В нашем проекте PT Application Inspector реализовано несколько подходов к анализу исходного кода на различных языках программирования:
- поиск по сигнатурам;
- исследование свойств математических моделей, полученных в результате статической абстрактной интерпретации кода;
- динамический анализ развернутого приложения и верификация на нем результатов статического анализа.
Наш цикл статей посвящен структуре и принципам работы модуля сигнатурного поиска (PM, pattern matching). Преимущества такого анализатора — скорость работы, простота описания шаблонов и масштабируемость на другие языки. Среди недостатков можно выделить то, что модуль не в состоянии анализировать сложные уязвимости, требующие построения высокоуровневых моделей выполнения кода.
К разрабатываемому модулю были, в числе прочих, сформулированы следующие требования:
- поддержка нескольких языков программирования и простое добавление новых;
- поддержка анализа кода, содержащего синтаксические и семантические ошибки;
- возможность описания шаблонов на универсальном языке (DSL, domain specific language).
В нашем случае все шаблоны описывают какие-либо уязвимости или недостатки в исходном коде.
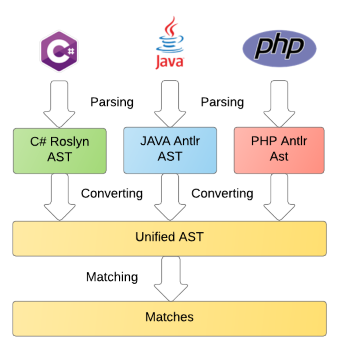
Весь процесс анализа кода может быть разбит на следующие этапы:
- парсинг в зависимое от языка представление (abstract syntax tree, AST);
- преобразование AST в независимый от языка унифицированный формат;
- непосредственное сопоставление с шаблонами, описанными на DSL.
Данная статья посвящена первому этапу, а именно: парсингу, сравнению функциональных возможностей и особенностей различных парсеров, применению теории на практике на примере грамматик Java, PHP, PLSQL, TSQL и даже C#. Остальные этапы будут рассмотрены в следующих публикациях.
Содержание
Теория парсинга
В начале может возникнуть вопрос: а зачем строить унифицированное AST, разрабатывать алгоритмы сопоставления графов вместо использования обычных регулярных выражений? Дело в том, что не все паттерны можно просто и удобно описать с помощью регулярных выражений. Стоит заметить, что, например, в C# регулярные выражения обладают мощностью контекстно-свободных грамматик благодаря именованным группам и обратным ссылкам (однако процесс написания паттернов с помощью таких выражений будет сопровождаться другими нецензурными выражениями сложным). По этому поводу также есть статья от разработчиков PVS-Studio. Кроме того, связанность получившегося унифицированного AST позволит в будущем использовать его для построения более сложных представлений выполнения кода, таких как граф свойств кода.
Терминология
Те, кто знаком с теорией парсинга, могут пропустить этот раздел.
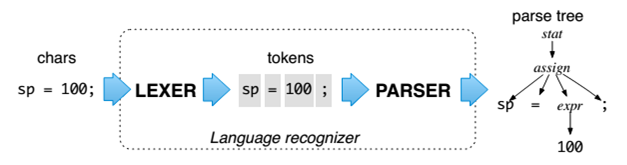
Парсинг — процесс преобразования исходного кода в структурированный вид. Типичный парсер представляет собой комбинацию лексера и парсера. Лексер группирует символы исходного кода в значащие последовательности, которые называются лексемами. После этого определяется тип лексемы (идентификатор, число, строка и т.п.). Токеном называется совокупность значения лексемы и ее типа. В примере на рисунке ниже токенами являются sp, =, 100. Парсер же из потока токенов строит связную древовидную структуру, которая называется деревом разбора. В данном случае assign является одним из узлов дерева. Абстрактное синтаксическое дерево или AST — дерево разбора на более высоком уровне, из которого удалены не значимые токены, такие как скобки, запятые. Однако существуют парсеры, в которых шаг лексирования и разбора совмещены.
Для описания различных узлов AST используются правила. Объединение всех правил называют грамматикой языка. Существуют инструменты, генерирующие код под определенную платформу (рантайм) для разбора языков на основе грамматик. Они называются генераторами парсеров. Например, ANTLR, Bison, Coco/R. Однако часто парсер по определенным причинам пишется вручную, например Roslyn. Преимуществами ручного подхода является то, что парсеры, как правило, получаются более производительными и читабельными.
Так как изначально проект было решено разрабатывать на .NET технологиях, то для анализа C# кода было решено использовать Roslyn, а для остальных языков — ANTLR, поскольку последний поддерживает .NET рантайм, а другие альтернативы имеют меньше возможностей.
Виды формальных языков
Согласно иерархии Хомского, существуют 4 вида формальных языков:
- регулярные, пример: an
- контекстно-свободные (КС, пример: anbn)
- контекстно-зависимые (КЗ, пример: anbncn)
- тьюринг-полные.
Регулярные выражения позволяют описывать только простейшие конструкции для сопоставления, которые, однако, покрывают большинство задач в повседневной практике. Еще одним достоинством регулярных выражений является то, что их поддержка включена в большинство современных языков программирования. Тьюринг-полные языки не имеют практического применения в силу их сложности как при написании, так и при разборе (из эзотерических можно вспомнить Thue).
В настоящее время практически весь синтаксис современных языков программирования можно описать с помощью КС-грамматик. Если сравнивать КС-языки и регулярные выражения «на пальцах», то последние не имеют памяти (не умеют считать). А если сравнивать КЗ- и КС-языки, то последние не запоминают посещенные ранее правила (умеют считать две вещи, но не множество).
Кроме того, язык в одном случае может являться КС, а в другом — КЗ. Если учитывать семантику, т.е. согласованность с определениями языка, в частности, согласованность типов, то язык может рассматриваться как КЗ. Например, T a = new T(). Здесь тип в конструкторе справа должен быть таким же, какой указан слева. Обычно целесообразно проверять семантику после этапа парсинга. Однако существуют синтаксическое конструкции, которые никак не распарсить с помощью КС-грамматик, например Heredoc в PHP: $x = <<<EOL Hello world EOL; В ней лексема EOL является маркером начала и окончания разрывной строки, поэтому требуется запоминание значения посещенного токена. В данной статье акцентируется внимание на разборе таких КС- и КЗ- языков.
ANTLR

Данный генератор парсеров является LL(*), он существует уже более 20 лет, а в 2013 год вышла его 4-я версия. Сейчас его разработка ведется на GitHub. В данный момент он позволяет генерировать парсеры на языках Java, C#, Python2, Python3, JavaScript. На подходе C++, Swift. Надо сказать, сейчас в этом инструменте достаточно просто разрабатывать и отлаживать грамматики. Несмотря на то, что LL грамматики не допускают леворекурсивных правил, в ANTLR, начиная с 4-й версии, появилась возможность записи таких правил (за исключением правил со скрытой или косвенной левой рекурсией). При генерации парсера происходит преобразование таких правил в обычные не леворекурсивные. Это сокращает запись, например, арифметических выражений:
expr : expr '*' expr | expr '+' expr | <assoc=right> expr '^' expr | id ;Кроме того, в 4-й версии значительна улучшена производительность парсинга благодаря использованию алгоритма Adaptive LL(*). Данный алгоритм совмещает преимущества относительно медленных и непредсказуемых алгоритмов GLL и GLR, которые, однако, способны разрешать случаи с неоднозначностью (используются при разборе естественных языков), и стандартных, быстрых LL-алгоритмов рекурсивного спуска, которые, в свою очередь, не способны разрешать все задачи с неоднозначностью. Суть алгоритма заключается в псевдопараллельном запуске LL-парсеров на каждом правиле, их кэшировании и выборе подходящего предсказания (в отличие от GLR, где допустимо несколько альтернатив). Таким образом, алгоритм является динамическим. Несмотря на то, что наихудшая теоретическая сложность алгоритма является O(n4), по факту скорость парсинга для существующих языков программирования является линейной. Также в четвертой версии сильно эволюционировала возможность восстановления процесса парсинга после обнаружения синтаксических ошибок. Подробнее об алгоритмах ANTLR 4 и их отличиях от других алгоритмов парсинга написано в Adaptive LL(*) Parsing: The Power of Dynamic Analysis.
Roslyn

Roslyn является не просто парсером, а полноценным инструментом для парсинга, анализа и компиляции C# кода. Его разработка также ведется на GitHub, однако он существенно моложе, чем ANTLR. В этой статье рассматриваются только его возможности парсинга без учета семантики. Roslyn парсит код в достоверное (fidelity), неизменяемое (immutable) и потокобезопасное (threadsafe) дерево. Достоверность заключается в том, что такое дерево может быть преобразовано обратно в код символ в символ, включая пробелы, комментарии и директивы препроцессора, даже если в нем будут синтаксические ошибки. Неизменяемость позволяет легко обрабатывать дерево несколькими потоками, поскольку в каждом потоке создается «умная» копия дерева, в которой хранятся только изменения. Это дерево может содержать в себе следующие объекты:
- Syntax Node — нетерминальный узел дерева, содержащий в себе несколько других узлов и отображающий определенную конструкцию. Также может содержать опциональный узел (например, ElseClauseSyntax для if);
- Syntax Token — терминальный узел, отображающий ключевое слово, идентификатор, литерал или пунктуацию;
- Syntax Trivia — терминальный узел, отображащий пробел, комментарий или директиву препроцессора (может быть безболезненно удален без потери информации о коде). Trivia не может иметь родителя. Данные узлы оказываются незаменимыми при трансформации дерева обратно в код (например, для рефакторинга).
Проблематика парсинга
При разработке грамматик и парсеров существуют некоторые проблемы, решение которых нужно продумать.
Ключевые слова как идентификаторы
Часто бывает, что при разборе ключевые слова также могут являться и идентификаторами. Например, в C# ключевое слово async, помещенное перед сигнатурой метода async Method(), означает, что данный метод является асинхронным. Но если данное слово будет использоваться в качестве идентификатора переменной var await = 42;, то код также будет валидным. В ANTLR данная проблема решается двумя способами:
- использованием семантического предиката для синтаксического правила:
async: {_input.LT(1).GetText() == "async"}? ID ;; при этом сам токен async не будет существовать. Данный подход плох тем, что грамматика становится зависимой от рантайма и некрасиво выглядит; - включением токена в само правило id:
ASYNC: 'async'; ... id : ID ... | ASYNC;
Неоднозначность
В естественном языке существуют неоднозначно трактуемые фразы (типа «казнить нельзя помиловать»). В формальных языках подобные конструкции также могут встречаться. Например, следующий фрагмент:
stat: expr ';' // expression statement | ID '(' ')' ';' // function call statement; ; expr: ID '(' ')' | INT ; Однако, в отличие от естественных языков, они скорее всего являются следствием неправильно разработанных грамматик. ANTLR не в состоянии обнаруживать такие неоднозначности в процессе генерации парсера, но может обнаруживать их непосредственно в процессе парсинга, если устанавливать опцию LL_EXACT_AMBIG_DETECTION (потому что, как уже говорилось, ALL — динамический алгоритм). Неоднозначность может возникать как в лексере, так и в парсере. В лексере для двух одинаковых лексем, формируется токен, объявленный выше в файле (пример с идентификаторами). Однако в языках, где неоднозначность действительно допустима (например, C++), можно использовать семантические предикаты (вставки кода) для ее разрешения, например:
expr: { isfunc(ID) }? ID '(' expr ')' // func call with 1 arg | { istype(ID) }? ID '(' expr ')' // ctor-style type cast of expr | INT | void ; Также иногда неоднозначность можно исправить с помощью небольшого переделывания грамматики. Например, в C# существует оператор побитового сдвига вправо RIGHT_SHIFT: '>>'; две угловые скобки могут также использоваться для описания классов-генериков: List<List<int>>. Если определить токен >>, то конструкция из двух списков никогда не сможет распарситься, потому что парсер будет считать, что вместо двух закрывающихся скобок написан оператор >>. Чтобы решить такую проблему, достаточно просто отказаться от токена RIGHT_SHIFT. При этом токен LEFT_SHIFT: '<<' можно оставить, поскольку такая последовательность символов при парсинге угловых скобок не может встретиться в валидном коде.
В нашем модуле мы пока что детально не тестировали, есть ли в разработанных грамматиках неоднозначность.
Обработка пробелов, комментариев.
Еще одной проблемой при парсинге является обработка комментариев. Неудобство здесь в том, что если включать комментарии в грамматику, то она получится переусложненной, поскольку по сути каждый узел будет содержать в себе комментарии. Однако просто выкинуть комментарии тоже нельзя, потому что в них может содержаться важная информация. Для обработки комментариев в ANTLR используются так называемые каналы, которые изолируют множество комментариев от остальных токенов: Comment: ~[\r\n?]+ -> channel(PhpComments);
В Roslyn комментарии включены в узлы дерева, но имеют специальный тип Syntax Trivia. И в ANTLR, и в Roslyn можно получить список тривиальных токенов, ассоциированных с определенным обычным токеном. В ANTLR для токена с индексом i в потоке существует метод, который возвращает все токены из определенного канала слева или справа: getHiddenTokensToRight(int tokenIndex, int channel), getHiddenTokensToRight(int tokenIndex, int channel). В Roslyn же такие токены сразу же включаются в терминальные Syntax Token.
Для того, чтобы получить все комментарии, в ANTLR можно взять все токены определенного канала: lexer.GetAllTokens().Where(t => t.Channel == PhpComments), а в Roslyn можно взять все DescendantTrivia для корневого узла со следующими SyntaxKind: SingleLineCommentTrivia, MultiLineCommentTrivia, SingleLineDocumentationCommentTrivia, MultiLineDocumentationCommentTrivia, DocumentationCommentExteriorTrivia, XmlComment.
Обработка пробелов и комментариев является одной из причин, почему для анализа нельзя использовать код, например, LLVM: в нем они будут просто выкинуты. Кроме комментариев, важна даже обработка пробелов. Например, для детектирования ошибок с одним утверждением в if (пример взят из статьи PVS-Studio покопался в ядре FreeBSD):
case MOD_UNLOAD: if (via_feature_rng & VIA_HAS_RNG) random_nehemiah_deinit(); random_source_deregister(&random_nehemiah);Обработка ошибок парсинга.

Важной способностью каждого парсера является обработка ошибок — по следующим причинам:
- процесс парсинга не должен прерывать только лишь из-за одной ошибки, а должен корректно восстанавливаться и парсить код дальше (например, после пропущенной точки с запятой);
- поиск релевантной ошибки и ее расположения, вместо множества нерелевантных.
Ошибки в ANTLR
В ANTLR существуют следующие типы ошибок парсинга:
- ошибка распознавания токена (Lexer no viable alt); единственная существующая лексическая ошибка, обозначающая отсутствие правила для формирования токена из существующей лексемы:
class # { int i; } — здесь такой лексемой является #.
- отсутствующий токен (Missing token); в этом случае ANTLR вставляет в поток токенов отсутствующий токен, помечает, что его не хватает, и продолжает парсинг, как будто он существует.
class T { int f(x) { a = 3 4 5; } } — здесь такой токен это
}в конце; - лишний токен (Extraneous token); ANTLR помечает, что токен ошибочный и продолжает парсинг дальше, как будто он отсутствует: в примере такой токен первая ;
class T ; { int i; }
- несовместимая входная цепочка (Mismatched input); при этом включается «режим паники», цепочка входных токенов игнорируется, а парсер ожидает токена из синхронизирущего множества. В следующем примере игнорируются лексемы 4 и 5, а синхронизирующим токеном является ;
class T { int f(x) { a = 3 4 5; } }
- отсутствующая альтернатива (No viable alternative input); данная ошибка описывает все остальные возможные ошибки парсинга.
class T { int ; }
Кроме того, ошибки можно обрабатывать вручную с помощью добавления альтернатив в правило, например так:
function_call : ID '(' expr ')' | ID '(' expr ')' ')' {notifyErrorListeners("Too many parentheses");} | ID '(' expr {notifyErrorListeners("Missing closing ')'");} ;Более того, в ANTLR 4 можно использовать свой механизм обработки ошибок. Это нужно, к примеру, для увеличения производительности парсера: сначала код парсится с помощью быстрого SLL-алгоритма, который, однако, может неправильно парсить код с неоднозначностью. Если же с помощью этого алгоритма выяснилось, что существует хотя бы одна ошибка (эта может быть как ошибка в коде, так и неоднозначность), код парсится уже с помощью полного, но менее быстрого ALL-алгоритма. Конечно, код с настоящими ошибками (например, пропущенная; ), будет всегда парситься с помощью LL, однако таких файлов обычно меньше, чем файлов без ошибок.
// try with simpler/faster SLL(*) parser.getInterpreter().setPredictionMode(PredictionMode.SLL); // we don't want error messages or recovery during first try parser.removeErrorListeners(); parser.setErrorHandler(new BailErrorStrategy()); try { parser.startRule(); // if we get here, there was no syntax error and SLL(*) was enough; // there is no need to try full LL(*) } catch (ParseCancellationException ex) { // thrown by BailErrorStrategy tokens.reset(); // rewind input stream parser.reset(); // back to standard listeners/handlers parser.addErrorListener(ConsoleErrorListener.INSTANCE); parser.setErrorHandler(new DefaultErrorStrategy()); // full now with full LL(*) parser.getInterpreter().setPredictionMode(PredictionMode.LL); parser.startRule(); }
Ошибки в Roslyn
В Roslyn существуют следующие ошибки парсинга:
- недостающий синтаксис; Roslyn достраивает соответствующий узел со значением свойства
IsMissing = true(типичным пример — Statement без точки с запятой); - незавершенный член; создается отдельный узел
IncompleteMember; - некорректное значение численного, строкового или символьного литерала (например, слишком большое значение, пустой char): отдельный узел с Kind, равным
NumericLiteralToken,StringLiteralTokenилиCharacterLiteralToken; - лишний синтаксис (например, случайно напечатанный символ): создается отдельный узел с Kind =
SkippedTokensTrivia.
Следующий фрагмент кода демонстрирует все эти ошибки
(Roslyn также удобно щупать с помощью плагина для Visual Studio Syntax Visualizer):
namespace App { class Program { ; // Skipped Trivia static void Main(string[] args) { a // Missing ';' ulong ul = 1lu; // Incorrect Numeric string s = """; // Incorrect String char c = ''; // Incorrect Char } } class bControl flow { c // Incomplete Member } }
Благодаря таким продуманным типам синтаксических ошибок Roslyn может преобразовать дерево с любым количеством ошибок обратно в код символ в символ.
От теории к практике

Для парсеров PHP, T-SQL были разработаны и выложены в опенсорс грамматики php, tsql, plsql, которые являются наглядными применениями вышеизложенной теории. Для парсинга Java использовались и сравнивались уже готовые грамматики java и java8. Также для сравнения парсеров на основе Roslyn и ANTLR мы доработали грамматику C# для поддержки версий 5 и 6 языка. Интересные моменты разработки и использования этих грамматик мы описали ниже. Хотя языки на базе SQL являются больше декларативными, нежели императивными, в их диалектах T-SQL, PL/SQL есть поддержка императивных конструкций (Control flow), для которых по большей части и разрабатывается наш анализатор.
Java- и Java8-грамматики
Для большинства случаев парсер на основе грамматики Java 7 быстрее парсит код, по сравнению с Java 8, за исключением случаев с глубокой рекурсией, например в файле ManyStringConcatenation.java, когда парсинг занимает на порядок больше времени и памяти. Хочу заметить, что это не просто синтетический пример — нам реально попадались файлы с подобным «кодом-спагетти». Как оказалось, вся проблема как раз из-за леворекурсивных правил в expression. В Java 8 леворекурсивные правила развернуты вручную. Это один из немногих случаев, когда не рекомендуется использовать левую рекурсию. Почему так происходит и можно ли это исправить? Это хорошая задача, которую еще только предстоит решить.
PHP-грамматика
Для парсинга PHP на платформе .NET существует проект Phalanger. Однако нас не устроило то, что этот проект практически не развивается, а также не предоставляет интерфейса Visitor для обхода узлов AST (только Walker). Таким образом, было решено разрабатывать грамматику PHP под ANTLR собственными силами.
Регистро-независимые ключевые слова.
Как известно, в PHP все лексемы, за исключением названий переменных (которые начинаются с ‘$’) являются нечувствительными к регистру. В ANTLR нечувствительность к регистру можно реализовать двумя способами:
- Объявление фрагментных лексических правил для всех латинских букв и их использование следующим способом:
Abstract: A B S T R A C T; Array: A R R A Y; As: A S; BinaryCast: B I N A R Y; BoolType: B O O L E A N | B O O L; BooleanConstant: T R U E | F A L S E; ... fragment A: [aA]; fragment B: [bB]; ... fragment Z: [zZ];Фрагментом в ANTLR является часть лексемы, которую можно использовать в других лексемах,
однако сама по себе она лексемой не является. Это по сути синтаксический сахар для описания лексем. Без использования фрагментов, например, первый токен можно записать так:Abstract: [Aa] [Bb] [Ss] [Tt] [Rr] [Aa] [Cc] [Tt]. Плюс данного подхода в том, что сгенерированный лексер является независимым от рантайма, поскольку символы в верхнем и нижнем регистрах объявляются сразу в грамматике. Из минусов можно отметить то, что производительность лексера при таком подходе ниже, чем во втором способе. - Приведение всего входного потока символов к нижнему (или верхнему) регистру и запуск лексера, в котором все токены описаны в этом регистре. Однако такое преобразование придется делать для каждого рантайма (Java, C#, JavaScript, Python) отдельно, как это описано в Implement a custom File or String Stream and Override LA. Более того, при данном подходе трудно сделать так, чтобы одни лексемы были чувствительны к регистру, а другие нет.
В разработанной грамматике PHP использовался первый подход, поскольку лексический анализ обычно проводится за меньшее время, чем синтаксический. И несмотря на то, что грамматика получилось все равно зависимой от рантайма, данный подход потенциально упрощает задачу портирования грамматики на другие рантаймы. Более того, нами был создан Pull Request RFC Case Insensitivity Proof of Concept — для облегчения описания нечувствительный к регистру лексем. Если повезет, то когда-нибудь такая возможность появится в ANTLR 🙂
Лексические режимы для PHP, HTML, CSS, JavaScript.
Как известно, вставки PHP-кода могут находится внутри HTML кода практически в любом месте. В этом же HTML могут находится вставки CSS- и JavaScript- кода (эти вставки еще называют «островками»). Например, следующий код (с использованием Alternative Syntax) является валидным:
<?php switch($a): case 1: // without semicolon?> <br> <?php break ?> <?php case 2: ?> <br> <?php break;?> <?php case 3: ?> <br> <?php break;?> <?php endswitch; ?>или
<script type="text/javascript"> document.addEvent('domready', function() { var timers = { timer: <?=$timer?> }; var timer = TimeTic.periodical(1000, timers); functionOne(<?php echo implode(', ', $arrayWithVars); ?>); }); </script>К счастью, в ANTLR есть механизм так называемых режимов (mode), которые позволяют переключаться между различными наборами токенов при определенном условии. Например, режимы SCRIPT и STYLE предназначены для генерации потока токенов для JavaScript и CSS соответственно (однако в этой грамматике они фактически просто игнорируются). В режиме по умолчанию DEFAULT_MODE генерируются HTML-токены. Стоит отметить, что реализовать поддержку Alternative Syntax в ANTLR можно без единой вставки целевого кода в лексер. А именно так: nonEmptyStatement включает в себе правило inlineHtml, которое, в свою очередь, включает в себя токены, полученные в режиме DEFAULT_MODE:
nonEmptyStatement : identifier ':' | blockStatement | ifStatement | ... | inlineHtml ; ... inlineHtml : HtmlComment* ((HtmlDtd | htmlElement) HtmlComment*)+ ;Сложные контекстно-зависимые конструкции.
Стоит отметить, что хотя ANTLR поддерживает только КС-грамматики, в нем существует так называемые экшены, т. е. вставки произвольного кода, которые расширяют допустимое множество языков как минимум до контекстно-зависимых. С помощью таких вставок была реализована обработка конструкций, типа Heredoc и других:
<?php foo(<<< HEREDOC Heredoc line 1. Heredoc line 2. HEREDOC ) ; ?>Грамматика T-SQL
Несмотря на общий корень «SQL», грамматики T-SQL (MSSQL) и PL/SQL достаточно сильно отличаются друг от друга.
Мы были бы рады не разрабатывать собственный парсер для этого непростого языка. Однако существующие парсеры не удовлетворяли критериям полноты охвата, актуальности (грамматика под заброшенный GOLD-parser) и открытым исходникам на C# (General SQL Parser). Было принято решение восстанавливать грамматику TSQL из документации MSDN. Результат получился достойным: грамматика уже охватывает много распространенных синтаксических конструкций, опрятно выглядит, независима от рантайма и покрыта тестами (примеры SQL-запросов из той же MSDN). Неприятным моментом разработки было то, что некоторые токены в грамматике являются опциональными. Например, точка с запятой. Побочным эффектом является то, что восстановление после ошибок при парсинге из-за этого проходит не очень гладко.
Грамматика PL/SQL
Доработка грамматики PL/SQL заняла еще меньше времени, поскольку сама грамматика уже существовала под ANTLR3. Основной сложностью являлось то, что она была разработана под java-runtime. Большая часть java вставок была удалена, так как построить AST можно и без них (как уже говорилось ранее, семантику можно проверять на другом этапе). А такие вставки, как
decimal_key : {input.LT(1).getText().equalsIgnoreCase("decimal")}? REGULAR_ID были заменены на фрагментные лексемы:
decimal_key: D E C I M A L, о которых также говорилось ранее.
C#-грамматика
Как это ни странно, но доработка грамматики, поддерживающей версии 5 и 6 языка, оказалась достаточно непростым занятием. Главной сложностью была поддержка интерполяции строк и корректная обработка препроцессорных директив. В силу того что эти вещи являются сильно контекстно-зависимыми, лексер и парсер для обработки директив получились зависимыми от runtime.
Директивы препроцессора
В C# возможна корректная компиляция следующего кода (код после первой директивы не компилирующийся, но и не учитывающийся в компиляции, т. к. false никогда не выполняется):
#if DEBUG || false Sample not compilied wrong code var 42 = a + ; #else // Compilied code var x = a + b; #endif Для корректной обработки таких случаев код сначала разбивается на массив токенов, находящихся в каналах по-умолчанию, COMMENTS_CHANNEL и DIRECTIVE. Также создается список codeTokens, куда попадают правильные токены для синтаксического разбора. После этого препроцессорный парсер вычисляет значение директивы для препроцессных токенов. Стоит обратить внимание на то, что ANTLR также позволяет писать код для вычисления значения сложного логического выражения прямо в грамматике. Как это реализовано — можно посмотреть в CSharpPreprocessorParser.g4. Значение true или false вычисляется только для директив #if, #elif, else, для всех же остальных директив всегда возвращается true, поскольку они не влияют на то, будет ли последующий код компилироваться. Также в этом парсере можно определить дефолтные Conditional Symbols (по умолчанию определен "DEBUG").
После того как значение директивы вычислено и принимает значение true, последующие токены добавляются в список codeTokens, в противном случае — нет. Такой подход позволяет игнорировать неправильные токены (как var 42 = a + ; в этом примере) уже на этапе парсинга. Весь этап парсинга также расписан здесь: CSharpAntlrParser.cs.
Интерполяция строк
Данную фичу было очень непросто разрабатывать, потому что, например, закрывающаяся фигурная скобка может означать как часть интерполируемого выражения (interpolation-expression), так и выход из самого режима выражения. А двоеточие может также быть частью выражения, а может означать конец выражения и описание формата вывода (например, #0.##). Кроме того, такие строки могут быть как обычными (regular), так и без экранирующих символов (verbatium), а также могут быть вложенными друг в друга. Подробнее синтаксис описан в MSDN.
Описанные выше вещи продемонстрированы в следующем коде, валидном с точки зрения синтаксиса:
s = $"{p.Name} is \"{p.Age} year{(p.Age == 1 ? "" : "s")} old"; s = $"{(p.Age == 2 ? $"{new Person { } }" : "")}"; s = $@"\{p.Name} ""\"; s = $"Color [ R={func(b: 3):#0.##}, G={G:#0.##}, B={B:#0.##}, A={A:#0.##} ]";Интерполяция строк была реализован с использованием стека для подсчета уровня текущей интерполируемой строки, а также фигурных скобок. Все это реализовано в CSharpLexer.g4.
Тестирование
Корректность парсеров ANTLR
Парсер Roslyn, очевидно, не нуждается в тестировании корректности парсинга. А тестированию парсеров ANTLR мы уделили большое внимание:
- Тестирование файлов, содержащих все богаство синтаксических конструкций. Например, тестовые файлы для TSQL находятся в официальном репозитории antlr grammars-v4. Для C# парсера использовался и дорабатывался файл AllInOne.cs, заимствованный из Roslyn.
- Тестирование специально подготовленных файлов без синтаксических ошибок и с ними.
- Тестирование на реальных проектах последних версий. PHP тестировался на WebGoat, phpbb, Zend Framework. C# парсер тестировался на Roslyn-1.1.1, Corefx-1.0.0-rc2, ImageProcessor-2.3.0, Newtonsoft.Json-8.0.2 и других.
Производительность парсеров ANTLR и Roslyn
Тестирование проводилось в однопоточном режиме и Release конфиге без отладчика. Тестировались версии ANTLR 4 4.5.0-alpha003 и Roslyn (Microsoft.CodeAnalysis) 1.1.1.
WebGoat.PHP
Обработанных файлов — 885. Общее количество строк — 137 248, символов — 4 461 768.
Приблизительное время работы — 00:00:31 сек (лексер 55%, парсер 45%).
PL/SQL Samples
Обработанных файлов — 175. Общее количество строк — 1 909, символов — 55 741.
Приблизительное время работы < 1 сек. (лексер 5%, парсер 95%).
CoreFX-1.0.0-rc2
Обработанных файлов — 7329. Общее количество строк — 2 286 274, символов — 91 132 116.
Приблизительное время работы:
- Roslyn: 00:00:04 сек.,
- ANTLR: 00:00:24 сек. (лексер 12%; парсер 88%).
Roslyn-1.1.1
Обработанных файлов — 6527. Общее количество строк — 1 967 672, символов — 74 319 082.
Приблизительное время работы:
- Roslyn: 00:00:03 сек.,
- ANTLR: 00:00:16 сек. (лексер 12%; парсер 88%).
Из результатов тестирования проектов CoreFX и Roslyn можно сделать вывод, что разработанный парсер C# на ANTLR примерно в 5—7 раз медленнее парсера Roslyn, что говорит о хорошем качестве последнего. Понятно, что написанный «на коленке» за неделю парсер вряд ли сможет конкурировать с такими гигантами, как Roslyn, однако его все же можно использовать для парсинга C#-кода на Java, Python или JavaScript (и других будущих языках), поскольку скорость парсинга все равно быстрая.
На основании всех остальных тестов можно сделать вывод, что лексирование является в основном более быстрой операцией, чем непосредственно разбор. Исключением является лексер PHP, где лексирование заняло даже больше времени, чем разбор. Вероятно это связано со сложной логикой лексера и сложными правилами, но не с регистронезависимыми ключевыми словами, поскольку лексеры T-SQL и PL/SQL (в которых тоже регистронезависимые ключевые слова) работают гораздо быстрее парсеров (раз в 20). Например, если в грамматике C# использовать лексическое правило SHARP: NEW_LINE Whitespace* '#'; вместо SHARP: '#';, то лексер будет не в 7 раз быстрее, а в 10 раз медленнее ! Это объясняется тем, что в любом файле очень много пробелов, а лексер на каждой строчке будет пытаться найти символ #, что значительно замедлит его производительность (мы сталкивались с такой проблемой, поэтому нахождение директивы на новой строчке нужно проверять в рантайме).
Механизмы обработки ошибок в ANTLR и Roslyn
Был написан простой C#-файл, содержащий все возможные типы ошибок ANTLR:
namespace App { © class Program { static void Main(string[] args) { a = 3 4 5; } } class B { c }Ошибки ANTLR
- token recognition error at: ‘©’ at 3:5
- mismatched input ‘4’ expecting {‘as’, ‘is’, ‘[‘, ‘(‘, ‘.’, ‘;’, ‘+’, ‘-‘, ‘*’, ‘/’, ‘%’, ‘&’, ‘|’, ‘^’, ‘<‘, ‘>’, ‘?’, ‘??’, ‘++’, ‘—‘, ‘&&’, ‘||’, ‘->’, ‘==’, ‘!=’, ‘<=’, ‘>=’, ‘<<‘} at 8:19
- extraneous input ‘5’ expecting {‘as’, ‘is’, ‘[‘, ‘(‘, ‘.’, ‘;’, ‘+’, ‘-‘, ‘*’, ‘/’, ‘%’, ‘&’, ‘|’, ‘^’, ‘<‘, ‘>’, ‘?’, ‘??’, ‘++’, ‘—‘, ‘&&’, ‘||’, ‘->’, ‘==’, ‘!=’, ‘<=’, ‘>=’, ‘<<‘} at 8:21
- no viable alternative at input ‘c}’ at 15:5
- missing ‘}’ at ‘EOF’ at 15:6
Ошибки Roslyn
- test(3,5): error CS1056: Unexpected character ‘©’
- test(8,19): error CS1002:; expected
- test(8,21): error CS1002:; expected
- test(15,5): error CS1519: Invalid token ‘}’ in class, struct, or interface member declaration
- test(15,6): error CS1513: } expected
Как видно, Roslyn обнаружил столько же ошибок, сколько и ANTLR. А первая и последние ошибки вообще различаются только названием. Также парсеры были протестированы и на более сложных файлах. Понятное дело, что Roslyn детектирует меньшее количество ошибок, и они более релевантны. Однако для простых случаев, таких как пропущенные и лишние токены (точка с запятой, скобки), ANTLR также отображает релевантную позицию и описание ошибки. Хуже ANTLR справляется с ошибками, в которых часть кода лексера написана вручную (директивы компиляции, интерполируемые строки). Например, сейчас если написать директиву #if без условия, то дальнейшая часть кода вообще не распарсится. Однако в этих случае код для восстановления процесса парсинга также нужно писать вручную (поскольку это контекстно-зависимая конструкция).
Заключение
В данной статье мы рассмотрели парсинг исходников с помощью ANTLR и Roslyn. В следующих статьях мы расскажем:
- о преобразовани деревьев разбора языков программирования в унифицированное AST с использованием Visitor или Walker (Listener);
- написании легкочитаемых, оптимальных по производительности и удобных в использовании грамматик в ANTLR 4;
- сериализации и обходе древовидных структур в .NET;
- сопоставлении с шаблонами в унифицированном AST;
- разработке и использовании DSL для описания шаблонов.
Для особо нетерпеливых я частично рассказа обо всех этих вещах в нашем с VladimirKochetkov вебинаре «Современные подходы к SAST» примерно с 40 по 60 минуты.
Источники
- Modeling and Discovering Vulnerabilities with Code Property Graphs; Fabian Yamaguchi; 2014.
- Compilers: Principles, Techniques, and Tools; Alfred V. Aho, Monica S. Lam, Ravi Sethi, and Jeffrey D. Ullman; 2006.
- The Definitive ANTLR Reference; Terence Parr; 2014.
- Adaptive LL(*) Parsing: The Power of Dynamic Analysis, Terence Parr; Sam Harwell; 2014.
- Roslyn code & docs, https://github.com/dotnet/roslyn
- ANTLR grammars, https://github.com/antlr/grammars-v4
- ANTLR code, https://github.com/antlr/antlr4
ссылка на оригинал статьи https://habrahabr.ru/post/210772/
Добавить комментарий