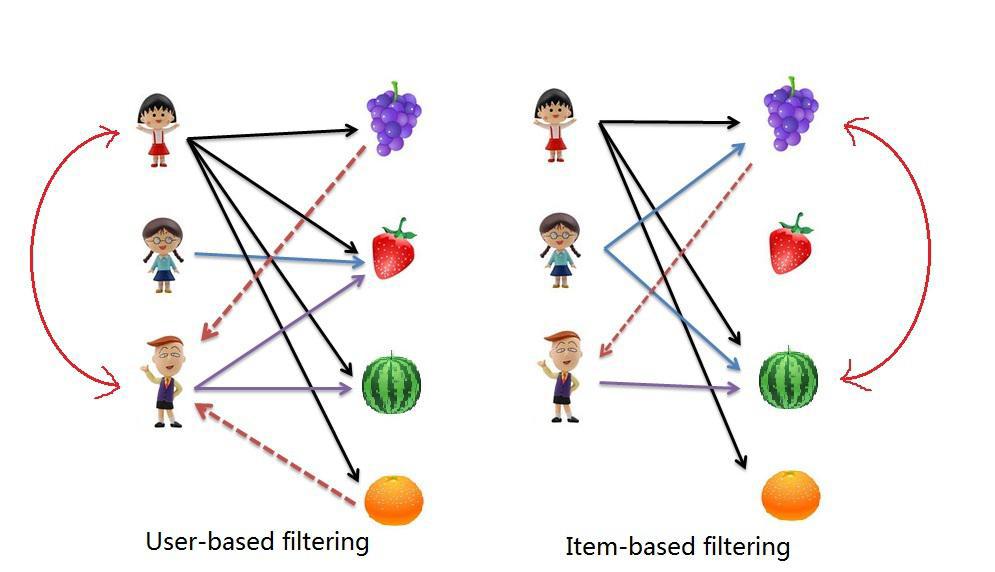
Ну что сложного? Никакой математики, только физика и химия. Матрица Пользователи*Товары и ищи похожие строчки, используя изучаемые в старшей группе детского сада формулы похожести векторов:
- Евклидово расстояние
- Расстояние городских кварталов
- Косинус угла между векторами
- Коэффициент кореляции Пиросона
- Расстояние Jaccard (на множествах)
Но на самом деле все гораздо хуже. Если у вас миллионы Пользователей и Товаров (как у нас), научно-популярные книжечки по построению рекомендательных систем, а также 99% имеющейся в сети информации и научных статей — можно смело выкинуть. Не-под-хо-дит 🙂
Тут выползает скрытый монстр под названием "проклятие размерности", начинаются серьезные вопросы по масштабируемости, скорости работы алгоритмов (все же знают, что Amazon придумал Item2Item алгоритм не от хорошей жизни, а потому — что User2Item алгоритм просто начал тормозить), превентивной оценки качества моделей и др.
А присовокупив настойчивую просьбу отдела маркетинга изменять коллаборативную фильтрацию в онлайне… — вы понимаете, что становится жарко.
Content-based рекомендательные системы
Принцип построения ну тоже до боли простой. Мы формируем профили объектов, будь то Пользователи, Группы или Товары и затем ищем похожие объекты методом хоть всем известного косинуса угла между векторами.
Чувствуете запах? Именно, запахло миром поисковиков…
Последнее время даже сам Mahout стал рассказывать о большой роли поисковых движков в построении рекомендательных систем.
И тут от вас уже требуются знания алгоритмов IR — ну если проект не очень очень простой. Хотя бы отличать «precision» от «recall» и «F1» — нужно уметь.
И конечно все это можно сжечь, когда данных становится много, ибо многое перестает работать и нужно самим выполнять реализацию IR-алгоритмов с пониманием их сути, например в NoSQL и/или памяти.
Но будьте осторожны! Вас сама команда может объявить Еретиком и сжечь за инакомыслие прямо на кухне 🙂
Обработка, фильтрация, агрегирование
Про инструменты мы поговорим позже. А в качестве алгоритмов нам сейчас предлагается не очень много вариантов:
— гонять SQL по данным в Hive, RedShift, Vertica
— понять и гонять по данным MapReduce задания
Со вторым поинтереснее. Если вы еще не поняли принцип MapReduce — это нужно сделать, он простой как «трусы за 1 руб 20 коп» и мощный. Есть, например, даже глава в известном Стенфордском курсе по обработке больших данных о том, как перевести на язык MapReduce любую операцию реляционной алгебры (и гонять по данным SQL!!!).
Но тут подвох. Нужные вам известные простые алгоритмы из популярных книг нужно перевести в распределенный вид для использования MapReduce — а как сделать это, не сообщается 🙂 Распределенных алгоритмов, получается, гораздо меньше и они нередко… другие.
Можете столкнуться еще с потоковыми алгоритмами обработки больших данных, но это отдельная тема другого поста.
Кластеризация
У вас несколько миллионов документов или пользователей и нужно найти группы. Либо склеить похожих. В лоб задача — не решается, слишком долго и дорого сравнивать каждого с каждым либо гонять итерации k-means.
Поэтому и придумали трюки с:
- minhash
- simhash
- LSH
Если у вас много данных, то ни k-means, ни c-means, ни, тем более, классическая иерархическая кластеризация — вам не помогут. Нужно «хакать» технологии и математику, искать решения в научных статьях и экспериментировать.
Тема интересная, обширная, полезная — но требует иногда серьезного знания вышеуказанных разделов математики.
Машинное обучение
С одной стороны, стороны бизнесовой, тут довольно понятно — вы учите модель на заранее подготовленных данных угадывать новые данные. Например, у нас 10000 писем и для каждого известно, спам это или нет. А затем мы подаем в модель новое письмо и, о чудо, модель говорит нам, спам это или нет.
По «силе угадывания» модели делятся на:
— бинарные классифиаторы, например угадывающие «спам/не спам»
— мультиклассовые классификаторы, например относящие документы к нескольким группам
— использующие регрессию, например угадывающие возраст или температуру воздуха
А вот алгоритмов — очень много, вот полезный ресурс.
И конечно это только малая часть алгоритмов, с которыми вам, вероятно, придется иметь дело.
Инструменты
Вот мы и дошли до инструментов. Что есть готового, что поможет нам в борьбе с Бигдатой?
Многие начинают со старого и доброго Hadoop MapReduce. В принципе сам Hadoop — это сборная солянка разных подпроектов, которые так между собой переплелись, что их уже родная мать не отделит.

Из наиболее востребованных:
- HDFS — кластерная файловая система для хранения вашей Бигдаты
- MapReduce — чтобы делать выборки из этих данных
- Hive — чтобы не связываться с низкоуровневыми MapReduce-техниками, а использовать старый добрый SQL
- Mahout — чтобы не изучать математику, а взять готовое и увидеть, что оно с большими данными не работает 🙂
- YARN — чтобы управлять всем этим «курятником»
Немного в сторонке находится Spark. Этот фреймворк выглядит, как бы мягко сказать, более современным, и позволяет обрабатывать данные, размещая их по возможности в памяти, а также выстраивать цепочки запросов — что, конечно, удобно. Мы сами его активно используем.
Хотя впечатления от Spark очень противоречивые. Он покрыт машинным маслом и торчащими проводами под напряжением — видимо его еще долго будут шлифовать, чтобы можно было разумными способами контролировать использование Spark оперативной памяти, не вызывая для этого духов Вуду.
А если вы в облаке Амазон, то HDFS вам, скорее всего, не понадобиться и можно напрямую использовать облачное объектное хранилище s3.
К сожалению, развернуть Spark в Амазоне — достаточно непросто. Да, есть известный скрипт, но — не стоит. Мало того, что он загружает половину кода Университета Беркли в Калифорнии вам на сервер, так еще потом если его неаккуратно запустить (добавить хотите новую машину в кластер или обновить) — ваш кластер Spark будет нещадно изуродован и сломан и ближайшую ночь вы проведете не в объятиях подруги, а занимаясь любовью с bash/ruby/копипастами конфигурации в 100-500 местах 🙂
А, чтобы сохранился позитивный осадок, посмотрите, как классно очень недавно Амазон стал продавать новый облачный сервисмашинного обучения, основанный на старом и добром «industry-standard logistic regression algorithm» (и никаких «лесов» и танцев с инопланетянами).
В добрый путь!
Вот наверно и все, что хотелось рассказать в вводном посте про алгоритмы и технологии обработки больших данных, с которыми разработчику вероятнее всего в ближайшие 3-6 месяцев придется вступить в бой. Надеюсь, информация и советы окажутся полезными и сэкономят вам, уважаемы коллеги, здоровье и манну.
А напоследок, ну чтобы понимать, как это может быть устроено изнутри, вид с птичьего полета нашего нового облачного сервиса:
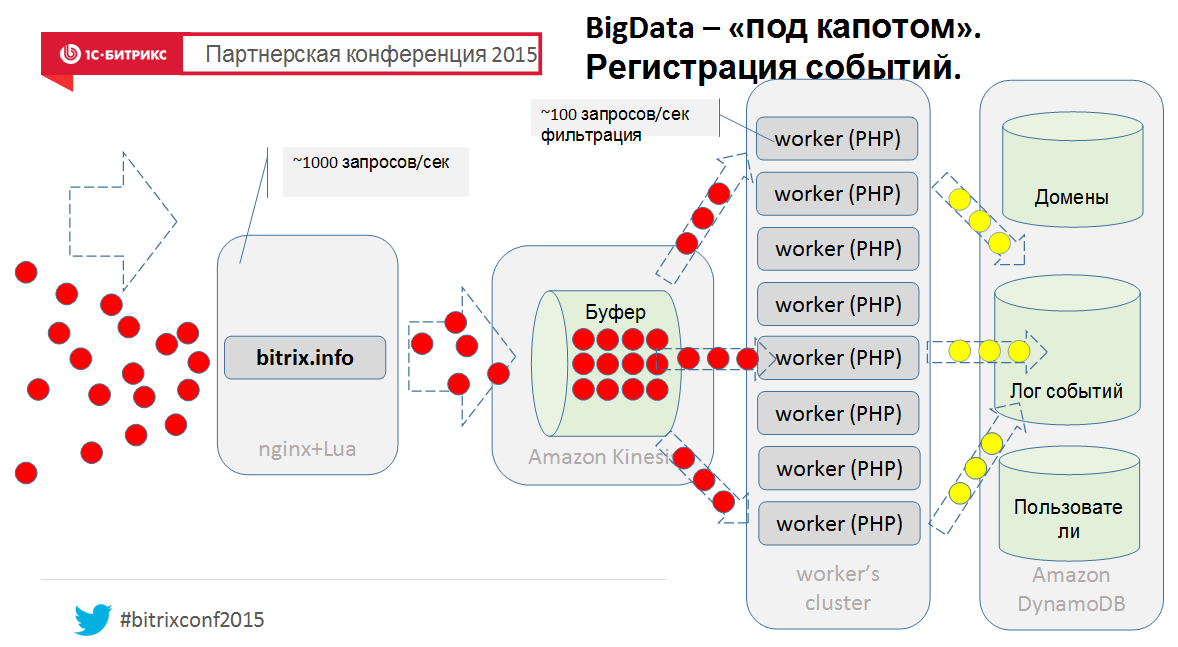
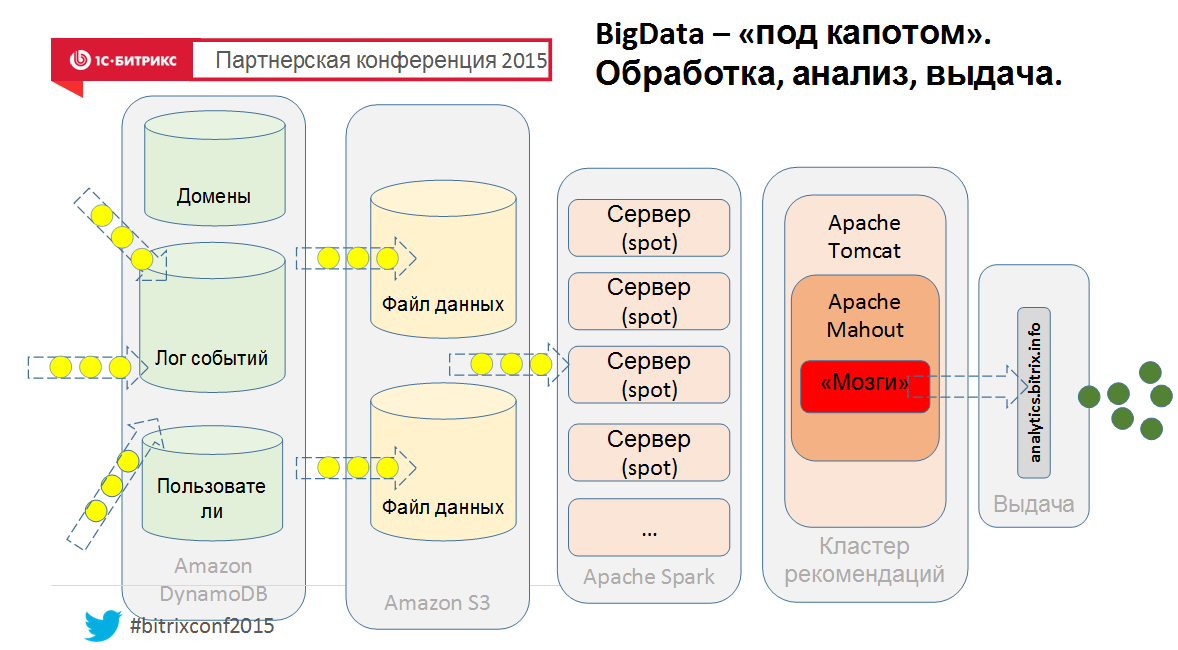
Ну это так, упрощенно, если что 🙂 Поэтому — спрашивайте в комментах.
ссылка на оригинал статьи http://habrahabr.ru/post/256551/
Добавить комментарий