Введение
Эта статья является продолжением предыдущей опубликованной статьи Tailing the MongoDB Replica Set Oplog with Scala and Akka Streams.
Как мы обсуждали прежде, слежение за обновлениями в MongoDB Sharded Cluster Oplog имеет свои подводные камни по сравнению с Replica Set. Данная статья попытается раскрыть некоторые аспекты темы.
В блоге команды MongoDB имеются очень хорошие статьи, полностью покрывающие тему слежения за обновлениями из MongoDB Oplog в Sharded Clusters. Вы можете найти их по следующим ссылкам:
- Tailing the MongoDB Oplog on Sharded Clusters
- Pitfalls and Workarounds for Tailing the Oplog on a MongoDB Sharded Cluster
Так же вы можете найти информацию об MongoDB Sharded Cluster в документации.
Примеры, приведенные в данной статье не следует рассматривать и использовать в продакшн среде. Проект с примерами доступен на github.
MongoDB Sharded Cluster
Из документации MongoDB:
Sharding, или горизонтальное масштабирование, разделение и распределение данных на нескольких серверах или сегментах (shards). Каждый сегмент является независимой базой данных, и в совокупности все сегменты составляют единую локальную базу данных.
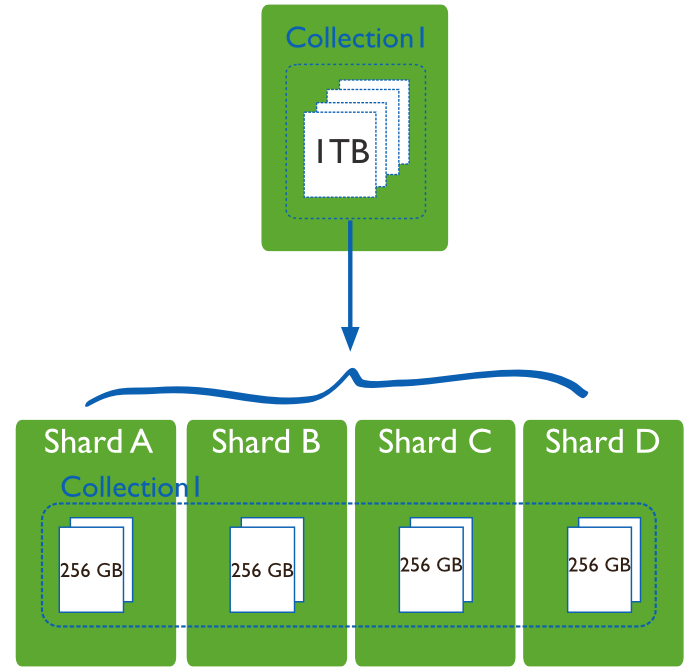
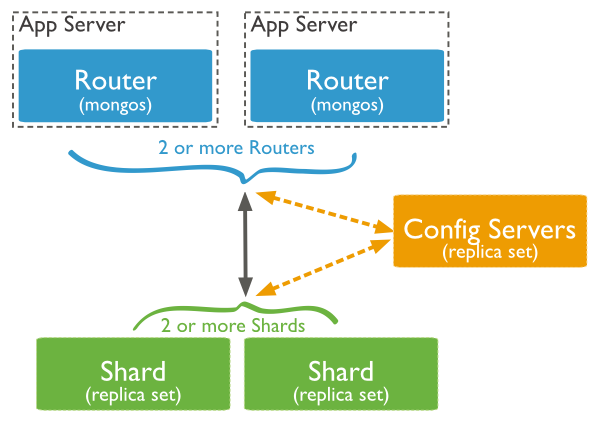
В продакшин среде каждый узел является Replica Set:
Внутренние операции MongoDB
Из-за распределения данных на несколько сегментов в MongoDB имеются внутрекластеровые операции, которые отражаются в oplog. Данные документы имеют дополнительное поле fromMigrate, т.к. мы не заинтересованы в этих операциях, мы обновим наш oplog запрос, чтобы исключить их из результата.
client.getDatabase("local") .getCollection("oplog.rs") .find(and( in(MongoConstants.OPLOG_OPERATION, "i", "d", "u"), exists("fromMigrate", false))) .cursorType(CursorType.TailableAwait) .noCursorTimeout(true)
Получение информации об узлах
Как вы наверно уже догадались, для слежения за обновлениями из oplog в Sharded Cluster нам понадобится следить за oplog каждого узла (Replica Set).
Для этого, мы можем запросить из базы данных config список всех доступных сегментов. Документы в коллекции выглядят как:
{ "_id" : "shard01", "host" : "shard01/localhost:27018,localhost:27019,localhost:27020" } Я предпочитаю использовать case классы вместо объектов Document, так что я объявлю класс:
case class Shard(name: String, uri: String) и функцию для перевода Document в Shard:
def parseShardInformation(item: Document): Shard = { val document = item.toBsonDocument val shardId = document.getString("_id").getValue val serversDefinition = document.getString("host").getValue val servers = if (serversDefinition.contains("/")) serversDefinition.substring(serversDefinition.indexOf('/') + 1) else serversDefinition Shard(shardId, "mongodb://" + servers) }теперь мы можем сделать запрос:
val shards = client.getDatabase("config") .getCollection("shards") .find() .map(parseShardInformation)В конечном итоге у нас будет список всех сегментов из нашего MongoDB Sharded Cluster.
Объявление Source для каждого узла
Что бы обозначить Source, мы можем просто пройтись по нашему списку сегментов и использовать метод из предыдущей статьи.
def source(client: MongoClient): Source[Document, NotUsed] = { val observable = client.getDatabase("local") .getCollection("oplog.rs") .find(and( in("op", "i", "d", "u"), exists("fromMigrate", false))) .cursorType(CursorType.TailableAwait) .noCursorTimeout(true) Source.fromPublisher(observable) } val sources = shards.map({ shard => val client = MongoClient(shard.uri) source(client) })
Один Source, чтобы управлять ими всеми
Мы могли бы обрабатывать каждый Source по отдельности, но конечно же намного легче и удобнее работать с ними в качестве одного Source. Для этого мы должны объединить их.
В Akka Streams имеется несколько Fan-in операций:
- Merge[In] – (N входящих потоков, 1 выходящий поток) выбирает элементы в случайном порядке из входящих потоков и отправляет их по одному в выходной поток.
- MergePreferred[In] – похоже на Merge но если элементы доступны на предпочтительном потоке, то выбирает элементы из него, иначе выбирает по тому же принципу что и **Merge
- ZipWith[A,B,…,Out] – (N входящих потоков, 1 выходящий поток) получает функцию от N входящих потоков которая возвращает 1 элемент в выходящий поток за элемент из каждого входящего потока.
- Zip[A,B] – (2 входящих потока, 1 выходящий поток) тоже самое что и ZipWith предназначенный для соединения элементов из потоков A и B в поток парных значений (A, B)
- Concat[A] – (2 входящих потока, 1 выходящий поток) соединяет 2 потока (отправляет элементы из первого потока, а потом из второго)
Мы используем упрощенный API для Merge и затем выведем все элементы потока в STDOUT:
val allShards: Source[Document, NotUsed] = sources.foldLeft(Source.empty[Document]) { (prev, current) => Source.combine(prev, current)(Merge(_)) } allShards.runForeach(println)
Обработка ошибок — Переключения и Аварийные Откаты
Для обработки ошибок Akka Streams использует Supervision Strategies. В общем имеется 3 различных способа для обработки ошибки:
- Stop — Поток завершается с ошибкой.
- Resume — Ошибочный элемент пропускается и обработка потока продолжится.
- Restart — Ошибочный элемент пропускается и обработка потока продолжится после перезагрузки текущего этапа. Перезагрузка этапа означает, что все аккумулированные данные очищаются. Это обычно достигается созданием нового образца этапа.
По умолчанию всегда используется Stop.
Но к сожалению все вышесказанное не относится к компонентам ActorPublisher и ActorSubscriber, так что в случае любой ошибки в нашем Source мы не сможем корректно восстановить обработку потока.
На Github #16916 уже описана данная проблема, и я надеюсь что это будет исправлено скоро.
В качестве альтернативы вы можете рассмотреть предложенный в статье Pitfalls and Workarounds for Tailing the Oplog on a MongoDB Sharded Cluster вариант:
Наконец, совершенно иным подходом будет, если мы будем следить за обновлениями большинства или даже всех узлов в наборе реплик. Так как пара значений
ts & hполей уникально идентифицирует каждую транзакцию, можно легко объединить результаты из каждогоoplogна стороне приложения, так что результатом потока будут события, которые были возвращены большинством узлов MongoDB. При таком подходе вам не нужно заботиться о том, является ли узел первичным или вторичным, вы просто следите заoplogвсех узлов, и все события, которые возвращаются большинствомoplogсчитаются действительными. Если вы получаете события, которые не существуют в большинствеoplog, такие события пропускаются и отбрасывают.
Я попытаюсь использовать данный вариант в одной из следующих статей.
Вывод
Мы не охватили тему обновлений orphan документов в MongoDB Sharded Cluster, т.к. в моем случае я заинтересован во всех операциях из oplog и рассматривают их идемпотентными по полю _id, так что это не мешает.
Как вы могли видеть, имеется множество аспектов которые довольно легко решаются при помощи Akka Streams, но имеются и сложные для решения. В общем у меня двоякое впечатление об этой библиотеке. Библиотека полна хороших идей, которые переносят идеи Akka Actors на новый уровень, но все это еще чувствуется недоработанным. Лично я пока буду придерживаться Akka Actors.
ссылка на оригинал статьи https://habrahabr.ru/post/279675/
Добавить комментарий