Примечание переводчика: В нашем блоге мы много пишем о построении облачного сервиса 1cloud, но немало интересного можно почерпнуть и из опыта по работе с инфраструктурой других компаний. Мы уже рассказывали о дата-центре фотосервиса imgix, а сегодня представляем вашему вниманию адаптированный перевод заметки о повышении производительности MySQL от инженеров соцсети Pinterest.
Когда я присоединился к Pinterest, то свои первые три недели провел в группе для новичков, где новоприбывшие работники трудятся над реальными проектами, затрагивающими весь спектр программного обеспечения компании. Мы поняли, что такое Pinterest, принимая непосредственное участие в его создании – вполне нормально, когда сотрудники с первых дней занимаются написанием кода и вносят посильный вклад в работу сервиса.
Компания дает новоприбывшим инженерам выбрать, к какой команде они хотят присоединиться, а написание кусков кода для различных нужд помогает принять взвешенное решение. Там сотрудники решают большое количество задач – моя была связана с частью проекта по оптимизации производительности MySQL.
Подумать только! Pinterest, MySQL и AWS!
Мы работаем с MySQL, развернутой на Amazon Web Services (AWS). Несмотря на достаточно мощные инстансы с RAID 0 на SSD-накопителях и довольно низкую рабочую нагрузку (множество записей выбирается по первичному ключу или простым ранжированием), достигающей максимум 2000 QPS (запросов в секунду), мы не могли реализовать сколько-нибудь адекватные уровни производительности ввода/вывода. Превышение порога в 800 IOPS (операций ввода/вывода в секунду) приводило к неприемлемому увеличению латентности (тайминга) и задержке репликации.
Асинхронность репликации или низкая производительность чтения на слэйв-серверах замедляет процесс ETL и выполнение заданий в пакетном режиме, что отрицательно сказывается на работе зависящих от них команд инженеров. У нас было два варианта: перейти на еще больший инстанс, что удвоило бы наши затраты и уменьшило эффективность, или найти способы увеличить производительность существующей системы.
Я подписался на проект с коллегой Робом Вулчем (Rob Wultsch), который уже провел большое исследование и выяснил, что при работе на SSD в AWS серьезное влияние на производительность оказывает версия ядра Linux. Стандартная версия ядра 3.2, поставляемая с Ubuntu 12.04, не справляется с этой задачей, как, впрочем, и версия 3.8, которую рекомендует AWS в качестве минимальной (однако она все равно в два раза быстрее версии 3.2). SysBench, запущенный на инстансе i2.2xlarge (двухдисковый RAID-0 из SSD) с ядром 3.2, с трудом выдавал 100 МБ/сек при 16K операциях произвольной записи. После апгрейда ядра до версии 3.8 тот же самый тест показал скорость 350 МБ/сек, но результат по-прежнему был гораздо меньше ожидаемого. Увидев, какой результат дало такое простое усовершенствование, мы задались другими вопросами о том, как еще можно повысить эффективность и исправить настройки конфигурации. Вырастет ли производительность, если установить еще более новую версию ядра? Должны ли мы менять другие настройки на уровне операционной системы? Можно ли что-то улучшить в файле конфигурации my.cnf? Как нам заставить MySQL работать быстрее?
В поисках ответов я задал более 60 различных тестовых конфигураций SysBench с выводом в файл. Конфигурации отличались версиями ядер, файловыми системами, mount-опциями и размерами разделов RAID. На основании проведенных тестов выбиралась лучшая конфигурация, после чего я запускал еще штук 20 тестов или около того, но уже с другими модификациями, наблюдая за изменением скорости обработки транзакций. Методология тестирования была стандартна и ничем не отличалась на всех этапах испытания: запустить тест на один час, каждую секунду фиксируя показатели, затем «отрезать» первые 600 секунд, тем самым исключив время разогрева, и обработать оставшуюся часть. Определив оптимальную конфигурацию, мы перестроили наши самые большие и самые важные серверы, чтобы изменения вступили в силу.
С 5000 QPS до 26000 QPS: повышение производительности MySQL без улучшения оборудования
Давайте взглянем, как повлияли внесенные изменения на скорость обработки транзакций в тесте SysBench, вычислив 99-й процентиль времени отклика при различных конфигурациях системы и разных количествах потоков: 16 и 32.
Ниже приведены расшифровка обозначений на графике и сами графики:
- CURRENT: версия ядра 3.2, стандартная конфигурация MySQL
- STOCK: версия ядра 3.18, стандартная конфигурация MySQL
- KERNEL: версия ядра 3.18, пара правок sysctl во вводе/выводе
- MySQL: версия ядра 3.18, оптимизированная конфигурация MySQL
- KERN + MySQL: версия ядра 3.18, изменения из пунктов №3 и №4
- KERN + JE: версия ядра 3.18, изменение из пункта №3 и jemalloc
- MySQL + JE: версия ядра 3.18, конфигурация MySQL из пункта №4 и jemalloc
- ALL: версия ядра 3.18, изменения из пунктов №3, №4 и jemalloc

Когда оптимальные настройки были установлены, то мы увидели, что производительность чтения/записи можно увеличить примерно на 500%, как в случае с 16 потоками, так и с 32, одновременно уменьшив 99-й процентиль латентности на более чем 500 мс в обоих случаях. Скорость обработки запросов чтения выросла с 4100-4600 QPS до более чем 22000-25000 QPS, в зависимости от степени параллелизма. Скорость обработки запросов записи выросла с 1000 QPS до 5100-6000 QPS. Такого громадного роста производительности и скорости обработки удалось достигнуть всего лишь благодаря нескольким простым модификациям.
Разумеется, все характеристики, полученные в ходе тестов производительности, ничего не значат, если не приводят к реальным результатам. Ниже изображен график времени ожидания в наших главных клиентских и серверных кластерах, отображающий данные за несколько дней до и после апгрейда всех мастер-серверов. Весь процесс занял всего неделю.
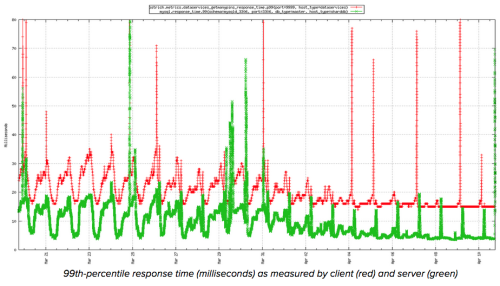
Красная линия показывает латентность на стороне клиента, а зеленая – на стороне сервера. Со стороны клиента 99-й процентиль латентности уменьшился с 15-35 мс (с отдельными выбросами до 100 мс) до стабильных 15 мс (с выбросами до 80 мс и меньше). Со стороны сервера время ожидания уменьшилось с 5-15 мс до стабильных 5 мс, с ежедневным 18-ти миллисекундным пиком на время обслуживания системы.
По сравнению с началом года пиковая производительность этих кластеров увеличилась на 50%, и теперь мы не просто справляемся с большей нагрузкой (которая по-прежнему ниже нашей расчетной пропускной способности), но делаем это с гораздо большей скоростью. Хорошей новостью для тех, кто любит поспать ночью, будет то, что число отмеченных нарушений, связанных с производительностью системы или перегрузкой сервера, упало с мартовских 300 до суммарных 10-и за апрель и май.
Если вы хотите получить больше информации, включая подробности о том, как выглядели наши MySQL и ОС до и после модификации, то посмотрите презентацию «Все ваши IOPS принадлежат нам» с моего выступления на конференции-выставке Percona Live MySQL в 2015 году.
ссылка на оригинал статьи http://habrahabr.ru/post/261741/
Добавить комментарий