Недавно я вспомнил об замечательной интеллектуальной игре «Балда», с которой я познакомился еще в школьные годы.
На днях я задался вопросом – насколько сложно будет реализовать алгоритм этой игры для компьютерного соперника?
Так как мне больше всего нравится работать с реляционными данными и моим любимым языком является SQL, то я решил совместить приятное с полезным и попробовать написать этот алгоритм используя только TSQL. Это моя первая попытка написать ИИ используя только возможности SQL.
Архив с файлами можно скачать по следующей ссылке – скрипты.
Все слова в словаре в верхнем регистре, а также в нем буквы «Е» и «Ё» считаются за одну (как «Е»).
В результате была создана следующая схема:
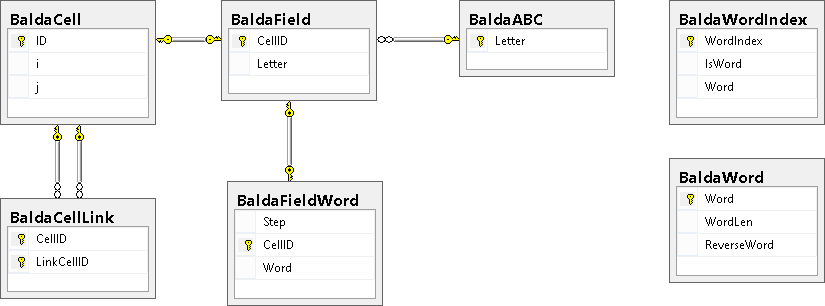
Описание таблиц:
- BaldaCell – Ячейки (i – номер строки, j – номер столбца)
- BaldaCellLink – Связи ячейки с другими ячейками
- BaldaABC – Алфавит (буквы, которые используются для составления слов)
- BaldaField – Используется для текущего описания состояния игрового поля
- BaldaFieldWord – Используется для запоминания уже использованных слов
- BaldaWord – Словарь, используемый компьютером для поиска подходящих слов
- BaldaWordIndex – Вспомогательная индексная таблица, используемая для более оптимального выполнения запроса
Скрипт для создания и наполнения таблиц:
/* DROP TABLE BaldaWord DROP TABLE BaldaFieldWord DROP TABLE BaldaField DROP TABLE BaldaCellLink DROP TABLE BaldaCell DROP TABLE BaldaABC DROP TABLE BaldaWordIndex */ -------------------------------------------------------------------- -- ячейки поля -------------------------------------------------------------------- CREATE TABLE BaldaCell( ID int NOT NULL, i int NOT NULL, j int NOT NULL, CONSTRAINT PK_BaldaCell PRIMARY KEY(ID) ) GO -- размеры поля DECLARE @MaxW int=5 DECLARE @MaxH int=5 -- наполнение ячеек ;WITH iCte AS( SELECT 1 i UNION ALL SELECT i+1 FROM iCte WHERE i<@MaxW ), jCte AS( SELECT 1 j UNION ALL SELECT j+1 FROM jCte WHERE j<@MaxH ) INSERT BaldaCell(ID,i,j) SELECT 10000+i*100+j,i,j FROM iCte CROSS JOIN jCte OPTION(MAXRECURSION 0) GO -------------------------------------------------------------------- -- связи между ячейками -------------------------------------------------------------------- CREATE TABLE BaldaCellLink( CellID int NOT NULL, LinkCellID int NOT NULL, CONSTRAINT PK_BaldaCellLink PRIMARY KEY(CellID,LinkCellID), CONSTRAINT FK_BaldaCellLink_CellID FOREIGN KEY(CellID) REFERENCES BaldaCell(ID), CONSTRAINT FK_BaldaCellLink_LinkCellID FOREIGN KEY(LinkCellID) REFERENCES BaldaCell(ID) ) GO -- заполняем связи INSERT BaldaCellLink(CellID,LinkCellID) SELECT c.ID,l.ID FROM BaldaCell c JOIN BaldaCell l ON (c.j=l.j AND c.i IN(l.i-1,l.i+1)) OR (c.i=l.i AND c.j IN(l.j-1,l.j+1)) GO /* SELECT * FROM BaldaCellLink WHERE CellID=10303 -- 4 соседа SELECT * FROM BaldaCellLink WHERE CellID=10503 -- 3 соседа SELECT * FROM BaldaCellLink WHERE CellID=10105 -- 2 соседа */ -------------------------------------------------------------------- -- алфавит -------------------------------------------------------------------- CREATE TABLE BaldaABC( Letter nchar(1) NOT NULL, CONSTRAINT PK_BaldaABC PRIMARY KEY(Letter) ) GO -- наполняем допустимыми буквами INSERT BaldaABC(Letter) VALUES (N'А'),(N'Б'),(N'В'),(N'Г'),(N'Д'),(N'Е'),(N'Ж'),(N'З'),(N'И'),(N'Й'), (N'К'),(N'Л'),(N'М'),(N'Н'),(N'О'),(N'П'),(N'Р'),(N'С'),(N'Т'),(N'У'), (N'Ф'),(N'Х'),(N'Ц'),(N'Ч'),(N'Ш'),(N'Щ'),(N'Ъ'),(N'Ы'),(N'Ь'),(N'Э'), (N'Ю'),(N'Я') GO -------------------------------------------------------------------- -- состояние игрового поля -------------------------------------------------------------------- CREATE TABLE BaldaField( CellID int NOT NULL, Letter nchar(1) NOT NULL, CONSTRAINT PK_BaldaField PRIMARY KEY(CellID), CONSTRAINT FK_BaldaField_CellID FOREIGN KEY(CellID) REFERENCES BaldaCell(ID), CONSTRAINT FK_BaldaField_Letter FOREIGN KEY(Letter) REFERENCES BaldaABC(Letter) ) GO -------------------------------------------------------------------- -- использованные слова -------------------------------------------------------------------- CREATE TABLE BaldaFieldWord( Step int NOT NULL, CellID int NOT NULL, Word nvarchar(50) NOT NULL, CONSTRAINT PK_BaldaFieldWord PRIMARY KEY(CellID), CONSTRAINT UK_BaldaFieldWord UNIQUE(Word), CONSTRAINT FK_BaldaFieldWord_CellID FOREIGN KEY(CellID) REFERENCES BaldaField(CellID) ON DELETE CASCADE, ) GO -------------------------------------------------------------------- -- словарь -------------------------------------------------------------------- CREATE TABLE BaldaWord( Word nvarchar(50) NOT NULL, WordLen int NOT NULL, ReverseWord nvarchar(50) NOT NULL, CONSTRAINT PK_Word PRIMARY KEY(Word) ) GO CREATE TABLE #TempWord( Word nvarchar(50) NOT NULL ) -- загружаем данные из текстового файла (ASCII) BULK INSERT #TempWord FROM 'd:\Temp\Словарь.txt' WITH ( FIRSTROW = 1, FIELDTERMINATOR = ',', ROWTERMINATOR = '\n', CODEPAGE = 'ACP' ); INSERT BaldaWord(Word,WordLen,ReverseWord) SELECT Word,LEN(Word),REVERSE(Word) FROM #TempWord DROP TABLE #TempWord -------------------------------------------------------------------- -- индекс для отсеивания по началу/концу слов -------------------------------------------------------------------- CREATE TABLE BaldaWordIndex( WordIndex nvarchar(50) NOT NULL, CONSTRAINT PK_BaldaWordIndex PRIMARY KEY(WordIndex) ) GO DECLARE @MaxWordLen int=(SELECT MAX(WordLen) FROM BaldaWord) DECLARE @IndexLen int=2 WHILE @IndexLen<@MaxWordLen BEGIN INSERT BaldaWordIndex(WordIndex) SELECT LEFT(Word,@IndexLen) FROM BaldaWord WHERE LEN(LEFT(Word,@IndexLen))=@IndexLen UNION SELECT LEFT(ReverseWord,@IndexLen) FROM BaldaWord WHERE LEN(LEFT(ReverseWord,@IndexLen))=@IndexLen SET @IndexLen+=1 END GO Алгоритм поиска (первая версия):
-- очистка поля DELETE BaldaField -- буквы первого слова INSERT BaldaField(CellID,Letter) VALUES (10301,N'С'), (10302,N'Л'), (10303,N'О'), (10304,N'В'), (10305,N'О') -- первое слово INSERT BaldaFieldWord(Step,CellID,Word) VALUES(0,10301,N'СЛОВО') /* INSERT BaldaField(CellID,Letter) VALUES (10301,N'Т'), (10302,N'Р'), (10303,N'О'), (10304,N'П'), (10305,N'А') INSERT BaldaFieldWord(Step,CellID,Word) VALUES(0,10301,N'ТРОПА') */ /* INSERT BaldaField(CellID,Letter) VALUES (10301,N'Ш'), (10302,N'К'), (10303,N'А'), (10304,N'Л'), (10305,N'А') INSERT BaldaFieldWord(Step,CellID,Word) VALUES(0,10301,N'ШКАЛА') */ DECLARE @Step int=1 DECLARE @NewCellID int=0 DECLARE @NewLetter nchar(1) DECLARE @Word nvarchar(50) DECLARE @WordLen int WHILE @NewCellID IS NOT NULL BEGIN -- основной рекурсивный запрос WITH newWordCte AS( SELECT CellID NewCellID, Letter NewLetter, CellID, CAST(Letter AS nvarchar(50)) Word, 1 WordLen, CAST(CellID AS varchar(300)) CellPath FROM ( SELECT l.LinkCellID CellID,abc.Letter FROM BaldaField f -- будем анализировать все пустые соседние ячейки JOIN BaldaCellLink l ON f.CellID=l.CellID AND l.LinkCellID NOT IN(SELECT CellID FROM BaldaField) -- подставляя в них каждую букву CROSS JOIN BaldaABC abc ) q UNION ALL SELECT w.NewCellID, w.NewLetter, f.CellID, CAST(w.Word+f.Letter AS nvarchar(50)), w.WordLen+1, CAST(w.CellPath+','+CAST(f.CellID AS varchar(10)) AS varchar(300)) FROM newWordCte w JOIN BaldaCellLink l ON w.CellID=l.CellID JOIN BaldaField f ON f.CellID=l.LinkCellID -- оставляем только те цепочки которые соответствуют индексу JOIN BaldaWordIndex i ON w.Word+f.Letter=i.WordIndex -- делаем проверку, чтобы исключить зацикливание WHERE CHARINDEX(CAST(f.CellID AS varchar(10)),w.CellPath)=0 ) SELECT DISTINCT NewCellID,NewLetter,Word INTO #ResultAll FROM newWordCte WHERE WordLen>1 -- т.к. слова с одной буквой не используются OPTION(MAXRECURSION 0); SELECT TOP 1 WITH TIES -- оставляем только самые длинные слова NewCellID, NewLetter, Word, WordLen INTO #Result FROM ( -- оставляем слова, которые есть в словаре SELECT r.NewCellID,r.NewLetter,w.Word,w.WordLen FROM #ResultAll r JOIN BaldaWord w ON r.Word=w.Word WHERE w.Word NOT IN(SELECT Word FROM BaldaFieldWord) UNION -- если слово написано в обратном направлении SELECT r.NewCellID,r.NewLetter,w.Word,w.WordLen FROM #ResultAll r JOIN BaldaWord w ON r.Word=w.ReverseWord WHERE w.Word NOT IN(SELECT Word FROM BaldaFieldWord) UNION -- на тот случай, если слов не найдено SELECT NULL,NULL,NULL,-1 ) q ORDER BY WordLen DESC DROP TABLE #ResultAll -- эмитируем ИИ DECLARE @RowCount int=(SELECT COUNT(*) FROM #Result) SELECT @NewCellID=NewCellID, @NewLetter=NewLetter, @Word=Word, @WordLen=WordLen FROM #Result ORDER BY NewCellID OFFSET CAST(FLOOR(RAND()*@RowCount) AS int) ROWS FETCH NEXT 1 ROWS ONLY DROP TABLE #Result IF @NewCellID IS NOT NULL BEGIN -- запоминаем результат INSERT BaldaField(CellID,Letter) VALUES(@NewCellID,@NewLetter) INSERT BaldaFieldWord(Step,CellID,Word) VALUES(@Step,@NewCellID,@Word) SET @Step+=1 END END На моем компьютере данный скрипт выполняется примерно 2 секунды.
Для просмотра результата используем следующие 2 запроса:
-- найденные слова SELECT uw.Step,c.i,c.j,f.Letter,uw.Word,LEN(uw.Word) WordLen FROM BaldaFieldWord uw JOIN BaldaField f ON uw.CellID=f.CellID JOIN BaldaCell c ON c.ID=f.CellID ORDER BY uw.Step -- вид игрового поля SELECT * FROM ( SELECT c.i,c.j,f.Letter FROM BaldaCell c LEFT JOIN BaldaField f ON c.ID=f.CellID ) q PIVOT(MAX(Letter) FOR j IN([1],[2],[3],[4],[5])) p ORDER BY i Результат:
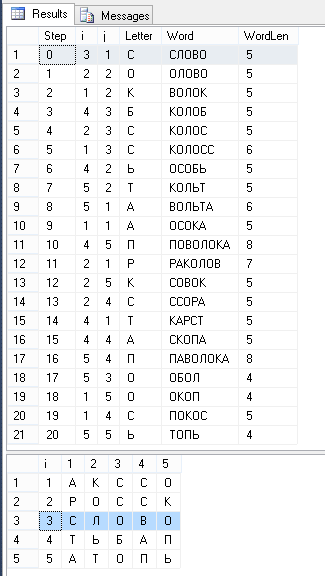
Пока готовил статью придумал более оптимальный вариант, который выигрывает по скорости почти в 2 раза (особенно заметно при расширении размеров поля). Во втором варианте расширена вспомогательная таблица BaldaWordIndex, за счет чего мы можем не использовать таблицу BaldaWord.
Скрипт для пересоздания таблицы BaldaWordIndex:
-------------------------------------------------------------------- -- индекс для отсеивания по началу/концу слов - версия 2 -------------------------------------------------------------------- DROP TABLE BaldaWordIndex GO CREATE TABLE BaldaWordIndex( WordIndex nvarchar(50) NOT NULL, IsWord bit NOT NULL, Word nvarchar(50), CONSTRAINT PK_BaldaWordIndex PRIMARY KEY(WordIndex) ) GO DECLARE @MaxWordLen int=(SELECT MAX(WordLen) FROM BaldaWord) DECLARE @IndexLen int=2 WHILE @IndexLen<=@MaxWordLen BEGIN INSERT BaldaWordIndex(WordIndex,IsWord,Word) SELECT WordIndex,MAX(IsWord),MAX(Word) FROM ( SELECT LEFT(Word,@IndexLen) WordIndex,IIF(LEN(Word)=@IndexLen,1,0) IsWord,IIF(LEN(Word)=@IndexLen,Word,NULL) Word FROM BaldaWord WHERE LEN(LEFT(Word,@IndexLen))=@IndexLen UNION SELECT LEFT(ReverseWord,@IndexLen),IIF(LEN(Word)=@IndexLen,1,0),IIF(LEN(Word)=@IndexLen,Word,NULL) FROM BaldaWord WHERE LEN(LEFT(ReverseWord,@IndexLen))=@IndexLen ) q GROUP BY WordIndex SET @IndexLen+=1 END GO /* SELECT COUNT(*) FROM BaldaWordIndex WHERE IsWord=1 SELECT COUNT(*) FROM ( SELECT Word FROM BaldaWord UNION SELECT ReverseWord FROM BaldaWord ) q */ Новый алгоритм поиска:
-- очистка поля DELETE BaldaField -- буквы первого слова INSERT BaldaField(CellID,Letter) VALUES (10301,N'С'), (10302,N'Л'), (10303,N'О'), (10304,N'В'), (10305,N'О') -- первое слово INSERT BaldaFieldWord(Step,CellID,Word) VALUES(0,10301,N'СЛОВО') /* INSERT BaldaField(CellID,Letter) VALUES (10301,N'Т'), (10302,N'Р'), (10303,N'О'), (10304,N'П'), (10305,N'А') INSERT BaldaFieldWord(Step,CellID,Word) VALUES(0,10301,N'ТРОПА') */ /* INSERT BaldaField(CellID,Letter) VALUES (10301,N'Ш'), (10302,N'К'), (10303,N'А'), (10304,N'Л'), (10305,N'А') INSERT BaldaFieldWord(Step,CellID,Word) VALUES(0,10301,N'ШКАЛА') */ DECLARE @Step int=1 DECLARE @NewCellID int=0 DECLARE @NewLetter nchar(1) DECLARE @Word nvarchar(50) DECLARE @WordLen int WHILE @NewCellID IS NOT NULL BEGIN -- основной рекурсивный запрос WITH newWordCte AS( SELECT CellID NewCellID, Letter NewLetter, CellID, CAST(Letter AS nvarchar(50)) Word, 1 WordLen, CAST(CellID AS varchar(300)) CellPath, CAST(0 AS bit) IsWord, CAST(NULL AS nvarchar(50)) ResWord FROM ( SELECT l.LinkCellID CellID,abc.Letter FROM BaldaField f -- будем анализировать все пустые соседние ячейки JOIN BaldaCellLink l ON f.CellID=l.CellID AND l.LinkCellID NOT IN(SELECT CellID FROM BaldaField) -- подставляя в них каждую букву CROSS JOIN BaldaABC abc ) q UNION ALL SELECT w.NewCellID, w.NewLetter, f.CellID, CAST(w.Word+f.Letter AS nvarchar(50)), w.WordLen+1, CAST(w.CellPath+','+CAST(f.CellID AS varchar(10)) AS varchar(300)), i.IsWord, i.Word FROM newWordCte w JOIN BaldaCellLink l ON w.CellID=l.CellID JOIN BaldaField f ON f.CellID=l.LinkCellID -- оставляем только те цепочки которые соответствуют индексу JOIN BaldaWordIndex i ON w.Word+f.Letter=i.WordIndex -- делаем проверку, чтобы исключить зацикливание WHERE CHARINDEX(CAST(f.CellID AS varchar(10)),w.CellPath)=0 ) SELECT TOP 1 WITH TIES -- оставляем только самые длинные слова NewCellID, NewLetter, Word, WordLen INTO #Result FROM ( SELECT DISTINCT NewCellID,NewLetter,ResWord Word,WordLen FROM newWordCte WHERE IsWord=1 -- отбираем только полные слова AND ResWord NOT IN(SELECT Word FROM BaldaFieldWord) UNION ALL -- на тот случай, если слов не найдено SELECT NULL,NULL,NULL,-1 ) q ORDER BY WordLen DESC OPTION(MAXRECURSION 0); -- эмитируем ИИ DECLARE @RowCount int=(SELECT COUNT(*) FROM #Result) SELECT @NewCellID=NewCellID, @NewLetter=NewLetter, @Word=Word, @WordLen=WordLen FROM #Result ORDER BY NewCellID OFFSET CAST(FLOOR(RAND()*@RowCount) AS int) ROWS FETCH NEXT 1 ROWS ONLY DROP TABLE #Result IF @NewCellID IS NOT NULL BEGIN -- запоминаем результат INSERT BaldaField(CellID,Letter) VALUES(@NewCellID,@NewLetter) INSERT BaldaFieldWord(Step,CellID,Word) VALUES(@Step,@NewCellID,@Word) SET @Step+=1 END END Новая версия скрипта на моем компьютере выполняется примерно за 1 секунду.
Для просмотра результата снова используем следующие 2 запроса:
-- найденные слова SELECT uw.Step,c.i,c.j,f.Letter,uw.Word,LEN(uw.Word) WordLen FROM BaldaFieldWord uw JOIN BaldaField f ON uw.CellID=f.CellID JOIN BaldaCell c ON c.ID=f.CellID ORDER BY uw.Step -- вид игрового поля SELECT * FROM ( SELECT c.i,c.j,f.Letter FROM BaldaCell c LEFT JOIN BaldaField f ON c.ID=f.CellID ) q PIVOT(MAX(Letter) FOR j IN([1],[2],[3],[4],[5])) p ORDER BY i Собственно, все.
Данная работа была проделана на скорую руку и больше из спортивного интереса, чтобы немного освежить память, а также посмотреть насколько оптимальным и быстрым получится решение с использованием SQL.
На мой взгляд решение получилось неплохое и достаточно прозрачное – SQL хорошо справился с данной задачей. Основной рекурсивный запрос можно без особого труда переписать на любой другой диалект SQL в котором есть поддержка рекурсивных CTE-выражений.
Изучайте SQL – это замечательный язык для манипуляции с данными.
Надеюсь, что статья была интересна.
Удачи и спасибо за внимание!
ссылка на оригинал статьи http://habrahabr.ru/post/271795/
Добавить комментарий