Привет!
Это первый пост от лица нашей компании на Хабре и в нём мы хотим вам немного рассказать об архитектуре нашего облачного сервиса мониторинга серверов и веб сайтов CloudStats.me, с которым мы в данный момент проходим акселерацию во ФРИИ в Москве. Мы также хотим поделиться с вами нашей текущей статистикой и рассказать о планах на ближайшее будущее, но обо всём по порядку.
1. Архитектура системы
Наша платформа нацелена на системных администраторов, которым не хочется долго возиться с настройкой Nagios или Zabbix, а просто нужно отслеживать основные параметры серверов, не тратя много времени и ресурсов на мониторинг. Мы стараемся не перегружать интерфейс системы количеством настроек, поэтому всё построено по принципу KISS (keep it simple stupid).
Почти вся система написана на Ruby on Rails (за исключением python агента, которого мы скоро также заменим на агента на Ruby), с использованием RactiveJS. Front-end работает на Tomcat, нагрузка на которые распределяется с помощью Haproxy. В качестве CDN мы используем CloudFlare, через которую проходят только статичные файлы JS, CSS, PNG и т.д. Тем не менее, даже для такого достаточно простого и пока что не очень большого сервиса, нам уже приходится применять балансировку нагрузки на всех частях платформы для избежания перегрузок.
Архитектура сервиса на начало июня:
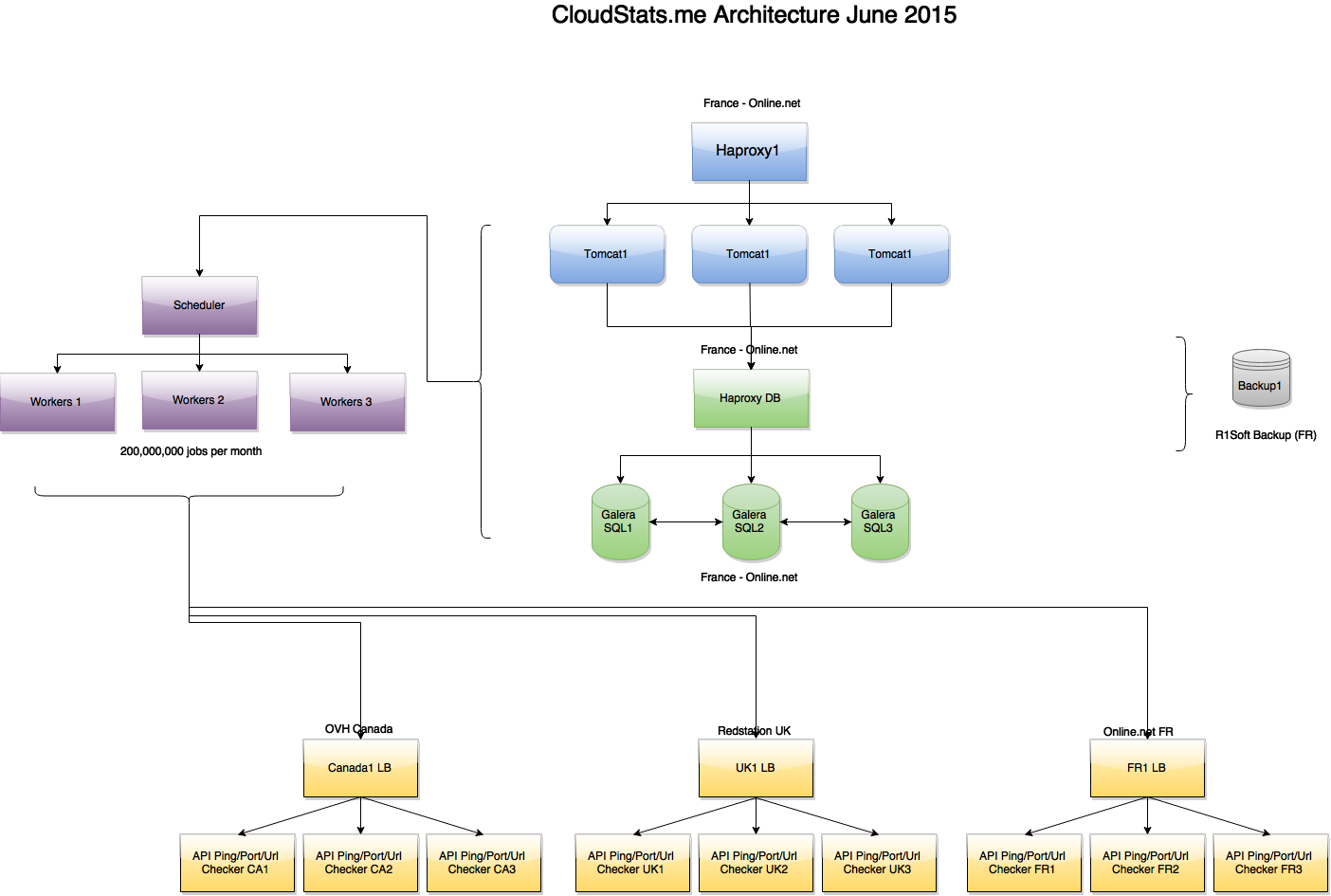
Как видно на картинке, задачи создаются отдельным нодом Scheduler и обрабатываются несколькими Worker нодами, которые в свою очередь связываются по API с серверами проверок Ping/Port/URL, расположенными в 3х зонах — France, UK, USA. Если один из серверов проверок вернул «Ping Failed» статус для какого-либо IP, то осуществляются дополнительные проверки в двух других зонах, чтобы исключить false positives. В будущем мы планируем вывести всё это во front-end чтобы вы смогли видеть, из каких локаций ваш IP недоступен (допустим, в ситуации с DDoS или routing issues).
Как мы писали ранее, мы используем master-master репликацию кластера Galera MariaDB и Haproxy перед ним. Haproxy установлены на всех участках нашей архитектуры, что позволяет нам как выкатывать новые версии продукта без ущерба для пользователей, так и обновлять backend системы без ухудшения сервиса. В дальнейшем мы планируем начать использовать партицирование.
2. Инфраструктура

Из датацентров, наш выбор пал на 3 достаточно распространённых ДЦ, которые нам позволяют держать затраты на инфраструктуру под контролем, а уровень сервиса на должном уровне.
Мы используем Online.net для наших серверов во Франции, где находится основной front-end системы. Выбор пал на Online.net, т.к. там присутствует удобная панель управления серверами, позволяющая быстро переносить IP адреса с одного сервера на другой, наличие удалённой консоли iDRAC, а также отсутствие ограничений по трафику и защита от DDoS атак. В Online.net мы использовали порядка 11 Tb трафика за июнь и за это не было никаких переплат, что удобно.
Дополнительные серверы, производящие проверки URL, Ping, и Ports, находятся в OVH Canada и Redstation UK, что даёт нам необходимый географический охват. Тем не менее, уже в июле мы завершим переезд на платформу Microsoft Azure, которая предоставит нам доступ к 15 датацентрам по всему миру. Это позволит увеличить количество локаций, откуда мы будем производить проверки серверов и сайтов, а также повысит отказоустойчивость платформы в целом (об этом мы напишем отдельно).
В данный момент мы уже производим порядка 200 миллионов проверок в месяц, что включает в себя пинги всех серверов (1352 сервера x 2 пинга в минуту x 60 минут x 24 часа x 31 день = ~120 млн. «ping jobs» в месяц), проверки URLs, а также проверки портов, сбор и обработку статистики по серверам и т.д.
3. Немного статистики:
В данный момент в нашу систему добавлено 1352 сервера, на которых установлен наш агент и которые каждые 4 минуты отправляют нам свою статистику. Вдобавок, мы проверяем каждый добавленный сервер с помощью внешнего ping’a 2 раза в минуту.
Серверы, добавленные в систему, в пиковый день 10 Июня 2015 генерировали до 1,6 Терабита трафика в сек. (Tb/s). Это включает в себя как входящий, так и исходящий трафик. Исходящего трафика немного больше, чем входящего, но это довольно предсказуемо.
Использование канала по дням за Июнь 2015 года. Пиковый день — 10 Июня.
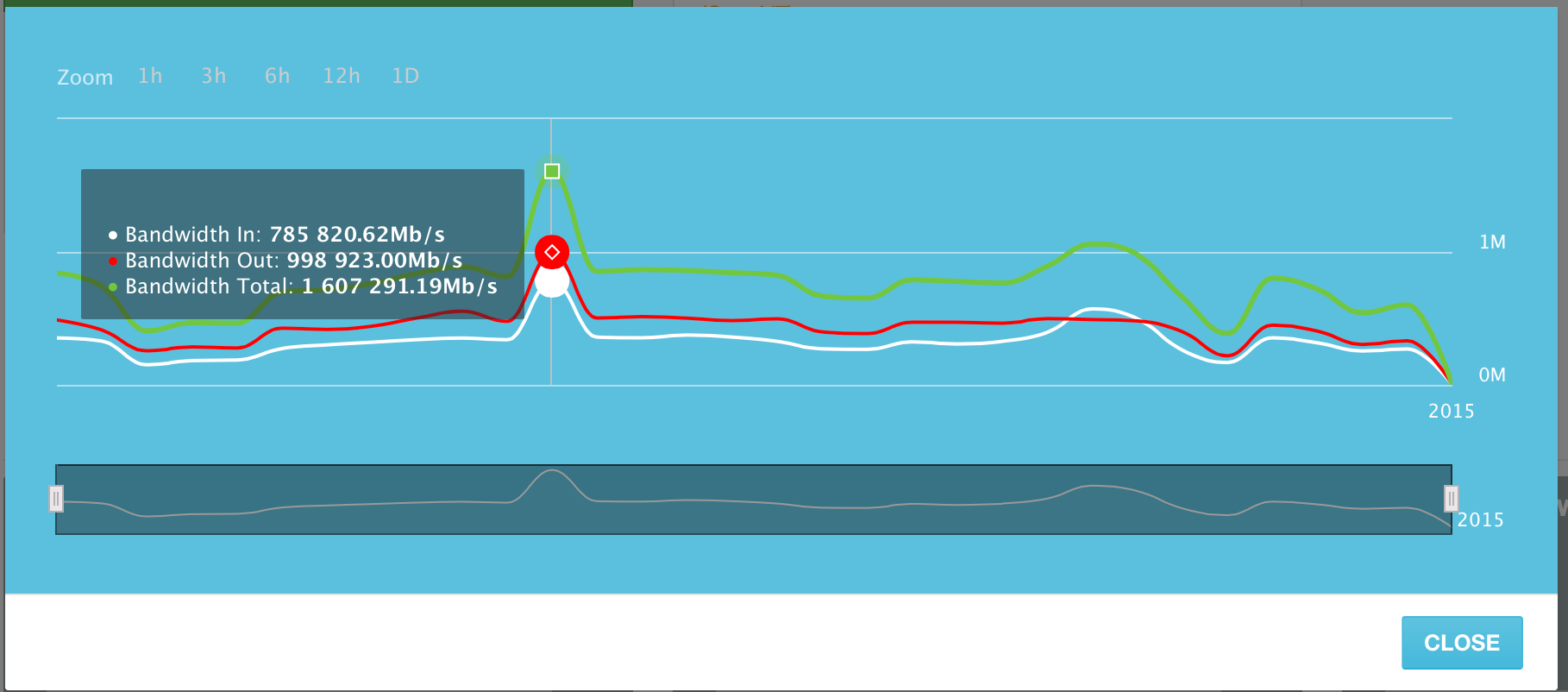
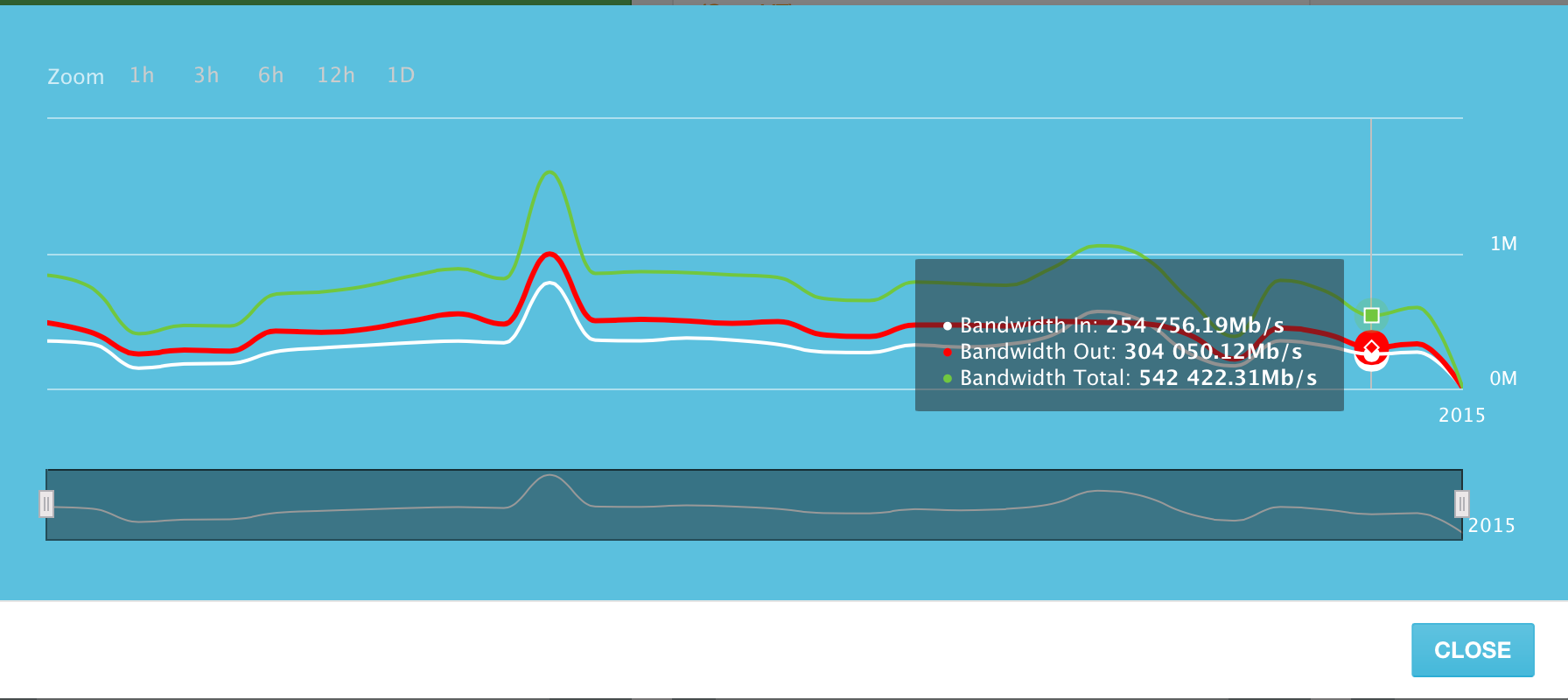
Среднее использование канала всех серверов в системе — в районе 500 Гигабит в секунду.
При небольшом пересчете, эти «средние» 500 Гигабит трафика в секунду выливаются примерно в 5 273 Терабайт переданных данных в день. И это объем данных, передаваемый только лишь ~1300 серверами в нашей системе!
Конечно, мы пока что еще молодой сервис мониторинга, но мы прилагаем все усилия для создания удобной и простой платформы, которую можно использовать как внутри компании, так и показывать клиентам и давать им доступ.
Впрочем, мы не идем по моделе конкурентов и не создаем «отечественный New Relic». Напротив, мы хотим создать платформу, в которой будет присутствовать не только мониторинг серверов, но также элементы безопасности — сканирование серверов и сайтов на уязвимости; возможность управления серверами из одной платформы, а также резервное копирование данных (backups) в облачный storage.
Следите за обновлениями!
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
ссылка на оригинал статьи http://habrahabr.ru/post/261497/
Добавить комментарий