HOW TO: Web Scrapping с помощью Python
Введение
Недавно заглянув на КиноПоиск, я обнаружила, что за долгие годы успела оставить более 1000 оценок и подумала, что было бы интересно поисследовать эти данные подробнее: менялись ли мои вкусы в кино с течением времени? есть ли годовая/недельная сезонность в активности? коррелируют ли мои оценки с рейтингом КиноПоиска, IMDb или кинокритиков?
Но прежде чем анализировать и строить красивые графики, нужно получить данные. К сожалению, многие сервисы (и КиноПоиск не исключение) не имеют публичного API, так что, приходится засучить рукава и парсить html-страницы. Именно о том, как скачать и распарсить web-cайт, я и хочу рассказать в этой статье.
В первую очередь статья предназначена для тех, кто всегда хотел разобраться с Web Scrapping, но не доходили руки или не знал с чего начать.
Off-topic: к слову, Новый Кинопоиск под капотом использует запросы, которые возвращают данные об оценках в виде JSON, так что, задача могла быть решена и другим путем.
Задача
Задача будет состоять в том, чтобы выгрузить данные о просмотренных фильмах на КиноПоиске: название фильма (русское, английское), дату и время просмотра, оценку пользователя.
На самом деле, можно разбить работу на 2 этапа:
- Этап 1: выгрузить и сохранить html-страницы
- Этап 2: распарсить html в удобный для дальнейшего анализа формат (csv, json, pandas dataframe etc.)
Инструменты
Для отправки http-запросов есть немало python-библиотек, наиболее известные urllib/urllib2 и Requests. На мой вкус Requests удобнее и лаконичнее, так что, буду использовать ее.
Также необходимо выбрать библиотеку для парсинга html, небольшой research дает следующие варианты:
- re
Регулярные выражения, конечно, нам пригодятся, но использовать только их, на мой взгляд, слишком хардкорный путь, и они немного не для этого. Были придуманы более удобные инструменты для разбора html, так что перейдем к ним. - BeatifulSoup, lxml
Это две наиболее популярные библиотеки для парсинга html и выбор одной из них, скорее, обусловлен личными предпочтениями. Более того, эти библиотеки тесно переплелись: BeautifulSoup стал использовать lxml в качестве внутреннего парсера для ускорения, а в lxml был добавлен модуль soupparser. Подробнее про плюсы и минусы этих библиотек можно почитать в обсуждении. Для сравнения подходов я буду парсить данные с помощью BeautifulSoup и используя XPath селекторы в модуле lxml.html. - scrapy
Это уже не просто библиотека, а целый open-source framework для получения данных с веб-страниц. В нем есть множество полезных функций: асинхронные запросы, возможность использовать XPath и CSS селекторы для обработки данных, удобная работа с кодировками и многое другое (подробнее можно почитать тут). Если бы моя задача была не разовой выгрузкой, а production процессом, то я бы выбрала его. В текущей постановке это overkill.
Загрузка данных
Первая попытка
Приступим к выгрузке данных. Для начала, попробуем просто получить страницу по url и сохранить в локальный файл.
import requests user_id = 12345 url = 'http://www.kinopoisk.ru/user/%d/votes/list/ord/date/page/2/#list' % (user_id) # url для второй страницы r = requests.get(url) with open('test.html', 'w') as output_file: output_file.write(r.text.encode('cp1251')) Открываем полученный файл и видим, что все не так просто: сайт распознал в нас робота и не спешит показывать данные.

Разберемся, как работает браузер
Однако, у браузера отлично получается получать информацию с сайта. Посмотрим, как именно он отправляет запрос. Для этого воспользуемся панелью "Сеть" в "Инструментах разработчика" в браузере (я использую для этого Firebug), обычно нужный нам запрос — самый продолжительный.
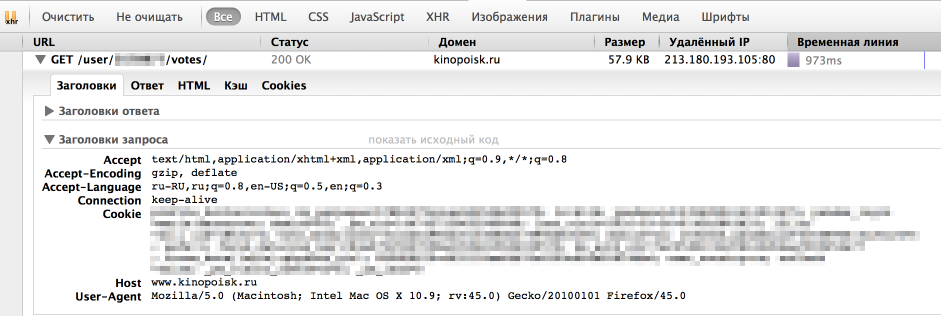
Как мы видим, браузер также передает в headers UserAgent, cookie и еще ряд параметров. Для начала попробуем просто передать в header корректный UserAgent.
headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0' } r = requests.get(url, headers = headers)На этот раз все получилось, теперь нам отдаются нужные данные. Стоит отметить, что иногда сайт также проверяет корректность cookie, в таком случае помогут sessions в библиотеке Requests.
Скачаем все оценки
Теперь мы умеем сохранять одну страницу с оценками. Но обычно у пользователя достаточно много оценок и нужно проитерироваться по всем страницам. Интересующий нас номер страницы легко передать непосредственно в url. Остается только вопрос: "Как понять сколько всего страниц с оценками?" Я решила эту проблему следующим образом: если указать слишком большой номер страницы, то нам вернется вот такая страница без таблицы с фильмами. Таким образом мы можем итерироваться по страницам до тех, пор пока находится блок с оценками фильмов (<div class = "profileFilmsList">).

import requests # establishing session s = requests.Session() s.headers.update({ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0' }) def load_user_data(user_id, page, session): url = 'http://www.kinopoisk.ru/user/%d/votes/list/ord/date/page/%d/#list' % (user_id, page) request = session.get(url) return request.text def contain_movies_data(text): soup = BeautifulSoup(text) film_list = soup.find('div', {'class': 'profileFilmsList'}) return film_list is not None # loading files page = 1 while True: data = load_user_data(user_id, page, s) if contain_movies_data(data): with open('./page_%d.html' % (page), 'w') as output_file: output_file.write(data.encode('cp1251')) page += 1 else: break
Парсинг
Немного про XPath
XPath — это язык запросов к xml и xhtml документов. Мы будем использовать XPath селекторы при работе с библиотекой lxml (документация lxml). Рассмотрим небольшой пример работы с XPath
from lxml import html test = ''' <html> <body> <div class="first_level"> <h2 align='center'>one</h2> <h2 align='left'>two</h2> </div> <h2>another tag</h2> </body> </html> ''' tree = html.fromstring(test) tree.xpath('//h2') # все h2 теги tree.xpath('//h2[@align]') # h2 теги с атрибутом align tree.xpath('//h2[@align="center"]') # h2 теги с атрибутом align равным "center" div_node = tree.xpath('//div')[0] # div тег div_node.xpath('.//h2') # все h2 теги, которые являются дочерними div ноде Подробнее про синтаксис XPath также можно почитать на W3Schools.
Вернемся к нашей задаче
Теперь перейдем непосредственно к получению данных из html. Проще всего понять как устроена html-страница используя функцию "Инспектировать элемент" в браузере. В данном случае все довольно просто: вся таблица с оценками заключена в теге <div class = "profileFilmsList">. Выделим эту ноду:
from bs4 import BeautifulSoup from lxml import html # Beautiful Soup soup = BeautifulSoup(text) film_list = film_list = soup.find('div', {'class': 'profileFilmsList'}) # lxml tree = html.fromstring(text) film_list_lxml = tree.xpath('//div[@class = "profileFilmsList"]')[0] Каждый фильм представлен как <div class = "item"> или <div class = "item even">. Рассмотрим, как вытащить русское название фильма и ссылку на страницу фильма (также узнаем, как получить текст и значение атрибута).
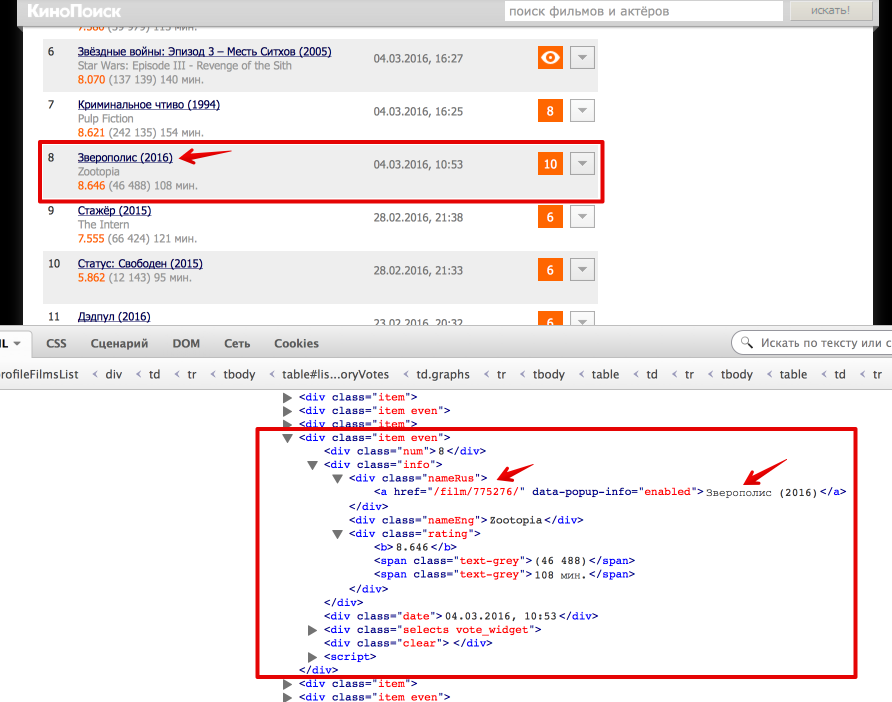
# Beatiful Soup movie_link = item.find('div', {'class': 'nameRus'}).find('a').get('href') movie_desc = item.find('div', {'class': 'nameRus'}).find('a').text # lxml movie_link = item_lxml.xpath('.//div[@class = "nameRus"]/a/@href')[0] movie_desc = item_lxml.xpath('.//div[@class = "nameRus"]/a/text()')[0] Еще небольшой хинт для debug’a: для того, чтобы посмотреть, что внутри выбранной ноды в BeautifulSoup можно просто распечатать ее, а в lxml воспользоваться функцией tostring() модуля etree.
# BeatifulSoup print item #lxml from lxml import etree print etree.tostring(item_lxml)
def read_file(filename): with open(filename) as input_file: text = input_file.read() return text def parse_user_datafile_bs(filename): results = [] text = read_file(filename) soup = BeautifulSoup(text) film_list = film_list = soup.find('div', {'class': 'profileFilmsList'}) items = film_list.find_all('div', {'class': ['item', 'item even']}) for item in items: # getting movie_id movie_link = item.find('div', {'class': 'nameRus'}).find('a').get('href') movie_desc = item.find('div', {'class': 'nameRus'}).find('a').text movie_id = re.findall('\d+', movie_link)[0] # getting english name name_eng = item.find('div', {'class': 'nameEng'}).text #getting watch time watch_datetime = item.find('div', {'class': 'date'}).text date_watched, time_watched = re.match('(\d{2}\.\d{2}\.\d{4}), (\d{2}:\d{2})', watch_datetime).groups() # getting user rating user_rating = item.find('div', {'class': 'vote'}).text if user_rating: user_rating = int(user_rating) results.append({ 'movie_id': movie_id, 'name_eng': name_eng, 'date_watched': date_watched, 'time_watched': time_watched, 'user_rating': user_rating, 'movie_desc': movie_desc }) return results def parse_user_datafile_lxml(filename): results = [] text = read_file(filename) tree = html.fromstring(text) film_list_lxml = tree.xpath('//div[@class = "profileFilmsList"]')[0] items_lxml = film_list_lxml.xpath('//div[@class = "item even" or @class = "item"]') for item_lxml in items_lxml: # getting movie id movie_link = item_lxml.xpath('.//div[@class = "nameRus"]/a/@href')[0] movie_desc = item_lxml.xpath('.//div[@class = "nameRus"]/a/text()')[0] movie_id = re.findall('\d+', movie_link)[0] # getting english name name_eng = item_lxml.xpath('.//div[@class = "nameEng"]/text()')[0] # getting watch time watch_datetime = item_lxml.xpath('.//div[@class = "date"]/text()')[0] date_watched, time_watched = re.match('(\d{2}\.\d{2}\.\d{4}), (\d{2}:\d{2})', watch_datetime).groups() # getting user rating user_rating = item_lxml.xpath('.//div[@class = "vote"]/text()') if user_rating: user_rating = int(user_rating[0]) results.append({ 'movie_id': movie_id, 'name_eng': name_eng, 'date_watched': date_watched, 'time_watched': time_watched, 'user_rating': user_rating, 'movie_desc': movie_desc }) return results
Резюме
В результате, мы научились парсить web-сайты, познакомились с библиотеками Requests, BeautifulSoup и lxml, а также получили пригодные для дальнейшего анализа данные о просмотренных фильмах на КиноПоиске.

Полный код проекта можно найти на github’e.
ссылка на оригинал статьи https://habrahabr.ru/post/280238/
Добавить комментарий