С поддержкой asyncio и вдохновленный Scrapy.
За чем еще один?
В первую очередь как инструмент для сбора данных, применяемый в моем хобби проекте, который не давил бы своей мощью, сложностью и наследием. И да, кто же будет сознательно начинать что-то новое на python2.x?
В итоге появилось идея сделать простой фреймворк для современной экосистемы python3.x, но такой же элегантный как Scrapy.
Под катом обзорная статья о Pomp в стиле FAQ.
За чем вообще фреймворки для парсинга сайтов нужны?
И действительно, ведь на простой связке requests + lxml можно сделать очень многое. В действительности же фреймворки задают правила и нужные абстракции, и берут много рутины на себя.
Почему Pomp позиционируется как "метафреймворк"?
Pomp из коробки не дает то, что может покрыть широкий спектр требований в решении задач парсинга сайтов: разбор содержимого, прокси, кеширование, обработка редиректов, куки, авторизация, заполнение форм и т.д.
В этом и слабость и одновременно сила Pomp. Данный фреймворк позиционируется как "фреймворк для фреймворков", другими словами дает все что нужно для того что бы сделать свой фреймворк и начать продуктивно "клепать" веб пауков.
Pomp дает разработчику:
- нужные абстракции(интерфейсы) и архитектуру схожую со Scrapy;
- не навязывает выбор методов для работы с сетью и разбора добытого контента;
- может работать как синхронно так и асинхронно;
- конкурентная добыча и разбор контента (concurrent.futures);
- не требует "проекта", настроек и прочих ограничений.
Выигрыш:
- запуск на python2.x, python3.x и pypy (можно даже на google app engine запуститься)
- можно использовать любимые библиотеки для работы c сетью и для разбора контента;
- ввести свою очередь задач;
- разработать cвой кластер пауков;
- более простая прозрачная интеграция с headless браузерами (см пример интеграции с phatnomjs).
Другими словами из Pomp можно сделать Scrapy, если работать с сетью на Twisted и разбирать контент с помощью lxml и т.д.
Когда следует применять Pomp, а когда нет?
В случае когда вам требуется обработать N источников, с общей моделью данных и с периодическим обновлением данных — это и есть идеальный случай применения Pomp.
Если вам необходимо обработать 1-2 источника и забыть, то быстрее и понятнее все сделать на requests+lxml, и вовсе не использовать специальные фреймворки.
Pomp vs Scrapy/Grab/etc?
Попытаться сравнить можно только в разрезе конкретной задачи.
И что лучше сказать сложно, но для меня это вопрос решенный, так как я используя Pomp могу собрать любой сложности систему. С другими же фреймворками зачастую придется бороться с их "рамками" и даже забивать гвозди микроскопом, к примеру использовать Scrapy для работы с headless browsers, оставляя неудел всю мощь Twisted.
Архитектура
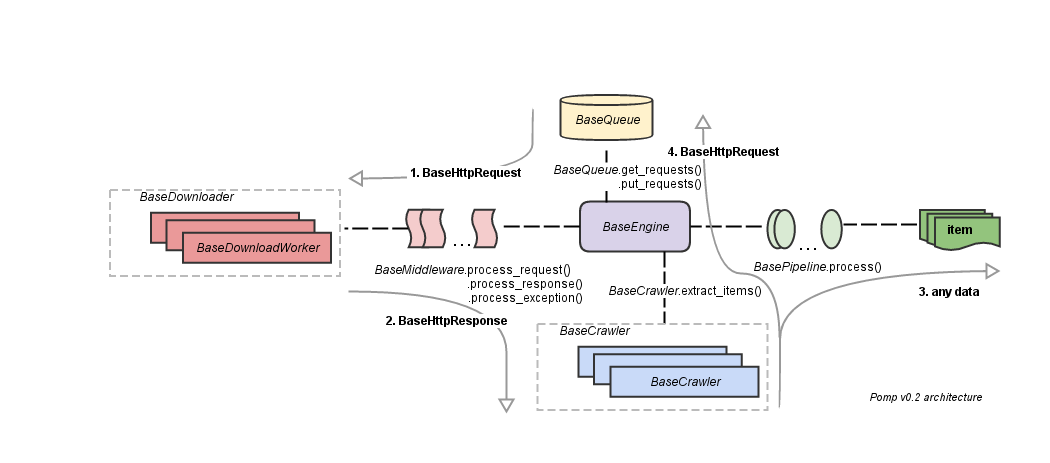
Основные блоки:
— очередь запросов (задач);
— "транспорт" (на диаграмме как BaseDownloader);
— middlewares для пре- и пост-обработки запросов;
— pipelines для последовательной обработки/фильтрации/сохранения добытых данных;
— crawler для разбора контента и генерации следующих запросов;
— engine, который связывает все части.
Простейший пример
Поиск на странице http://python.org/news предложений со словом python простейшим regexp.
import re from pomp.core.base import BaseCrawler from pomp.contrib.item import Item, Field from pomp.contrib.urllibtools import UrllibHttpRequest python_sentence_re = re.compile('[\w\s]{0,}python[\s\w]{0,}', re.I | re.M) class MyItem(Item): sentence = Field() class MyCrawler(BaseCrawler): """Extract all sentences with `python` word""" ENTRY_REQUESTS = UrllibHttpRequest('http://python.org/news') # entry point def extract_items(self, response): for i in python_sentence_re.findall(response.body.decode('utf-8')): item = MyItem(sentence=i.strip()) print(item) yield item if __name__ == '__main__': from pomp.core.engine import Pomp from pomp.contrib.urllibtools import UrllibDownloader pomp = Pomp( downloader=UrllibDownloader(), ) pomp.pump(MyCrawler())
Пример создания "кластера" для разбора craigslist.org
В примере используется:
— Redis для организации централизованной очереди задач;
— Apache Kafka для агрегации добытых данных;
— Django на postgres для хранения и отображения данных;
— grafana c kamon dashboards для отображения метрик работы кластера kamon-io/docker-grafana-graphite
— docker-compose что бы запустить весь этот зоопарк на одной машине.
Исходный код и инструкции по запуску смотрите здесь — estin/pomp-craigslist-example.
А так же видео без звука, где большая часть времени ушла на развертывание окружения. На видео можно найти некоторые ошибки в сборе метрик о размере очереди задач.
Примечание: в примере умышлено не исправлены ошибки в разборе некоторых страниц, для того что бы в процессе работы райсились исключения.
Дальнейшие планы
Pomp по большей части уже сформировался и достиг поставленных целей.
Дальнейшее развитие скорее всего будут заключаться в более плотной интеграции с asyncio.
Ссылки
— проект на bitbucket https://bitbucket.org/estin/pomp
— зеркало проекта на github https://github.com/estin/pomp
— документация http://pomp.readthedocs.org/en/latest/
ссылка на оригинал статьи https://habrahabr.ru/post/278445/
Добавить комментарий