 В преддверии скорого очного тура NeoQUEST-2015 продолжаем разбирать задания online-этапа. В статье разбирается задание «Абракадабра», состоящее из двух частей. Обе части — на криптоанализ: первая — на частотный, вторая — на дифференциальный.
В преддверии скорого очного тура NeoQUEST-2015 продолжаем разбирать задания online-этапа. В статье разбирается задание «Абракадабра», состоящее из двух частей. Обе части — на криптоанализ: первая — на частотный, вторая — на дифференциальный.
Участникам были даны два файла. Первый файл имел формат .docx, на его первой странице была та самая «абракадабра» — текст, состоящий сплошь из непонятных закорючек и символов, а на второй странице – не вполне понятный список. Глядя на него, одно можно было сказать точно: здесь описан некий алгоритм шифрования.
Второй файл был формата .txt, в нем содержались 2 столбца, озаглавленные как plaintext и cyphertext. Со всем этим надо было что-то делать…
Непонятный текст:
Ощыс щонныяыфЕoцътфюую pяокьюцфцъoхц дцхоягыьчc фц быяюсьфючьфлё юьфюиыфocё эывщг бёющфлэо яцхфючьсэo о яцхфючьcэo блёющц. Щбц юьфюиыфос кяыщчьцбъcпь рюфpяыьфлм oфьыяыч б цфцъохыМ щoнныяыфЕоцътфлм кяюнцмъ o ёцяцрьыяочьopц яцгфщц. ЩонныяыфЕoцътфлм кяюнцмъ кюрцхлбцыь быяюсьфючьфюы юьфюиыфоы эывщг бёющфлэo яцхфючьcэо o яцхфючьсэо блёющц дъюpц. Кющюдфлы кяюнцмъл эюугь дльт чюхщцфл щъc рцвщюую oх бючтэо дъюpюб б DЫS. Ёцяцрьыяoчьоpц яцгфщц кющюдфц щoнныяыфЕоцътфюэг кяюнцмъг, фю блжoчъсыьчc щъс Еыъюую яцгфщц. Юфц кюрцхлбцыь быяюcьфючьт, ч pюьюяюм ющфц бёющфцс яцхфючьт чюхщцъц дл яцхфючьт юкяыщыъaффюую блёющц. Юдяцьоьы бфoэцфоы, жью ёцяцрьыяoчьоpц ющфц o ьц вы щъc рцвщюую яцгфщц, кюьюэг жью ъпдюы юьфюиыфоы, pюьюяюы бръпжцыь яцхфючьo, фы хцбочoь юь pъпжым яцгфщц. Очкюътхгм щонныяыфЕoцътфлм ряокьюцфцъoх щъс кяюёювщыфоc бьюяюм жцчьo хцщцфос, oъо вы oщо фцкяюъюэ. Ц pъпж р йьюм жцчьo хцщцфоc М жцчьюьфлмцфцъoх.
Список:
- Substitution (15, 1, 8, 14, 6, 11, 3, 4, 9, 7, 2, 13, 12, 0, 5, 10)
- Permutation P(i) = 9*i + 4 (mod 32)
- 3 цикла: 2 цикла с [XOR with key + Substitution + Permutation], последний [XOR with key + Substitution + XOR with key]
- Вход: S-box №1 (10; 1), второй: S-box №3 (8; 6).
Учитывая список из файла Word, по парам открытых и закрытых текстов во втором файле формата .txt и нужно было восстановить ключ.
«Абракадабра» №1
Разбор первой части задания, с непонятным текстом, следовало начинать с определения кодировки, с этим успешно справлялись многие онлайн-декодеры (в частности, этот).

После использования декодера, получался уже более осмысленный текст, со знаками препинания, наводящий на мысль о шифровании путем замены символа на символ. Однако самый простой вариант – шифр Цезаря – здесь ничем не помог. Дальнейшие направления мысли сводились к частотному криптоанализу. Здесь, как и в случае с определением кодировки, существуют сервисы , позволяющие провести частотный анализ текста.
Результат частотного анализа введенного текста
Проведен анализ текста
Количество символов в тексте 910
Количество пробелов 114
Количество цифр 0
Количество точек и запятых 16
Количество английских букв 53
Количество русских букв 715
Посимвольная статистика и частотный анализ
Символ встречается 114 раз. Частота 12.53%
Символ ю встречается 86 раз. Частота 9.45%
Символ ц встречается 80 раз. Частота 8.79%
Символ ф встречается 63 раз. Частота 6.92%
Символ ь встречается 52 раз. Частота 5.71%
Символ ы встречается 50 раз. Частота 5.49%
Символ я встречается 43 раз. Частота 4.73%
Символ щ встречается 38 раз. Частота 4.18%
Символ ъ встречается 31 раз. Частота 3.41%
Символ о встречается 30 раз. Частота 3.30%
Символ o встречается 28 раз. Частота 3.08%
Символ ч встречается 27 раз. Частота 2.97%
Символ б встречается 22 раз. Частота 2.42%
Символ х встречается 21 раз. Частота 2.31%
Символ л встречается 19 раз. Частота 2.09%
Символ к встречается 16 раз. Частота 1.76%
Символ м встречается 16 раз. Частота 1.76%
Символ э встречается 14 раз. Частота 1.54%
Символ н встречается 14 раз. Частота 1.54%
Символ г встречается 13 раз. Частота 1.43%
Символ ё встречается 12 раз. Частота 1.32%
Символ с встречается 11 раз. Частота 1.21%
Символ р встречается 11 раз. Частота 1.21%
Символ c встречается 11 раз. Частота 1.21%
Символ т встречается 11 раз. Частота 1.21%
Символ p встречается 11 раз. Частота 1.21%
Символ. встречается 9 раз. Частота 0.99%
Символ ж встречается 9 раз. Частота 0.99%
Символ д встречается 9 раз. Частота 0.99%
Символ в встречается 7 раз. Частота 0.77%
Символ, встречается 7 раз. Частота 0.77%
Символ е встречается 6 раз. Частота 0.66%
Символ у встречается 6 раз. Частота 0.66%
Символ п встречается 5 раз. Частота 0.55%
Символ и встречается 4 раз. Частота 0.44%
Символ й встречается 1 раз. Частота 0.11%
Символ a встречается 1 раз. Частота 0.11%
Символ d встречается 1 раз. Частота 0.11%
Символ s встречается 1 раз. Частота 0.11%
Из результатов анализа видно, что в тексте не две английские буквы (обратите внимание на загадочное DЫS, которое может быть DES, DOS, DNS и так далее), а целых 53! Можно было потрудиться и написать программку, перебирающую буквы, которые одинаково выглядят как в русском, так и в английском варианте (например, очевидные o, e, p), а можно было погуглить и найти программку , которая подсветит английские буквы:

Внимательные участники могли заметить повторяющиеся слова, являющиеся, скорее всего, различными формами одного и того же слова:
щонныяыфЕoцътфюую
щoнныяыфЕоцътфлм
щoнныяыфЕоцътфюэг
Логично предположить, что наиболее краткая форма слова из этих трех – это именительный падеж, слово из 16 букв, в котором буквы 3 и 4 – одинаковые. Всего слов из 16 букв, если верить словарю, не так-то много: 759. А таких, чтобы третья и четвертые буквы совпадали, тем более. Можно было реализовать программку, подбирающую слова, подходящие по маске к зашифрованному, а можно было просто проверить слова из 16 букв с удвоенными на 3 и 4 позициях. Даже если проверять вручную, выбор невелик:
беззастенчивость
баллотировальник
гелленологофобия
коллаборационизм
коллаборационист
коллекционерство
целлофанирование
коммерциализация
пессимистичность
рассудительность
дифференцировать
Но буквы на позициях 2 и 10 также должны совпадать! По такому параметру подходит только слово «дифференцировать», и если попробовать осуществить такую замену символов, текст станет уже более читаемым, хоть и не до конца, откуда становится понятно, что искомое слово – не «дифференцировать», а «дифференциальный». Связав со второй частью задания, DЫS превращается в DES, еще немного упрощая задачу, а конечный вариант текста выглядит так:
«Идея дифференциального криптоанализа базируется на вероятностных отношениях между входными разностями и разностями выхода. Два отношения представляют конкретный интерес в анализе: дифференциальный профайл и характеристика раунда. Дифференциальный профайл показывает вероятностное отношение между входными разностями и разностями выхода блока. Подобные профайлы могут быть созданы для каждого из восьми блоков в DЕS. Характеристика раунда подобна дифференциальному профайлу, но вычисляется для целого раунда. Она показывает вероятность, с которой одна входная разность создала бы разность определённого выхода. Обратите внимание, что характеристика одна и та же для каждого раунда, потому что любое отношение, которое включает разности, не зависит от ключей раунда. Используй дифференциальный криптоанализ для прохождения второй части задания, или же иди напролом. А ключ к этой части задания — частотныйанализ.
Вот мы и получили ключ к первой части задания, однако если вводить «частотныйанализ» в поле ввода, выскакивает сообщение о том, что ключ неверен. Что делать? Все просто: от этой фразы нужно было взять MD5-хеш. Profit! Кстати, writeup по этому заданию уже опубликовал один из наших участников здесь, пройдя его немного по-другому, но, тем не менее, добившись успеха!
«Абракадабра» №2
Как уже было написано в расшифрованном тексте, вторую часть задания можно было пройти двумя способами:
- реализовать дифференциальный криптоанализ;
- забрутфорсить ключ, используя пары открытый-закрытый текст.
Большинство участников выбрали второй способ прохождения (и их можно понять, ведь реализовать криптоанализ все же трудозатратнее), поэтому этот способ мы разберем подробнее.
Дифференциальный криптоанализ
В его основу положена неравномерность распределения поразрядных разностей по модулю 2 пар открытых и соответствующих им зашифрованных текстов. Для атаки с использованием дифференциального метода требуется наличие подобранных открытых и соответствующих зашифрованных текстов, это условие выполнялось.
Участникам, неискушенным в криптоанализе, для прохождения задания именно этим способом, пришлось бы достаточно потрудиться, а именно:
- Разобраться в том, что такое дифференциал цикла шифрования.
- Изучить понятие дифференциальной характеристики.
- Понять, как работают подстановка и перестановка.
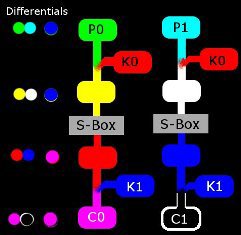
Дифференциал i-го цикла шифрования – это пара векторов a и b, такая, что пара открытых текстов (x1 и x2) с разностью a может перейти после i-го цикла в пару выходных текстов (y1 и y2) с разностью b. Дифференциальная характеристика представляет собой последовательность одноцикловых дифференциалов, при этом выходная разность текстов для предыдущего цикла совпадает с входной разностью текстов последующего цикла.
Блочный шифр имеет длину блока и ключа по 32 бита (об этом можно догадаться, посмотрев на условие 2 в списке). Зашифрование, как уже было указано в списке документа .docx, выполняется на 3 циклах, каждый из которых содержит XOR с ключом, замену 4-битовых слов (подстановка, Substitution), и два цикла содержат перестановку (Permutation). При выполнении перестановки бит с позиции i перемещается на позицию 9*i + 4 (mod 32).
К слову, перестановка вызвала значительные затруднения у участников из-за своей нетривиальности: на входе нумерация битов идет от 1 до 32, а на выходе — от 0 до 31 (пример: Permutation(0x12345678)=0хB3E29180). Однако после публикации подсказки в Twitter, участники стали активно проходить задание!
Общий алгоритм прохождения задания методом дифференциального криптоанализа:
- Используя пару открытых текстов, смотрим разность для этой пары на выходе 2 цикла
- Используя пару выходных шифртекстов после 3 цикла, выполняем их обратные преобразования, вычисляя обратную подстановку и делая XOR с ключом.
- Вычисляем разность для преобразованных шифртекстов.
- Сравниваем разности для преобразованных шифртекстов и для пары открытых текстов.
- Ищем совпадающие биты, если они есть, увеличиваем счетчик числа совпадений.
- Перебрав все кусочки ключа (2 по 4 бита, итого — 8 битов), смотрим, для какого (или для каких) наибольшее количество совпадений. Это и будет искомой частью ключа.
- Повторяем, выбирая другие активные блоки и строим новую характеристику, для определения уже другой части ключа. Делаем, пока либо все 32 бита не будут вскрыты, либо пока не будет вскрыта большая часть ключа — остальное можно забрутить.
Брутфорс
Перейдем к прохождению задания методом брутфорса! Можно было реализовать программу, которая осуществляет брутфорс параллельно на всех ядрах процессора. Помимо этого, конечно, требовалось быть внимательными при реализации подстановки и перестановки.
using System; using System.Collections; using System.Collections.Generic; using System.IO; using System.Linq; using System.Text; using System.Threading; using System.Threading.Tasks; namespace ConsoleApplication2 { static class Program { static long progress = 0; static long prev_progress = 0; static DateTime prev_date; static bool complete = false; static byte reverse_bits( this byte b) { byte r = 0; for (int i = 0; i < 8; i++) { byte mask = (byte)(1 << i); byte mask_neg = (byte)(1 << (7 - i)); if ((b & mask) == mask) { r |= mask_neg; } } return r; } static byte[] reverse_bits(this byte[] array) { byte[] r = new byte[array.Length]; for (int i = 0; i < array.Length; i++) { r[i] = array[i].reverse_bits(); } return r; } static void Main(string[] args) { DateTime start_date = DateTime.Now; progress = 0; prev_progress = 0; prev_date = DateTime.Now; Thread monitor = new Thread(a => { while (progress != 0xFFFFFFFF && complete == false) { Thread.Sleep(5000); long long_percent = ((progress * 100 * 1000) / 0xFFFFFFFF); long sec = (long)(DateTime.Now - prev_date).TotalSeconds; long speed = (long)((progress - prev_progress) / sec); Console.WriteLine("{0}.{1}% ... speed={2} left={3}", long_percent / 1000, long_percent % 1000, speed, 0x100000000 - progress); prev_date = DateTime.Now; prev_progress = progress; } }); monitor.Start(0); Parallel.For(0x00000000, 0xFFFFFFFF, i => { byte[] text = BitConverter.GetBytes((UInt32)0x5ABF054B); Array.Reverse(text); byte[] key = BitConverter.GetBytes((UInt32)i); Array.Reverse(key); Crypt(ref text, key); Array.Reverse(text); if (BitConverter.ToUInt32(text, 0) == (UInt32)0x4CD3CA17) { complete = true; Console.WriteLine("KEY {0}", i.ToString("X")); File.WriteAllText(i.ToString("X") + ".txt", i.ToString()); Console.WriteLine("Complete! time = " + (DateTime.Now - start_date).ToString()); Console.ReadKey(); } Interlocked.Increment(ref progress); } ); Console.WriteLine("Complete! time = " + (DateTime.Now - start_date).ToString()); Console.ReadKey(); } static int[] substitution_table = { 15, 1, 8, 14, 6, 11, 3, 4, 9, 7, 2, 13, 12, 0, 5, 10}; static void Crypt(ref byte[] text, byte[] key) { Xor(ref text, key); Substitution(ref text); Permutation(ref text); Xor(ref text, key); Substitution(ref text); Permutation(ref text); Xor(ref text, key); Substitution(ref text); Xor(ref text, key); } static void Substitution(ref byte[] text) { for (int i = 0; i < 8; i += 2) { int h = (text[i / 2] >> 4) & 0xF; int l = (text[i / 2] >> 0) & 0xF; h = substitution_table[h]; l = substitution_table[l]; text[i / 2] = (byte)((h << 4) | l); } } static void Permutation(ref byte[] text) { BitArray bits = new BitArray(text.reverse_bits()); text = new byte[text.Length]; for (int i = 0; i < 32; i++) { int idx = ((i + 1) * 9 + 4) % 32; text[idx / 8] |= (byte)((bits[i] ? 1 : 0) << (idx % 8)); idx = idx; } text = text.reverse_bits(); } static void Xor(ref byte[] text, byte[] key) { for (int i = 0; i < text.Length; i++) { text[i] ^= key[i]; } } } } Любопытно, что для некоторых пар открытых и соответствующих им зашифрованных текстов программа могла найти и не один ключ (в частности, для самой первой пары). От найденного значения, как и в первой части задания, нужно было найти MD5-хеш.
ссылка на оригинал статьи http://habrahabr.ru/post/258893/
Добавить комментарий