В одном из предыдущих постов мы уже писали о центральном понятии в статистике — p-уровне значимости. И пока в научной среде не утихают споры об интерпретации p-value, значительная часть исследований проводится именно с использованием p-value для определения значимости полученных в исследовании различий. Сегодня же мы поговорим о самом творческом этапе обработки данных — как же значимые различия визуализировать.
Визуализация результатов — неотъемлемая часть проведенного исследования, например, публикация статьи или выступление с докладом и т.д. При этом корректное изображение полученных различий — вопрос не только эстетический (хотя, разумеется, эффектная визуализация как минимум привлечет внимание слушателей!), но и сугубо статистический. Мне всегда нравился подход, согласно которому график должен содержать в себе исчерпывающий отчет о проделанной работе: какие группы сравнивали, по какой переменной, были ли обнаружены статистически значимые различия и т.д.
Сравнение средних значений в R
Давайте остановимся на одном из самых популярных типов графиков — сравнение средних значений — и выясним, как их можно строить в R буквально в несколько строчек кода. Воспользуемся встроенными в R данными mtcars, предоставляющими информацию о различных технических характеристиках 32 автомобилей. Сравним средние значения расхода топлива у машин с автоматической и ручной коробкой передач.
mtcars$am <- factor(mtcars$am, labels = c("Auto", "Manual")) # сделаем тип коробки передач фактором t.test(mpg ~ am, mtcars)
Результаты t — теста:
t = -3.7671, df = 18.332, p-value = 0.001374 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -11.280194 -3.209684 sample estimates: mean in group 0 mean in group 1 17.14737 24.39231
Статистически значимые различия обнаружены, осталось визуализировать результат. Начнем с графика-чемпиона в категории “как не нужно отображать сравнения средних значений”.
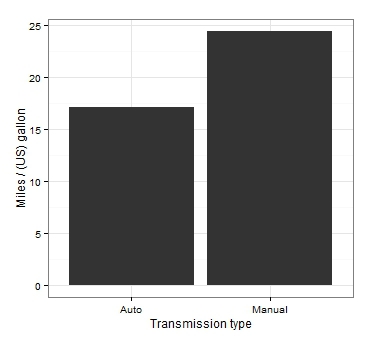
Что, собственно говоря, здесь не так?
Даже если смириться с тем, что средние отображены столбиками, основной недостаток такого рода графика — отсутствие на нем мер изменчивости наших данных. Глядя на такой график, абсолютно не ясно, были ли получены значимые различия. И единственный вывод, который мы можем сделать: правый столбик выше левого!
Давайте улучшим исходный вариант следующим образом: отобразим средние значения точками и добавим доверительные интервалы:
library(ggplot2) ggplot(mtcars, aes(am, mpg))+ stat_summary(fun.data = mean_cl_boot, geom = "errorbar", width = 0.1, size = 1)+ stat_summary(fun.y = mean, geom = "point", size = 6, shape = 22, fill = "white")+ theme_bw()+ xlab("Transmission type")+ ylab("Miles / (US) gallon")

Так гораздо лучше! Во-первых, непересекающиеся доверительные интервалы подтверждают наш вывод о статистически значимых различиях. Во-вторых, для внимательного наблюдателя данный график также предоставляет дополнительную информацию о деталях наших данных: легко заметить, что доверительный интервал для среднего значения расхода топлива в группе с ручной коробкой передач значительно шире. В нашем случае это объясняется различным значением стандартного отклонения в группах (эту информацию в принципе невозможно получить, глядя на “столбчатый” график).
Дисперсионный анализ и сравнение нескольких групп
Рассмотрим теперь более интересный вариант с применением дисперсионного анализа и сравнением нескольких групп. Воспользуемся еще одними встроенными в R данными — ToothGrowth. Данные позволяют исследовать рост зубов у морских свинок в зависимости от дозировки витамина C и типа потребляемых продуктов. Применим дисперсионный анализ:
fit <- aov(len ~ dose * supp, ToothGrowth)
Результаты анализа:
Df Sum Sq Mean Sq F value Pr(>F) dose 1 2224.3 2224.3 133.415 < 2e-16 *** supp 1 205.3 205.3 12.317 0.000894 *** dose:supp 1 88.9 88.9 5.333 0.024631 * Residuals 56 933.6 16.7
Мы видим, что и влияние каждого фактора в отдельности, и их взаимодействие оказались значимыми. Это определенно тот случай, когда без визуализации сделать какие-то выводы весьма затруднительно.
ggplot(ToothGrowth, aes(factor(dose), len, col = supp))+ stat_summary(fun.data = mean_cl_boot, geom = "errorbar", width = 0.1, size = 1, position = position_dodge(0.2))+ stat_summary(fun.y = mean, geom = "point", size = 3, shape = 22, fill = "white", position = position_dodge(0.2))+ theme_bw()+ xlab("Dose in milligrams")+ ylab("Tooth lenght")+ scale_color_discrete(name = "Supplement type", labels = c("Orange juice", "Ascorbic acid"))
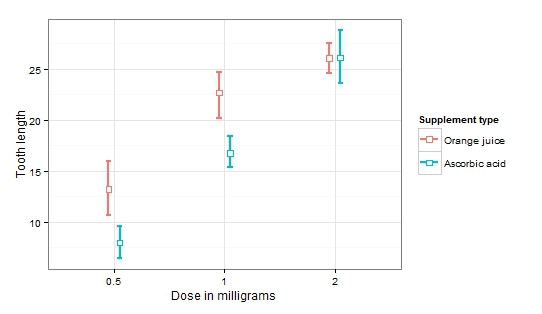
Теперь легко заметить увеличение среднего значения длины зубов при увеличении дозировки (значимый фактор дозировки). При этом влияние типа продуктов сходит на нет с увеличением дозировки (значимый фактор типа продукта и взаимодействие факторов).
Таким образом, нанесение доверительных интервалов на график не только позволяет нам оценить, насколько статистически значимы полученные различия, но также даёт возможность составить представление о характере изменчивости внутри сравниваемых групп. Ниже представлена небольшая памятка о соотношении дистанции между доверительными интервалами и приблизительным значением p-value.

Почему все-таки R?
На сегодняшний день существует множество инструментов для анализа данных и визуализации результатов, некоторые из них позволяют применять довольно широкий спектр статистических методов, не имея никакого опыта программирования (например, SPSS). Также весьма распространен для анализа данных язык программирования Python.
Если вы начинаете осваивать анализ данных:
- R очень простой и интуитивно понятный язык программирования. Изучив азы работы в R, вы значительно упростите и ускорите решение ваших задач.
- Работа в R дает ценный опыт и помогает при изучении более сложных языков программирования.
- Разумеется визуализация! Мы рассмотрели в этой статье только самый базовый вариант графиков, но даже он смотрится в разы симпатичнее, чем визуализация в программах для анализа данных с графическим интерфейсом.
Если вы уже имеете опыт анализа данных:
- В R тысячи пакетов и библиотек, предоставляющих возможность применять, пожалуй, абсолютно любые статистические методы. Реализовать регрессионный анализ со случайными эффектами в R позволит специальная библиотека lme4. С помощью языка Python, например, это сделать значительно сложнее!
- В R множество библиотек, которые написаны непосредственно исследователями и учеными для решения весьма узкоспециализированных задач из различных научных областей. Например, bioconductor — предоставляет инструменты для анализа данных в биоинформатике. Библиотека grt поможет обрабатывать экспериментальные данные в области вычислительных моделей в когнитивной науке! Специальные библиотеки помогут обработать результаты EEG, FMRI или исследования, фиксирующего движение глаз человека при помощи айтрекера.
- И, в завершении, R позволяет быстро решать широчайший спектр задач в интерактивном режиме.
Онлайн-курс по R на русском языке: три недели анализа данных
Не так давно на платформе Stepic завершился онлайн-курс по введению в статистику, посвященный базовыми методами анализа данных. В нашем новом трехнедельном онлайн-курсе от Института биоинформатики слушатели познакомятся с основами программирования на языке R.
На первой неделе мы научимся манипулировать с данными и познакомимся с базовым синтаксисом языка. Вторая и третья недели курса посвящены применению основных статистических тестов и визуализации результатов. Курс на русском языке и абсолютно бесплатный для всех желающих! Записаться: Анализ данных в R
ссылка на оригинал статьи http://habrahabr.ru/post/260981/
Добавить комментарий