В этой публикации мы поговорим о подавляющем рынке видеоаналитики, который представлен сегодня так называемым интеллектуальным видеонаблюдением.
Уже по самой масштабности можно приклеить этому направлению понятие «классическое». Тем более что у истоков стояла фирма Intel, а это уже классика. Именно на базе ее библиотеки с открытым кодом Open CV до сих пор делают свои продукты разработчики видеонаблюдения. Гордости ради надо сказать, программисты этого направления – русские и к тому же располагались в России – в нижегородском филиале Intel. Почему располагались? Направление закрыто уже несколько лет, народ разошелся по другим фирмам. Видимо, Intel первым почувствовал бесперспективность своей «классики».
Тем не менее, дело его живет и активно развивается. Только самый ленивый разработчики систем видеонаблюдения не применил Open CV в своих «интеллектуальных» кодах. И эта библиотека после своей смерти творит чудеса! Как заявляют многие продавцы систем видеонаблюдения, вычисляет криминальные моменты, детектирует драки, определяет оставленные и унесенные предметы, находит экстремистов… И пипл хавает. Миллиарды рублей вбухиваются в такие задачи для проектов «Безопасный город», «Безопасность на метрополитене», «Операция антитеррор» и т.д. Но, это больше политика, мы же поговорим о технологиях, почему эта красивая обертка для выставок не может работать на практике.
Специалисты называют это направление «жестким», потому что алгоритмы такой видеоаналитики основаны на точном задании параметров и порядка действий: пересечь определенную виртуальную линию, превысить детектируемую площадь, поставить предмет… Существует и другое направление (не интеловское) — гибкая видеоаналитика, работа которой не привязана к формализованным задачам, но о ней мы поговорим в следующий раз.
Принцип классической «жесткой» видеоаналитики в большинстве своем основан на детекторе объектов, локализующим замкнутые области видеодетекции по общим признакам их сосуществования. Но пока нет таких принципов, чтобы четко отличать людей от собак, кошек от автомобилей, а ветку дерева от газонокосилки. К сожалению, всё это хорошо работает только в идеальных лабораторных условиях, где пытаются обходить такие скользкие моменты, как то:
1. Видеодетектор основан на контрастности. Cливающиеся с фоном области не подпадают под его анализ. А значит, невозможно хоть как-то предугадать основные параметры интересуемого объекта.

Первая камера видит человека на темном фоне, соответственно детектирует только белую рубашку, остальные детали тела сливаются с фоном и недоступны для анализа. Учитывая еще и проблемы освещения, отличить более темное на темном или менее темное на темном практически не представляется возможным, т.к. это находится на уровне помех.
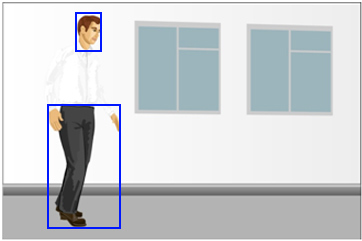
Вторая видит человека на белом фоне, соответственно детектирует только темную голову и темные брюки. Белая рубашка вообще никак не учитывается, т.к. для детектора нет информации. Таким образом, первая камера вообще будет видеть несколько объектов вместо одного человека.
2. Такие явления как тень отфильтровать успешно практически невозможно – уж, больно много форм она принимает, постоянно бегая за всеми нами.

В результате пропорции цели нарушены, и компьютер не понимает, что это человек.
3. Пересекающиеся цели приводят разум «железяки» в полных хаос. Определить, что это два человека, а не один или не пять, сегодняшние алгоритмы точно не могут.

4. Групповые цели неотличимы по форме детекции от сторонних объектов, например, несколько человек и автомобиль.

5. Параметр «размер объекта», на который уповают демонстраторы видеоаналитики при доказательстве возможности отличать людей от машин, неприемлем в 2D-видеонаблюдении в принципе.

Что больше: птица или автомобиль?
6. Часто приходится слышать такое достижение: но мы же регистрируем сразу несколькими камерами! Это, пожалуй, должно звучать как недостаток, ибо камеры видят объект по-разному.

— Первая видит темный гладкий затылок, вторая — светлое лицо с длинным выступом — носом.
— Первая видит большой объект, т.к. человек идет к ней ближе, вторая маленький, т.к. человек дальше. Перспективы у двухмерного зрения нет.
— Первая видит надпись на передней стороне майке «Спорт», вторая — на задней «Отдых».
— Первая видит качающуюся ветку над головой человека, по перспективе сливающуюся с головой. Вторая – муху, севшую перед камерой, создающую вид слона (ведь она ближе).
Вообще, перечень того, почему жесткая видеоаналитика невозможна в на практике, длинный, но у него есть очень интересный аспект: Данные проблемы легко скрыть при заранее подготовленном показе.
Заданный однородный фон, заданный контрастный костюм, заданные действия с непересекающимися целями, отсутствие помех в виде кустов, деревьев, осадков, бликов… Всё это у себя в офисе легко организовать, и тогда видеоаналитика превращается в чудо!
P.S.: Только это мы говорили про «классику», которую давно похоронил создатель, и имя которой эксплуатируется во многих денежных проектах. Но есть на рынке и живые алгоритмы видеоаналитики, об их достоинствах и недостатках поговорим в следующей статье.
Вполне возможно, что и труп когда-нибудь воскреснет. Ну, на каком-нибудь этапе новых типов компьютеров или систем ренгено-видеонаблюдения. Хотелось бы уже потому, что Интел, скорее всего, был не первым, в его нижегородскую лабораторию «Computer Vision» пришли русские ребята из других российских фирм, которые и стояли у истоков видеоаналитики. По сути, это российское изобретение. И жаль, что приходится писать такие статьи. Но ради этого не обманывать же другой российский народ, который все еще покупает несвежее, рекламой обработанное мясо?
ссылка на оригинал статьи http://habrahabr.ru/post/257565/
Добавить комментарий