Недавно вышло большое обновление Intel Parallel Studio XE 2016, и вместе с ним Intel Threading Building Blocks 4.4. В новой версии появилось несколько интересных дополнений:
- Глобальный контроль для управления ресурсами, в первую очередь, количеством рабочих потоков.
- Новые типы узлов Flow Graph: composite_node и async_node. Кроме того, во Flow Graph была улучшена функциональность сброса (reset).
- Больше фишек из С++11 для лучшей производительности.
Глобальный контроль
Бывает много случаев, когда нужно ограничить число рабочих потоков параллельного алгоритма. Intel TBB позволяет это сделать через инициализацию объекта tbb::task_scheduler_init, указав в параметре желаемое количество потоков:
tbb::task_scheduler_init my_scheduler(8); Однако, приложение может иметь сложную структуру. Например, множество плагинов, или потоков, каждый из которых может использовать свою версию Intel TBB. В этом случае будет несколько объектов tbb::task_scheduler_init, и созданием нового дело не исправишь.
Для решения таких проблем появился класс tbb::global_control. Создание объекта такого класса с параметром global_control::max_allowed_parallelism ограничивает количество активных потоков Intel TBB глобально. В отличие от the tbb::task_scheduler_init, это ограничение сразу становится общим для всего процесса, даже если библиотека уже инициализирована в других модулях или потоках. Уже созданные потоки, конечно, не исчезнут, но активно работать одновременно будет столько, сколько указано, остальные будут ждать.
#include "tbb/parallel_for.h" #include "tbb/task_scheduler_init.h" #define TBB_PREVIEW_GLOBAL_CONTROL 1 #include "tbb/global_control.h" using namespace tbb; void foo() { // The following code could use up to 16 threads. task_scheduler_init tsi(16); parallel_for( . . . ); } void bar() { // The following code could use up to 8 threads. task_scheduler_init tsi(8); parallel_for( . . . ); } int main() { { const size_t parallelism = task_scheduler_init::default_num_threads(); // total parallelism that TBB can utilize is cut in half for the dynamic extension // of the given scope, including calls to foo() and bar() global_control c(global_control::max_allowed_parallelism, parallelism/2); foo(); bar(); } // restore previous parallelism limitation, if one existed } В этом примере функции foo() и bar() инициализируют TBB task scheduler локально. При этом объект global_control в main() устанавливает верхний лимит одновременно работающих потоков. Будь у нас ещё один task_scheduler_init вместо глобального контроля, ре-инициализация Intel TBB в foo() и bar() не произошла бы, т.к. главный поток уже имел бы активный task_scheduler_init. Локальные установки в foo() и bar() были бы проигнорированы, обе функции использовали бы ровно то число потоков, которое было установлено в main(). C global_control мы жёстко ограничиваем верхний предел (например, не больше 8 потоков), но это не мешает инициализировать библиотеку локально с меньшим числом потоков.
Объекты global_control могут быть вложенными. Когда мы создаём новый, он переписывает лимит потоков в меньшую сторону, в большую не может. Т.е. Если сначала создали global_control с 8 потоками, потом с 4, то ограничение будет 4. А если сначала с 8, потом с 12, ограничение будет 8. А когда объект global_control удаляется, восстанавливается предыдущее значение, т.е. минимум из установок всех «живых» объектов глобального контроля.
tbb::global_control пока является preview feature в Intel TBB 4.4. Кроме количества потоков, этот класс позволяет ограничить размер стэка для потоков через параметр thread_stack_size.
Flow Graph composite_node
Новый тип узла tbb::flow::composite_node позволяет «упаковывать» любое количество других узлов. Большие приложения с сотнями узлов могут быть лучше структурированы, собираясь из нескольких крупных блоков tbb::flow::composite_node, с определёнными интерфейсами входа и выхода.

Пример на картинке выше использует composite_node для инкапсуляции двух узлов, join_node и function_node. Концепция в том, чтобы продемонстрировать, что сумма первых n положительных нечётных чисел равна n в квадрате.
Сначала создаём класс adder. В нём есть join_node j с двумя входами и function_node f. j получает число на каждый из своих входов, и отсылает tuple из этих чисел на вход f, который складывает числа. Для инкапсуляции этих двух узлов adder наследуется от типа composite_node с двумя входами и одним выходом, что соответствует двум входам j и одному выходу f:
#include "tbb/flow_graph.h" #include <iostream> #include <tuple> using namespace tbb::flow; class adder : public composite_node< tuple< int, int >, tuple< int > > { join_node< tuple< int, int >, queueing > j; function_node< tuple< int, int >, int > f; typedef composite_node< tuple< int, int >, tuple< int > > base_type; struct f_body { int operator()( const tuple< int, int > &t ) { int n = (get<1>(t)+1)/2; int sum = get<0>(t) + get<1>(t); std::cout << "Sum of the first " << n <<" positive odd numbers is " << n <<" squared: " << sum << std::endl; return sum; } }; public: adder( graph &g) : base_type(g), j(g), f(g, unlimited, f_body() ) { make_edge( j, f ); base_type::input_ports_type input_tuple(input_port<0>(j), input_port<1>(j)); base_type::output_ports_type output_tuple(f); base_type::set_external_ports(input_tuple, output_tuple); } }; Дальше создаём split_node s, который будет служить источником положительных нечётных чисел. Используем первые 4 таких числа: 1, 3, 5 и 7. Создаём три объекта adder: a0, a1 и a2. Adder a0 получает 1 и 3 от split_node. Они складываются, и сумма отправляется к a1. Второй adder a1 получает сумму 1 и 3 с одного входного порта, и 5 со второго от split_node. Эти значения тоже складываются, и сумма отправляется в a2. Таким же образом, третий adder a2 получает сумму 1, 3 и 5 с одного входа и 7 со второго входа от split_node. Каждый adder пишет сумму, которую он вычислил, которая равна квадрату количества чисел в момент выполнения adder в графе.
int main() { graph g; split_node< tuple<int, int, int, int> > s(g); adder a0(g); adder a1(g); adder a2(g); make_edge(output_port<0>(s), input_port<0>(a0)); make_edge(output_port<1>(s), input_port<1>(a0)); make_edge(output_port<0>(a0),input_port<0>(a1)); make_edge(output_port<2>(s), input_port<1>(a1)); make_edge(output_port<0>(a1), input_port<0>(a2)); make_edge(output_port<3>(s), input_port<1>(a2)); s.try_put(std::make_tuple(1,3,5,7)); g.wait_for_all(); return 0; } Flow Graph async_node
Шаблонный класс async_node позволяет асинхронно работать с активностями, происходящими за пределами пула потоков Intel TBB. Например, если ваше Flow Graph приложение должно общаться со сторонним потоком, рантаймом или устройством, async_node может стать полезным. Он имеет интерфейсы для отправки результата обратно, поддерживая двустороннюю асинхронную коммуникацию между TBB Flow Graph и внешней для него сущностью. async_node является preview feature в Intel TBB 4.4.
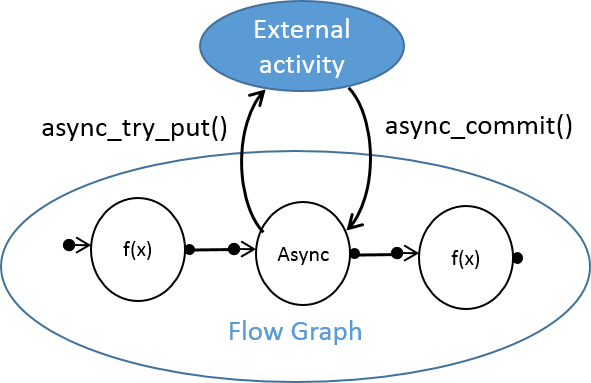
Сброс flow graph (reset)
Теперь можно сбрасывать состояние Flow Graph после некорректной остановки, например, выброшенного исключения или явной остановки (cancel). Вызовите tbb::flow::graph::reset(reset_flags f) для удаления всех рёбер графа (флаг reset(rf_clear_edges)) или сброса всех функциональных объектов (флаг reset(rf_reset_bodies)).
Ещё добавились (как preview) следующие операции над графом:
- Вырезание одного узла из графа
- Получение количества «предшественников» и «последователей» узла
- Получение копии всех «предшественников» и «последователей» узла
C++ 11
Операции перемещения (move operations) C++11 помогают избежать ненужного копирования данных. В Intel TBB 4.4 появились move-aware insert и emplace методы для контейнеров concurrent_unordered_map и concurrent_hash_map. concurrent_vector::shrink_to_fit был оптимизирован для типов, поддерживающих C++11 move semantics.
Контейнер tbb::enumerable_thread_specific получил move constructor и оператор присваивания. Локальные значения потока теперь могут быть сконструированы с произвольным числом аргументов с помощью конструктора, использующего variadic templates.
Заголовочный файл tbb/compat/thread автоматически включает C++11 где возможно. “Exact exception propagation” появилось для Intel C++ Compiler под OS X*.
Вы можете скачать последнюю версию Intel TBB c open source или коммерческого сайтов.
ссылка на оригинал статьи http://habrahabr.ru/post/266587/
Добавить комментарий