Социальные сети (Twitter, Facebook, LinkedIn) — пожалуй, самая популярная бесплатная доступная широкой общественности площадка для высказывания мыслей по разным поводам. Миллионы твитов (постов) ежедневно — там кроется огромное количество информации. В частности, Twitter широко используется компаниями и обычными людьми для описания состояния дел, продвижения продуктов или услуг. Twitter также является прекрасным источником данных для проведения интеллектуального анализа текстов: начиная с логики поведения, событий, тональности высказываний и заканчивая предсказанием трендов на рынке ценных бумаг. Там кроется огромный массив информации для интеллектуального и контекстуального анализа текстов.
В этой статье я покажу, как проводить простой анализ тональности высказываний. Мы загрузим twitter-сообщения по определенной теме и сравним их с базой данных позитивных и негативных слов. Отношение найденных позитивных и негативных слов называют отношением тональности. Мы также создадим функции для нахождения наиболее часто встречающихся слов. Эти слова могут дать полезную контекстуальную информацию об общественном мнении и тональности высказываний. Массив данных для позитивных и негативных слов, выражающих мнение (тональных слов) взят из Хью и Лью, KDD-2004.
Реализация на R с применением twitteR, dplyr, stringr, ggplot2, tm, SnowballC, qdap и wordcloud. Перед применением нужно установить и загрузить эти пакеты, используя команды install.packages() и library().
Загрузка Twitter API
Первый шаг — зарегистрироваться на портале разработчиков для Twitter и пройти авторизацию. Вам понадобятся:
api_key = "Ваш ключ API" api_secret = "Ваш api_secret пароль" access_token = "Ваш токен доступа" access_token_secret = "Ваш пароль токена доступа" После получения этих данных авторизируемся для получения доступа к Twitter API:
setup_twitter_oauth(api_key,api_secret,access_token,access_token_secret) Загрузка словарей
Следующий шаг — загрузить массив позитивных и негативных тональных слов (словарь) в рабочую папку R. Слова можно будет достать из переменных, positive и negative, как показано ниже.
positive=scan('positive-words.txt',what='character',comment.char=';') negative=scan('negative-words.txt',what='character',comment.char=';') positive[20:30]
## [1] "accurately" "achievable" "achievement" "achievements" ## [5] "achievible" "acumen" "adaptable" "adaptive" ## [9] "adequate" "adjustable" "admirable"
negative[500:510]
## [1] "byzantine" "cackle" "calamities" "calamitous" ## [5] "calamitously" "calamity" "callous" "calumniate" ## [9] "calumniation" "calumnies" "calumnious" Всего 2006 позитивных и 4783 негативных слова. Раздел выше также показывает некоторые примеры слов из этих словарей.
Можно добавлять в словари новые слова или удалять существующие. С помощью кода ниже мы добавляем слово cloud в словарь positive и удаляем его из словаря negative.
positive=c(positive,"cloud") negative=negative[negative!="cloud"] Поиск по twitter-сообщениям
Следующий шаг — задать строку поиска по twitter-сообщениям и присвоить ее значение переменной, findfd. Количество твитов, которые будут использованы для анализа, присваивается другой переменной, number. Время на поиск по сообщениям и извлечение информации зависит от этого числа. Медленное соединение с Интернет или сложный поисковый запрос могут привести к задержкам.
findfd= "CyberSecurity" number= 5000 В коде выше используется строка «CyberSecurity» и 5000 твитов. Код для поиска по twitter:
tweet=searchTwitter(findfd,number)
## Time difference of 1.301408 mins Получение текста твитов
У твитов множество дополнительных полей и системной информации. Мы используем функцию gettext() для получения текстовых полей и присвоим получившийся список переменной tweetT. Функция применяется ко всем 5000 твитов. Код ниже также показывает результат выборки для первых пяти сообщений.
tweetT=lapply(tweet,function(t)t$getText()) head(tweetT,5)
## [[1]] ## [1] "RT @PCIAA: \"You must have realtime technology\" how do you defend against #Cyberattacks? @FireEye #cybersecurity http://t.co/Eg5H9UmVlY" ## ## [[2]] ## [1] "@MPBorman: #Cybersecurity on agenda for 80% corporate boards http://t.co/eLfxkgi2FT @CS
http://t.co/h9tjop0ete http://t.co/qiyfP94FlQ" ## ## [[3]] ## [1] "The FDA takes steps to strengthen cybersecurity of medical devices | @scoopit via @60601Testing http://t.co/9eC5LhGgBa" ## ## [[4]] ## [1] "Senior Solutions Architect, Cybersecurity, NYC-Long Island region, Virtual offic... http://t.co/68aOUMNgqy #job#cybersecurity" ## ## [[5]] ## [1] "RT @Cyveillance: http://t.co/Ym8WZXX55t #cybersecurity #infosec - The #DarkWeb As You Know It Is A Myth via @Wired http://t.co/R67Nh6Ck70" Функция очищения текста
На этом шаге напишем функцию, которая выполнит ряд команд и очистит текст: удалит знаки пунктуации, специальные символы, ссылки, дополнительные пробелы, цифры. Эта функция также приводит символы в верхнем регистре к нижнему, используя tolower(). Функция tolower() часто выдает ошибку, если встречает специальные символы, и выполнение кода останавливается. Чтобы этого не допустить, напишем функцию для перехвата ошибок, tryTolower, и используем ее в коде функции очищения текста.
tryTolower = function(x) { y = NA # tryCatch error try_error = tryCatch(tolower(x), error = function(e) e) # if not an error if (!inherits(try_error, "error")) y = tolower(x) return(y) } Функция clean() очищает твиты и разбивает строки на векторы слов.
clean=function(t){ t=gsub('[[:punct:]]','',t) t=gsub('[[:cntrl:]]','',t) t=gsub('\\d+','',t) t=gsub('[[:digit:]]','',t) t=gsub('@\\w+','',t) t=gsub('http\\w+','',t) t=gsub("^\\s+|\\s+$", "", t) t=sapply(t,function(x) tryTolower(x)) t=str_split(t," ") t=unlist(t) return(t) } Очищение и разбиение твитов на слова
На этом шаге мы применим функцию clean(), чтобы очистить 5000 твитов. Результат будет храниться в переменной-списке tweetclean. Нижеследующий код также показывает первые пять твитов, очищенных и разбитых на слова с помощью этой функции.
tweetclean=lapply(tweetT,function(x) clean(x)) head(tweetclean,5)
## [[1]] ## [1] "rt" "pciaa" "you" "must" ## [5] "have" "realtime" "technology" "how" ## [9] "do" "you" "defend" "against" ## [13] "cyberattacks" "fireeye" "cybersecurity" ## ## [[2]] ## [1] "mpborman" "cybersecurity" "on" "agenda" ## [5] "for" "" "corporate" "boards" ## [9] " " "cs" ## ## [[3]] ## [1] "the" "fda" "takes" "steps" ## [5] "to" "strengthen" "cybersecurity" "of" ## [9] "medical" "devices" "" "scoopit" ## [13] "via" "testing" ## ## [[4]] ## [1] "senior" "solutions" "architect" ## [4] "cybersecurity" "nyclong" "island" ## [7] "region" "virtual" "offic" ## [10] "" "jobcybersecurity" ## ## [[5]] ## [1] "rt" "cyveillance" "" "cybersecurity" ## [5] "infosec" "" "the" "darkweb" ## [9] "as" "you" "know" "it" ## [13] "is" "a" "myth" "via" ## [17] "wired" Анализ твитов
Мы добрались до фактической задачи анализа твитов. Сравниваем тексты твитов со словарями и находим совпадающие слова. Для того, чтобы это сделать, сначала зададим функцию для подсчета позитивных и негативных слов, совпадающих со словами из нашей базы. Вот код функции returnpscore для подсчета позитивных совпадений.
returnpscore=function(tweet) { pos.match=match(tweet,positive) pos.match=!is.na(pos.match) pos.score=sum(pos.match) return(pos.score) } Теперь применим функцию к списку tweetclean.
positive.score=lapply(tweetclean,function(x) returnpscore(x)) Следующий шаг — задать цикл для подсчета общего количества позитивных слов в твитах.
pcount=0 for (i in 1:length(positive.score)) { pcount=pcount+positive.score[[i]] } pcount
## [1] 1569 Как видно выше, в твитах 1569 позитивных слов. Аналогично можно найти количество негативных. Код ниже считает позитивные и негативные вхождения.
poswords=function(tweets){ pmatch=match(t,positive) posw=positive[pmatch] posw=posw[!is.na(posw)] return(posw) } Эта функция применяется к списку tweetclean, и в цикле слова добавляются в data frame, pdatamart. Код ниже показывает первые 10 вхождений позитивных слов.
words=NULL pdatamart=data.frame(words) for (t in tweetclean) { pdatamart=c(poswords(t),pdatamart) } head(pdatamart,10)
## [[1]] ## [1] "best" ## ## [[2]] ## [1] "safe" ## ## [[3]] ## [1] "capable" ## ## [[4]] ## [1] "tough" ## ## [[5]] ## [1] "fortune" ## ## [[6]] ## [1] "excited" ## ## [[7]] ## [1] "kudos" ## ## [[8]] ## [1] "appropriate" ## ## [[9]] ## [1] "humour" ## ## [[10]] ## [1] "worth" Аналогично создается ряд функций и циклов для подсчета негативных тональных слов. Эта информация записывается в другой data frame, ndatamart. Вот список первых десяти негативных слов в твитах.
head(ndatamart,10)
## [[1]] ## [1] "attacks" ## ## [[2]] ## [1] "breach" ## ## [[3]] ## [1] "issues" ## ## [[4]] ## [1] "attacks" ## ## [[5]] ## [1] "poverty" ## ## [[6]] ## [1] "attacks" ## ## [[7]] ## [1] "dead" ## ## [[8]] ## [1] "dead" ## ## [[9]] ## [1] "dead" ## ## [[10]] ## [1] "dead" Графики часто встречающихся негативных и позитивных слов
В этом разделе мы создадим некоторые графики, чтобы показать распределение часто встречающихся негативных и позитивных слов. Используем функцию unlist(), чтобы превратить списки в векторы. Векторные переменные pwords и nwords приводятся к data frame-объектам.
dpwords=data.frame(table(pwords)) dnwords=data.frame(table(nwords)) Используя пакет dplyr, нужно привести слова к переменным типа character и затем отфильтровать позитивные и негативные по частоте встречаемости (frequency > 15).
dpwords=dpwords%>% mutate(pwords=as.character(pwords))%>% filter(Freq>15) Выведем основные позитивные слова и их частоту с пмощью пакета ggplot2. Как видим, позитивных слов всего 1569. Функция распределения показывает степень позитивной тональности.
ggplot(dpwords,aes(pwords,Freq))+geom_bar(stat="identity",fill="lightblue")+theme_bw()+ geom_text(aes(pwords,Freq,label=Freq),size=4)+ labs(x="Major Positive Words", y="Frequency of Occurence",title=paste("Major Positive Words and Occurence in \n '",findfd,"' twitter feeds, n =",number))+ geom_text(aes(1,5,label=paste("Total Positive Words :",pcount)),size=4,hjust=0)+theme(axis.text.x=element_text(angle=45)) 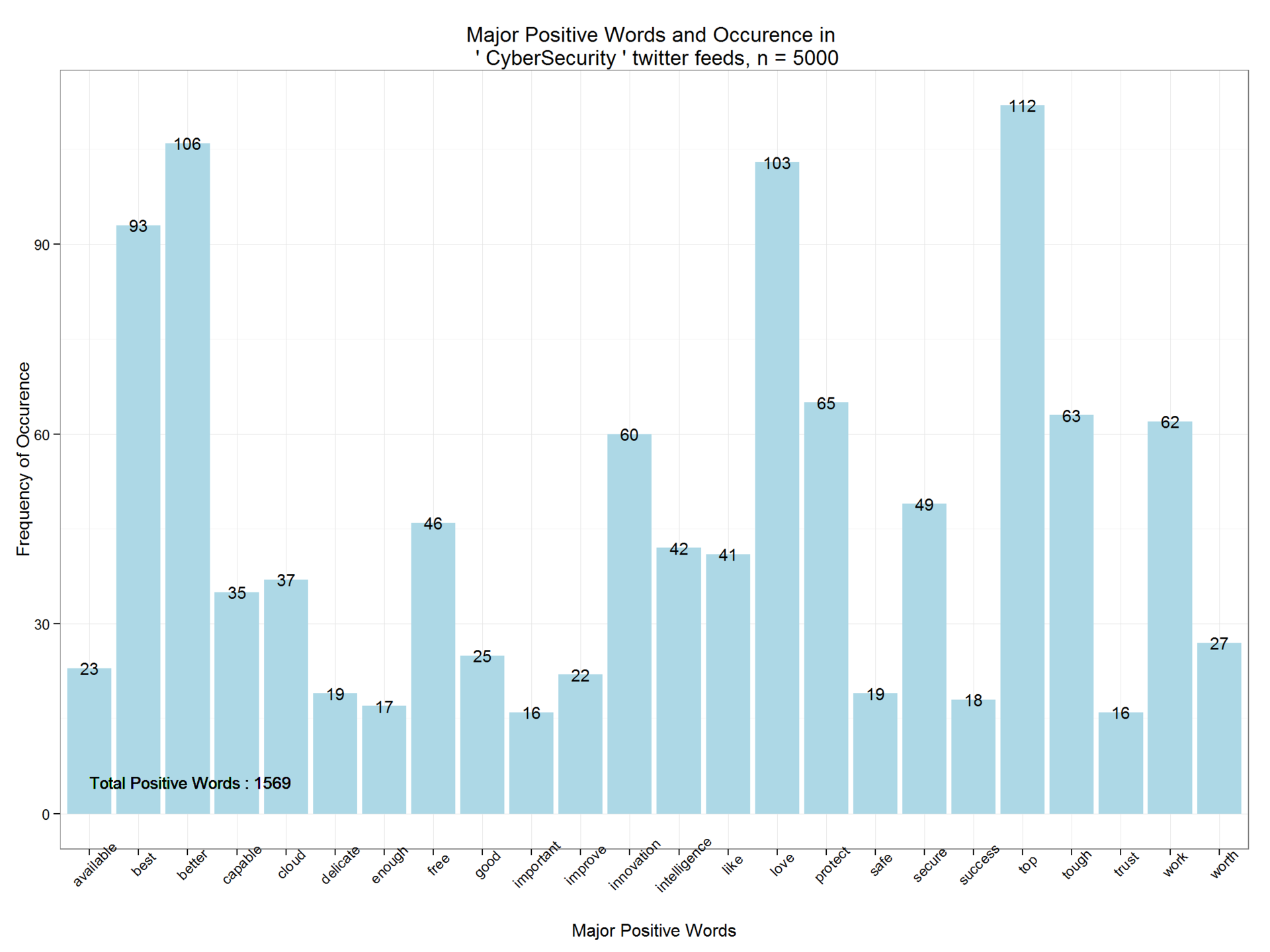
Аналогично, выведем негативные слова и их частоту. В 5000 твитов, содержащих поисковую строку «CyberSecurity», содержится 2063 негативных слова.
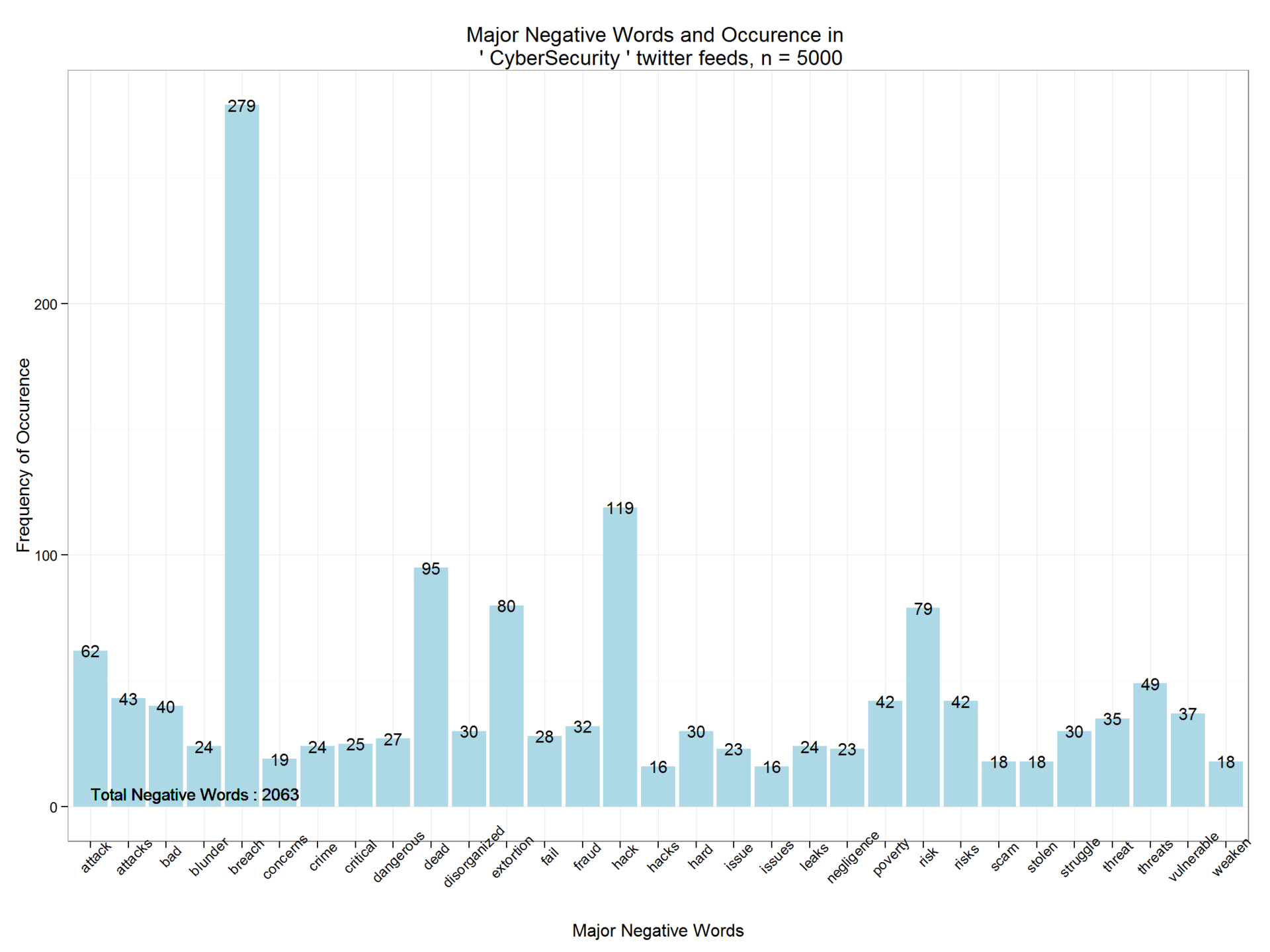
Удаление общих слов и создание облака слов
Превратим tweetclean в блок слов, используя функцию VectorSource. Представление в виде блока позволит удалить избыточные общие слова с помощью пакета интеллектуального анализа текста tm. Удаление общих слов, так называемых стоп-слов, поможет нам сосредоточиться на важных и выделить контекст. Код ниже выводит несколько примеров стоп-слов:
tweetscorpus=Corpus(VectorSource(tweetclean)) tweetscorpus=tm_map(tweetscorpus,removeWords,stopwords("english")) stopwords("english")[30:50]
## [1] "what" "which" "who" "whom" "this" "that" "these" ## [8] "those" "am" "is" "are" "was" "were" "be" ## [15] "been" "being" "have" "has" "had" "having" "do" Теперь создадим для твитов облако слов, используя пакет wordcloud. Обратите внимание, мы ограничиваем максимальное количество — 300.
wordcloud(tweetscorpus,scale=c(5,0.5),random.order = TRUE,rot.per = 0.20,use.r.layout = FALSE,colors = brewer.pal(6,"Dark2"),max.words = 300) 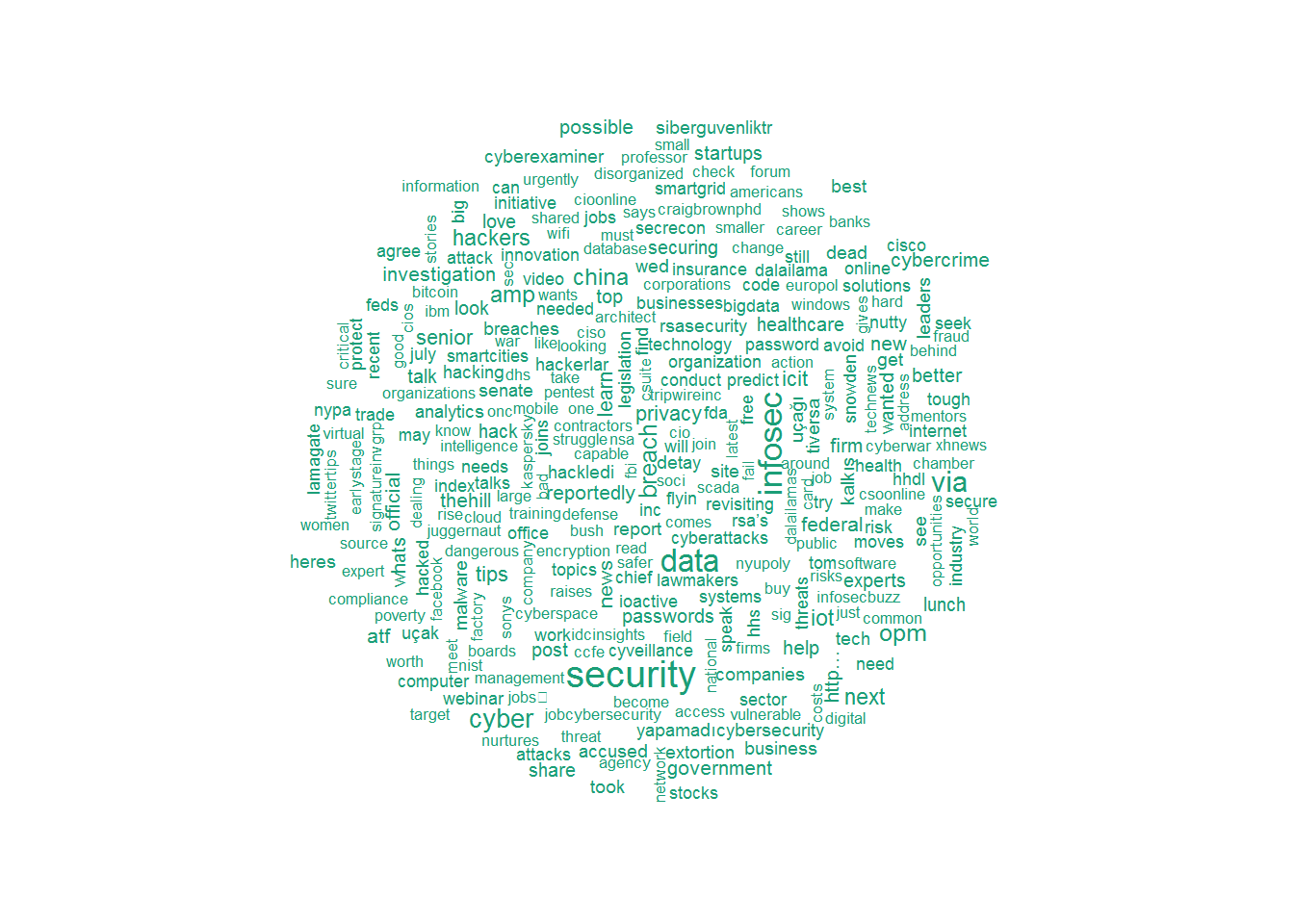
Анализ и построение графика часто встречающихся слов
На этом последнем шаге мы превращаем блок слов в матрицу документов функцией DocumentTermMatrix. Матрицу документов можно анализировать на предмет часто встречающихся нетипичных слов. Затем убираем из блока редкие слова (со слишком низкой частотой встречаемости). Код ниже выводит наиболее часто встречающиеся (с частотой 50 и выше).
dtm=DocumentTermMatrix(tweetscorpus) # #removing sparse terms dtms=removeSparseTerms(dtm,.99) freq=sort(colSums(as.matrix(dtm)),decreasing=TRUE) #get some more frequent terms findFreqTerms(dtm,lowfreq=100)
## [1] "amp" "atf" "better" "breach" ## [5] "china" "cyber" "cybercrime" "cybersecurity" ## [9] "data" "experts" "federal" "firm" ## [13] "government" "hackers" "hack" "healthcare" ## [17] "help" "heres" "http
" "icit" ## [21] "infosec" "investigation" "iot" "learn" ## [25] "look" "love" "lunch" "new" ## [29] "news" "next" "official" "opm" ## [33] "passwords" "possible" "post" "privacy" ## [37] "reportedly" "securing" "security" "senior" ## [41] "share" "site" "startups" "talk" ## [45] "thehill" "tips" "took" "top" ## [49] "via" "wanted" "wed" "whats" Наконец, приводим матрицу к data frame, фильтруем по Minimum frequency > 75 и строим график с помощью ggplot2:
wf=data.frame(word=names(freq),freq=freq) wfh=wf%>% filter(freq>=75,!word==tolower(findfd))
ggplot(wfh,aes(word,freq))+geom_bar(stat="identity",fill='lightblue')+theme_bw()+ theme(axis.text.x=element_text(angle=45,hjust=1))+ geom_text(aes(word,freq,label=freq),size=4)+labs(x="High Frequency Words ",y="Number of Occurences", title=paste("High Frequency Words and Occurence in \n '",findfd,"' twitter feeds, n =",number))+ geom_text(aes(1,max(freq)-100,label=paste("# Positive Words:",pcount,"\n","# Negative Words:",ncount,"\n",result(ncount,pcount))),size=5, hjust=0) 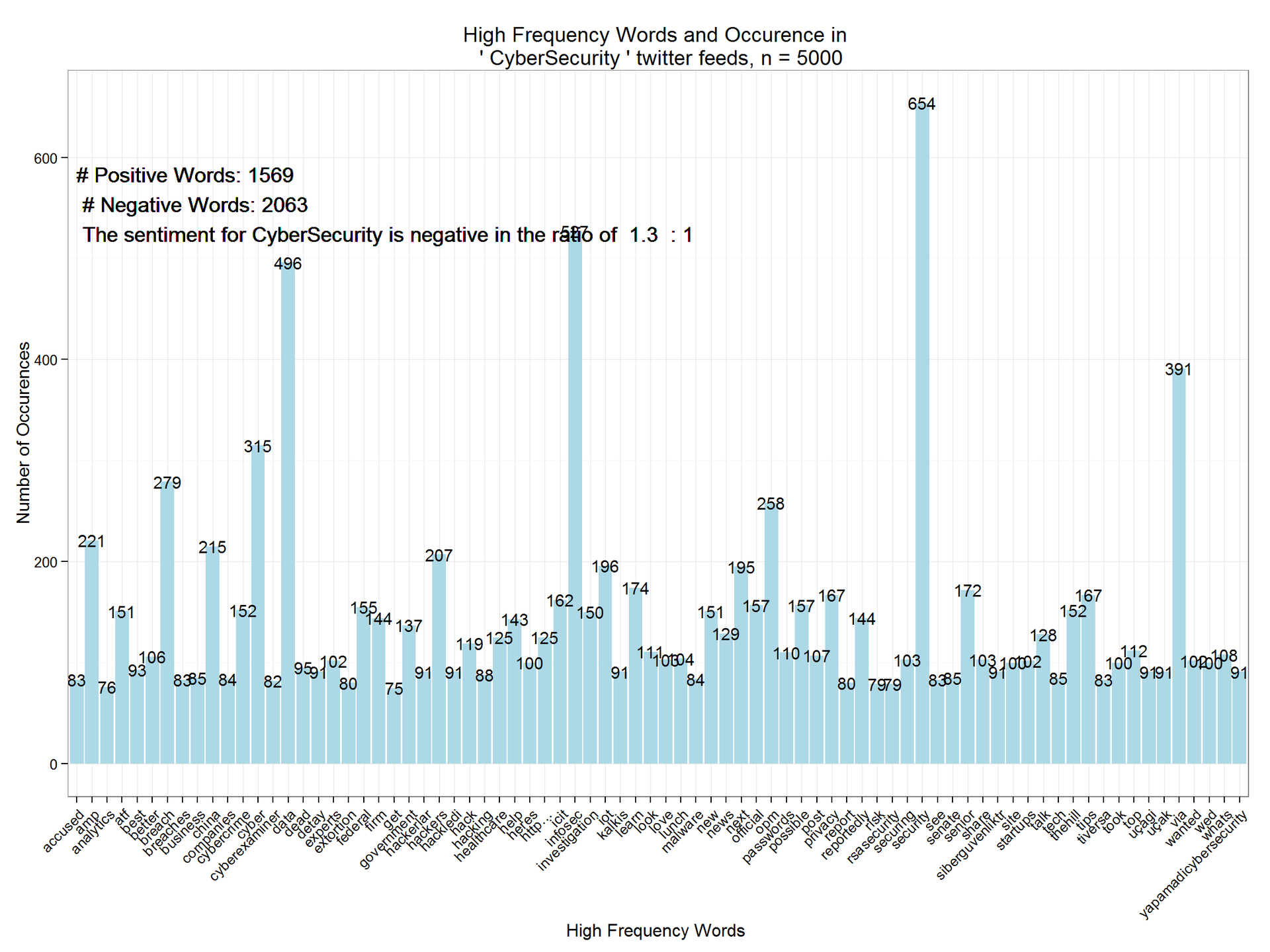
Выводы
Как видим, тональность CyberSecurity негативная с отношением 1,3: 1. Этот анализ можно расширить для нескольких временных промежутков с целью выделения трендов. Также можно осуществлять его итеративно, по близким темам, чтобы сравнить и проанализировать относительный рейтинг тональности.
ссылка на оригинал статьи http://habrahabr.ru/post/261589/
Добавить комментарий