В этой статье я опишу установку и настройку Active/Active кластера на основе Pacemaker, Corosync 2.x и CLVM с использованием разделяемого хранилища. Покажу, как приспособить этот кластер для работы с контейнерами LXC и Docker. Опишу команды для работы с кластером. И припомню те грабли, в которые вляпался, что, надеюсь, облегчит судьбу следующим проходимцам.
В качестве серверных дистрибутивов буду использовать CentOS 7 + epel и актуальные версии пакетов в них. Основной инструмент для работы с Pacemaker-ом будет PCS (pacemaker/corosync configuration system).

- Подготовка серверов
- Установка и базовая настройка Pacemaker и CLVM
- Работа с LXC в кластере
- Переносим контейнер OpenVZ в LXC
- Работа с Docker-ом в кластере
- Шпаргалка
- Ссылки
Подготовка серверов
Я использовал конфигурацию из двух узлов, но их количество можно увеличивать по мере надобности. Сервера имеют общее разделяемое хранилище, подключённое по SAS. Если такого под рукой не найдётся, то можно использовать хранилище подключаемое FC или iSCSI. Потребуются два тома, один для общих нужд, другой для Docker-а. Можно один том разбить на два раздела.
Устанавливаем CentOS 7, epel репозиторий и настраиваем сеть. Использование bonding-а для сетевых интерфейсов и multipath для SAS желательны. Для работы с различными vlan-ми настраиваем соответствующие мосты br0.VID, к которым потом будем привязывать контейнера LXC. Подробности описывать не буду – всё стандартно.
Для работы LXC и Docker нужно отключить штатный firewald.
# systemctl stop firewalld.service # systemctl disable firewalld.service # setenforce Permissive Так же переводим selinux в режим permissive, для облегчения настройки и смелых экспериментов. Позже, когда отладим, переключим назад, может быть.
Сразу же внесём необходимые адреса и имена в /etc/hosts на всех узлах:
#nodes, vlan 10 10.1.0.1 cluster-1 10.1.0.2 cluster-2 #nodes ipmi, vlan 314 10.1.15.1 ipmi-1 10.1.15.2 ipmi-2 #docker, vlan 12 10.1.2.10 docker 10.1.2.11 dregistry Для работы будет необходим механизм STONITH («Shoot The Other Node In The Head»), в качестве которого используем ipmi. Настраиваем с помощью ipmitool:
# ipmitool shell impitool> user set name 2 admin impitool> user set password 2 'очень секретный пароль' # <uid> < privilege level> <channel number>) impitool> user priv 2 4 1 Заводим пользователя admin (id=2) и даём ему права администратора (livel=4) на канал связанный с сетевым интерфейсом (channel=1).
Сеть для ipmi желательно вынести в отдельный vlan, во первых это позволит её изолировать, во вторых не будет проблем со связностью, если IPMI BMC (baseboard management controller) разделяет сетевой интерфейс с сервером.
impitool> lan set 1 ipsrc static impitool> lan set 1 ipaddr 10.1.15.1 impitool> lan set 1 netmask 255.255.255.0 impitool> lan set 1 defgw ipaddr 10.1.15.254 impitool> lan set 1 vlan id 314 # настройка доступа: impitool> lan set 1 access on impitool> lan set 1 auth ADMIN MD5 ipmitool> channel setaccess 1 2 callin=on ipmi=on link=on privilege=4 На других узлах аналогично, только IP разные.
Проверь связность можно так:
# ipmitool -I lan -U admin -P 'очень секретный пароль' -H 10.1.15.1 bmc info
Установка и базовая настройка Pacemaker и CLVM
Если вы не знаете что такое Pacemaker, то желательно сначала почитать про него. Хорошо и по русски про Pacemaker написано тут.
На всех узлах устанавливаем пакеты из epel репозитория:
# yum install pacemaker pcs resource-agents На всех узлах устанавливаем пароль для администратора кластера hacluster. Под этим пользователем работает PCS, а так же доступен веб-интерфейс управления.
echo CHANGEME | passwd --stdin hacluster Дальше операции выполняются на одном узле.
Настраиваем аутентификацию:
# pcs cluster auth cluster-1 cluster-2 -u hacluster -p CHANGEME --force Создаём и запускаем кластер “Cluster” из двух узлов:
# pcs cluster setup --force --name Cluster cluster-1 cluster-2 # pcs cluster start --all Смотрим результат:
# pcs cluster status Cluster Status: Last updated: Wed Jul 8 14:16:32 2015 Last change: Wed Jul 8 10:01:20 2015 Stack: corosync Current DC: cluster-1 (1) - partition with quorum Version: 1.1.12-a14efad 2 Nodes configured 17 Resources configured (всё ещё впереди) PCSD Status: cluster-1: Online cluster-2: Online Есть один нюанс, если в переменных окружения задан https_proxy, то pcs может врать о статусе узлов, видимо пытаясь использовать проксю.
Запускаем и прописываем в автозагрузку демон pcsd:
# systemctl start pcsd # systemctl enable pcsd После этого доступен веб-интерфейс управления кластером по адресу "https://ip_узла:2224"
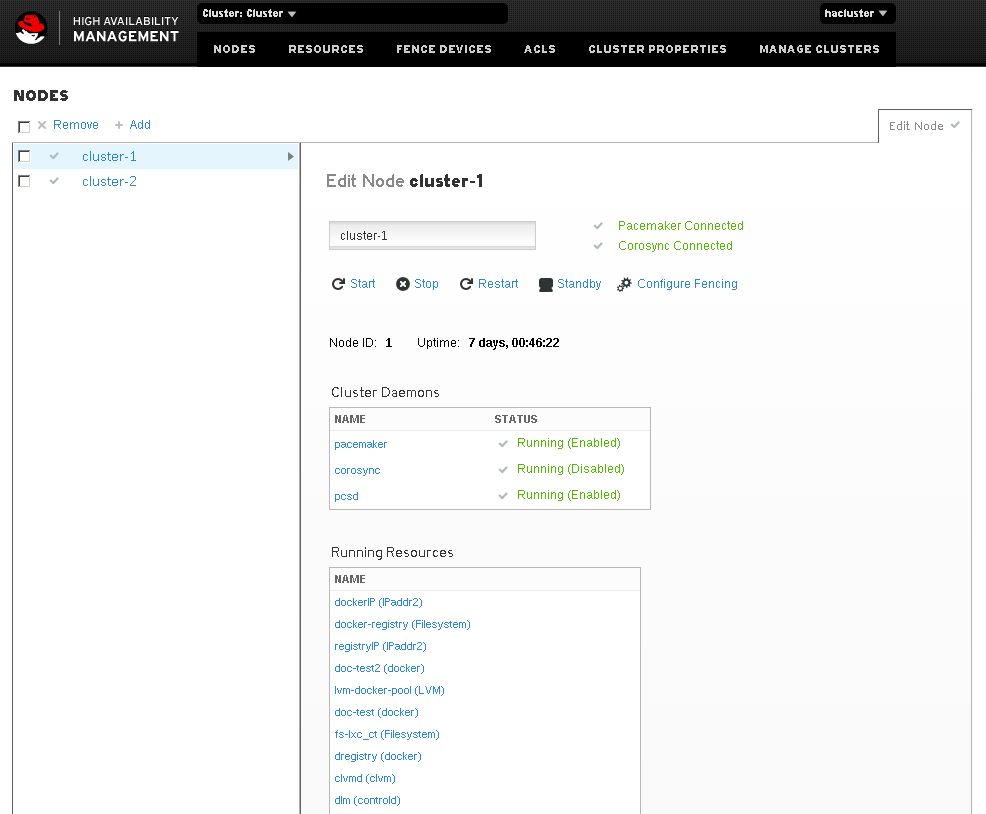
Интерфейс позволит посмотреть состояние кластера, добавить или изменить его параметры. Мелочь, а приятно.
Так как узла у нас всего два, то кворума у нас не будет, потому нужно эту политику отключить:
# pcs property set no-quorum-policy=ignore Для авто-запуска узлов кластера достаточно добавить в автозагрузку pacemaker:
# systemctl enable pacemaker Для работы CLVM и GFS2 необходим DLM (Distributed Lock Manager). И CLVM и DLM в RHEL7 (CentOS 7) как самостоятельные демоны отсутствуют и являются ресурсами кластера. При этом для работы DLM требуется STONITH, иначе соответствующий ресурс кластера не запустится. Настраиваем:
# pcs property set stonith-enabled=true # pcs stonith create cluster-1.stonith fence_ipmilan ipaddr="ipmi-1" passwd="пароль на ipmi" login="admin" action="reboot" method="cycle" pcmk_host_list=cluster-1 pcmk_host_check=static-list stonith-timeout=10s op monitor interval=10s # pcs stonith create cluster-2.stonith fence_ipmilan ipaddr="ipmi-2" passwd="пароль на ipmi" login="admin" action="reboot" method="cycle" pcmk_host_list=cluster-2 pcmk_host_check=static-list stonith-timeout=10s op monitor interval=10s # pcs constraint location cluster-1.stonith avoids cluster-1=INFINITY # pcs constraint location cluster-2.stonith avoids cluster-2=INFINITY Почему так, хорошо описано тут. Если вкратце, то заводим два stonith ресурса, каждый отвечающий за свой узел и запрещаем им работать на узле, который они должны пристреливать.
Настроим дополнительные глобальные параметры.
Для экспериментов, полезно настроить миграцию ресурсов после первого сбоя:
# pcs resource defaults migration-threshold=1 Чтобы ресурс, мигрировавший на другой узел в результате сбоя, не возвращался назад, по восстановлении узла выставим:
# pcs resource defaults resource-stickiness=100 Где «100» это некий вес, на основе которого Pacemaker рассчитывает поведение ресурса.
Чтобы в разгар смелых экспериментов узлы не перестреляли друг друга, рекомендую явно задать политику на отказ ресурса:
# pcs resource op defaults on-fail=restart Иначе на самом интересном месте сработает stonith, который по умолчанию на отказ команды «stop».
Устанавливаем CLVM на каждом узле:
# yum install lvm2 lvm2-cluster Настраиваем LVM для работы в кластере на каждом узле:
# lvmconf --enable-cluster Заводим ресурсы dlm и clvmd в кластере:
# pcs resource create dlm ocf:pacemaker:controld op monitor interval=30s on-fail=fence clone interleave=true ordered=true # pcs resource create clvmd ocf:heartbeat:clvm op monitor interval=30s on-fail=fence clone interleave=true ordered=true Это критичные ресурсы для нашего кластера, потому для ситуации сбоя явно задаём политику stonith (on-fail=fence). Ресурс должен быть запущен на всех узлах кластера, потому он объявляется клонированным (clone). Запускаем ресурсы по очереди, а не параллельно (ordered=true). Если ресурс зависит от других clone-ресурсов, то не ждём запуска всех образцов ресурса на всех узлах, а довольствуемся локальным (interleave=true). Обратите внимание на последние два параметра, они могут существенно отразится на работе кластера в целом, а clone-ресурсы у нас ещё будут.
Задаём порядок запуска ресурсов, при котором clvmd запускается только после dlm. В командах используется уже служебное имя *-clone, которое обозначает ресурс на конкретном узле:
# pcs constraint order start dlm-clone then clvmd-clone # pcs constraint colocation add clvmd-clone with dlm-clone Так же обязываем запускать ресурс clvmd-clone вместе с dlm-clone на одном узле. В нашем случае двух узлов это кажется излишним, но в общем случае *-clone ресурсов может быть меньше, чем количество узлов и тогда совместное расположение становится критичным.
Сразу же по созданию ресурсов они запускаются на всех узлах, и если всё хорошо, то можем приступать к созданию разделяемых логических томов и файловых систем. clvmd проследит за целостностью метаданных и оповестит об изменениях все узлы, потому операцию проделываем на одном узле.
Инициализируем разделы для использования в LVM:
# pvcreate /dev/mapper/mpatha1 # pvcreate /dev/mapper/mpatha2 Вообще, работа с кластерным LVM почти не отличается от работы с обычным, с той лишь разницей, что если группа томов (VG) помечена как кластерная, то её метаданные контролирует clvmd. Создаём группы томов:
# vgcreate --clustered y shared_vg /dev/mapper/mpatha1 # vgcreate --clustered y shared_vg-ex /dev/mapper/mpatha2 Общая настройка кластера завершена, дальше будем его наполнять ресурсами. Ресурс с точки зрения Pacemaker-а, это любая служба, процесс, ip-адрес работой которого можно управлять скриптами. Сами ресурс-скрипты похожи на init-скрипты и так же выполняют набор функций start, stop, monitor и тп. Основной принцип, которому мы будем следовать – данные необходимые ресурсу, работающему на одном узле, помещаем в логический раздел группы shared_vg и любую файловую систему по желанию; данные, которые необходимы на обоих узлах одновременно, помещаем на GFS2. За целостностью данных в первом случае проследит Pacemaker, который контролирует количество и расположение запущенных ресурсов, включая используемые файловые системы. Во втором случае внутренние механизмы GFS2. Группа shared_vg-ex будет полностью отдана под логический раздел для Docker-а. Дело в том, что Docker создаёт разреженный том (thin provisioned), который может быть активен только в эксклюзивном режиме на одном узле. А поместить этот том в отдельную группу удобно для дальнейшей работы и настройки.
Работа с LXC в кластере
Работать будем используя утилиты lxc-*, которые входят в пакет lxc. Ставим:
# yum install lxc lxc-templates Настаиваем параметры по умолчанию для будущих контейнеров:
# cat /etc/lxc/default.conf lxc.start.auto = 0 lxc.network.type = veth lxc.network.link = br0.10 lxc.network.flags = up # memory and swap lxc.cgroup.memory.limit_in_bytes = 256M lxc.cgroup.memory.memsw.limit_in_bytes = 256M Тип сети будет veth – внутри контейнера интерфейс eth0, вне контейнера он будет прицеплен к мосту br0.10. Из ограничений у нас в ходу только по памяти, их и укажем. При желании можно прописать любые, поддерживаемые ядром, по принципу lxc.cgroup.state-object-name=value. Так же их можно менять на лету с помощью lxc-cgroup. На файловой системе эти параметры представлены по пути /sys/fs/cgroup/TYPE/lxc/CT-NAME/object-name.
Размещением, запуском и остановкой контейнеров будет управлять Pacemaker, потому автозагрузку контейнеров выключаем явно.
Каждый LXC контейнер будет жить в своём логическом томе группы shared_vg. Настроим имя VG по умолчанию:
# cat /etc/lxc/lxc.conf lxc.bdev.lvm.vg = shared_vg Такое размещение позволит запускать контейнер на любом узле кластера. Файлы конфигурации контейнеров тоже должны быть общие, по этому создадим общую файловую систему и настроим её использование на всех узлах:
# lvcreate -L 500M -n lxc_ct shared_vg # mkfs.gfs2 -p lock_dlm -j 2 -t Cluster:lxc_ct /dev/shared_vg/lxc_ct Выбираем протокол блокировок lock_dlm, так как хранилище общее. Заводим два журнала, по количеству узлов (-j2). Настраиваем имя в таблице блокировок, где Cluster — имя нашего кластера.
# pcs resource create fs-lxc_ct Filesystem fstype=gfs2 device=/dev/shared_vg/lxc_ct directory=/var/lib/lxc clone ordered=true interleave=true # pcs constraint order start clvmd-clone then fs-lxc_ct-clone Заводим очередной clone-ресурс, типа Filesystem, поля device и directory обязательны и описывают что примонтировать и куда. И указываем порядок запуска ресурса, так как без clvmd файловая система не примонтируется. После этого, на всех узлах директория, где LXC хранит настройки контейнеров, примонтируется.
Создадим первый контейнер:
# lxc-create -n lxc-racktables -t oracle -B lvm --fssize 2G --fstype ext4 --vgname shared_vg -- -R 6.6 Здесь lxc-racktables — имя контейнера, oracle – используемый шаблон. -B определяет тип используемого хранилища и параметры. lxc-create создаст LVM раздел и развернёт туда базовую систему, согласно шаблону. После "—" указываются параметры шаблона, в моём случае — версия.
На момент написания статьи шаблон из пакета для centos на lvm не работал, но меня устроил и oracle.
Если нужно развернуть систему на базе deb пакетов, то сначала необходимо поставить утилиту debootstrap. Подготовленная система сначала разворачивается в /var/cache/lxc/ и при каждом последующем запуске lxc-create обновляет пакеты системы до текущих версий. Для себя удобно собрать собственный шаблон, со всеми нужными предустановками. Стандартные шаблоны находятся тут: /usr/share/lxc/templates.
Так же можно использовать специальный шаблон "download", который скачивает из репозитория уже подготовленные архивы систем.
Контейнер готов. Управлять контейнерами можно утилитами lxc-*. Запускаем в фоне, смотрим его состояние, останавливаем:
# lxc-start -n lxc-racktables -d # lxc-info -n lxc-racktables Name: lxc-racktables State: RUNNING PID: 9364 CPU use: 0.04 seconds BlkIO use: 0 bytes Memory use: 1.19 MiB KMem use: 0 bytes Link: vethS7U8J1 TX bytes: 90 bytes RX bytes: 90 bytes Total bytes: 180 bytes # lxc-stop -n lxc-racktables Настраиваем дополнительные параметры контейнера либо в его консоли с помощью lxc-console, либо примонтировав куда-нибудь lvm раздел контейнера.
Теперь можно отдать управление Pacemaker-у. Но сначала возьмём свежий ресурс-файл управления с GitHub-а:
# wget -O /usr/lib/ocf/resource.d/heartbeat/lxc https://raw.githubusercontent.com/ClusterLabs/resource-agents/master/heartbeat/lxc # chmod +x /usr/lib/ocf/resource.d/heartbeat/lxc Директория /usr/lib/ocf/resource.d/ содержит файлы управления ресурсами в иерархии provider/type. Посмотреть весь список ресурсов можно командой pcs resource list. Посмотреть описание определённого ресурса — pcs resource describe <standard:provider:type|type>.
# pcs resource describe ocf:heartbeat:lxc ocf:heartbeat:lxc - Manages LXC containers Allows LXC containers to be managed by the cluster. If the container is running "init" it will also perform an orderly shutdown. It is 'assumed' that the 'init' system will do an orderly shudown if presented with a 'kill -PWR' signal. On a 'sysvinit' this would require the container to have an inittab file containing "p0::powerfail:/sbin/init 0" I have absolutly no idea how this is done with 'upstart' or 'systemd', YMMV if your container is using one of them. Resource options: container (required): The unique name for this 'Container Instance' e.g. 'test1'. config (required): Absolute path to the file holding the specific configuration for this container e.g. '/etc/lxc/test1/config'. log: Absolute path to the container log file use_screen: Provides the option of capturing the 'root console' from the container and showing it on a separate screen. To see the screen output run 'screen -r {container name}' The default value is set to 'false', change to 'true' to activate this option
Итак, добавляем в наш кластер новый ресурс:
# pcs resource create lxc-racktables lxc container=lxc-racktables config=/var/lib/lxc/lxc-racktables/config # pcs constraint order start fs-lxc_ct-clone then lxc-racktables И указываем порядок запуска.
Ресурс сразу же запустится и его состояние можно узнать командой pcs status. Если запуск не удался, то там же будет и возможная причина. Команда pcs resource debug-start <resource id> позволит сделать запуск ресурса с выводом на экран результата:
# pcs resource debug-start lxc-racktables Operation start for lxc-racktables (ocf:heartbeat:lxc) returned 0 > stderr: DEBUG: State of lxc-racktables: State: STOPPED > stderr: INFO: Starting lxc-racktables > stderr: DEBUG: State of lxc-racktables: State: RUNNING > stderr: DEBUG: lxc-racktables start : 0 Но с ней нужно быть осторожнее, она игнорирует настройки кластера по размещению ресурса и запускает его на текущем узле. И если ресурс уже запущен на другом узле, то могут быть неожиданности. Модификатор "--full" выдаст много дополнительной информации.
Хоть управляет контейнером Pacemaker, но с ним по прежнему можно работать всеми lxc-* утилитами, конечно только на узле, на котором он в данный момент работает и с оглядкой на Pacemaker.
Получившийся контейнер-ресурс можно перенести на другой узел, выполнив:
# pcs resource move <resource id> [destination node] В таком случае, контейнер корректно завершит работу на одном узле, и запустится на другом.
К сожалению, у LXC нет приличного инструмента живой миграции, но когда появится, то можно будет настроить и миграцию. Для этого нужно будет создать ещё один общий раздел на GFS2, куда будут помещаться дампы и модифицировать ресурс-скрипт lxc, чтобы он отрабатывал функции migrate_to и migrate_from.
Проект CRIU я смотрел, но добиться работы на CentOS 7 не сумел.
Переносим контейнер OpenVZ в LXC
Создаём новый логический раздел и переносим туда данные с контейнера OpenVZ (выключенного):
# lvcreate -L 2G -n lxc-openvz shared_vg # mkfs.ext4 /dev/shared_vg/lxc-openvz # mount /dev/shared_vg/lxc-openvz /mnt/lxc-openvz # rsync -avh --numeric-ids -e 'ssh' openvz:/vz/private/<containerid>/ /mnt/lxc-openvz/ Создаём файл конфигурации для нового контейнера, копируя и меняя содержимое lxc-racktables:
# mkdir /var/lib/lxc/lxc-openvz # cp /var/lib/lxc/lxc-racktables/config /var/lib/lxc/lxc-openvz/ В файле конфигурации необходимо изменить поля:
lxc.rootfs = /dev/shared_vg/lxc-openvz lxc.utsname = openvz #lxc.network.hwaddr При необходимости, настроить ограничения и нужный сетевой мост. Так же в контейнере нужно изменить настройки сети, переписав их на интерфейс eth0 и исправить файл etc/sysconfig/network.
В принципе, после этого контейнер уже можно запускать, но для лучшей совместимости с LXC необходимо содержимое доработать. Как пример, я использовал шаблон для создания контейнера centos (/usr/share/lxc/templates/lxc-centos), а именно содержание функций configure_centos и configure_centos_init с небольшой доработкой. Особое внимание обратите на создание скрипта etc/init/power-status-changed.conf, без него контейнер не сможет корректно завершать работу. Либо inittab контейнера должен содержать правило вида: "p0::powerfail:/sbin/init 0"(зависит от дистрибутива).
#
start on power-status-changed
exec /sbin/shutdown -h now «SIGPWR received»
Если кому-то лень разбираться самому (а зря), то можете воспользоваться моим (на свой страх и риск). MAC адрес контейнера лучше зафиксировать в файле конфигурации.
У перенесённых контейнеров возможны проблемы с консолью — её нельзя получить средствами lxc-console. Скриптом я эту проблему решаю используя agetty (alternative Linux getty), который входил в переносимые контейнера. И настройками init, который запускает процессы вида:
/sbin/agetty -8 38400 /dev/console /sbin/agetty -8 38400 /dev/tty1 Рецепт и скрипты /etc/init/ были позаимствованы из созданного чистого контейнера и переделаны под agetty.
# This service starts the configured number of gettys.
#
# Do not edit this file directly. If you want to change the behaviour,
# please create a file start-ttys.override and put your changes there.
start on stopped rc RUNLEVEL=[2345]
env ACTIVE_CONSOLES=/dev/tty[1-6]
env X_TTY=/dev/tty1
task
script
. /etc/sysconfig/init
for tty in $(echo $ACTIVE_CONSOLES); do
[ "$RUNLEVEL" = «5» -a "$tty" = "$X_TTY" ] && continue
initctl start tty TTY=$tty
done
end script
#
# This service maintains a getty on the console from the point the system is
# started until it is shut down again.
start on stopped rc RUNLEVEL=[2345]
stop on runlevel [!2345]
env container
respawn
#exec /sbin/mingetty —nohangup —noclear /dev/console
exec /sbin/agetty -8 38400 /dev/console
#
# This service maintains a getty on the specified device.
#
# Do not edit this file directly. If you want to change the behaviour,
# please create a file tty.override and put your changes there.
stop on runlevel [S016]
respawn
instance $TTY
#exec /sbin/mingetty —nohangup $TTY
exec /sbin/agetty -8 38400 $TTY
usage ‘tty TTY=/dev/ttyX — where X is console id’
Я пробовал использовать mingetty в перенесённом контейнере с CentOS 6.6, но он отказался работать с ошибкой в логах:
# /sbin/mingetty --nohangup /dev/console console: no controlling tty: Operation not permitted С LXC можно работать через libvrt, используя драйвер lxc:///, но этот способ опасен и RedHat грозится удалить его поддержку из дистрибутива.
Для управлением через libvrt в Pacemaker-е существует ресурс-скрипт ocf:heartbeat:VirtualDomain, который может управлять любой VM, в зависимости от драйвера. Возможности включают в себя и живую миграцию для KVM. Думаю, использование Pacemaker-а для управления KVM, будет аналогичным, но мне это не было нужным.
Работа с Docker-ом в кластере
Настройка Pacemaker-а для работы с Docker-ом похожа на настройку LXC, но есть и конструктивные отличия.
Для начала поставим Docker, так как он входит в дистрибутив RHEL/CentOS 7, то проблем не возникнет.
# yum install docker Научим Docker работать с LVM. Для этого создаём файл /etc/sysconfig/docker-storage-setup с содержимым:
VG=shared_vg-ex Где указываем, в какой группе томов Docker-у создавать свой пул. Тут же можно задать дополнительные параметры (man docker-storage-setup).
Запускаем docker-storage-setup:
# docker-storage-setup Rounding up size to full physical extent 716.00 MiB Logical volume "docker-poolmeta" created. Logical volume "docker-pool" created. WARNING: Converting logical volume shared_vg-ex/docker-pool and shared_vg-ex/docker-poolmeta to pools data and metadata volumes. THIS WILL DESTROY CONTENT OF LOGICAL VOLUME (filesystem etc.) Converted shared_vg-ex/docker-pool to thin pool. Logical volume "docker-pool" changed. # lvs | grep docker-pool docker-pool shared_vg-ex twi-aot--- 17.98g 14.41 2.54 Docker использует разреженный том (thin provisioned), это накладывает ограничение на использование в кластере. Такой том не может быть активным на нескольких узлах одновременно. Настроим LVM так, чтобы тома в группе shared_vg-ex не активировалась автоматически. Для этого необходимо явно указать группы (или тома по отдельности) которые будут активироваться автоматически в файле /etc/lvm/lvm.conf (на всех узлах):
auto_activation_volume_list = [ "shared_vg" ] Передадим управление этим томом Pacemaker-у:
# pcs resource create lvm-docker-pool LVM volgrpname=shared_vg-ex exclusive=yes # pcs constraint order start clvmd-clone then lvm-docker-pool # pcs constraint colocation add lvm-docker-pool with clvmd-clone Теперь тома группы shared_vg-ex будут активироваться на том узле, где запущен ресурс lvm-docker-pool.
Docker будет использовать для NAT-а контейнеров из внешней сети выделенный IP. Зафиксируем его в конфигурации:
# cat /etc/sysconfig/docker-network DOCKER_NETWORK_OPTIONS="--ip=10.1.2.10 —fixed-cidr=172.17.0.0/16" Отдельный мост настраивать не будем, пусть использует по умолчанию docker0, только зафиксируем сеть для контейнеров. Я пробовал указывать мне удобную сеть для контейнеров, но наткнулся на какие-то не внятные ошибки. Гугл подсказал, что не я один, по этому удовлетворился просто зафиксировав сеть, которую Docker сам себе выбрал. Docker так же не останавливает мост при своём выключении и не убирает ip-адрес, но так как мост не соединён ни с одним физическим интерфейсом, то это не проблема. В других конфигурациях это надо учитывать.
Чтобы Docker ходил в интернет через прокси-сервер, настроим ему переменные окружения. Для этого создаём директорию и файл /etc/systemd/system/docker.service.d/http-proxy.conf с содержанием:
[Service] Environment="http_proxy=http://ip_proxy:port" "https_proxy=http://ip_proxy:port" "NO_PROXY=localhost,127.0.0.0/8,dregistry" Базовая настройка завершена, будем наполнять кластер соответствующими ресурсами. Так как за Docker будет отвечать набор ресурсов, то удобно их собрать в группу. Все ресурсы группы запускаются на одном узле и запускаются последовательно, согласно порядку в группе. Но нужно учитывать, что при сбое одного из ресурсов группы, вся группа соберётся мигрировать на другой узел. А так же, при выключении какого-либо ресурса группы, все последующие ресурсы тоже выключатся. Первым ресурсом группы будет созданный LVM том:
# pcs resource group add docker lvm-docker-pool Создаём ресурс — IP адрес, выданный Docker-у:
# pcs resource create dockerIP IPaddr2 --group docker --after lvm-docker-pool ip=10.1.2.10 cidr_netmask=24 nic=br0.12 Кроме LVM тома Docker так же использует файловую систему для хранения своих данных. По этому нужно завести ещё один раздел под управлением Pacemaker-а. Так как эти данные нужны только работающему Dokcer-у, то и ресурс будет обычным.
# lvcreate -L 500M -n docker-db shared_vg # mkfs.xfs /dev/shared_vg/docker-db # pcs resource create fs-docker-db Filesystem fstype=xfs device=/dev/shared_vg/docker-db directory=/var/lib/docker --group docker --after dockerIP Теперь можно добавлять сам Docker-демон:
# pcs resource create dockerd systemd:docker --group docker --after fs-docker-db После успешного запуска ресурсов группы, на узле, где поселился Docker смотрим его статус и убеждаемся, что всё хорошо.
# docker info Containers: 5 Images: 42 Storage Driver: devicemapper Pool Name: shared_vg--ex-docker--pool Pool Blocksize: 524.3 kB Backing Filesystem: xfs Data file: Metadata file: Data Space Used: 2.781 GB Data Space Total: 19.3 GB Data Space Available: 16.52 GB Metadata Space Used: 852 kB Metadata Space Total: 33.55 MB Metadata Space Available: 32.7 MB Udev Sync Supported: true Library Version: 1.02.93-RHEL7 (2015-01-28) Execution Driver: native-0.2 Kernel Version: 3.10.0-229.7.2.el7.x86_64 Operating System: CentOS Linux 7 (Core) CPUs: 4 Total Memory: 3.703 GiB Name: cluster-2
Можно уже работать с Docker-ом в обычном порядке. Но для полноты картины, заведём и поселим в наш кластер Docker-реестр. Для реестра будем использовать отдельный IP и имя 10.1.2.11 (dregistry), а файловое хранилище образов вынесем в отдельный раздел.
# lvcreate -L 10G -n docker-registry shared_vg # mkfs.ext4 /dev/shared_vg/docker-registry # mkdir /mnt/docker-registry # pcs resource create docker-registry Filesystem fstype=ext4 device=/dev/shared_vg/docker-registry directory=/mnt/docker-registry --group=docker –after=dockerd # pcs resource create registryIP IPaddr2 --group docker --after docker-registry ip=10.1.2.11 cidr_netmask=24 nic=br0.12 Создаём контейнер-реестр на узле, где запущен Docker:
# docker create -p 10.1.2.11:80:5000 -e REGISTRY_STORAGE_FILESYSTEM_ROOTDIRECTORY=/var/lib/registry -v /mnt/docker-registry:/var/lib/registry -h dregistry --name=dregistry registry:2 Задаём проброс порта в контейнер (10.1.2.11:80 → 5000). Подключаемую директорию /mnt/docker-registry. Имя хоста и имя контейнера.
Вывод docker ps -a покажет созданный контейнер, готовый к запуску.
Отдадим управление им Pacemaker-у. Для начала скачиваем свежий ресурс-скрипт:
# wget -O /usr/lib/ocf/resource.d/heartbeat/docker https://raw.githubusercontent.com/ClusterLabs/resource-agents/master/heartbeat/docker # chmod +x /usr/lib/ocf/resource.d/heartbeat/docker Важно следить за идентичностью ресурс-скриптов на всех узлах, а то могут быть неожиданности. Ресурс-скрипт «docker» сам умеет создавать требуемые контейнера с заданными параметрами, скачивая их из реестра. По этому можно просто использовать постоянно запущенные Docker-а на узлах кластера с общим реестром и личными хранилищами. А Pacemaker-ом только контролировать отдельные контейнера, но это не так интересно, да и избыточно. Я и с одним то Docker-ом ещё не придумал, что делать.
Итак, передадим управление готовым контейнером Pacemaker-у.
# pcs resource create dregistry docker reuse=true image="docker.io/registry:2" --group docker --after registryIP reuse=true – важный параметр, иначе контейнер будет удалён после остановки. image необходимо указать полные координаты контейнера, включая реестр и тэг. Ресурс-скрипт подхватит готовый контейнер по имени dregistry и запустит.
Пропишем наш локальный реестр в конфигурацию Docker-а на узлах кластера (/etc/sysconfig/docker).
ADD_REGISTRY='--add-registry dregistry' INSECURE_REGISTRY='--insecure-registry dregistry' HTTPS нам не нужен, потому отключаем для локального реестра.
После этого перезапускаем службу Docker-а systemctl restart docker на узле, где он живёт или pcs resource restart dockerd на любом узле кластера. И можем пользоваться возможностями нашего личного реестра по адресу 10.1.2.11 (dregistry).
Теперь на примере Docker-контейнеров я покажу, как работать с шаблонами в Pacemaker-е. К сожалению, возможности утилиты pcs тут сильно ограничены. Шаблоны как таковые она не умеет вообще, а для constraint позволяет создать некоторые объединения, но работать с ними через pcs не удобно. Благо, на помощь приходит возможность править конфигурацию кластера на прямую в xml файле:
# pcs cluster cib > /tmp/cluster.xml # правим, что нужно # pcs cluster cib-push /tmp/cluster.xml Docker-ресурсы должны отвечать следующим требованиям:
- находится на одном узле с ресурсами группы docker
- запускаться после всех ресурсов группы docker
- контейнера должны быть не зависимы от статуса друг друга
Конечно, этого можно добиться навешав зависимости на каждый контейнер с помощью pcs constraint, но конфигурация получается громоздкой и плохо читаемой.
Для начала создадим три подопытных контейнера, в качестве которых я использовал контейнер с Nginx-ом. Контейнер предварительно скачивается и выкладывается в локальный реестр:
# docker pull nginx:latest # docker push nginx:latest # pcs resource create doc-test3 docker reuse=false image="dregistry/nginx:latest" --disabled # pcs resource create doc-test2 docker reuse=true image="dregistry/nginx:latest" --disabled # pcs resource create doc-test docker reuse=true image="dregistry/nginx:latest" --disabled Ресурсы создаются выключенными, иначе они попробуют запустится и тут как повезёт с узлом.
В свежевыгруженный xml добавляем объединение ресурсов. Определяющее совместное расположение (секция <constraints>):
<rsc_colocation id="docker-col" score="INFINITY"> <resource_set id="docker-col-0" require-all="false" role="Started" sequential="false"> <resource_ref id="doc-test"/> <resource_ref id="doc-test2"/> <resource_ref id="doc-test3"/> </resource_set> <resource_set id="docker-col-1"> <resource_ref id="docker"/> </resource_set> </rsc_colocation> Здесь заводится общее объединение (colocation set, id="docker-col") с требованием совместного проживания на одном узле (score="INFINITY"). Первое объединение ресурсов (id="docker-col-0") со свойствами:
- одновременный запуск ресурсов (
sequential="false") - не зависимость ресурсов от статуса друг друга (
require-all="false") - роль ресурсов (
role="Started")
Тэг resource_ref ссылается на существующие ресурсы кластера, которые нужно включить в это объединение. Параметр role="Started" критичен.
И второе объединение ресурсов (id="docker-col-1"), куда входят все ресурсы группы docker.
Мне не совсем понятна логика работы параметра role в этой конструкции, но оно должно быть так (проверено экспериментами).
Ordering set, определяющий порядок запуска ресурсов:
<rsc_order id="order_doc"> <resource_set id="order_doc-0"> <resource_ref id="docker"/> </resource_set> <resource_set id="order_doc-1" require-all="false" sequential="false"> <resource_ref id="doc-test"/> <resource_ref id="doc-test2"/> <resource_ref id="doc-test3"/> </resource_set> </rsc_order> Здесь прозрачнее, сначала запускаем ресурсы группы docker, затем скопом и не зависимо все контейнера.
После загрузки изменённой конфигурации, контейнера можно безбоязненно включать/выключать и удалять. Это не повлияет на работу других ресурсов. Но требование совместного расположение заставит переместится на другой узел кластера все связанные ресурсы, в случае переноса какого-либо ресурса. В выводе pcs эти настройки выглядят следующим образом:
# pcs constraint --full | grep -i set Resource Sets: set docker (id:order_doc-0) set doc-test doc-test2 doc-test3 sequential=false require-all=false (id:order_doc-1) (id:order_doc) Resource Sets: set doc-test doc-test2 doc-test3 role=Started sequential=false require-all=false (id:docker-col-0) set docker (id:docker-col-1) setoptions score=INFINITY (id:docker-col) Работа с шаблонами ресурсов осуществляется сходным образом. Создадим шаблон для LXC контейнера (в секции <resources>):
<template id="lxc-template" class="ocf" provider="heartbeat" type="lxc"> <meta_attributes id="lxc-template-meta_attributes"> <nvpair id="lxc-template-meta_attributes-allow-migrate" name="use_screen" value="false"/> </meta_attributes> <operations> <op id="lxc-template-monitor-30s" interval="30s" name="monitor" timeout="20s"/> <op id="lxc-template-start-0" interval="0" name="start" timeout="20s"/> <op id="lxc-template-stop-0" interval="0" name="start" timeout="90s"/> </operations> </template> В котором пропишем основные параметры ресурса. И перепишем настройки ресурса на использование этого шаблона:
<primitive id="lxc-racktables" template="lxc-template"> <instance_attributes id="lxc-racktables-instance_attributes"> <nvpair id="lxc-racktables-instance_attributes-container" name="container" value="lxc-racktables"/> <nvpair id="lxc-racktables-instance_attributes-config" name="config" value="/var/lib/lxc/lxc-racktables/config"/> </instance_attributes> </primitive> После обновления конфигурации вывод свойств ресурса стал совсем короток:
# pcs resource show lxc-racktables Resource: lxc-racktables (template=lxc-template) Attributes: container=lxc-racktables config=/var/lib/lxc/lxc-racktables/config Правда создавать новые ресурсы средствами pcs с использованием шаблонов пока не получится.
Осталось зафиксировать порядок запуска контейнеров LXC аналогичным объединением, как с Docker-ом.
Для управления Pacemaker-ом можно поставить пакет crmsh из репозитория opensuse.org, но, возможно, придётся повозится с зависимостями.
Кластер приобрёл следующий вид:
Last updated: Thu Jul 16 12:29:33 2015
Last change: Thu Jul 16 10:23:40 2015
Stack: corosync
Current DC: cluster-1 (1) — partition with quorum
Version: 1.1.12-a14efad
2 Nodes configured
19 Resources configured
Online: [ cluster-1 cluster-2 ]
Full list of resources:
cluster-1.stonith (stonith:fence_ipmilan): Started cluster-2
cluster-2.stonith (stonith:fence_ipmilan): Started cluster-1
Clone Set: dlm-clone [dlm]
Started: [ cluster-1 cluster-2 ]
Clone Set: clvmd-clone [clvmd]
Started: [ cluster-1 cluster-2 ]
Clone Set: fs-lxc_ct-clone [fs-lxc_ct]
Started: [ cluster-1 cluster-2 ]
lxc-racktables (ocf::heartbeat:lxc): Started cluster-1
Resource Group: docker
lvm-docker-pool (ocf::heartbeat:LVM): Started cluster-2
dockerIP (ocf::heartbeat:IPaddr2): Started cluster-2
fs-docker-db (ocf::heartbeat:Filesystem): Started cluster-2
dockerd (systemd:docker): Started cluster-2
docker-registry (ocf::heartbeat:Filesystem): Started cluster-2
registryIP (ocf::heartbeat:IPaddr2): Started cluster-2
dregistry (ocf::heartbeat:docker): Started cluster-2
doc-test (ocf::heartbeat:docker): Started cluster-2
doc-test2 (ocf::heartbeat:docker): Started cluster-2
doc-test3 (ocf::heartbeat:docker): Stopped
PCSD Status:
cluster-1: Online
cluster-2: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
Resource: cluster-1.stonith
Disabled on: cluster-1 (score:-INFINITY)
Resource: cluster-2.stonith
Disabled on: cluster-2 (score:-INFINITY)
Resource: doc-test
Enabled on: cluster-2 (score:INFINITY) (role: Started)
Ordering Constraints:
start dlm-clone then start clvmd-clone (kind:Mandatory)
start clvmd-clone then start fs-lxc_ct-clone (kind:Mandatory)
start fs-lxc_ct-clone then start lxc-racktables (kind:Mandatory)
start clvmd-clone then start lvm-docker-pool (kind:Mandatory)
Resource Sets:
set docker set doc-test doc-test2 doc-test3 sequential=false require-all=false
Colocation Constraints:
clvmd-clone with dlm-clone (score:INFINITY)
fs-lxc_ct-clone with clvmd-clone (score:INFINITY)
lvm-docker-pool with clvmd-clone (score:INFINITY)
Resource Sets:
set doc-test doc-test2 doc-test3 role=Started sequential=false require-all=false set docker setoptions score=INFINITY
Спасибо за внимание.
Шпаргалка
Посмотреть параметры конкретного ресурса:
# pcs resource show <resource id> Обновить или дополнить параметры ресурса, например:
# pcs resource update <resource id> op start start-delay="3s" interval=0s timeout=90 Необходимо указать весь список параметров для обновляемой функции, включая существующие, так как update их перезапишет.
Перезапустить ресурс
# pcs resource restart <resource id> [node]Важно при перезапуске clone-ресурса обязательно указать узел явно, иначе перезапустит, где вздумается.
Посмотреть и сбросить счётчик ошибок для конкретного ресурса:
# pcs resource failcount show <resource id> [node] # pcs resource failcount reset <resource id> [node] Это очень полезно, если ресурс впал в состояние ошибки и Pacemaker ждёт ваших действий что-бы продолжить работу с ресурсом дальше.
Почистить ошибки и статус по ресурсу:
# pcs resource cleanup [<resource id>]После после этого Pacemaker подхватывает ресурс в работу.
Выключить/включить какой-либо ресурс:
# pcs resource disable [<resource id>] # pcs resource enable [<resource id>]Это приведёт к остановке/запуску соответствующего процесса, службы или настройки.
Переместить ресурс на другой узел:
# pcs resource move <resource id> [destination node]Если ресурс-скрипт не отрабатывает функции миграции, то ресурс будет штатно остановлен на своём текущем узле и запущен на целевом. Если ресурс переносили на другой узел, и запуск там не удался, то ресурс вернётся назад. При этом, в constraint добавится правило вида:
Resource: docker Enabled on: cluster-2 (score:INFINITY) (role: Started) (id:cli-prefer-docker) c адресом целевого узла. После отладки правило нужно удалять в ручную.
Посмотреть полный вывод ограничений и зависимостей:
# pcs constraint –fullУдалить какое-либо ограничения по id, полученное выше:
# pcs constraint remove <constraint id>Сохранить и загрузить изменённую конфигурацию кластера:
# pcs cluster cib > /tmp/cluster.xml # pcs cluster cib-push /tmp/cluster.xml<source lang="bash">Cсылки
- Pacemaker, теория
- Clusters from Scratch
- Configuration Explained
- Pacemaker: как добить лежачего
- Creating LVM Volumes in a Cluster
- Linux Containers with libvirt-lxc (deprecated)
- High Availability Add-On Reference
- High Availability Add-On Administration
- Docker Docs
- Get Started with Docker Formatted Container Images on Red Hat Systems
- LXC 1.0.
- GitHub ClusterLabs
- CRIU
ссылка на оригинал статьи http://habrahabr.ru/post/263091/
Добавить комментарий