Подвернулась мне задача — запустить Proxmox и несколько виртуалок на сервере всего с 2 дисками. При этом требовалось обеспечить ну хоть какую-то надежность и простоту исправления проблем связанных с выходом из строя одного из дисков. Далее в заметке подробное описание тестирования решения на стенде.
Вводная
Я считаю что читатель данной заметки может самостоятельно установить Proxmox на ноду и не буду рассматривать установку и настройку самого гипервизора. Рассмотрим только настройки касающиеся ZFS RAID1 и тестирование ситуации сбоя одного из дисков.
Железо на котором предстояло развернуть проект представляло из себя ноду Supermicro, видимо в исполнении 2 node in 1U с псевдо-рейдом интегрированном в чипсет от Intel который не поддерживается в Proxmox. В связи с этим попробуем испытать решение предлагаемое «из коробки» в версии 4.0. Хоть убейте — я не помню был-ли такой вариант установки в Proxmox 3.6, может и был, но не отложилось в памяти из-за невостребованности такой конфигурации. В тестовой стойке у нас отыскался аналогичный сервер и я принялся за проверку решения, предоставляемого ребятами из Proxmox Server Solutions.
Установка
Как и предупреждал — не буду показывать установку полностью, заострю внимание только на важных моментах.
Выбираем zfs RAID1:
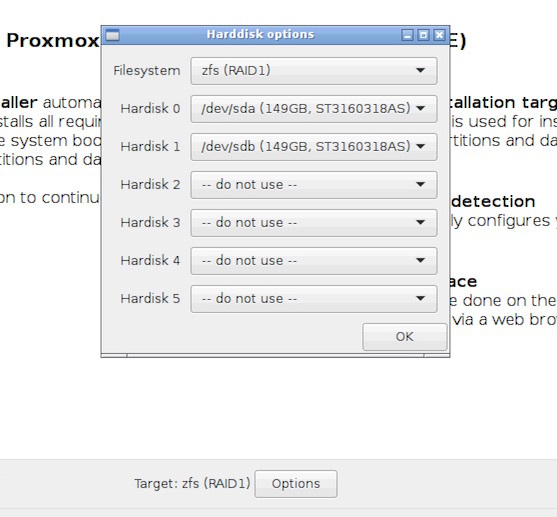
Сервер тестовый и нет подписки на коммерческий репозиторий. В /etc/apt/sources.list подключаем бесплатный:
deb http://download.proxmox.com/debian jessie pve-no-subscription В /etc/apt/sources.list.d/pve-enterprise.list закомментируем коммерческий.
Ну и вдруг забудете:
root@pve1:~# apt-get update && apt-get upgrade Смотрим что нам нарезал инсталлятор на дисках (привожу только часть вывода):
root@pve1:~# fdisk -l /dev/sd* Disk /dev/sda: 149.1 GiB, 160041885696 bytes, 312581808 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: gpt Disk identifier: 758FA29C-4F49-4315-BA0C-F3CCC921FA01 Device Start End Sectors Size Type /dev/sda1 34 2047 2014 1007K BIOS boot /dev/sda2 2048 312565389 312563342 149G Solaris /usr & Apple ZFS /dev/sda9 312565390 312581774 16385 8M Solaris reserved 1 Disk /dev/sdb: 149.1 GiB, 160041885696 bytes, 312581808 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: gpt Disk identifier: 3CD4B489-A51D-4354-8018-B1391F52B08D Device Start End Sectors Size Type /dev/sdb1 34 2047 2014 1007K BIOS boot /dev/sdb2 2048 312565389 312563342 149G Solaris /usr & Apple ZFS /dev/sdb9 312565390 312581774 16385 8M Solaris reserved 1 Глянем на наш массив:
root@pve1:~# zpool status rpool pool: rpool state: ONLINE scan: none requested config: NAME STATE READ WRITE CKSUM rpool ONLINE 0 0 0 mirror-0 ONLINE 0 0 0 sda2 ONLINE 0 0 0 sdb2 ONLINE 0 0 0 errors: No known data errors По умолчанию инсталлятор Proxmox установил загрузчик на оба раздела — отлично!
Тестирование
Имитируем отказ жесткого диска следующим образом:
— выключаем сервер;
— выдергиваем одну из корзин;
— включаем сервер.
Сервер прекрасно грузится на любом из двух оставшихся дисков, массив работает в режиме DEGRADED и любезно подсказывает какой диск нам надо сменить и как это сделать:
root@pve1:~# zpool status rpool pool: rpool state: DEGRADED status: One or more devices could not be used because the label is missing or invalid. Sufficient replicas exist for the pool to continue functioning in a degraded state. action: Replace the device using 'zpool replace'. see: http://zfsonlinux.org/msg/ZFS-8000-4J scan: none requested config: NAME STATE READ WRITE CKSUM rpool DEGRADED 0 0 0 mirror-0 DEGRADED 0 0 0 14981255989033513363 FAULTED 0 0 0 was /dev/sda2 sda2 ONLINE 0 0 0 errors: No known data errors Если вернуть извлеченный диск на место — он прекрасно «встает» обратно в зеркало:
root@pve1:~# zpool status rpool pool: rpool state: ONLINE status: One or more devices has experienced an unrecoverable error. An attempt was made to correct the error. Applications are unaffected. action: Determine if the device needs to be replaced, and clear the errors using 'zpool clear' or replace the device with 'zpool replace'. see: http://zfsonlinux.org/msg/ZFS-8000-9P scan: resilvered 1.29M in 0h0m with 0 errors on Wed Dec 2 08:37:46 2015 config: NAME STATE READ WRITE CKSUM rpool ONLINE 0 0 0 mirror-0 ONLINE 0 0 0 sda2 ONLINE 0 0 3 sdb2 ONLINE 0 0 0 errors: No known data errors Инсценируем замену диска на новый. Я просто взял другую корзину с таким-же диском из старого сервера. Ставим корзину на горячую для большей правдоподобности:
root@pve1:~# fdisk -l /dev/sdb Disk /dev/sdb: 149.1 GiB, 160041885696 bytes, 312581808 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: gpt Disk identifier: 38BE38AC-00D9-4680-88FC-0876378526BC Device Start End Sectors Size Type /dev/sdb1 40 409639 409600 200M EFI System /dev/sdb2 411648 312580095 312168448 148.9G Microsoft basic data Условно неисправный диск у нас /dev/sdb и учитывая одинаковую емкость и геометрию копируем таблицу разделов 1:1 с исправного диска /dev/sda
root@pve1:~# sgdisk -R /dev/sdb /dev/sda The operation has completed successfully. Генерируем уникальные UUID для /dev/sdb
root@pve1:~# sgdisk -G /dev/sdb The operation has completed successfully. Ставим загрузчик на замененный диск и обновляем GRUB:
root@pve1:~# grub-install --recheck /dev/sdb Installing for i386-pc platform. Installation finished. No error reported. root@pve1:~# update-grub Generating grub configuration file ... Found linux image: /boot/vmlinuz-4.2.3-2-pve Found initrd image: /boot/initrd.img-4.2.3-2-pve Found linux image: /boot/vmlinuz-4.2.2-1-pve Found initrd image: /boot/initrd.img-4.2.2-1-pve Found memtest86+ image: /ROOT/pve-1@/boot/memtest86+.bin Found memtest86+ multiboot image: /ROOT/pve-1@/boot/memtest86+_multiboot.bin done root@pve1:~# update-initramfs -u update-initramfs: Generating /boot/initrd.img-4.2.3-2-pve Осталось только заменить сбойный диск в массиве на свежеустановленный, но тут всплывает одна проблема, порожденная методом адресации дисков в массиве примененной в инсталляторе. А именно — диски включены в массив по физическому адресу и команда zpool replace rpool /dev/sdb2 покажет нам вот такую фигу:
root@pve1:~# zpool replace rpool /dev/sdb2 cannot replace /dev/sdb2 with /dev/sdb2: /dev/sdb2 is busy Что совершенно логично, нельзя сменить сбойный диск на /dev/sdb2 так как сбойный диск и есть /dev/sdb2, а зачем нам повторять недоработку инсталлятора? Привяжем диск по UUID, я вообще уже забыл то время когда диски прибивались гвоздями вида /dev/sdХХ — UUID наше все:
root@pve1:~# zpool replace rpool /dev/disk/by-partuuid/cf590df4-72b7-4cfc-a965-001ffe56d0c9 Make sure to wait until resilver is done before rebooting. Нас предупредили о необходимости дождаться окончания синхронизации прежде чем перезагружаться. Проверим статус массива:
root@pve1:~# zpool status rpool pool: rpool state: ONLINE status: One or more devices is currently being resilvered. The pool will continue to function, possibly in a degraded state. action: Wait for the resilver to complete. scan: resilver in progress since Wed Dec 2 18:07:01 2015 92.8M scanned out of 920M at 8.44M/s, 0h1m to go 92.5M resilvered, 10.09% done config: NAME STATE READ WRITE CKSUM rpool ONLINE 0 0 0 mirror-0 ONLINE 0 0 0 sda2 ONLINE 0 0 0 cf590df4-72b7-4cfc-a965-001ffe56d0c9 ONLINE 0 0 0 (resilvering) errors: No known data errors Для общего порядку включим и sda2 в массив используя UUID:
root@pve1:~# zpool detach rpool /dev/sda2 root@pve1:~# zpool attach rpool /dev/disk/by-partuuid/cf590df4-72b7-4cfc-a965-001ffe56d0c9 /dev/disk/by-partuuid/8263d908-e9a8-4ace-b01e-0044fa519037 Make sure to wait until resilver is done before rebooting. Пока я копипастил предыдущие 2 команды из консоли в редактор массив уже синхронизировался:
root@pve1:~# zpool status rpool pool: rpool state: ONLINE scan: resilvered 920M in 0h1m with 0 errors on Wed Dec 2 18:36:37 2015 config: NAME STATE READ WRITE CKSUM rpool ONLINE 0 0 0 mirror-0 ONLINE 0 0 0 cf590df4-72b7-4cfc-a965-001ffe56d0c9 ONLINE 0 0 0 8263d908-e9a8-4ace-b01e-0044fa519037 ONLINE 0 0 0 errors: No known data errors
Вывод
Когда нет аппаратного Raid-контроллера вполне удобно применить размещение корневого раздела на доступном в Proxmox 4.0 «из коробки» zfs RAID1. Конечно-же всегда остается вариант переноса /boot и корня на зеркала созданные средствами mdadm, что тоже неоднократно было использовано мной и до сих пор работает не нескольких серверах, но рассмотренный вариант проще и предлагается разработчиками продукта «из коробки».
ссылка на оригинал статьи http://habrahabr.ru/post/272249/
Добавить комментарий