Мы (Алексей Бурнаков и Роман Гудченко) в прошедшие выходные упорно участвовали в хакатоне, организованном Microsoft: ссылка.
Мы выбрали задачу от Альфа-Банка про прогнозирование оттока клиентов. Краткая суть:
Перед вами набор данных, состоящий из 3-х поколений (3 последовательных отчетных месяцев) активных клиентов, часть из которых спустя 2 месяца стали неактивными, т.е. ушли в отток (поле target = 1) Тестовый набор данных содержит следующее, 4-ое поколение активных клиентов.
Цель:
Для представленного набора данных построить бинарный классификатор вероятного оттока клиентов спустя 2 месяца.
Критерий качества оценки – AUC, по результатам проверки на контрольном наборе.
Работать предполагалось на сервисе Azure Machine Learning — вэб-платформа с вычислениями в облаке и всеми необходимыми интегрированными инструментами: Azure.
С платформой впервые мы познакомились на кануне в пятницу, 27 ноября. 29 вечером отмечали победу. Это большой плюс сервиса, так как порог входа для новичка невысок, а вот знания в сфере машинного обучения для успешного применения встроенных моделей требуются.
Я сразу расскажу про модель, которая у нас получилась. Сделаю оговорку, что в силу ограниченного времени приходилось работать быстро и 99% возможных гипотез о данных не были проверены. По сути, мы подавали немного предобработанные данные и нажимали кнопку Run. Этакий фастфуд мира data mining. В обычной работе (а мы работаем в команде BI компании Align Technology), конечно, на первом месте идет кропотливый разбор данных, проверка статистических гипотез, выбор вариантов нормализации данных, подбор и сравнение моделей. Но можно отметить, что Azure также позволяет сделать это довольно комфортно.
Наш результат:
Стадия предобработки данных

Во-первых мы решили убрать из набора данных все переменные типа string, потому что многие модели не хотели на них обучаться и выдавали ошибку — модуль Project Columns.
Во-вторых мы заменили missing data на одну из мер центральной тенденции, и анализ значимости полученных переменных показал, что бывшие миссинги статистически значимо влияют на Target.
В-третьих из обучающего наборы был исключен столбец с ID.
Данные были разделены на обучающий и тестовый наборы с помощью модуля Split Data в пропорции 70/30.
Первый слой обучения: «слабые» классификаторы

На нижнем уровне мы выбрали 3 классификаторы исходя из нашего опыта и после нескольких проб всех доступных моделей two-sample classifier с использованием модуля Sweep Parameters. Пример быстрого доступа к интересным нам моделям:

Реально удобно, но мы сошлись на мнении, что, в целом, сервис для индусов. То есть, все по максимуму стандартизовано и с защитой от дурака.
Выбор пал на boosted decision trees, neural network, logistic regression. Для каждой из моделей мы выбрали по 3 набора параметров (из Sweep Parameters), которые можно характезировать как а) наиболее слабая модель, б) средней сложности модель, в) модель повышенной сложности. Это и количество деревьев и эпохи обучения и learning rate.
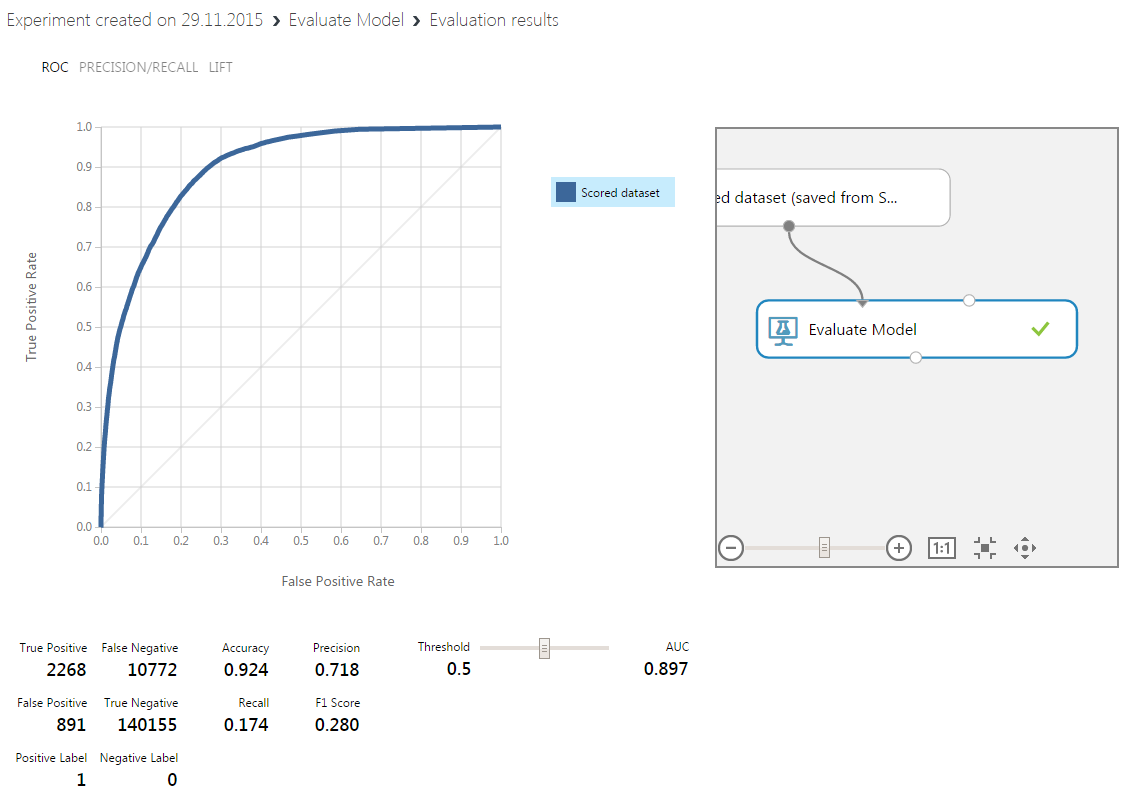
Получили 9 вариантов предсказаний, из которых ускоренный лес деревьев дал наилучший результат, примерно соответствующий уровню попавших в тройку лучших моделей на этой задаче:

В реальности, метрика была немного лучше (я уже переобучил модель с другими параметрами).
Логистическая регрессия и слабая нейронная сеть дали результаты похуже.
Второй слой обучения:
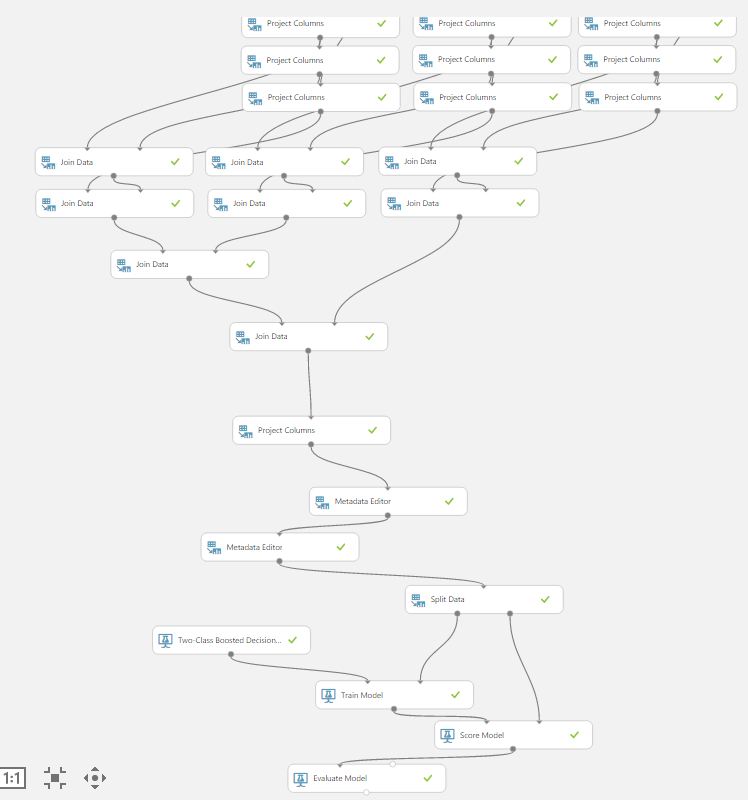
Мы приняли решение подать предсказания всех 9-ти моделей первого слоя в качестве обучающего набора на модель второго слоя, в качестве которой был выбран также ускоренный лес деревьев решений. Таким образом мы реализовали концепцию Stacking (мета-обучение), которая при некоторых допущениях даст результат не хуже, чем лучший из «слабых» моделей. У нас это и получилось в результате.
Заметим, что на второй слой шли результаты, полученные на тестовом наборе (30%) выборки.
Для того, чтобы второй корректно отработал на входах-выходах первого слоя нужно колдовство с MetaData Editor:

Все. Плюс к сказанному — мы делали одновременно разные части работы и копировали друг у друга получившиеся эксперименты для доработок. В результате к 15:00 подошли с двумя одинаковыми архитектурами, но с разными параметрами обучаемых моделей. Выбрана была лучшая согласно наших представлениям.
Отметим, что обучение на наборе из 400+ К строк и 100+ столбцов в облаке Azure происходило быстрее, чем мы думали — около 10 минут. Мы даже успели пообедать до того, как в 15:55 расшарили workspace с экспертами MS.
Также советуем вам обратить внимание на правила оформления workspace и experiments. Мы чуть не попали в просак, назвав наше рабочее пространство произвольным именем, и пришлось досабмитить модель уже перед самым объявлением победителей.
Сорри, МикроЯндекс, мы вас оставили на почетном втором месте. Респект СПб за почетное третье место.
Из минусов сервиса, которые можно, кстати, списать на наше нубство, мы не смогли найти как вывести список переменных с типами. И капитан команды Роман юзал ночью SQL и R, чтобы создать такую банальную таблицу вывода. А я руками просеивал столбцы и наполнял Project Columns. Отметим, что, возможно, стринговые переменные могут еще улучшить качество прогноза, если их хорошо приготовить и тщательно переварить.
Спасибо за внимание.
Роман, Алексей.
PS: Спасибо Татьяне за отличную организацию.
ссылка на оригинал статьи http://habrahabr.ru/post/271975/
Добавить комментарий