В Grammary основа нашего бизнеса — центральный языковой движок, он написан на Common Lisp. Сейчас движок обрабатывает более чем тысячу предложений в секунду, масштабируется горизонтально и надежно служит нам в продакшене почти 3 года.
Мы заметили, что почти нет постов о развертывании Lisp софта в современной облачной инфраструктуре, поэтому мы решили что поделиться нашим опытом идеей будет хорошей идеей. Рантайм и среда программирования Lisp’а предоставляют несколько уникальных, немного непривычных, возможностей для поддержки продакшн систем (для нетерпеливых — они описаны в последней части).
Wut Lisp?!!

Вопреки распространенному мнению, Lisp это невероятно практичный язык для создания продакшн систем. Вобще говоря, вокруг нас много Lisp-систем: когда вы ищите авиа-билет на Hipmunk или едете на метро в Лондоне, используются Lisp-программы.
Наши Lisp-сервисы концептуально представляют собой классическое ИИ-приложение, которое функционирует на огромной куче знаний, созданных лингвистами и исследователями. Его главный используемый ресурс это ЦПУ, и это один из крупнейших потребителей вычислительных ресурсов в нашей сети.
Система работает на обычных образах Линукс, развернутых в AWS. Мы используем SBCL для продакшена и CCL на большинстве машин разработчиков. Один из приятных моментов при использовании Lisp’а — вы имеете возможность выбора из нескольких развитых реализаций с различными плюсами и минусами: в нашем случае мы оптимизировали скорость работы на сервере и скорость сборки при разработке (почему это критично для нас описано далее).
A stranger in a strange land

There is a cost to maintenance, but we value choice and freedom over rules and processes.
В Grammarly мы используем множество языков программирования для разработки наших сервисов: кроме языков для JVM и Javascript’а мы так пишем на Erlang, Python и Go. Должная инкапсуляция сервисов позволяет нам использовать тот язык или платформу, который лучше всего подходит для задачи. Такой подход имеет определенную цену в обслуживании, но мы ценим выбор и свободу больше чем правила и процессы.
Мы так же стараемся опираться на простые, не завязанные на языки, инфраструктурные утилиты. Такой подход освобождает нас от множества проблем при интеграции всего этого зоопарка технологий в нашей платформе. Например, statsd отличный пример невероятно простого и полезного сервиса, который очень легко использовать. Другой — Graylog2, он предоставляет шикарную спецификацию для логирования, и несмотря на то, что не было готовой библиотеки для работы с ним из CL, ее было очень легко собрать из того, что доступно в Lisp-экосистеме. Вот весь код, который нужен (и практически весь он просто слово в слово перевод спецификации):
(defun graylog (message &key level backtrace file line-no) (let ((msg (salza2:compress-data (babel:string-to-octets (json:encode-json-to-string #{ :version "1.0" :facility "lisp" :host *hostname* :|short_message| message :|full_message| backtrace :timestamp (local-time:timestamp-to-unix (local-time:now)) :level level :file file :line line-no }) :encoding :utf-8) 'salza2:zlib-compressor))) (usocket:socket-send (usocket:socket-connect *graylog-host* *graylog-port* :protocol :datagram :element-type '(unsigned-byte 8)) msg (length msg)))) Отсутствие библиотек в экосистеме одна из частых претензий к Lisp’у. Как видите, 5 библиотек использованы только в этом примере для таких вещей как кодирование, сжатие, получение Unix-времени и сокет соединения.
Lisp-библиотеки действительно существуют, но, как и во всех интеграциях библиотек, мы сталкиваемся с проблемами. Для примера, чтобы подключить Jenkins CI нам пришлось использовать xUnit и было не очень просто найти спецификации для него. К счастью этот туманный вопрос на Stackoverflow помог — в итоге мы встроили его в свою собственную библиотеку тестирования should-test.
but we had to spend much more time upgrading our AMIs to support the current version of the C library.
Еще один пример — использование HDF5 для обмена моделями машинного обучения: мы потратили некоторое время на адаптацию низкоуровневой библиотеку hdf5-cffi для наших реалий, но нам пришлось потратить намного больше времени на обновление наших AMIs для поддержки текущей версии C библиотеки.
Другой принцип, которому мы следуем в платформе Grammarly — это максимальная декомпозиция различных сервисов для обеспечения горизонтальной масштабируемости и функциональной независимости — про это пост моего коллеги. Таким образом нам не нужно взаимодействовать с базами данных в критических частях наших главных сервисов. Однако, мы используем MySQL, Postgres, Redis и Mongo для внутреннего хранилища и мы успешно воспользовались CLSQL, postmodern, cl-redis и cl-mongo для доступа к ним из Lisp’а.
We rely on Quicklisp for managing external dependencies and a simple system of bundling library source code with the project for our internal libraries or forks.
Мы используем Quicklisp для управления внешними зависимостями и простую систему комплектации исходного кода библиотек с проектом для внутреннего использования и форков. Репозиторий Quicklisp содержит более 1000 Lisp-библиотек, не супер огромное число, но вполне достаточное для удовлетворения всех потребностей нашего продакшена.
Для развертывания в продакшене мы используем универсальный стек: приложение тестируется и собирается с помощью Jenkins, доставляется на сервера благодаря Rundeck и запускается там через Upstart как обычный Unix-процесс.
В целом проблемы, с которыми мы сталкиваемся при интеграции Lisp-приложений в облачный мир радикально не отличаются от тех, которые мы встречаем во множестве других технологий. Если вы хотите использовать Lisp в продакшене и испытывать удовольствие от написания Lisp-кода, нет ни одной реальной технической причины не делать этого!
The hardest bug I’ve ever debugged

Как бы ни была идеальна эта история, не все только про радуги и единорогов.
Мы создали эзотерическое приложение (даже по меркам Lisp-мира) и в процессе уперлись в некоторые ограничения платформы. Одной такой неожиданностью было исчерпание стека во время компиляции. Мы очень сильно полагаемся на макросы и самые большие из них раскрываются в тысячи строчек низкоуровневого кода. Оказалось что компилятор SBCL реализует множество оптимизаций, благодаря которым мы радуемся довольно быстрому сгенерированному коду, но некоторые из них требуют экспотенциальных времени и памяти. К сожалению нет способа выключить или отрегулировать их. Несмотря на это, существует известное общее решение, стиль call-with-*, которое позволяет пожертвовать немного эффективности ради лучшей модульности (что оказалось решающим в нашем случае) и отлаживаемости.
but we run it with 25G heap size which automatically results in a huge volume for the nursery.
Менее неожиданным чем приручение компилятора оказался регулировка GC для улучшения задержек и утилизации ресурсов в нашей системе. SBCL предоставляет достойный, сборщик мусора, основанный на поколениях, хотя и не настолько изощренный как в JVM. Нам пришлось настроить размеры поколений и оказалось, что лучшим вариантом было использование кучи огромного размера: наше приложение потребляло 2-4 гигабайта памяти, но мы запустили его с 25G кучи, что автоматически привело к ????.. Еще одно настройка, которую нам пришлось сделать, гораздо менее очевидная, была запуском GC программно каждые N минут. С огромной кучей мы заметили постепенное наращивание использования памяти за периоды в десятки минут, из-за чего все больше времени тратилось на GC и уменьшалась производительность приложения. Наш подход с периодическим GC привел систему в более стабильное состояние с практически константным потреблением памяти. С лева видно как выполняется система без наших настроек, а справа — эффект периодического GC.
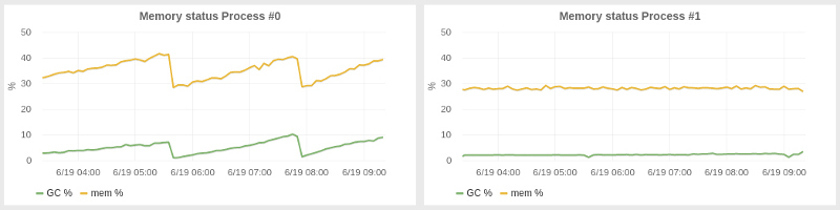
Из всех этих трудностей, худшим багом, что я встречал был сетевой баг. Как обычно бывает в таких ситуациях, баг был не в приложении, а в нижележащей платформе (в этот раз — SBCL). И, более того, я напоролся на него дважды в двух разных сервисах, но в первый раз я не смог вычислить его, так что пришлось его обойти.
Когда мы только начинали запуск нашего сервиса на существенных нагрузках в продакшене, после некоторого времени нормального функционирования все сервера внезапно начинали замедляться и в конце концов становились недоступны. После длительного расследования с подозрением на входные данные, мы обнаружили что проблема была в гонке в низкоуровневом сетевом коде SBCL, конкретно в способе вызова функции сокета — getprotobyname, которая не была потокобезопасной. Это была очень маловероятная гонка, так что она проявляла себя только в высоконагруженном сетевом сервисе, когда эта функция вызывалась десятки тысяч раз. Это выбивало один рабочий поток за другим, постепенно вводя систему в кому.
Вот фикс, на котором мы остановились, к сожалению, его нельзя использовать в более широком контексте как библиотеку. (Баг был отправлен к команде SBCL и был исправлен, но мы все еще используем этот хак, на всякий случай 🙂
#+unix (defun sb-bsd-sockets:get-protocol-by-name (name) (case (mkeyw name) (:tcp 6) (:udp 17))) Back to the future

Системы Common Lisp реализуют множество идей почтенных Lisp-машин. Одна из наиболее выдающихся это интерактивное окружение SLIME. Пока индустрия ожидает созревания LightTable и ему подобного, Lisp-программисты тихо и высокомерно наслаждаются такими возможностями в SLIME много лет. Узрите мощь этой до зубов вооруженной и функционирующей боевой станции в действии.
Но SLIME это не просто подход Lisp’а к IDE. Будучи клиент-серверным приложением, оно позволяет запускать свой бэкенд на удаленной машине и подключаться к ней из вашего локального Emacs (или Vim, если у вас нет выбора, с SLIMV). Программисты Java могут подумать о JConsole, но тут вы не скованы предопределенным набором операций и можете производить любую интроспекцию или изменение какое только захотите. Мы бы не смогли отловить гонку в функции сокета без этих возможностей.
Более того, удаленная консоль не единственная полезная утилита предоставляемая SLIME. Как множество IDE она имеет возможность перемещаться в исходный код функций, но в отличие от Java или Python, у меня на машине есть исходный код SBCL, так что я часто просматриваю исходные коды реализации, и это помогает выяснять что происходит гораздо лучше. Для случая с сокетным багом это так же было важной частью процесса отладки.
Наконец, еще одна супер полезная утилита для интроспекции и дебага, которой мы пользуемся — TRACE. Она полностью изменила мой подход к отладке: от нудной местной пошаговости к анализированию большей картины. Она так же была инструментом прибивания нашего мерзкого бага.
С trace вы указываете функцию для трассировки, выполняете код, и Lisp печатает все вызовы этой функции и ее аргументы и все результаты которые она возвращает. Это что-то похожее на трейс стека, но вам не нужен полный стек и вы динамически получаете поток трассировок, без остановки приложения. trace это как print на стероидах который позволяет вам быстро проникнуть во внутренности кода произвольной сложности и мониторить сложнейшие пути выполнения. Единственный недостаток — нельзя трейсить макросы.
Вот фрагмент трейсинга, который я сделал буквально сегодня, чтобы убедиться что JSON-запрос к одному из наших сервисов формируется корректно и возвращает нужный результат:
0: (GET-DEPS ("you think that's bad, hehe, i remember once i had an old 100MHZ dell unit i was using as a server in my room")) 1: (JSON:ENCODE-JSON-TO-STRING #<HASH-TABLE :TEST EQL :COUNT 2 {1037DD9383}>) 2: (JSON:ENCODE-JSON-TO-STRING "action") 2: JSON:ENCODE-JSON-TO-STRING returned "\"action\"" 2: (JSON:ENCODE-JSON-TO-STRING "sentences") 2: JSON:ENCODE-JSON-TO-STRING returned "\"sentences\"" 1: JSON:ENCODE-JSON-TO-STRING returned "{\"action\":\"deps\",\"sentences\":[\"you think that's bad, hehe, i remember once i had an old 100MHZ dell unit i was using as a server in my room\"]}" 0: GET-DEPS returned ((("nsubj" 1 0) ("ccomp" 9 1) ("nsubj" 3 2) ("ccomp" 1 3) ("acomp" 3 4) ("punct" 9 5) ("intj" 9 6) ("punct" 9 7) ("nsubj" 9 8) ("root" -1 9) ("advmod" 9 10) ("nsubj" 12 11) ("ccomp" 9 12) ("det" 17 13) ("amod" 17 14) ("nn" 16 15) ("nn" 17 16) ("dobj" 12 17) ("nsubj" 20 18) ("aux" 20 19) ("rcmod" 17 20) ("prep" 20 21) ("det" 23 22) ("pobj" 21 23) ("prep" 23 24) ("poss" 26 25) ("pobj" 24 26))) ((<you 0,3> <think 4,9> <that 10,14> <'s 14,16> <bad 17,20> <, 20,21> <hehe 22,26> <, 26,27> <i 28,29> <remember 30,38> <once 39,43> <i 44,45> <had 46,49> <an 50,52> <old 53,56> <100MHZ 57,63> <dell 64,68> <unit 69,73> <i 74,75> <was 76,79> <using 80,85> <as 86,88> <a 89,90> <server 91,97> <in 98,100> <my 101,103> <room 104,108>)) Так, для отладки нашего ужасного сокетного бага мне пришлось закопаться глубоко в сетевой код SBCL и изучить вызываемые функции, затем подключиться по SLIME к умирающему серверу и пробовать трейсить эти функции одну за другой. И когда я получил вызов, который не вернулся — это было оно. В итоге, после выяснение в мануале того, что функция не является потокобезопасной и встречи нескольких упоминаний про это в комментариях в исходниках SBCL я убедился в этой гипотезе.
Это показывает что Lisp доказал, что является удивительно надежной платформой для одного из наших самых критичных проектов. Он довольно хорошо соответствует общим требованиями современной облачной инфраструктуры, и несмотря на то, что этот стек не очень широко известен и популярен, он имеет свои сильные стороны — вам нужно только научиться использовать их. Не считая мощи Lisp-подхода к решению сложных задач, за который мы его так любим. Но это уже совершенно другая история…
ссылка на оригинал статьи http://habrahabr.ru/post/262153/
Добавить комментарий