
Года полтора назад, встал вопрос совместимости написанного кода с Python3. Поскольку уже стало более менее очевидно что развивается только Python3 и рано или поздно, все библиотеки будут портированы под него. И во всех дистрибутивах по умолчанию будет тройка. Но постепенно, по мере изучения, что нового появилось в последних версиях Python мне все больше стал нравится Asyncio и скорее даже не Acyncio а написанный для работы с ним aiohttp. И спустя какое то время появилась небольшая обертка вокруг aiohttp в стиле like django. Кому интересно что из этого получилось прошу под кат.
Введение
Краткий обзор других фреймворков на базе aiohttp
1. Структура
2. aiohttp и jinja2
3. aiohttp и роуты
4. статика и GET, POST параметры, редиректы
5. Websocket
6. asyncio и mongodb, aiohttp, session, middlwere
7. aiohttp, supervisor, nginx, gunicorn
8. После установки, о примерах.
9.RoadMap
Введение
На тот момент уже были готовы для Python3 практически все часто используемые в проектах библитеки.
Почивший PIL был прекрасно заменен на Philow, tweppy на twython, python-openid на python3-openid и т.д. Jinja2, xlrt, xlwt и прочие уже были с поддержкой Python3.
Грубо говоря все что надо было реализовать, это чтоб система отдавала данные в виде bytes:
def application(env, start_response): start_response('200 OK', [('Content-Type','text/html')]) return bytes("Hello World", 'utf-8') Немного, с переименованием библиотек помучатся:
py = sys.version_info py3k = py >= (3, 0, 0) if py3k: unicode = str import io as StringIO import builtins as __builtin__ else: import StringIO Ну и естественно по мере изучения что нового появилось Python3 не мог не привлечь внимание Asyncio. Встроенный в python3 асинхронный движок. Появившийся правда только в 3.4 версии. И только с версии 3.5 которая вышла на днях, у него появился достаточно удачный синтаксический сахар, об этом чуть ниже.
Первое время конечно на нем что то написать было дико неудобно, и насколько я понял все по прежнему пользовались tornado, gevent, twisted или оберткой вокруг того же asynio и twisted — autobuh. Достаточно неплохим продуктом. Но время шло и один из разработчиков asyncio svetlov создал достаточно быстро развивающийся асинхронный фреймворк aiohttp. Aiohttp упрощает разработку с помощью asyncio примерно до уровня flask или bottle.
Но с довольно легко подключаемыми, websocket-ами, и при желании позволяющий выполнять большинство операций асинхронно и как на мой взгляд с довольно небольшой ценой за это, особенно с оглядкой на python3.5.
Примерно это выглядит так:
#python3.4 @asyncio.coroutine def read_data(): data = yield from db.fetch('SELECT . . . ') #python3.5 async def read_data(): data = await db.fetch('SELECT ...') И поскольку до сих пор для написания чатов, игрушек, конференций с webrtc где есть websoket-ы мне приходилось пользоваться либо gevent либо autobah либо в некоторых случаях node.js, взвесив все за и против очень захотелось переписать свои библиотеки на aiohttp, который за последний год успел обрасти своей эко-системой, и рядом удобных возможностей. И так появилась эта публикация.
Надо еще добавить что в aiohttp вполне можно писать и синхронно, выполнять блокирующие операции, хотя это и не совсем правильно.
Дальше будет описана работа с aiohttp и создание небольшого фреймворка в стиле like django , с похожей структурой и возможностями.
Естественно от версии 0.1 ожидать каких то батареек не приходится, но думаю, что в следующей версии, уже можно будет увидеть много положительных сдвигов.
Краткий обзор других фреймворков на базе asyncio и aiohttp
Тут хочется привести очень краткий обзор, чтоб было общее представление о состоянии дел на данный момент с написанием асинхронных библиотек упрощающих жизнь разработчикам в Python3.
Все ниже перечисленные фреймворки, можно поделить на две категории те которые по зависимостям тянут aiohttp и базируются на нем, и те которые работают без него только с asyncio.
Pulsar — framework использующий asyncio и multiprocessing. Интегрируется с django, hello world на нем выглядит как обычный wsgi. На github есть достаточно много примеров использования, например чатов, автор насколько я понял любит angular.js
from pulsar.apps import wsgi def hello(environ, start_response): data = b'Hello World!\n' response_headers = [ ('Content-type','text/plain'), ('Content-Length', str(len(data))) ] start_response('200 OK', response_headers) return [data] if __name__ == '__main__': wsgi.WSGIServer(callable=hello).start()
Mufin — framework базирующийся на aiohttp. У него есть некоторое количество плагинов насколько я понял написанных по возможности асинхронно. Также имеется развернутое на Heroku тестовое приложение в виде чата.
import muffin app = muffin.Application('example') @app.register('/', '/hello/{name}') def hello(request): name = request.match_info.get('name', 'anonymous') return 'Hello %s!' % name
introduction — еще один базирующийся на aiohttp framework
from interest import Service, http class Service(Service): @http.get('/') def hello(self, request): return http.Response(text='Hello World!') service = Service() service.listen(host='127.0.0.1', port=9000, override=True, forever=True)
Spanner.py — позиционируется как микро web-framework написанный на python для людей :), автора вдохновляли Flask и express.js. Использует только asyncio. Выглядит действительно довольно лаконичным.
from webspanner import Spanner app = Spanner() @app.route('/') def index(req, res): res.write("Hello world")
Growler — framework использующий только asyncio, авторы говорят что взяли идеи node.js и express.
import asyncio from growler import App from growler.middleware import (Logger, Static, Renderer) loop = asyncio.get_event_loop() app = App('GrowlerServer', loop=loop) # Добавление нескольких middleware приложений app.use(Logger()) app.use(Static(path='public')) @app.get('/') def index(req, res): res.render("home") Server = app.create_server(host='127.0.0.1', port=8000) loop.run_forever()
astrid — Простой flask подобный framework основанный на aiohttp.
import os from astrid import Astrid from astrid.http import render, response @app.route('/') def index_handler(request): return response("Hello") app.run()
1. Структура
Итак, у нас должна быть сама библиотека, которую мы хотим устанавливать с помощью pip install и в которой должны быть модули или батарейки идущие в составе, например админка или веб-магазин. И должен быть проект который мы создаем в каком то месте, в котором разработчик должен иметь возможность добавлять свои модули с разным функционалом.
В каждом компоненте как проекта так и самой библиотеки должна быть папка со статикой, и папка с шаблонами, файлик со списком роутов, и файлик или файлики с запросами к базе и выводом всего этого в шаблоны.
Библиотека — устанавливается через pip install:
apps-> app-> static templ view.py routes.py app1-> ... app2-> ... core-> core.py union.py utils.py Пример проекта — их может быть сколько угодно штук, в идеале для каждого сайта свой:
apps-> app-> static templ view.py routes.py app1-> ... app2-> ... static templ view.py route.py settings.py Содержание файликов со списком роутов мы хотим видеть примерно таким:
from core.union import route route( '/', page, 'GET' ) route( '/db', test_db, 'GET' ) А view где эти роуты обрабатываются такого типа:
@asyncio.coroutine def page(request): return templ('index', request, {'key':'val'}) То есть все выглядит довольно просто и достаточно удобно, кроме необязательной необходимости каждый раз писать вызов корутины @asyncio.coroutine или async def
2. aiohttp, jinja2 и отладчик
Для aiohttp есть специально для него написанный дебагер и асинхронная обертка для jinja2. Их мы и будем использовать.
pip install aiohttp_jinja2
import asyncio, jinja2, aiohttp_jinja2 from aiohttp import web @asyncio.coroutine def page(req): return aiohttp_jinja2.render_template('index.tpl', req,{'k':'v'}) @asyncio.coroutine def init(loop): app = web.Application(loop=loop) aiohttp_jinja2.setup(app, loader=jinja2.FileSystemLoader('./')) app.router.add_route('GET', '/', page) srv = yield from loop.create_server(app.make_handler(), '127.0.0.1', 80) return srv app = web.Application() loop = asyncio.get_event_loop() loop.run_until_complete(init(loop)) try: loop.run_forever() except KeyboardInterrupt: pass
Но нам надо вызывать шаблоны с разных мест и желательно максимально просто, например:
return templ('index', request, {'key':'val'}) И для самого шаблона. нужно как то сокращенно указывать путь, мест где могут хранится шалоны может быть несколько штук:
- Шаблоны лежащие в папке
templв корне самого проекта. - Шаблоны которые лежат в модулях проектов или модулях библиотеки.
Поэтому условно договоримся что если шаблоны лежат в корне какого либо проекта то будет просто указываться название шаблона, например 'template'. А шаблоны из модулей будут выглядеть примерно так:
return templ("apps.app:template", request, {'key':'val'}) где 'app' название компонента а 'template' название шаблона.
Поэтому, в месте, где мы инициализируем пути, подключения шаблонов мы вызываем функцию которая будет собирать все пути, к директориям где лежат шаблоны:
aiohttp_jinja2.setup(app, loader=jinja2.FunctionLoader ( load_templ ) )
def get_path(app): if type(app) == str: __import__(app) app = sys.modules[app] return os.path.dirname(os.path.abspath(app.__file__)) def get_templ_path(path): module_name = ''; module_path = ''; file_name = ''; name_templ = 'default'; if ':' in path: module_name, file_name = path.split(":", 1) # app.table main module_path = os.path.join( get_path( module_name), "templ") else: module_path = os.path.join( os.getcwd(), 'templ', name_templ) return module_name, module_path, file_name+'.tpl' def render_templ(t, request, p): # если хотим написать параметры через = то p = dict(**p) return aiohttp_jinja2.render_template( t, request, p ) def load_templ(t, **p): (module_name, module_path, file_name) = get_templ_path(t) def load_template (module_path, file_name): path = os.path.join(module_path, file_name) template = '' filename = path if os.path.exists ( path ) else False if filename: with open(filename, "rb") as f: template = f.read() return template template = load_template( module_path, file_name) if not template: return 'Template not found {}' .format(t) return template.decode('UTF-8')
Тут хотелось бы остановится на последовательности действий:
1) Мы парсим наш путь к шаблону например 'apps.app:index', просто проверяем что если в пути есть двоеточие то значит шаблоны берутся не из корня проекта, и тогда вызываем функцию для поиска путей из импортов:
def get_path(app): if type(app) == str: # импортирует модуль по имени. Например имя будет "news". __import__(app) # по имени "news" мы получаем сам модуль news и присваиваем его переменной app app = sys.modules[app] # получаем путь к нашему модулю return os.path.dirname(os.path.abspath(app.__file__)) 2) Зная пути и имя шаблона, читаем его с диска (замечу что asyncio не поддерживает асинхронные операции чтения с диска):
filename = path if os.path.exists ( path ) else False if filename: with open(filename, "rb") as f: template = f.read() Тут хотелось бы заметить один момент, часто в примерах к подключению jinja2 в том числе в aiohttp_jinja2 рекомендуется для инициализации применять FileSystemLoader просто передавая ему путь, или список путей, например:
aiohttp_jinja2.setup(app, loader=jinja2.FileSystemLoader('/templ/'))
А в нашем случае мы использовали FunctionLoader:
aiohttp_jinja2.setup(app, loader=jinja2.FunctionLoader ( load_templ ) )
Это связано с тем что мы хотим хранить шаблоны в разных директориях, для разных модулей, и не заботится одинаковыми названиями. А в случае с FunctionLoader мы идём только по необходимым путям, в результате у нас модули имеют независимые пространства имён.
Для того того чтоб писать в вызове шаблона сокращенно templ напишем маленькую обертку и присвоим её builtins.templ, после чего сможем вызывать из любого места templ, не делая его импорт постоянно:
def render_templ(t, request, p): return aiohttp_jinja2.render_template( t, request, p ) builtins.templ = render_templ
aiohttp_debugtoolbar
aiohttp_debugtoolbar — подключается довольно легко, там где мы инициализируем наш app:
app = web.Application(loop=loop, middlewares=[ aiohttp_debugtoolbar.middleware ]) aiohttp_debugtoolbar.setup(app) Подключается он через очень middlwere, как написать свой будем говорить немного ниже.
Сам aiohttp_debugtoolbar у меня вызвал приятное впечатление, и все необходимое в нем присутствует, немного скриншотов:
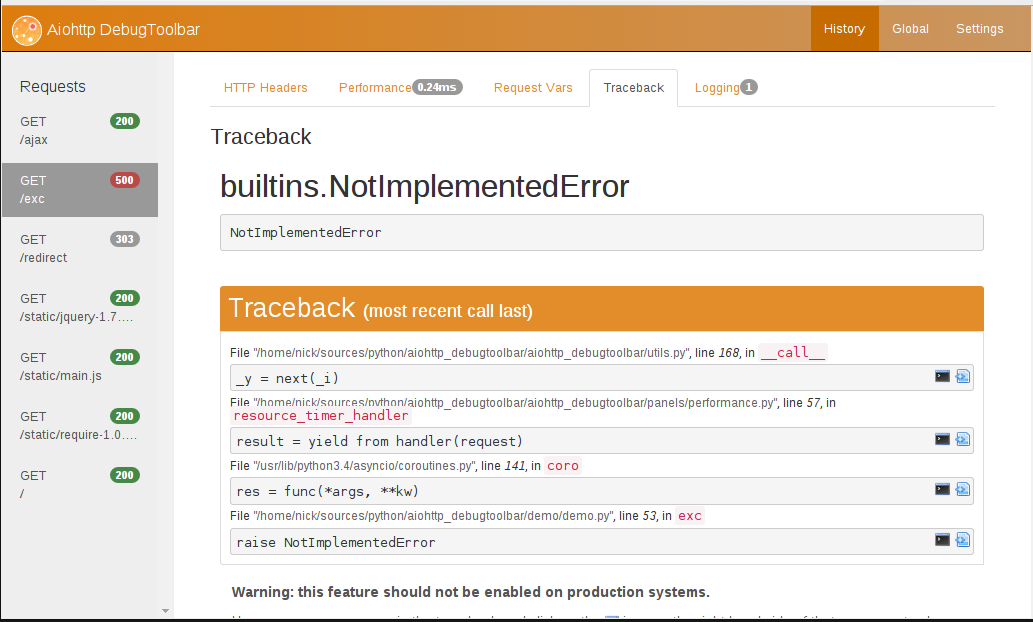

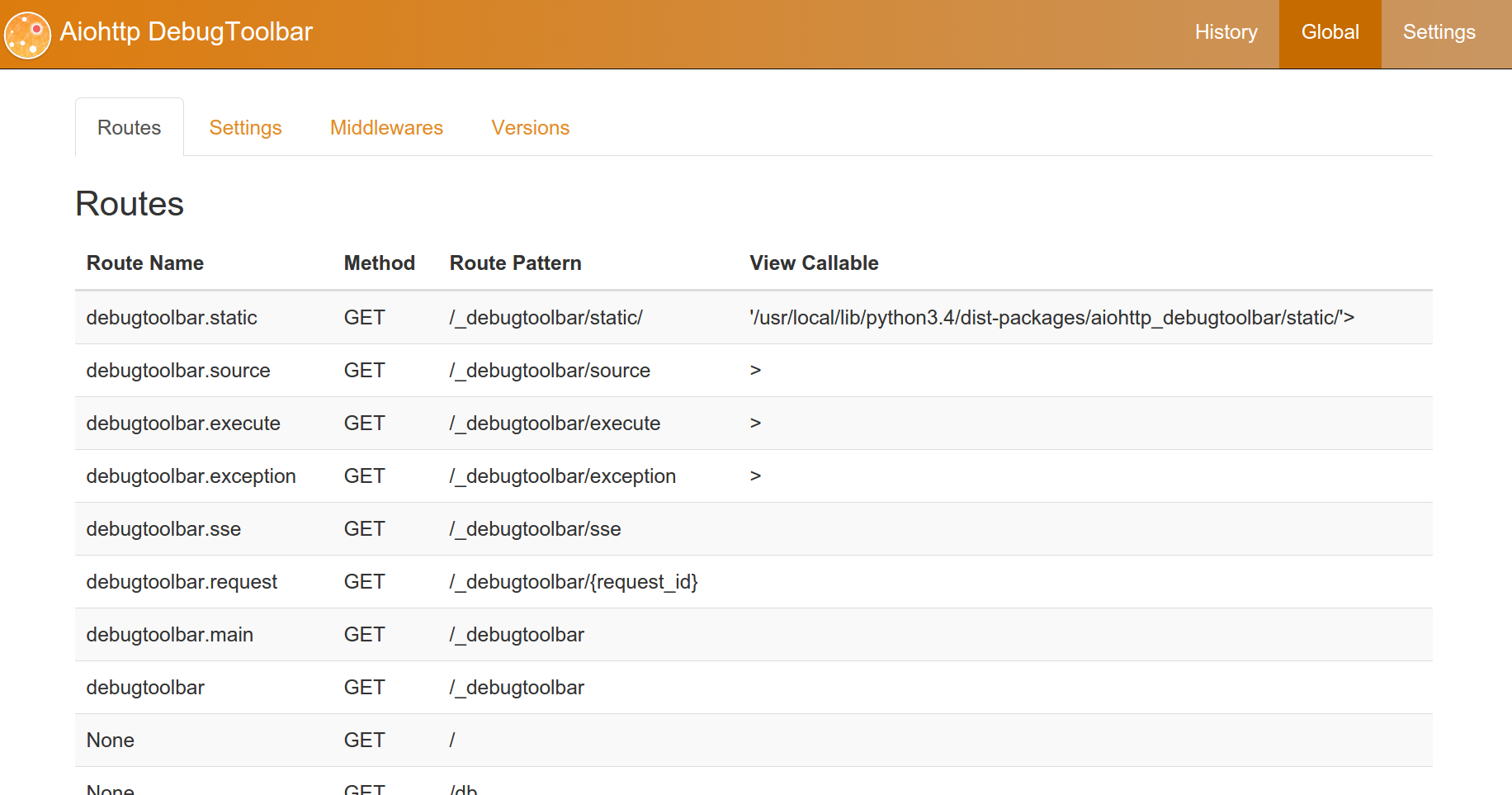
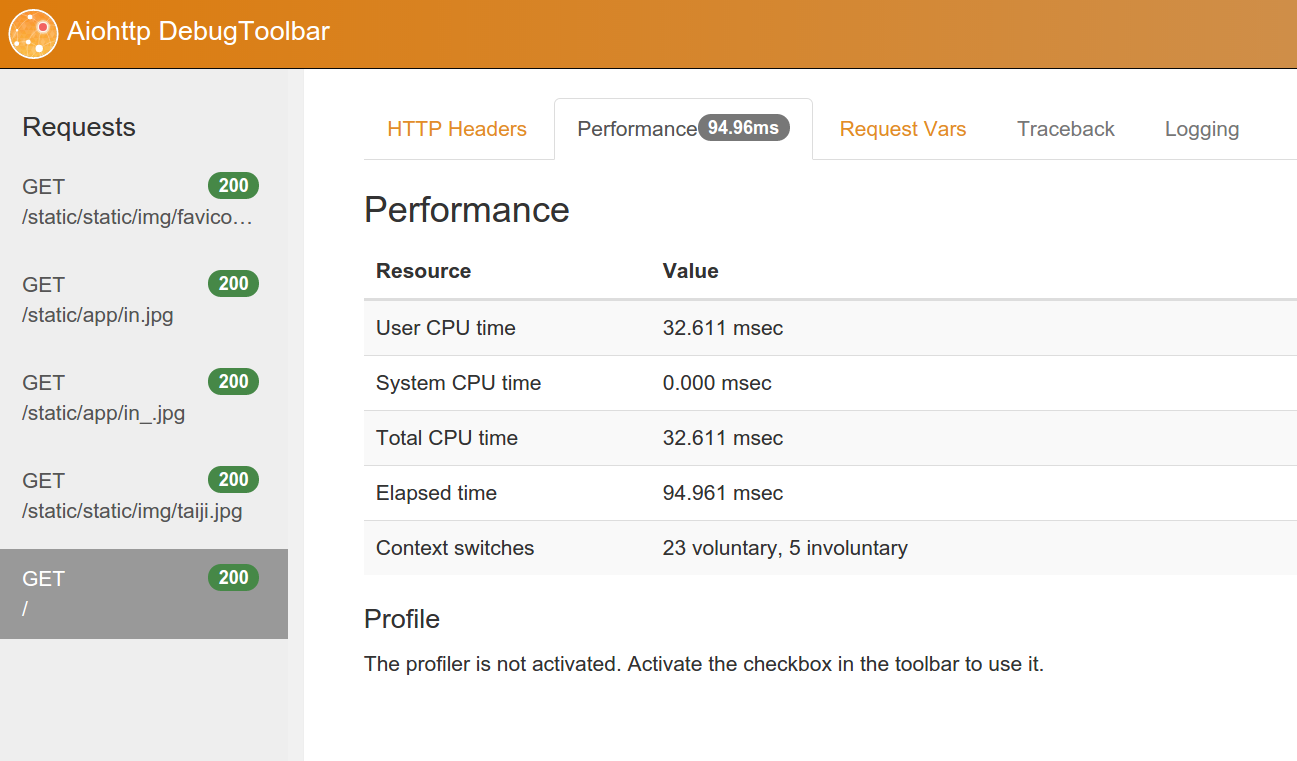

3. aiohttp и роуты
В aiohttp роуты выглядят достаточно просто, пример из документации с получением динамического параметра из адреса:
@asyncio.coroutine def variable_handler(request): return web.Response( text="Hello, {}".format(request.match_info['name'])) app = web.Application() app.router.add_route('GET', '/{name}', variable_handler) Но поскольку у нас модульная система, нам необходимо вызывать роуты в каждом модуле свои, в файлике routes.py. И желательно упростить это максимально, например:
from core import route route( '/', page, 'GET' ) route( '/db', test_db, 'POST' ) Тут придется воспользоватся глобальной переменной, хоть это не очень кошерно. Функция route имеет простой вид:
def route(t, r, func): routes.append((t, r, func)) В глобальную переменную, представляющую из себя список, заносим кортежами значения каждого роута. А потом во время инициализации просто в форе проходим по всем кортежам и подставляем в аутентичный вызов роута:
for res in routes: app.router.add_route( res[2], res[0], res[1]) Естественно перед прохождением по всем роутам нам нужно инициализировать пути где находятся файлы routes.py<code>. Мы это делаем с помощью функции которая в упрощенном виде выглядит примерно так: <source lang="python"> def union_routes( dir=settings.root ): name_app = dir.split(os.path.sep) name_app = name_app[len(name_app) - 1] for name in os.listdir(dir): path = os.path.join(dir, name) if os.path.isdir ( path ) and os.path.isfile ( os.path.join( path, 'routes.py' )): name = name_app+'.'+path[len(dir)+1:]+'.routes' builtins.__import__(name, globals=globals()) </source> <h3><anchor>4</anchor><font color="orange">4. Отдача статики</font> </h3> Конечно по нормальному статику лучше отдавать с помощью <code>nginx но наш фреймворк тоже должен уметь отдавать статику.
В aiohttp уже была функция отдачи статики но она была замечена чуть позже чем надо и уже была написана своя функция.
Распознавать статически файлы будем по роуту /static/path. Те файлы которые расположены в корне проекта будут распознаваться по пути /static/static/file_name, а файлы в компонентах /static/modul_name/file_name.
Естественно что все статические файлы будут лежать в папках /static любого модуля или проекта, и могут иметь любое количество вложенностей, скажем /static/img/big_img/.
Начинать реализовывать мы как и всегда, с инициализации. Тут мы просто одним роутом обслуживаем все основные встречающиеся виды статических адресов.
app.router.add_route('GET', '/static/{component:[^/]+}/{fname:.+}', union_stat) Дальше в функции union_stat мы просто разбираем параметры роута {component:[^/]+}/{fname:.+} которые получили:
component = request.match_info.get('component', "st") fname = request.match_info.get('fname', "st") И формируем соотвествующие пути.
После этого, в другой вспомогательной функции, мы создаем нужные нам заголовки для файлов, например:
mimetype, encoding = mimetypes.guess_type(filename) if mimetype: headers['Content-Type'] = mimetype if encoding: headers['Content-Encoding'] = encoding И читаем сам файл с диска.
В конце мы возвращаем заголовки и сам файл:
return web.Response( body=content, headers=MultiDict( headers ) )
@asyncio.coroutine def union_stat(request, *args): component = request.match_info.get('component', "Anonymous") fname = request.match_info.get('fname', "Anonymous") path = os.path.join( settings.root, 'apps', component, 'static', fname ) if component == 'static': path = os.path.join( os.getcwd(), 'static') elif not os.path.exists( path ): path = os.path.join( os.getcwd(), 'apps', component, 'static' ) else: path = os.path.join( settings.root, 'apps', component, 'static') content, headers = get_static_file(fname, path) return web.Response(body=content, headers=MultiDict( headers ) ) def get_static_file( filename, root ): import mimetypes, time root = os.path.abspath(root) + os.sep filename = os.path.abspath(os.path.join(root, filename.strip('/\\'))) headers = {} mimetype, encoding = mimetypes.guess_type(filename) if mimetype: headers['Content-Type'] = mimetype if encoding: headers['Content-Encoding'] = encoding stats = os.stat(filename) headers['Content-Length'] = stats.st_size from core.core import locale_date lm = locale_date("%a, %d %b %Y %H:%M:%S GMT", time.gmtime(stats.st_mtime), 'en_US.UTF-8') headers['Last-Modified'] = str(lm) headers['Cache-Control'] = 'max-age=604800' with open(filename, 'rb') as f: content = f.read() f.close() return content, headers
Пару слов скажу про POST, GET запросы и переадресацию в aiohttp. GET запросы выглядят довольно стандартно
@asyncio.coroutine def get_get(request): query = request.GET['query'] @asyncio.coroutine def get_post(request): data = yield from request.post() filename = data['mp3'].filename Редирект по адресу заданyому в роуте 'test' c 302 ответом
@asyncio.coroutine def redirect(request): data = yield from request.post() . . . url = request.app.router['test'].url() return web.HTTPFound( url ) Список всех ответов.
5. aiohttp и Websocket
Одна из самых приятных особенностей aiohttp это возможность легко подключать вебсокеты, просто вызвав в роуте функцию которая отвечает за их обработку. Без каких то лишних костылей.
Например app.router.add_route('GET', '/ws', ws). Если рассматривать роут из нашей небольшой обертки которую мы только что написали то это может выглядеть так: route( '/ws', ws, 'GET' )
Сама обработка вебсокетов выглядит довольно просто, и скажем написания небольшого чата по количеству кода довольно лаконично.
def ws(request): ws = web.WebSocketResponse() ws.start(request) while True: msg = yield from ws.receive() if msg.tp == MsgType.text: if msg.data == 'close': yield from ws.close() else: ws.send_str(msg.data + '/answer') elif msg.tp == aiohttp.MsgType.close: print('websocket connection closed') return ws Для примера то же самое в случае с Node.JS, с использованием модуля ws:
var WebSocketServer = new require('ws'); var clients = {}; var webSocketServer = new WebSocketServer.Server({ port: 8081 }); webSocketServer.on('connection', function(ws) { var id = Math.random(); clients[id] = ws; ws.on('message', function(message) { for (var key in clients) { clients[key].send(message); } }); ws.on('close', function() { console.log('Сonnection closed ' + id); delete clients[id]; }); });
6. asyncio и mongodb, aiohttp, session, middlwere
У aiohttp есть такой прекрасный инструмент как middlwere, в разных случаях под этим термином понимают немного разные вещи, поэтому рассмотрим его на примере создания коннектора к базе.
У таких фреймворков как flask или bootle есть возможность вызвать какую либо функцию перед загрузкой всего остального или после, например в bootle:
@bottle.hook('after_request') def enable_cors(): response.headers['Access-Control-Allow-Origin'] = '*' В случае с aiohttp, в том числе и для примерно таких случаев был придуман middlwere.
Итак мы хотим писать запросы к базе максимально просто, request.db:
def test_db(request): return templ('apps.app:db_test', request, { 'key': request.db.doc.find_one({"_id":"test"}) }) Для этого мы создадим middlwere и инициализируем его в самом начале, это делается довольно просто, пример с уже инициализированным дебагером, сессиями и базой.
app = web.Application(loop=loop, middlewares=[ aiohttp_debugtoolbar.middleware, db_handler(), session_middleware(EncryptedCookieStorage(b'Secret byte key')) ])
def db_handler(): @asyncio.coroutine def factory(app, handler): @asyncio.coroutine def middleware(request): if request.path.startswith('/static/') or request.path.startswith('/_debugtoolbar'): response = yield from handler(request) return response # инициализация db_inf = settings.database kw = {} if 'rs' in db_inf: kw['replicaSet'] = db_inf['rs'] from pymongo import MongoClient mongo = MongoClient( db_inf['host'], 27017) db = mongo[ db_inf['name'] ] db.authenticate('admin', settings.database['pass'] ) request.db = db # процессинг запроса (дальше по цепочки мидлверов и до приложения) response = yield from handler(request) mongo.close() # экземеляр рабочего объекта по цепочке вверх до библиотеки return response return middleware return factory
На что хотелось бы обратить внимание, поскольку на каждый запрос к серверу срабатывает middleware, первым делом, мы проверяем что в request не содержится адрес по которому мы получаем статику, а также адрес по которому вызывается дебагер. Чтоб на каждый запрос не дергать базу.
def middleware(request): if request.path.startswith('/static/') or request.path.startswith('/_debugtoolbar'): После этого мы конектимся к базе:
mongo = MongoClient( db_inf['host'], 27017) А в конце закрываем соединение:
mongo.close() Все выглядит довольно просто, некоторые полезности от автора aiohttp svetlov инициализируются и созданы подобным образом через middlwere.
Ну а дальше подробнее надо остановится на самом драйвере к mongodb. К большому сожалению он пока не асинхронный, правильнее сказать асинхронный драйвер есть есть но он давно заброшен и оставляет желать лучшего, и в нем нет поддержки gridFS, нет нововведений pymongo и тд.
Но все таки прогресс не стоит на месте и разработчик PyMongo и одновременно асинхронного драйвера к MongoDB для Tornado, Motor — A. Jesse Jiryu Davis активно работает над интеграцией Asyncio в Motor. И уже обещает этой осенью выпустить версию 0.5 с поддержкой Asyncio.
7. aiohttp, supervisor, nginx, gunicorn
Запустить aiohttp можно несколькими способами:
aiohttpлучше просто запускать с консоли если занимаемся разработкой, и с помощьюsupervisorеcли продакшен.- Запустить с помощью
gunicornиsupervisor.
Думаю для обоих случаев, в упрощенном варианте, подойдет настройка nginx как proxy, хотя gunicorn можно запустить через сокет при желании.
server { server_name test.dev; location / { proxy_pass http://127.0.0.1:8080; } } Aiohttp и supervisor
Устанавливаем supervisor:
apt install supervisor В /etc/supervisor/conf.d/ создаем файл aio.conf и в нем:
[program:aio] command=python3 index.py directory=/path/to/project/ user=nobody autorestart=true redirect_stderr=true После этого обновляем конфиги всех приложений, без перезапуска
supervisorctl reread >>aio: available >>erp: changed Перезапуск приложений для которых обновился конфиг:
supervisorctl update >>erp: stopped >>erp: updated process group >>aio: added process group Смотрим статус приложений:
supervisorctl status >>aio RUNNING pid 31570, uptime 0:06:49 >>erp FATAL Exited too quickly (process log may have details)
import asyncio from aiohttp import web def test(request): return {'title': 'Hello' } @asyncio.coroutine def init(loop): app = web.Application( loop = loop ) app.router.add_route('GET', '/', basic_handler, name='index') handler = app.make_handler() srv = yield from loop.create_server(handler, '127.0.0.1', 8080) return srv, handler loop = asyncio.get_event_loop() srv, handler = loop.run_until_complete( init( loop ) ) try: loop.run_forever() except KeyboardInterrupt: loop.run_until_complete(handler.finish_connections())
В случае с нашим небольшим фреймворком, в стартовом файле мы добавляем в sys.path нужные нам пути:
#путь к библиотеке sys.path.append( settings.root ) #путь к проекту sys.path.append( os.path.dirname( __file__ ) )
Aiohttp gunicorn и supervisor
Простой вариант для запуска с помощью gunicorn выглядит таким образом, тут нужно обратить внимание что мы не пишем над функцией index карутину, для вызва.
from aiohttp import web def index(request): return web.Response(text="Hello!") app = web.Application() app.router.add_route('GET', '/', index)
gunicorn выглядит таким образом, тут нужно обратить внимание что мы не пишем над функцией index карутину, для вызва.
from aiohttp import web def index(request): return web.Response(text="Hello!") app = web.Application() app.router.add_route('GET', '/', index) Для запуска нашего фреймворка с помощью gunicorn мы немного упростим функцию инициализации, убрав оттуда карутину и все что касается сервера, и не забываем вернуть app.
def init_gunicorn(): app = web.Application( middlewares=[ aiohttp_debugtoolbar.middleware, db_handler(), session_middleware(EncryptedCookieStorage(b'Sixteen byte key')) ]) aiohttp_debugtoolbar.setup(app) aiohttp_jinja2.setup(app, loader=jinja2.FunctionLoader ( load_templ ) ) union_routes(os.path.join ( settings.root, 'apps' ) ) union_routes(os.path.join ( os.getcwd(), 'apps' ) ) for res in routes: app.router.add_route( res[2], res[0], res[1], name=res[3]) app.router.add_route('GET', '/static/{component:[^/]+}/{fname:.+}', union_stat) return app
Ну а в файле который будет уже запускать gunicorn мы просто вызываем её.
import sys, os, settings sys.path.append( settings.root ) sys.path.append( os.path.dirname( __file__ ) ) from core.union import init_gunicorn app = init_gunicorn() Теперь можно просто запустить сам gunicorn из папки с файлом инициализации:
>> gunicorn app:app -k aiohttp.worker.GunicornWebWorker -b localhost:8080 Естественно что команду вызова можно просто прописать в конфигурации supervisor.
Для запуска gunicorn через supervisor у нас будет следующая конфигурация, в папке с проектом создаем файл gunicorn.conf.py в нем:
worker_class ='aiohttp.worker.GunicornWebWorker' bind='127.0.0.1:8080' workers=8 reload=True user = "nobody" В /etc/supervisor/conf.d/name.conf:
[program:name] command=/usr/local/bin/gunicorn app:app -c /path/to/project/gunicorn.conf.py directory=/path/to/project/ user=nobody autorestart=true redirect_stderr=true Выполняем команды:
supervisorctl reread supervisorctl update 8. После установки, о примерах.
Теперь мы можем установить нашу библиотечку
pip install tao1 Естественно после установки нам нужно развернуть проект и создать в нем пару модулей и тд.
Команда utils.py -p name создаст нам проект в папке в которой мы её выполним, естественно заместо -p можно написать --project или --startProject.
Команду utils.py -a name надо выполнять в директории apps вашего проекта и в ней так же опцию -a можно заменить на --app или --startApp 😉
Сам utils.py устроен довольно просто.
Создание проекта или модуля выглядит довольно просто.
С помощью модуля argparse получаем опции из командной строки:
parser = argparse.ArgumentParser() parser.add_argument('-project', '-startproject', '-p', type=str, help='Create project' ) parser.add_argument('-app', '-startapp', '-a', type=str, help='Create app' ) args = parser.parse_args() В зависимости от опций копируем уже заранее заготовленные файлы лежащие в библиотеке в нужное место:
import shutil shutil.copytree( os.path.join( os.path.dirname(__file__), 'sites', 'test'), str(args.project) ) А в файле setup.py где мы инициализируем наш пакет для установки в
https://pypi.python.org/ указываем scripts=['tao1/core/utils.py'] .
Тогда после установки пакета файл utils.py будет помещен в /usr/local/bin/ (если говорить о ubuntu) и станет исполняемым.
9. Road map
Версия 0.2 — 0.5
- Кеширование ( скорее всего memcached).
- Мультиязычность.
- Небольшой каркас для написания он-лайн игр.
- Полноценная админка. Более менее полноценные блоги и интернет магазин.
Каркас для конструктора справочников и документов для создания своих конфигураций.
ссылка на оригинал статьи http://habrahabr.ru/post/242541/
Добавить комментарий