
Если Вам интересно, как вызов метода ClassLoader.getResourceAsStream() в Android приложении может занимать 1432ms и насколько опасны могут быть некоторые библиотеки — прошу под кат.
Описание проблемы
Исследуя проблемы производительности в android приложениях, я заметил данный метод. Проблема проявлялась только при самом первом вызове, все последующие занимали несколько миллисекунд. Интересной особенностью было то, что проблема есть в очень большом количестве приложений, начиная от Amazon’s Kindle с более чем 100,000,000 скачиваний и заканчивая мелкими с парой сотен загрузок.
Другая особенность заключается в том, что в разных приложениях этот метод занимал совершенно разное время. Вот, например, время для популярнейшего приложения для селфи: B612 — Selfie from the heart

Как видим, тут метод занимаем 771ms, что тоже не мало, но намного меньше чем 1432ms.
Еще немного очень популярных приложений, чтобы подчеркнуть, насколько велика проблема.
(Для профилирования приложений, использовался сервис https://nimbledroid.com)
| Приложение | Время выполнения getResourceAsStream() |
|---|---|
| Yahoo Fantasy Sports | 2166ms |
| Timehop | 1538ms |
| Audiobooks from Audible | 1527ms |
| Nike+ Running | 1432ms |
| Booking.com Hotel Reservations | 497ms |
И еще много много других.
Давайте внимательно посмотрим на Call Stack некоторых приложений.
LINE: Free Calls & Messages:

Как мы видим, вызов getResourceAsStream выполняется НЕ в главном потоке. Это значит, что разработчики Line знают о том, насколько он медленный.
Yahoo Fantasy Sports:

Вызов происходит не в коде приложения, а внутри библиотеки JodaTime
Audiobooks from Audible

Вызов происходит в библиотеке логирование Logback
После анализа приложений с этой проблемой, становится понятно, что этот вызов в основном используется в различных библиотеках и SDK, которые распространяются в виде Jar файлов. Это логично, так как таким образом мы можем получить доступ к ресурсам, более того, этот код будет работать и на Android, и в мире большой Java. Многие приходят в Android разработку имея Java опыт и, естественно, начинают использовать знакомые библиотеки, не зная о том, насколько замедляют свои приложения. Думаю теперь понятно, почему затронуто такое большое количество приложений.
На самом деле о проблеме знают, были, например, такие вопросы на stackoverflow: Android Java — Joda Date is slow
В далеком 2013 году был написан этот пост: http://blog.danlew.net/2013/08/20/joda_time_s_memory_issue_in_android/ и появилась такая библиотека https://github.com/dlew/joda-time-android.
НО
- До сих пор есть много приложений, которые используют обычную версию JodaTime.
- Есть много других библиотек и SDK с такой же проблемой.
Теперь, когда проблема ясна, давайте попробуем разобраться в чем ее причина.
Исследование проблемы
Для этого мы будем разбираться в исходном коде Android.
Я не буду останавливаться на том, где найти исходники, как собирать AOSP и т.д., а сразу перейду к делу, для тех, кто все же хочет попробовать разобраться в этом самостоятельно и повторить мой путь, начинайте отсюда: https://source.android.com/
Я буду использовать ветку android-6.0.1_r11
Давайте откроем файл libcore/libart/src/main/java/java/lang/ClassLoader.java и посмотрим на код getResourceAsStream:
public InputStream getResourceAsStream(String resName) { try { URL url = getResource(resName); if (url != null) { return url.openStream(); } } catch (IOException ex) { // Don't want to see the exception. } return null; }Все выглядит довольно просто, сначала находим путь к ресурсу, и если он не null, то открываем его с помощью метода openStream(), который есть в java.net.URL
Давайте посмотрим на реализацию getResource():
public URL getResource(String resName) { URL resource = parent.getResource(resName); if (resource == null) { resource = findResource(resName); } return resource; }Все еще ничего интересного, findResource():
protected URL findResource(String resName) { return null; }Ок, то есть findResource() не реализован. ClassLoader это абстрактный класс, значит нам нужно найти, какой класс используется в реальных приложениях. Если мы откроем документацию: http://developer.android.com/reference/java/lang/ClassLoader.html, то увидим: Android provides several concrete implementations of the class, with PathClassLoader being the one typically used..
Хочется в этом убедиться, поэтому я собрал AOSP, предварительно модифицировав getResourceAsStream() подобным образом:
public InputStream getResourceAsStream(String resName) { try { Logger.getLogger("RESEARCH").info("this: " + this); URL url = getResource(resName); if (url != null) { return url.openStream(); } ... Я получил то, что и ожидалось — dalvik.system.PathClassLoader, но если мы проверим исходники PathClassLoader, мы не найдем реализации findResource(). На самом деле findResource() реализован в родительском классе — BaseDexClassLoader.
/libcore/dalvik/src/main/java/dalvik/system/BaseDexClassLoader.java:
@Override protected URL findResource(String name) { return pathList.findResource(name); }Давайте найдем pathList (я специально не удаляю комментарии разработчиков, чтобы было проще понять, что есть что):
public class BaseDexClassLoader extends ClassLoader { private final DexPathList pathList; /** * Constructs an instance. * * @param dexPath the list of jar/apk files containing classes and * resources, delimited by {@code File.pathSeparator}, which * defaults to {@code ":"} on Android * @param optimizedDirectory directory where optimized dex files * should be written; may be {@code null} * @param libraryPath the list of directories containing native * libraries, delimited by {@code File.pathSeparator}; may be * {@code null} * @param parent the parent class loader */ public BaseDexClassLoader(String dexPath, File optimizedDirectory, String libraryPath, ClassLoader parent) { super(parent); this.pathList = new DexPathList(this, dexPath, libraryPath, optimizedDirectory); } Давайте перейдем в этот DexPathList.
libcore/dalvik/src/main/java/dalvik/system/DexPathList.java:
/** * A pair of lists of entries, associated with a {@code ClassLoader}. * One of the lists is a dex/resource path — typically referred * to as a "class path" — list, and the other names directories * containing native code libraries. Class path entries may be any of: * a {@code .jar} or {@code .zip} file containing an optional * top-level {@code classes.dex} file as well as arbitrary resources, * or a plain {@code .dex} file (with no possibility of associated * resources). * * <p>This class also contains methods to use these lists to look up * classes and resources.</p> */ /*package*/ final class DexPathList {Кажется мы нашли место, где реально выполняется поиск ресурса.
/** * Finds the named resource in one of the zip/jar files pointed at * by this instance. This will find the one in the earliest listed * path element. * * @return a URL to the named resource or {@code null} if the * resource is not found in any of the zip/jar files */ public URL findResource(String name) { for (Element element : dexElements) { URL url = element.findResource(name); if (url != null) { return url; } } return null; }Element — это просто статический внутренний класс в DexPathList. И внутри него есть намного более интересный код:
public URL findResource(String name) { maybeInit(); // We support directories so we can run tests and/or legacy code // that uses Class.getResource. if (isDirectory) { File resourceFile = new File(dir, name); if (resourceFile.exists()) { try { return resourceFile.toURI().toURL(); } catch (MalformedURLException ex) { throw new RuntimeException(ex); } } } if (zipFile == null || zipFile.getEntry(name) == null) { /* * Either this element has no zip/jar file (first * clause), or the zip/jar file doesn't have an entry * for the given name (second clause). */ return null; } try { /* * File.toURL() is compliant with RFC 1738 in * always creating absolute path names. If we * construct the URL by concatenating strings, we * might end up with illegal URLs for relative * names. */ return new URL("jar:" + zip.toURL() + "!/" + name); } catch (MalformedURLException ex) { throw new RuntimeException(ex); } }Давайте на этом немного остановимся. Как мы знаем, APK — это просто zip файл. Как мы видим:
if (zipFile == null || zipFile.getEntry(name) == null) {мы пытаемся найти ZipEntry по имени, и если находим, то возвращаем java.net.URL. Это может быть довольно медленная операция, но если мы проверим реализацию getEntry, мы увидим, что это просто итерация по LinkedHashMap:
/libcore/luni/src/main/java/java/util/zip/ZipFile.java:
... private final LinkedHashMap<String, ZipEntry> entries = new LinkedHashMap<String, ZipEntry>(); ... public ZipEntry getEntry(String entryName) { checkNotClosed(); if (entryName == null) { throw new NullPointerException("entryName == null"); } ZipEntry ze = entries.get(entryName); if (ze == null) { ze = entries.get(entryName + "/"); } return ze; }Это не супер быстрая операция, но она не может занимать очень много времени.
Мы упустили одну вещь: прежде чем работать с Zip файлами, мы должны открыть их. Если мы снова посмотрим на реализацию метода DexPathList.Element.findResource(), мы увидим вызов maybeInit();.
Давайте проверим его:
public synchronized void maybeInit() { if (initialized) { return; } initialized = true; if (isDirectory || zip == null) { return; } try { zipFile = new ZipFile(zip); } catch (IOException ioe) { /* * Note: ZipException (a subclass of IOException) * might get thrown by the ZipFile constructor * (e.g. if the file isn't actually a zip/jar * file). */ System.logE("Unable to open zip file: " + zip, ioe); zipFile = null; } }Вот оно! Эта строка:
zipFile = new ZipFile(zip);открывает zip файл на чтение.
public ZipFile(File file) throws ZipException, IOException { this(file, OPEN_READ); }Это очень медленная операция, тут мы инициализируем entries LinkedHashMap. Очевидно, что чем больше zip файл, тем больше времени потребуется на его открытие. Из-за флага initialized мы открываем zip файл только один раз, это обьясняет почему последующие вызовы происходят быстро.
Чтобы больше разобраться во внутренней структуре Zip файла, посмотрите исходники:
https://android.googlesource.com/platform/libcore/+/android-6.0.1_r21/luni/src/main/java/java/util/zip/ZipFile.java
Надеюсь это было интересно! Потому что это — только начало.
На самом деле, пока мы разобрались только с вызовом:
URL url = getResource(resName);Но если мы изменим код getResourceAsStream таким образом:
public InputStream getResourceAsStream(String resName) { try { long start; long end; start = System.currentTimeMillis(); URL url = getResource(resName); end = System.currentTimeMillis(); Logger.getLogger("RESEARCH").info("getResource: " + (end - start)); if (url != null) { start = System.currentTimeMillis(); InputStream inputStream = url.openStream(); end = System.currentTimeMillis(); Logger.getLogger("RESEARCH").info("url.openStream: " + (end - start)); return inputStream; } ...соберем AOSP и протестируем пару приложений, то мы увидим, что url.openStream() занимает значительно больше времени, чем getResource().
url.openStream()
В этой части я опущу некоторые не очень интересные моменты. Если мы будем двигаться по цепочке вызовов от url.openStream(), то мы попадем в /libcore/luni/src/main/java/libcore/net/url/JarURLConnectionImpl.java:
@Override public InputStream getInputStream() throws IOException { if (closed) { throw new IllegalStateException("JarURLConnection InputStream has been closed"); } connect(); if (jarInput != null) { return jarInput; } if (jarEntry == null) { throw new IOException("Jar entry not specified"); } return jarInput = new JarURLConnectionInputStream(jarFile .getInputStream(jarEntry), jarFile); }Давайте проверим метод connect():
@Override public void connect() throws IOException { if (!connected) { findJarFile(); // ensure the file can be found findJarEntry(); // ensure the entry, if any, can be found connected = true; } }Ничего интересного, we need to go deeper 🙂
private void findJarFile() throws IOException { if (getUseCaches()) { synchronized (jarCache) { jarFile = jarCache.get(jarFileURL); } if (jarFile == null) { JarFile jar = openJarFile(); synchronized (jarCache) { jarFile = jarCache.get(jarFileURL); if (jarFile == null) { jarCache.put(jarFileURL, jar); jarFile = jar; } else { jar.close(); } } } } else { jarFile = openJarFile(); } if (jarFile == null) { throw new IOException(); } }Это интересный метод и тут мы остановимся. getUseCaches() через цепочку вызовов приведет нас к
public abstract class URLConnection { ... private static boolean defaultUseCaches = true; ...Это значение не переопределяется, поэтому мы увидим использование cache:
private static final HashMap<URL, JarFile> jarCache = new HashMap<URL, JarFile>(); Тут мы видим вторую проблему производительности! Zip файл открывается снова! Естественно это не будет работать быстро, особенно для приложений размером 40mb 🙂
Есть еще один интересный момент, давайте проверим метод openJarFile():
private JarFile openJarFile() throws IOException { if (jarFileURL.getProtocol().equals("file")) { String decodedFile = UriCodec.decode(jarFileURL.getFile()); return new JarFile(new File(decodedFile), true, ZipFile.OPEN_READ); } else { ...Как вы видите, мы создаем НЕ ZipFile, а JarFile. JarFile наследник ZipFile, давайте проверим, что он добавляет:
/** * Create a new {@code JarFile} using the contents of file. * * @param file * the JAR file as {@link File}. * @param verify * if this JAR filed is signed whether it must be verified. * @param mode * the mode to use, either {@link ZipFile#OPEN_READ OPEN_READ} or * {@link ZipFile#OPEN_DELETE OPEN_DELETE}. * @throws IOException * If the file cannot be read. */ public JarFile(File file, boolean verify, int mode) throws IOException { super(file, mode); // Step 1: Scan the central directory for meta entries (MANIFEST.mf // & possibly the signature files) and read them fully. HashMap<String, byte[]> metaEntries = readMetaEntries(this, verify); // Step 2: Construct a verifier with the information we have. // Verification is possible *only* if the JAR file contains a manifest // *AND* it contains signing related information (signature block // files and the signature files). // // TODO: Is this really the behaviour we want if verify == true ? // We silently skip verification for files that have no manifest or // no signatures. if (verify && metaEntries.containsKey(MANIFEST_NAME) && metaEntries.size() > 1) { // We create the manifest straight away, so that we can create // the jar verifier as well. manifest = new Manifest(metaEntries.get(MANIFEST_NAME), true); verifier = new JarVerifier(getName(), manifest, metaEntries); } else { verifier = null; manifestBytes = metaEntries.get(MANIFEST_NAME); } }Ага, вот и разница! Как мы знаем, APK файл должен быть подписан, и класс JarFile это проверит.
Я не буду углубляться дальше, если вы хотите понять как работает верификация, смотрите тут: https://android.googlesource.com/platform/libcore/+/android-6.0.1_r21/luni/src/main/java/java/util/jar/.
Но, что нужно сказать, так это то, что это очень очень медленный процесс.
Заключение
Когда ClassLoader.getResourceAsStream() вызывается первый раз, APK файл открывается как zip файл, чтобы найти ресурс. После этого он открывается второй раз, но уже с верификацией, чтобы открыть InputStream. Это также обьясняет, почему такая большая разница в скорости работы вызова для разных приложений, все зависит от размера APK файла и насколько много файлов внутри!
One more thing
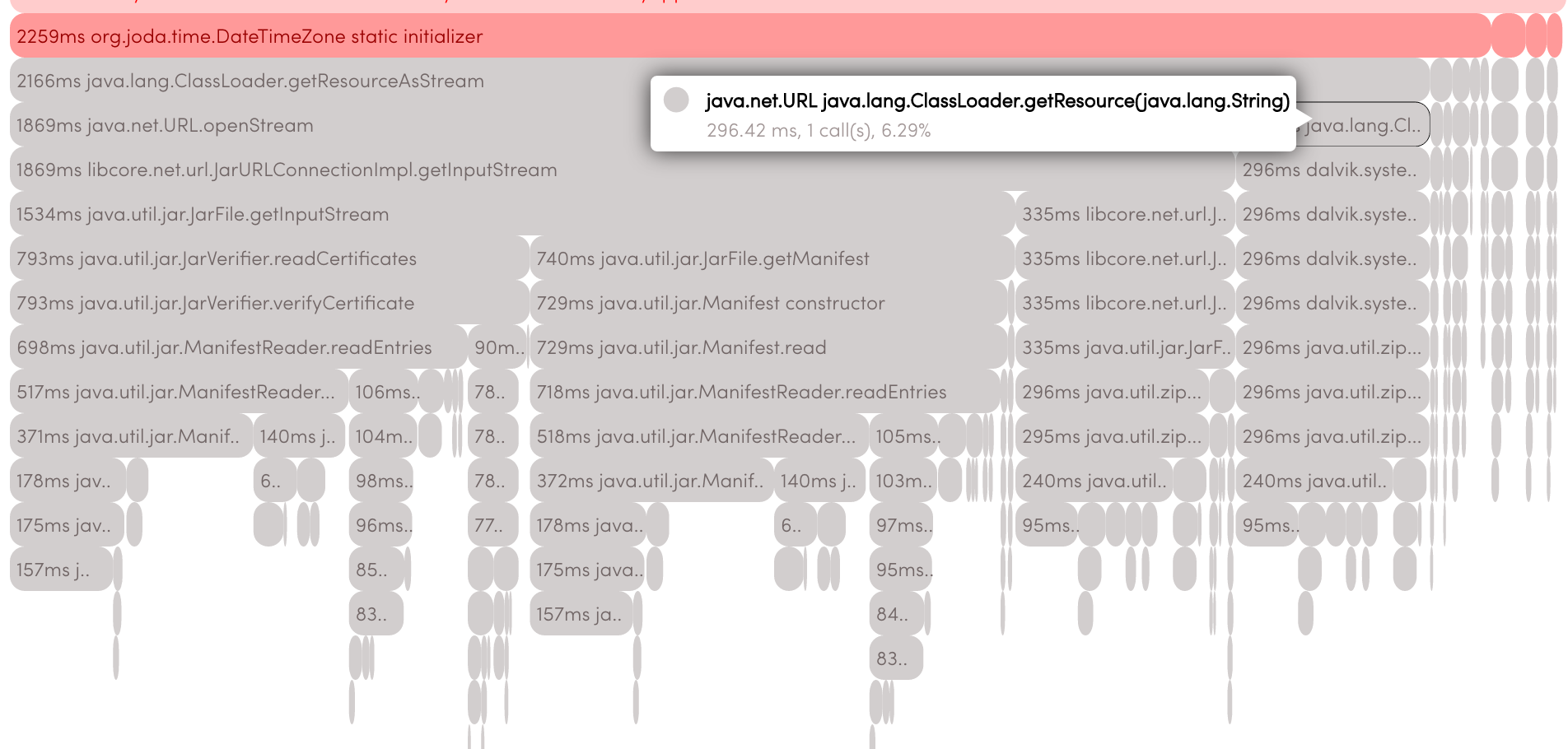
Если в nimbledroid в разделе Full Stack Trace в правом верхнем углу вы нажмете на Expand Android Framework, вы увидите все методы, по которым мы прошлись:
Q&A
Q: Есть ли какая нибудь разница между Dalvik и ART runtime и работой вызова getResourceAsStream()
A: На самом деле нет, я проверил несколько веток AOSP android-6.0.1_r11 с ART и android-4.4.4_r2 с Dalvik. Проблема есть в обеих!
Разница между ними немного в другом, но об этом много написано 🙂
Q: Почему нет такой проблемы при вызове ClassLoader.findClass()
A: Если мы перейдем в уже знакомый нам класс DexPathList, то мы увидим:
public Class findClass(String name, List<Throwable> suppressed) { for (Element element : dexElements) { DexFile dex = element.dexFile; if (dex != null) { Class clazz = dex.loadClassBinaryName(name, definingContext, suppressed); if (clazz != null) { return clazz; } } } if (dexElementsSuppressedExceptions != null) { suppressed.addAll(Arrays.asList(dexElementsSuppressedExceptions)); } return null; }Проследовав по цепочке вызовов мы прийдем к методу:
private static native Class defineClassNative(String name, ClassLoader loader, Object cookie) throws ClassNotFoundException, NoClassDefFoundError;И дальше то, как это будет работать, будет зависеть от runtime (ART или Dalvik), но как мы видим, никакой работы с ZipFile.
Q: Почему у вызовов Resources.get… (resId) нет этой проблемы
A: По той же причине, что и у ClassLoader.findClass().
Все эти вызовы приведут нас к /frameworks/base/core/java/android/content/res/AssetManager.java
/** Returns true if the resource was found, filling in mRetStringBlock and * mRetData. */ private native final int loadResourceValue(int ident, short density, TypedValue outValue, boolean resolve);Спасибо за внимание! Happy coding!
ссылка на оригинал статьи https://habrahabr.ru/post/280340/
Добавить комментарий