Вступление
В чем прелесть XML? Он реализован под все платформы, «человекочитаемый», для него созданы схемы данных (условно человекочитаемые). Открывая 25-мегабайтный файл в браузере сразу замечаешь недостатки этого текстового формата, и начинаешь задумываться. Делаем мы это, конечно, не часто, но все же — чем бы заменить XML?
Добавление самопальных бинарных контейнеров в проект заканчивается провалом, когда к вам приходят партнеры и просят подключить их к этому каналу данных. Google Protobuf поначалу выглядит хорошо, но вскоре понимаешь, что это не замена для XML, не хватает функциональности. BSON в 5 раз медленнее Protobuf, уступает в компактности и для него не реализованы схемы данных.
Разработаем же еще один бинарный формат.
USDS 1.0
USDS (или $S) — Universal serialized data structures — универсальные сериализованные структуры данных, бинарный формат, способный полностью заменить XML и JSON. Основные отличия:
- Вместо текстовых тегов/ключей используются целые числа. Соотношение «Имя» — «Целочисленный идентификатор» задается отдельно, в «Словаре». Словарь может быть прикреплен к документу USDS или может быть передан отдельно.
- Нет закрывающих тегов, как в XML;
- Документы USDS формируются строго по схеме, которая также задается в Словаре. Поддерживаются полиморфизм и опциональные поля.
- Числовые значения в документе USDS хранятся в бинарном виде (не как текст).
Допустим, мы задокументировали этот формат и создали первую версию библиотеки для работы с ним. Есть ли профит? Бенчмарк расставит все по своим местам:

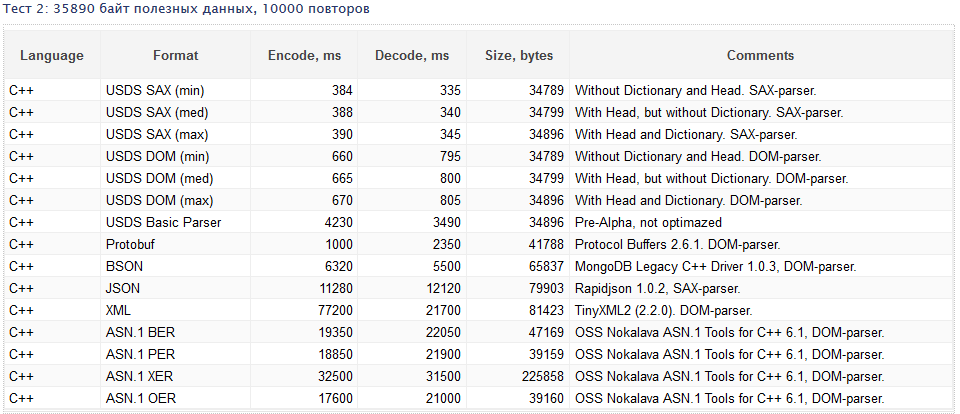
Что-то в этом уже есть, хотя работы еще не мало: Basic Parser всегда будет уступать Google Protobuf, но не на столько же.
Пример использования
Хоть формат и бинарный, использовать его не сложнее, чем XML. Посмотрим, как это будет выглядеть на С++ (а в далеком светлом будущем и на других языках).
Шаг 1: составляем Словарь
Как было сказано выше, документ USDS строится только по схеме, которая может выглядеть так:
USDS DICTIONARY ID=1000000 v.1.0 { 1: STRUCT internalObject { 1: UNSIGNED VARINT varintField; 1: UNSIGNED VARINT varintField; 2: DOUBLE doubleField; 3: STRING<UTF-8> stringField; 4: BOOLEAN booleanField; } RESTRICT {notRoot;} 2: STRUCT rootObject { 1: INT intField; 2: LONG longField; 3: ARRAY<internalObject> arrayField; } } Все правила построения схемы можно посмотреть здесь. Библиотека USDS Basic Parser пока что поддерживает далеко не все элементы схемы, но пример выше — рабочий. Сохраняем схему в текстовый файл, или вставляем прямо в исходный код, что дальше?
Шаг 2: инициализируем парсер:
Так или иначе, схема данных оказалась в массиве «text_dictionary», скормим его парсеру:
BasicParser* clientParser = new BasicParser(); clientParser->addDictionaryFromText(text_dictionary, strlen(text_dictionary), USDS_UTF8); Парсер готов генерировать бинарные USDS документы. Если вам необходимо только декодировать бинарники, то инициализация словарем не требуется: парсер автоматически вытащит словарь прямо из бинарного документа USDS.
Шаг 3: создаем бинарный документ:
Алгоритм ничем не отличается от работы с любым другим DOM-парсером: добавляем несколько корневых объектов, инициализируем их значениями, генерируем выходной массив данных.
UsdsStruct* tag = clientParser->addStructTag("rootObject"); tag->setFieldValue("intField", 1234); tag->setFieldValue("longField", 5000000000); ... BinaryOutput* usds_binary_doc = new BinaryOutput(); clientParser->encode(usds_binary_doc, true, true, true); const unsigned char* binary_data = usds_binary_doc->getBinary(); size_t binary_size = usds_binary_doc->getSize(); Особенности работы с массивами опущены, вы можете посмотреть их отдельно, скачав исходный код примера.
Шаг 4: декодирование бинарного документа:
Для чистоты эксперимента создадим отдельный объект парсера, не будем его инициализировать словарем и посмотрим, разберет ли он наш бинарный документ:
BasicParser* serverParser = new BasicParser(); serverParser->decode(binary_data, binary_size); int int_value = 0; long long long_value = 0; tag->getFieldValue("intField", &int_value); std::cout << "\tintField = " << int_value << "\n"; tag->getFieldValue("longField", &long_value); std::cout << "\tlongField = " << long_value << "\n"; Обратите внимание, что «Сервер» заранее ничего не знает о схеме данных, но спокойно получил бинарник, нашел в нем поля по их текстовым именам и корректно преобразовал их в значения переменных С++. Именно эта функция недоступна в Google Protobuf и ASN.1.
Вы можете существенно ускорить программу, если будете инициализировать поля по их числовым идентификаторам (ID, совпадают с теми, что указаны в Словаре), смотрите исходный код примера.
Человекочитаемость
Это действительно очень важная функция: вы не можете прочитать посторонний бинарный пакет Google Protobuf или ASN.1 (кроме XER), а иногда очень хочется. При использовании BSON можно преобразовать любой пакет данных в JSON, что уже неплохо. Не отстает от него и USDS:
std::string json; serverParser->getJSON(USDS_UTF8, &json); std::cout << "JSON:\n" << json << "\n"; Сервер не только получил произвольный бинарный документ, но и смог преобразовать его в JSON. Ту же операцию можно было выполнить и на стороне «Клиента»: сформировать DOM-объект и сразу преобразовать его в JSON, который также строго соответствует схеме данных.
В планы разработки USDS заложен редактор документов USDS с полноценным GUI. В ближайшем будущем в USDS Basic Parser будет реализована конвертация между XML, JSON и USDS в любом направлении.
Заключение
Зачем я опубликовал сырой продукт (Pre-Alpha), который настоятельно не рекомендуется использовать в проектах? Мне важен ваш отклик:
- чего не хватает в продукте?
- нужен ли он вообще?
- понятно ли написана документация и исходный код?
Отвечу в комментариях на любые вопросы.
Источники:
Страница проекта: USDS 1.0
Скачать библиотеку и исходный код примера можно здесь.
Исходный код библиотеки доступен здесь.
ссылка на оригинал статьи http://habrahabr.ru/post/270469/
Добавить комментарий