
В конце октября вышла новая версия HP Vertica. Команда разработчиков продолжила славные традиции выпуска строительной техники BigData и дала кодовое имя новой версии Excavator.
Изучив нововведения этой версии, я думаю название выбрано верное: все что нужно для работы с большими данными у HP Vertica уже было реализовано, теперь же нужно балансировать и улучшать существующее, то есть копать 🙂
Ознакомиться с полным списком нововведений можно в этом документе: http://my.vertica.com/docs/7.2.x/PDF/HP_Vertica_7.2.x_New_Features.pdf
Я же вкратце пройдусь по наиболее значимым с моей точки зрения изменениям.
Изменена политика лицензирования
В новой версии были изменены алгоритмы подсчета занимаемого размера данных в лицензии:
- Для табличных данных теперь при подсчете не учитывается 1 байт разделителя для числовых и дата-время полей;
- Для данных в зоне flex при подсчете размер лицензии считается, как 1/10 от размера загруженных JSON.
Таким образом, при переходе на новую версию, размер занимаемой лицензии вашего хранилища уменьшится, что особенно будет заметно на больших хранилищах данных, занимающих десятки и сотни терабайт.
Добавлена официальная поддержка RHEL 7 и CentOS 7
Теперь можно будет разворачивать кластер Vertica на более современных ОС Linux, что думаю должно обрадовать системных администраторов.
Оптимизировано хранение каталога базы данных
Формат хранения каталога данных в Vertica уже достаточно много версий оставался прежним. С учетом роста не только самих данных в базах данных, но и количества объектов в них и количества нод в кластерах, он уже перестал удовлетворять вопросам эффективности для высоконагруженных хранилищ данных. В новой версии была проведена оптимизация, с целью уменьшения размера каталога, что положительно сказалось на скорости его синхронизации между нодами и работе с ним при выполнении запросов.
Доработана интеграция с Apache решениями
Добавлена интеграция с Apache Kafka:
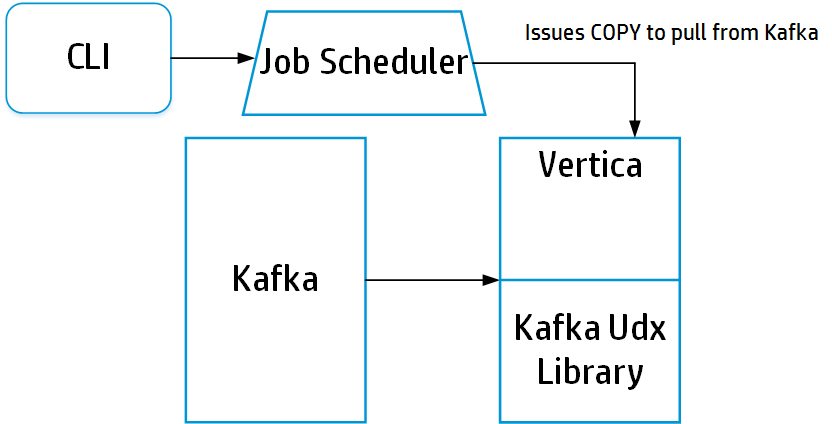
Такое решение позволяет организовать загрузку потоков в реальном времени через Kafka, где этот продукт будет заниматься сбором данных с потоков в JSON и далее параллельно загружать их в Flex зону хранилища Vertica. Все это позволит легко создавать загрузки потоковых данных без привлечения дорогостоящего ПО или ресурсоёмкой разработки собственных джобов на ETL.
Так же добавлена поддержка загрузки файлов с Apache HDFS в формате Avro. Это достаточно популярный формат хранения данных на HDFS и его поддержки раньше действительно очень не хватало.
Ну и работа Vertica с Hadoop стала настолько постоянным явлением у клиентов, что теперь нет необходимости устанавливать отдельно пакет работы с Hadoop в Vertica, он сразу в нее включен. Не забудьте только перед установкой новой версии удалить старый пакет интеграции с Hadoop!
Добавлены драйвера для Python
Теперь у Python для работы с Vertica есть собственные нативные полнофункциональные драйвера, официально поддерживаемые HP Vertica. Ранее разработчикам на Питоне приходилось довольствоваться ODBC драйверами, что создавало неудобства и дополнительные трудности. Теперь они смогут легко и просто работать с Vertica.
Улучшена функциональность драйверов JDBC
Добавлена возможность в рамках одной сессии одновременного выполнения множества запросов (Multiple Active Result Sets). Это позволяет сессии, для построения сложного аналитического запроса с разными секциями, одновременно запустить нужные запросы, которые по мере выполнения будут возвращать свои данные. Те данные, которые еще сессия не забрала с сервера, будут кэшироваться на его стороне.
Так же добавлена функциональность расчета хэш значения полей, аналогичного вызову функции Hash в Vertica. Это позволяет еще до загрузки записей в таблицу хранилища данных, рассчитать, на какие ноды они будут размещены по заданному ключу сегментации.
Расширено управление процессом восстановления нод кластера
Добавлена функциональность, которая позволяет установить приоритет recovery таблиц для восстанавливаемых нод. Это полезно, если требуется самостоятельно сбалансировать восстановление кластера, определив, какие таблицы будут восстановлены в числе первых, а какие лучше восстанавливать последними.
Добавлена новая функциональность механизма резервного копирования
- Можно проводить резервное копирование на локальные хосты нод;
- Можно восстановить из полной или объектной резервной копии выборочно схему или таблицу;
- С помощью функции COPY_PARTITIONS_TO_TABLE можно организовать шаринг хранения данных между несколькими таблицами с одинаковой структурой. После выполнения копирования данных партиций из таблицы в таблицу, они будут физически ссылаться на одни и те же ROS контейнеры скопированных партиций. При изменениях в этих партициях таблиц, у каждой далее появится своя версия изменений. Это дает возможность делать снапшоты партиций таблиц в другие таблицы для их использования, с гарантией, что исходные данные оригинальной таблицы останутся целыми, с высокой скоростью, без затрат на хранение скопированных данных на дисках.
- При объектном восстановлении можно указать поведение при существовании восстанавливаемого объекта. Vertica может его создать, если его еще нет в базе данных, не восстанавливать, если он есть, пересоздать из резервной копии или же создать рядом с существующим новый объект с префиксом в имени таблицы наименования резервной копии и ее даты.
Улучшена работа оптимизатора
При соединениях таблиц методом HASH JOIN, процесс обработки соединения мог занимать достаточно много времени, если обе соединяемых таблицы имели большое количество записей. Фактически приходилось на таблицу внешнего соединения строить хэш таблицу значений и далее сканируя таблицу внутренего соединения, искать хэш в созданной хэш таблице. Теперь в новой версии сканирование в хэш таблице сделано параллельным, что должно в разы улучшить скорость соединения таблиц таким методом.
Для планов запросов реализована возможность с помощью хинтов в запросе создавать сценарии планов запросов: указывать явный порядок соединения таблиц, алгоритмы их соединения и сегментации, перечислять проекции, которые можно или нельзя использовать при выполнении запроса. Это позволяет более гибко добиваться от оптимизатора построения эффективных планов запросов. А чтобы BI системы могли воспользоваться такой оптимизацией при выполнении типовых запросов без требования вносить описания хинтов, в Vertica добавлена возможность сохранения сценария таких запросов. Любая сессия, выполняющая запрос, подходящий по шаблону к сохраненному по сценарию, будет получать уже описанный оптимальный план запроса и работать по нему.
Для оптимизации выполнения запросов с множеством вычислений в вычисляемых полях или условиях, включая like, в Vertica добавлена JIT компиляция выражений запроса. Ранее использовалась интерпретация выражений и это сильно деградировало скорость выполнения запросов, в которых, например, встречались десятки like выражений.
Расширена функциональность проверки целостности данных
Ранее Vertica при описании ограничений на таблицы проверяла только NOT NULL условие при загрузке и изменении данных. Полностью все ограничения PK, FK и UK проверялись только при одиночных DML операторах INSERT и UPDATE, а также для оператора MERGE, алгоритм работы которого напрямую зависит от соблюдения целостности PK и FK ограничений. Проверить же на нарушение целостности значений всех ограничений можно было с помощью специальной функции, которая выдавала список нарушающих ограничения записей.
Теперь в новой версии можно включить проверку всех ограничений для групповых DML операторов и COPY на все или только нужные таблицы. Это позволяет более гибко реализовывать проверки чистоты загружаемых данных и выбирать между скоростью загрузки данных и простотой проверки их целостности. Если данные в хранилище поступают из надежных источников и в больших объемах, разумно не включать проверку ограничений на такие таблицы. Если же объем поступающих данных не критичен, а вот их чистота под вопросом, проще включить проверки, чем реализовывать самостоятельно механизм их проверок на ETL.
Объявление Depricated
Увы, любое развитие продукта всегда не только добавляет функциональность, но и избавляется от устаревшей. В данной версии Vertica объявлено устаревшим не так много, но есть пару значимых объявлений, о которых стоит задуматься:
- Поддержка файловой системы ext3
- Поддержка pre-join проекций
Оба пункта достаточно критичны для клиентов Vertica. Те, кто давно уже работает с этим сервером, могут запросто иметь кластера еще на старой фс ext3. И так же я знаю, многие, для оптимизации запросов к созвездиям используют pre-join проекции. В любом случае, явной версии удаления поддержки этих функций не указано и время к этому подготовиться у клиентов Vertica есть думаю, как минимум еще пару лет.
Резюмируя впечатления о новой версии
В этой статье перечислена только половина того, что добавилось в Vertica. Объем расширения функционала впечатляет, однако я перечислил только то, что актуально для всех проектов построения хранилищ данных. Если вы используете полнотекстовый поиск, гео-локацию, расширенный security и прочие крутые фишки, реализованные в Vertica, то все изменения по ним вы можете прочитать по ссылке, что я дал в начале статьи или документации по новой версии Vertica:
https://my.vertica.com/docs/7.2.x/HTML/index.htm
От себя же скажу: работая с хранилищами данных большого объема на HP Vertica в десятки терабайт в разных проектах, я оцениваю изменения новой версии очень положительно. В ней действительно реализовано многое то, что хотелось бы получить и облегчить разработку и сопровождение хранилищ данных.
ссылка на оригинал статьи http://habrahabr.ru/post/270755/
Добавить комментарий