
Перевод поста Eila Stiegler "The Wolfram Language Worldwide Translations Project".
Код, приведенный в статье, можно скачать здесь, дополнительный код для поста можно скачать здесь.
Выражаю огромную благодарность Кириллу Гузенко KirillGuzenko за помощь в переводе и подготовке публикации
Довольно много времени прошло с тех пор, как я закончила колледж в Германии. И я до сих пор хорошо помню те длинные бессонные ночи, что проводила за выполнением трудных домашних заданий, исследований, и почти полное отсутствие свободного времени. Но так же я хорошо помню и занятия по программированию. Я старалась приступить к ним как можно позже. Но когда программирование уже вошло в список моих обязательных предметов, у меня уже не было возможности его игнорировать. И так как английский — не мой родной язык, мне тяжело давались принципы программирования, которые были для меня чем-то уж очень абстрактным; я постоянно терялась среди названий различных функций, которые приводились на английском. И пускай мне далось всё это весьма тяжело, я с успехом закончила обучение, и вот теперь, годы спустя, я являюсь частью проекта, который мог бы тогда мне сильно помочь — проекта по переводу Wolfram Language на различные языки.
Проект по переводу Wolfram Language представляет любым неанглоговорящим программистам лёгкий вход в изучение Wolfram Language. Проект служит для того, чтобы иметь возможность работать с Wolfram Language вне зависимости от навыков владения английским языком.
Как обычно обучаются программированию? Судя по моему опыту, студентам дают кусок кода и объясняют для чего он нужен. Таким образом, у них появляется возможность познакомиться со структурой и различными функциями. Чтобы облегчить этот процесс, Wolfram Research добавила функционал, который проставляет к коду на языке Wolfram Language аннотации на предпочтительном для вас языке. Мы постоянно развиваем это направление и стараемся добавить максимально возможное количество языков. На данный момент уже имеется поддержка японского, китайского традиционного и упрощенного, корейского, испанского, русского, украинского, польского, немецкого, французского и португальского.
Так же в рамках этого проекта мы добавили перевод меню на традиционный китайский, испанский языки, добавив их к уже реализованным японскому и упрощенному китайскому.
Аннотации к коду
Снова возвращаясь к своему студенчеству: если бы у меня был код демонстрации “Major Multinational Languages”, — пример с сайта Wolfram Demonstrations Project — я смогла бы увидеть этот код, аннотированный на немецком. Аннотации никак не изменяют код и не ограничивают его функциональность. Он по-прежнему вычисляемый и может редактироваться, а аннотации к нему изменяются на лету:

Эксперимента ради, я могла бы вспомнить свои восемь лет занятия русским и попробовать следующее:

Эту функцию можно включить как для одной ячейки/всего ноутбука, так и глобально. Таким образом, я могу сравнить тот же код, аннотированный на немецком, с его русской версией. Аннотацию кода так же можно заметить и в разделе автодополнения. Для данного случая я выбрала французский.
Немного о разных длинах строк
Один из первых вопросов, который возник при старте этого проекта, заключался в разных длинах слов на разных языках. Описательные конструкции и имена функций в CamelCase (ВерблюжьемРегистре) на английском добавляют проблем при попытке сохранить разумную длину для переводов.
Чтобы проиллюстрировать эту проблему, давайте возьмём испанский. Функция String была переведена как "cadena de caracteres". Этот перевод получился значительно длиннее, чем оригинал на английском. А теперь примем во внимание то, что это слово часто встречается в названиях различных функций, как пример StringFreeQ и StringReplacePart; можно представить, какой длины получатся переводы.
Давайте сравним русский и японский переводы символа $FrontEnd. Переводы доступны не только в интерактивном режиме, но и программно через WolframLanguageData с опцией «Translations»:

Длины строк для двух переводов отличаются на 66 символов. Возникает вопрос: как наши переводы соотносятся по длине с их английскими оригиналами? Для начала, давайте загрузим все зарезервированные имена в Wolfram Language, а так же их переводы.

А теперь рассмотрим, как соотносятся переводы с их оригиналами:

Очевидно, что азиатские письменные системы дают значительно более сжатый по длине перевод. С другой стороны, исследуя глубже максимумы и минимумы в разнице между английским и польским, мы увидим следующее (наведите курсор на ListPlot для появления подсказки о сравнении названий на английском и польском):
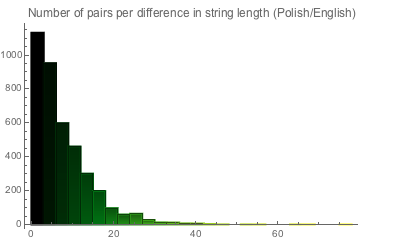

Мы получаем 251 случай соответствий элементов в длину. Вот несколько примеров:

Вот пара с самой большой разницей — аж в 75 символов:

Давайте рассмотрим разницы по длинам на различных языках:
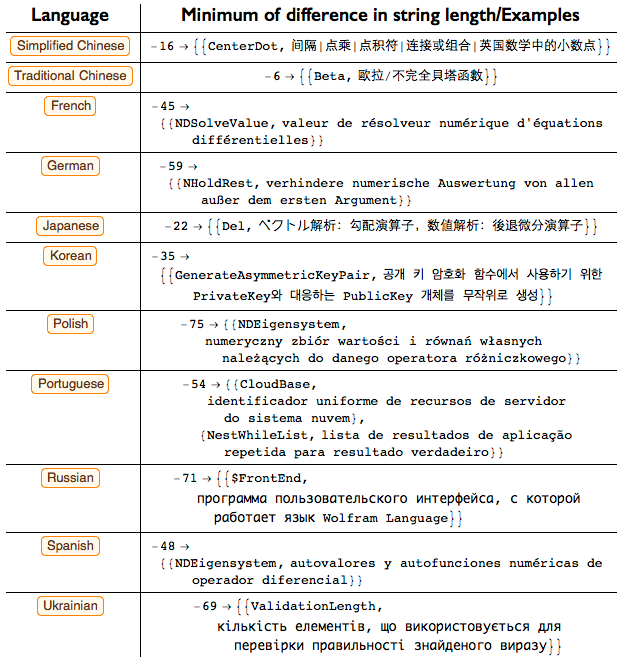

Учитывая эти расхождения, мы можем найти некоторые интересные моменты о языках и их связи в этом наборе данных.
К примеру, каков top 5 имён, наиболее близких по длине к оригиналу для всех языков? Это Here, Byte, ColorQ, ListQ и Ball:


В каком языке больше всего пробелов? В корейском:

И в каком языке строки самые длинные? В немецком:

Проиллюстируем это:

Как мы учтём расхождения в длинах переводов в нашем интерфейсе? Вернёмся к коду из примера “Major Multinational Languages” со включенными аннотациями на немецком. В случаях, когда длина аннотации превышает длину оригинала на английском, мы заменяем заголовок на •••. При наведении курсора на аннотацию она разворачивается и выделяется жирным.

Облака из слов
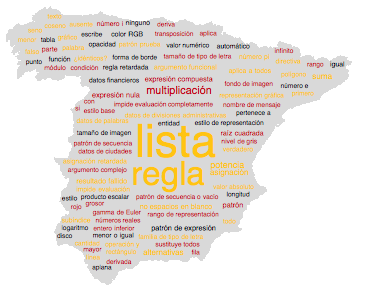
Используя новую функцию Wolfram Language WordCloud, мы можем получить графическое представление переводов, в котором размеру слов соответствует частота их использования. Взяв переводы 120 наиболее популярных имён, а так же задействовав недавно добавленную функцию GeoGraphics, мы можем построить облака из слов по контурам границ этих стран. Вот, к примеру, Германия и Португалия:

Можем пойти дальше и изобразить облака из слов на фигуре, которая описывает границы этой страны. И получается весьма симпатично; вот, к примеру, Испания:
Полные переводы
Поигравшись с переводами и рассмотрев их под разными углами, логично было бы продолжить это и попытаться представить переводы не просто в виде аннотаций, а вместо оригинального кода Wolfram Language на английском. Конечно, имея под рукой функцию TranslateCodeCompletely, осуществить подобное не составляет труда. Передав функции фрагмент кода и требуемый язык в качестве аргумента, наша новая функция возвращает полный перевод. И вот этот код в полном виде:

Вот код, который выдаёт гистограмму с различными длинами имён, приведённую выше — теперь на корейском. Определённые пользователям имена находятся там же, где и были, а системные имена полностью переводятся и выделяются серым. В прилагаемом ниже CDF-файле можно наводить курсор мыши на переведённые функции и наблюдать их исходные названия.
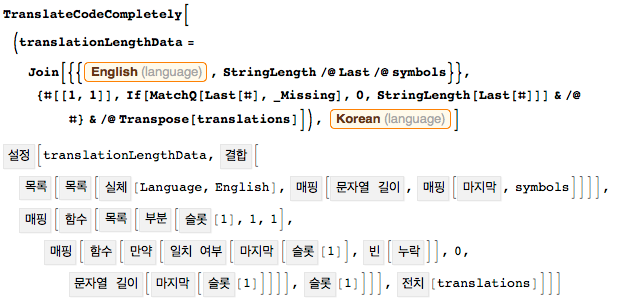
Забавный побочный эффект для тех, кто уже хорошо знаком с Wolfram Language: если вы уже достаточно ориентируетесь в именах функций языка, то с помощью нового функционала можете улучшить свои знания в каком-то новом естественном языке.
Надеюсь, этот функционал поможет большому количеству новых пользователей освоиться в мире Wolfram Language. В дальнейшем мы не собирается останавливаться на одном лишь расширении количества языков. Мы планируем добавить переводы и для других разделов Wolfram Language — меню, горячие клавиши и прочее. Будем рады услышать о желаемых для перевода языках, которые бы вы хотели увидеть в Wolfram Language, а так же будем рады услышать ваши пожелания и отзывы.
ссылка на оригинал статьи http://habrahabr.ru/post/274281/
Добавить комментарий