Введение
В Badoo несколько десятков «самописных» демонов. Большинство из них написаны на Си, остался один на С++ и пять или шесть на Go. Они работают примерно на сотне серверов в четырех дата-центрах.
В Badoo проверка работоспособности и обнаружение проблем с демонами лежат на плечах отдела мониторинга. Коллеги с помощью Zabbix и скриптов проверяют, запущен ли сервис, отвечает ли он на запросы, а также следят за версиями. Кроме того, в отделе анализируется статистика демонов и скриптов, работающих с ними, на предмет аномалий, резких скачков и т.п.
{kind=link}
Однако у нас до недавнего времени не было очень важной части — сбора и анализа логов, которые каждый демон пишет локально в файлы на сервере. Зачастую именно эта информация помогает на самом раннем этапе поймать проблему или постфактум понять причины отказа.
Мы построили такую систему и спешим поделиться подробностями. Наверняка у кого-то из вас будет стоять похожая задача, и прочтение данной статьи убережет от ошибок, которые мы успели совершить.
Выбор инструментов
Мы с самого начала отмели «облачные» системы, т.к. в Badoo принято не отдавать свои данные наружу, если это возможно. Проанализировав популярные инструменты, мы пришли к выводу, что, скорее всего, нам подойдет одна из трех систем:
Splunk
В первую очередь мы попробовали Splunk. Splunk — это система под ключ, закрытое и платное решение, стоимость которого напрямую зависит от трафика, приходящего в систему. Мы ее уже используем для данных в отделе биллинга. Коллеги очень довольны.
{kind=link}
Мы воспользовались их инсталляцией для тестов и почти сразу же столкнулись с тем, что наш трафик превышал имеющиеся и оплаченные лимиты.
Еще одним нюансом стало то, что во время тестирования некоторые сотрудники жаловались на сложность и «неинтуитивность» пользовательского интерфейса. Коллеги из биллинга за это время уже наловчились в общении со Splunk и у них не было никаких проблем, но все же этот факт стоит отметить, т.к. приятный интерфейс будет иметь большое значение, если мы хотим, чтобы нашей системой активно пользовались.
По технической части Splunk, судя по всему, нас полностью устраивал. Но его стоимость, закрытость и неудобный интерфейс заставили нас искать дальше.
ELK: Elastic Search + Logstash + Kibana
{kind=link}
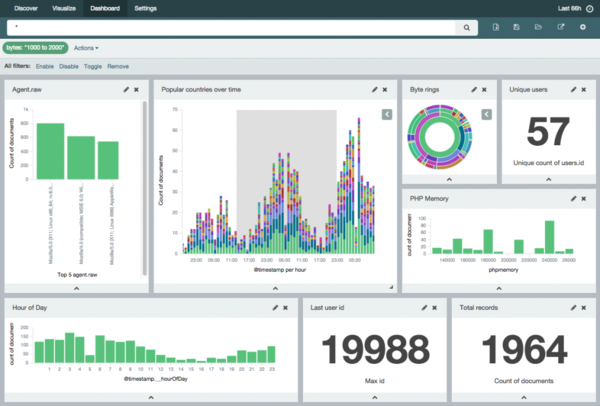
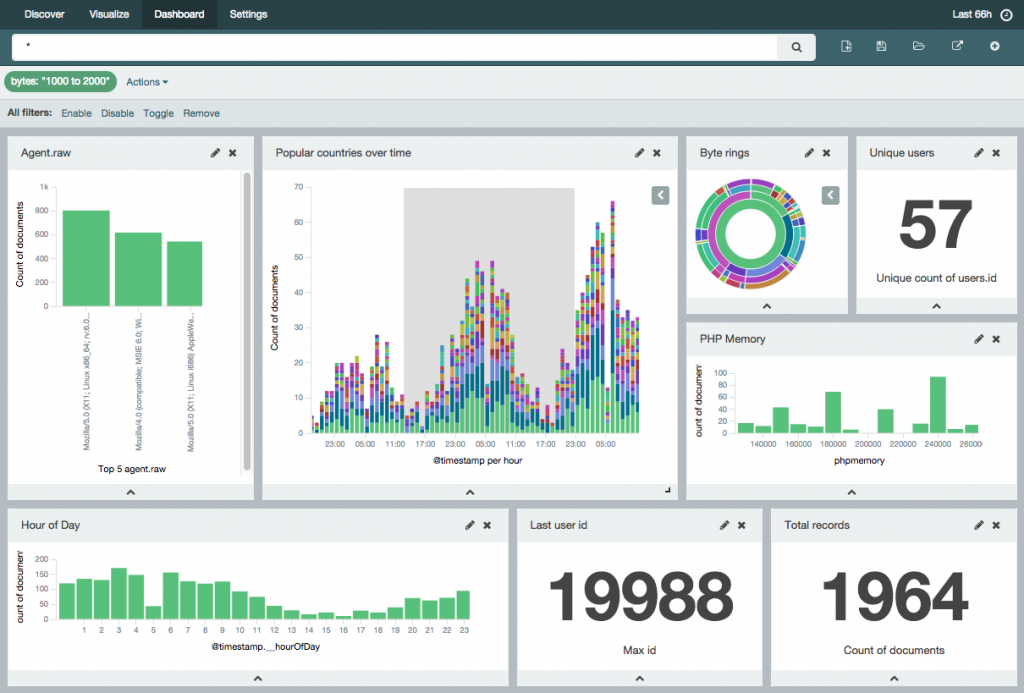
Следующей в списке оказалась ELK. ELK — это, наверное, самая популярная на сегодняшний день система для сбора и анализа логов. И хочу сказать, что это неудивительно, т.к. она бесплатная, простая, гибкая и мощная.
ELK состоит из трех компонентов:
- Elastic Search. Система хранения и поиска данных, основанная на «движке» Lucene;
- Logstash. «Труба» с кучей фич, через которую данные (возможно, обработанные) попадают в Elastic Search;
- Kibana. Веб-интерфейс для поиска и визуализации данных из Elastic Search.
Начать работать с ELK очень просто: достаточно скачать с официального сайта три архива, разархивировать и запустить несколько бинарников. Эта простота позволила за считаные дни протестировать систему и понять, насколько она нам подходит.
И в целом она подошла. Технически мы могли реализовать все, что нам нужно, при необходимости написать свои решения и встроить их в общую инфраструктуру.
Несмотря на то, что ELK нас полностью устраивала, был и третий претендент.
Graylog 2
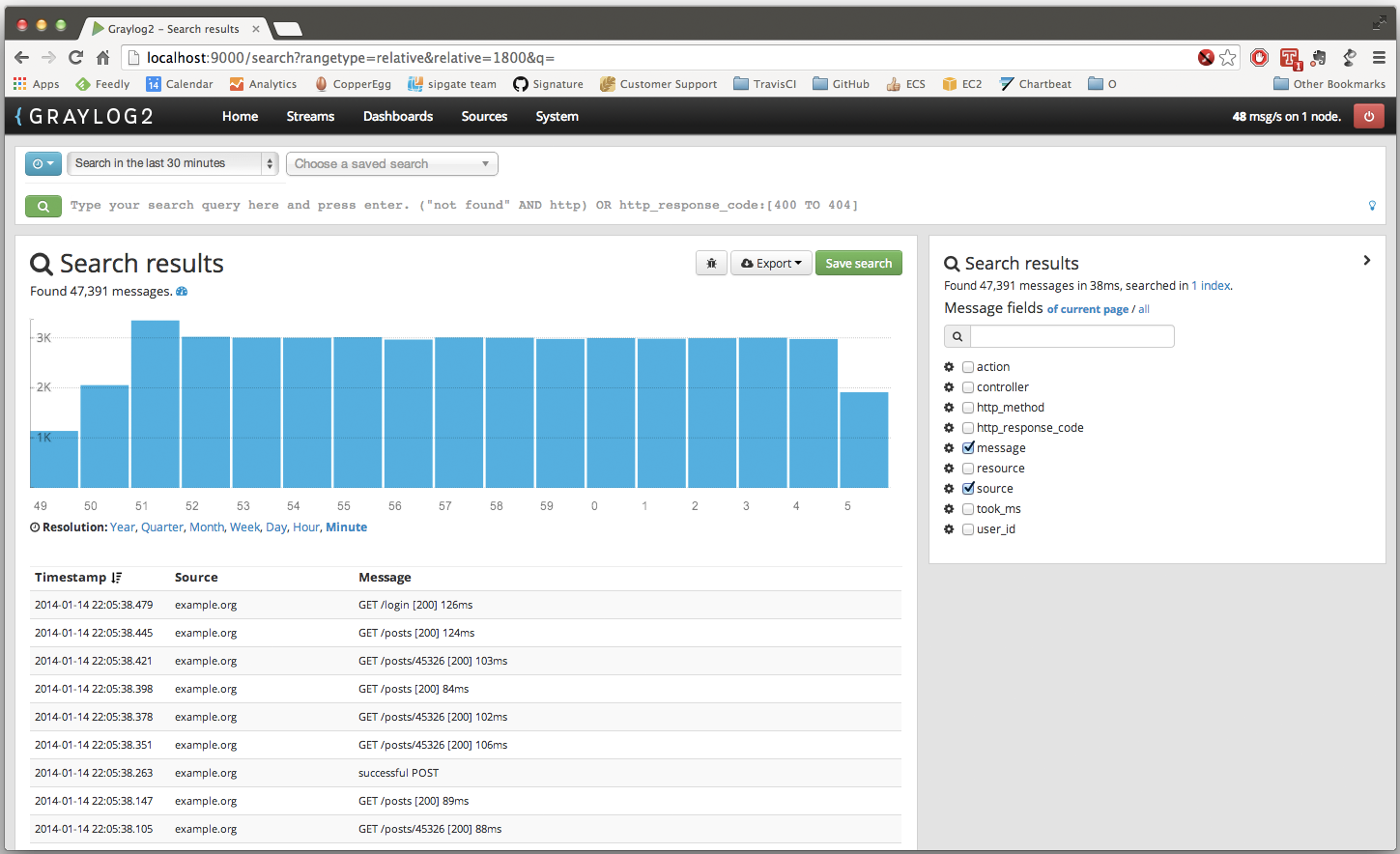{kind=link}
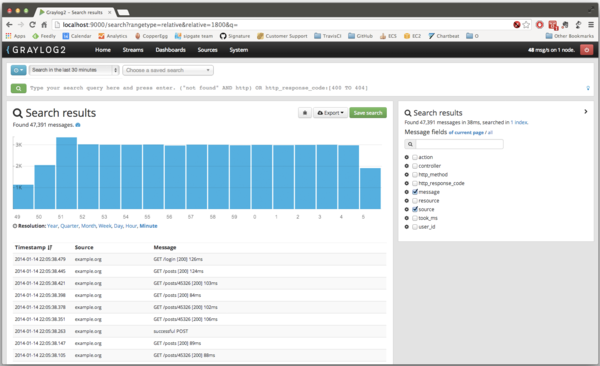
В общем и целом Graylog 2 очень похожа на ELK: открытый код, легко устанавливать, тоже используется Elastic Search и может использоваться Logstash. Основное отличие в том, что Graylog 2 — система, готовая к использованию и «заточенная» конкретно на сбор логов. Своей готовностью для конечного пользователя она очень напоминаем Splunk. Здесь есть и удобный графический интерфейс с возможностью настраивать разбор строчек прямо в браузере, и ограничение доступа, и уведомления.
Но мы пришли к выводу, что ELK позволит нам сделать гораздо более гибкую систему, настроенную под наши нужды; позволит расширяться, менять компоненты. Как конструктор. Не понравилась одна часть — заменили на другую. Не хотели платить за watcher — сделали свою систему. Если в ELK все части легко можно снять и заменить, в Graylog 2 было ощущение, что какие-то части придется выдирать с корнем, а какие-то просто не получится внедрить.
Решено. Будем делать на ELK.
Доставка логов
На самом раннем этапе мы поставили обязательное требование, что логи должны и попадать в наш сборщик, и оставаться на диске. Система сбора и анализа логов — это хорошо, но любая система дает некоторую задержку, может выйти из строя и ничто не заменит тех возможностей, которые дают стандартные unix-утилиты типа grep, AWK, sort и т.д. У программиста должна остаться возможность зайти на сервер и посмотреть своими глазами, что там происходит.
Доставлять логи в Logstash мы могли следующим образом:
- использовать имеющиеся утилиты из набора ELK (logstash-forwarder, а теперь уже beats). Они представляют из себя отдельный демон, который следит за файлом на диске и заливает его в Logstash;
- использовать собственную разработку под именем LSD, которая у нас доставляет PHP-логи. По сути, это тоже отдельный демон, который следит за файлами с логами в файловой системе и заливает их куда-то. С одной стороны, в LSD были учтены и решены все проблемы, которые могут произойти при заливке огромного количества логов с огромного количества серверов, но система слишком «заточена» на PHP-скрипты. Нам бы пришлось ее доделывать;
- параллельно с записью на диск записывать логи в стандартный для мира UNIX syslog.
Несмотря на недостатки последнего, этот подход был очень прост, и мы решили попробовать именно его.
Архитектура
Сервера и rsyslogd
Вместе с системными администраторами мы набросали архитектуру, которая показалась нам разумной: ставим один rsyslogd-демон на каждом сервере, один главный rsyslogd-демон на площадку, по одному Logstash на площадку и один кластер Elastic Search поближе к нам, к Москве, т.е. в пражский дата-центр.
В картинках один из серверов выглядел примерно так:
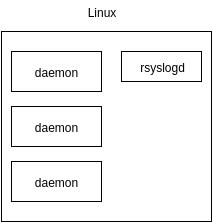
Т.к. в Badoo кое-где используется docker, то мы планировали прокинуть сокет /dev/log внутрь контейнера встроенными средствами.
Итоговая схема была примерно такая:
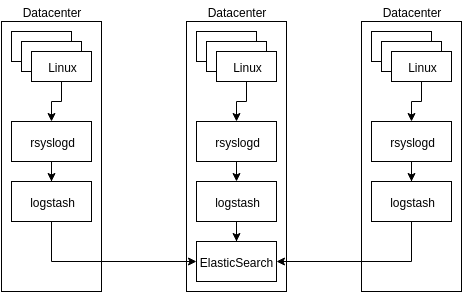
Придуманная выше схема выглядела для начала достаточно устойчивой к потере данных: каждый из rsyslogd-демонов, при невозможности передавать сообщения дальше, сохранит их на диск и отправит тогда, когда это «дальше» заработает.
Единственная потеря данных была возможна в случае, если бы не работал самый первый rsyslog-демон. Но мы не стали в тот момент уделять слишком много внимания этой проблеме. Все-таки логи — не настолько важная информация, чтобы с самого начала тратить на это много времени.
Формат строчки лога и Logstash

Logstash — это труба для данных, в которую отправляются строчки. Внутри они парсятся и уходят в Elastic Search в виде готовых для индексирования полей и тегов.
Практически все наши сервисы построены с использованием собственной библиотеки libangel, а это значит, что формат логов у них одинаковый и выглядит следующим образом:
Mar 04 04:00:14.609331 [NOTICE] <shard6> <16367> storage_file.c:1212 storage___update_dump_data(): starting dump (threaded, update) Формат состоит из общей части, которая неизменна, и части, которую программист задает сам, когда вызывает одну из функций для логирования.
В общей части мы видим дату, время с микросекундами, уровень лога, метку, PID, имя файла и номер строки в исходниках, имя функции. Самые обычные вещи.
Syslog к этому сообщению добавляет информацию от себя: время, PID, hostname сервера и так называемый ident. Обычно это просто название программы, но туда можно передать все что угодно.
Мы этот ident стандартизовали и передаем туда имя, вторичное имя и версию демона. К примеру meetmaker-ru.mlan-1.0.0. Таким образом мы можем отличить логи от разных демонов, от разных типов одного демона (например, страна, реплика) и иметь информацию о запущенной версии демона.
Разбор такого сообщения довольно прямолинеен. Я не буду в статье приводить куски из конфигурационного файла, но все сводится с постепенному «выкусыванию» и парсингу частей строки с использованием обычных регулярных выражений.
Если какой-то этап парсинга был неуспешен, мы добавляем к сообщению специальный тег, который в дальнейшем позволяет находить такие сообщения и мониторить их количество.
Упомяну про разбор времени. Мы постарались учесть разные варианты, и временем сообщения по умолчанию будет время из libangel-сообщения, т.е. по сути время, когда это сообщение было сгенерировано. Если по какой-то причине это время не было найдено, мы возьмем время от syslog, т.е. время, когда сообщение ушло в первый локальный syslog-демон. Если по какой-то причине и это время недоступно, временем сообщения будет время приема этого сообщения в Logstash.
Получившиеся поля идут в Elastic Search для индексации.
{kind=link}
ElasticSearch
Elastic Search поддерживает работу в режиме кластера, когда несколько узлов объединяются в одну сеть и работают сообща. За счет того, что можно для каждого из индексов настроить репликацию на другой узел, кластер сохраняет работоспособность в случае выхода из строя некоторых узлов.
Минимальное количество узлов в отказоустойчивом кластере — три, первое нечетное число, которое больше единицы. Это связано с тем, что для работы внутренних алгоритмов необходимо, чтобы при разбиении кластера на части возможно было выделить большинство. Четное количество узлов для этого не подходит.
Мы выделили три сервера для кластера Elastic Search и настроили его так, чтобы каждый индекс имел одну реплику, как на схеме.
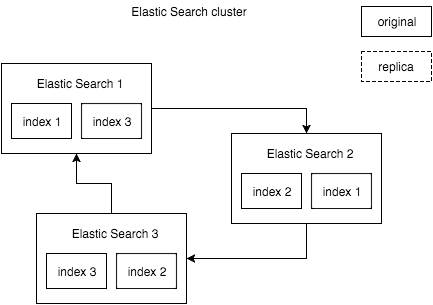
В такой архитектуре выход из строя любого из узлов кластера не фатален и не приводит к недоступности кластера.
Кроме собственно отказоустойчивости, при такой схеме удобно делать обновление самого Elastic Search: останавливаем один из узлов, обновляем его, запускаем, обновляем другой.
То, что мы храним в Elastic Search именно логи, позволяет нам легко поделить все данные на индексы по дням. Такое разбиение дает несколько преимуществ:
- в случае, если на серверах кончается место на диске, очень легко удалить старые данные. Это быстрая операция, и более того, для удаления старых данных есть готовый инструмент Curator;
- во время поиска в интервале больше одного дня поиск можно вести параллельно. Более того, его можно вести параллельно как на одном сервере, так и на нескольких.
Как уже было сказано, мы настроили Curator, чтобы автоматически удалять старые индексы при нехватке места на диске.
В настройке Elastic Search много тонкостей, связанных как с Java, так и просто с тем, что внутри используется Lucene. Но все эти тонкости описаны и в официальной документации, и в многочисленных статьях, поэтому я не буду углубляться. Кратко только упомяну, что на сервере Elastic Search нужно не забыть выделить память как под Java Heap, так и вне Heap (ее будет использовать Lucene), а также прописать «маппинги» конкретно для ваших полей в индексах, чтобы ускорить работу и уменьшить потребление места на диске.
Kibana
Тут говорить вообще не о чем 🙂 Поставили и работает. К счастью, в последней версии разработчики добавили возможность менять часовой пояс в настройках. Раньше по умолчанию брался локальный часовой пояс пользователя, что очень неудобно, т.к. у нас на серверах везде и всегда UTC, и мы привыкли общаться именно по нему.
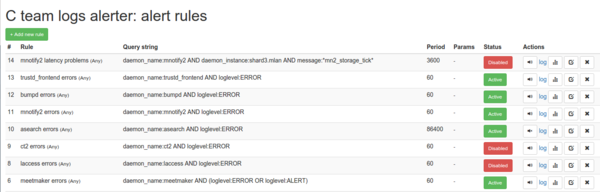
Система уведомлений
Очень важной частью системы сбора логов и одним из основных требований было наличие системы уведомлений. Системы, которая на основе правил или фильтров рассылала бы письма, уведомляющие о срабатывании правила со ссылкой на страницу, где можно посмотреть подробности.
В мире ELK нашлись два похожих готовых продукта:
- Watcher от самой компании Elastic;
- Elastalert от Yelp.
Watcher — закрытый продукт от компании Elastic, требующий активную подписку. Elastalert — продукт open source, написаный на Python. Watcher мы отмели почти сразу по той же причине, что и раньше — закрытость и сложность расширения и адаптации под нас. Elastalert же по тестам показал себя классным продуктом, но и в нем было несколько минусов (впрочем, не очень критичных):
- он написан на Python. Мы любим Python в качестве языка для написания быстрых «наколеночных» скриптов, но не очень хотим его видеть на продакшене в качестве конечного продукта;
- возможности построения писем, которые система посылает в ответ на событие, совсем рудиментарны. А красота и удобство письма — это очень важно, если мы хотим, чтобы у других было желание пользоваться системой.
Поигравшись с Еlastalert и изучив его исходный код, мы решили написать продукт на PHP силами отдела платформы. В итоге Денис Карасик Battlecat за 2 недели написал «заточенный» под нас продукт: он интегрирован в backoffice и имеет только нужный функционал.
{kind=link}
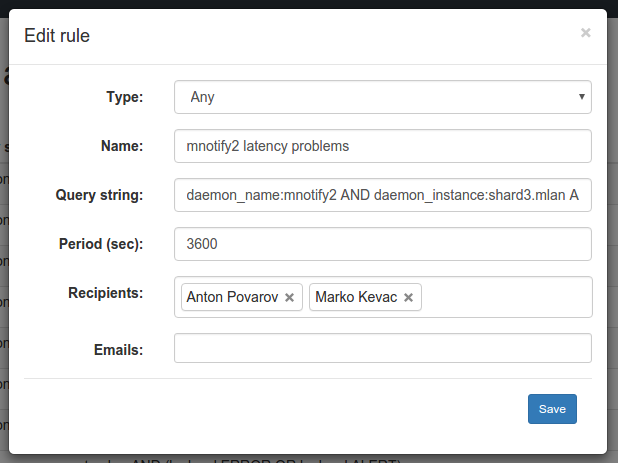{kind=link}
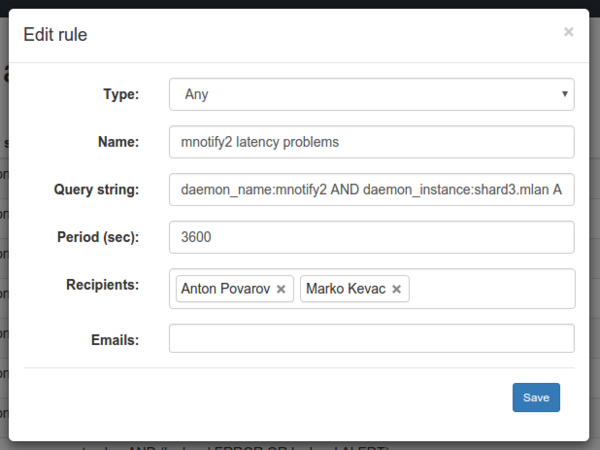
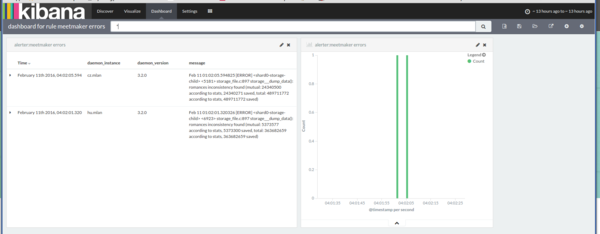
Для каждого правила система автоматически создает базовый dashboard в Kibana, ссылка на который будет в письме. При нажатии на ссылку вы увидите сообщения и график ровно за указанный в уведомлении промежуток времени.
{kind=link}
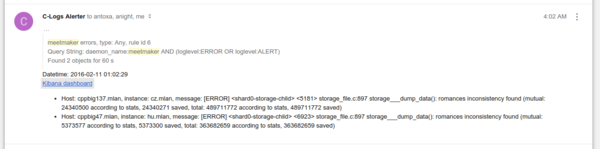
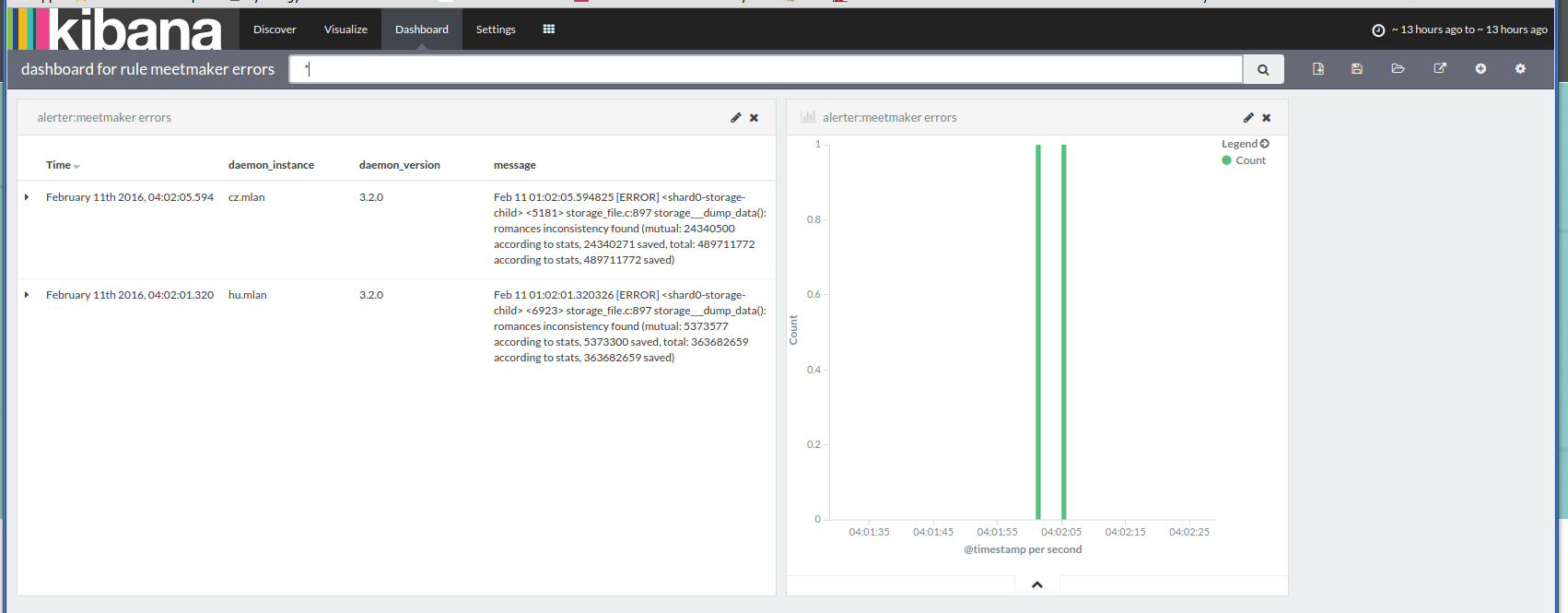{kind=link}
«Грабли»
На этом этапе первый релиз системы был готов, работал и им можно было пользоваться. Но, как мы обещали, «грабли» не заставили себя ждать.
Проблема 1 (syslog + docker)
Стандартный способ общения между syslog-демоном и программой является unix socket /dev/log. Как говорилось выше, мы его пробросили внутрь контейнера стандартными средствами docker. Эта связка отлично работала до тех пор, пока нам не понадобилось перегрузить syslog-демон.
Судя по всему, если перебрасывается конкретный файл, а не директория, то при удалении или пересоздании файла на хост-системе он уже не будет доступен внутри контейнера. Получается, что любая перезагрузка syslog-демона ведет к прекращению заливки логов из docker-контейнеров.
Если пробрасывать директорию целиком, то внутри без проблем может быть unix-сокет, и перезагрузка демона не нарушит ничего. Но тогда усложняется настройка всего этого богатства, ведь libc ожидает, что сокет находится в /dev/log.
Второй вариант, который мы рассматривали — использовать UDP или TCP для отправки логов наружу. Но тут такая же проблема, как и в предыдущем случае: libc умеет писать только в /dev/log. Нам бы пришлось писать свой syslog-клиент, а на данном этапе не хотелось этого делать.
В конце концов мы решили запустить по одному syslog-демону в каждом контейнере и продолжать писать в /dev/log стандартными libc функциями openlog()/syslog().
Это не было большой проблемой, т.к. наши системные администраторы все равно в каждом контейнере используют init-систему, а не запускают только один демон.
Проблема 2 (блокирующий syslog)
На devel-кластере мы заметили, что один из демонов периодически зависает. Включив внутренний watchdog демона, мы получили несколько backtrace, которые показывали, что демон зависает в syslog() -> write().
==== WATCHDOG ==== tag: IPC_SNAPSHOT_SYNC_STATE start: 3991952 sec 50629335 nsec now: 3991953 sec 50661797 nsec Backtrace: /lib64/libc.so.6(__send+0x79)[0x7f3163516069] /lib64/libc.so.6(__vsyslog_chk+0x3ba)[0x7f3163510b8a] /lib64/libc.so.6(syslog+0x8f)[0x7f3163510d8f] /local/meetmaker/bin/meetmaker-3.1.0_2782 | shard1: running(zlog1+0x225)[0x519bc5] /local/meetmaker/bin/meetmaker-3.1.0_2782 | shard1: running[0x47bf7f] /local/meetmaker/bin/meetmaker-3.1.0_2782 | shard1: running(storage_save_sync_done+0x68)[0x47dce8] /local/meetmaker/bin/meetmaker-3.1.0_2782 | shard1: running(ipc_game_loop+0x7f9)[0x4ee159] /local/meetmaker/bin/meetmaker-3.1.0_2782 | shard1: running(game+0x25b)[0x4efeab] /local/meetmaker/bin/meetmaker-3.1.0_2782 | shard1: running(service_late_init+0x193)[0x48f8f3] /local/meetmaker/bin/meetmaker-3.1.0_2782 | shard1: running(main+0x40a)[0x4743ea] /lib64/libc.so.6(__libc_start_main+0xf5)[0x7f3163451b05] /local/meetmaker/bin/meetmaker-3.1.0_2782 | shard1: running[0x4751e1] ==== WATCHDOG ==== Быстренько скачав исходники libc и посмотрев на реализацию syslog-клиента, мы поняли, что функция syslog() синхронна и любые задержки на стороне rsyslog скажутся на демонах.
Что-то с этим нужно было делать, и чем скорее, тем лучше. Но мы не успели…
Через пару дней мы наступили на самые неприятные грабли современных архитектур — каскадный отказ.

Rsyslog по умолчанию настроен так, что если внутренняя очередь по какой-то причине заполняется, он начинает «троттлить» (англ. throttle), т.е. тормозить «запись в себя» новых сообщений.
У нас получилось так, что по недосмотру программиста один из тестовых серверов начал посылать в лог огромное количество сообщений. Logstash не справлялся с таким потоком, очередь главного rsyslog переполнилась и он очень медленно вычитывал сообщения от других rsyslog. Из-за этого очереди других rsyslog тоже переполнились и они очень медленно вычитывали сообщения от демонов.
А демоны, как я говорил выше, пишут в /dev/log синхронно и без какого-либо таймаута.
Результат предсказуем: из-за одного флудящего тестового демона тормозить начали все демоны, которые пишут в syslog хоть с какой-то значимой частотой.
Еще одной ошибкой стало то, что мы не сказали о потенциальной проблеме системным администраторам, и на то чтобы, выяснить причину и отключить rsyslog, ушло больше часа.
Не мы одни наступали на эти грабли, оказывается. И даже не только с rsyslog. Синхронные вызовы в event loop демона — непозволительная роскошь.
Перед нами было несколько вариантов:
- уходить от syslog. Возвращаться к одному из других вариантов, которые предполагают, что демон пишет на диск, а уже какой-то другой демон абсолютно независимо читает с диска;
- продолжать писать в syslog синхронно, но в отдельном треде;
- написать свой syslog-клиент и посылать данные в syslog по UDP.
Самым правильным вариантом, пожалуй, является первый. Но мы не хотели тратить время на него и быстро сделали третий, т.е. начали писать в syslog по UDP.
Что же касается Logstash, то все проблемы решили два параметра запуска: увеличение количества обработчиков и количества одновременно обрабатываемых строк (-w 24 -b 1250).
Планы на будущее
В ближайших планах сделать dashboard для наших демонов. Такой dashboard, который объединит в себе уже существующие и некоторые новые возможности:
- просмотр работоспособности демона («светофор»), его базовой статистики;
- графики количества строчек ERROR и WARNING в логах, их просмотр;
- сработавшие правила системы оповещений;
- SLA-мониторинг (мониторинг latency-ответов) с отображением проблемных сервисов или запросов;
- выделение из логов демона различных этапов. Например, отметка о том, на каком этапе загрузки он находится, время загрузки, длительность каких-то периодичных процессов и т.п.
Наличие такого dashboard, по моему мнению, придется по вкусу и менеджерам, и программистам, и администраторам, и мониторщикам.
Заключение
Мы построили простую систему, которая собирает логи всех наших демонов, позволяет по ним удобно искать, строить графики и визуализации, уведомляет нас о проблемах по почте.
Об успехе системы говорит то, что за время ее существования мы в кратчайшие сроки обнаруживали те проблемы, которые раньше вообще бы не обнаружили или нашли спустя много времени, а также то, что инфраструктуру начинают использовать и другие команды.
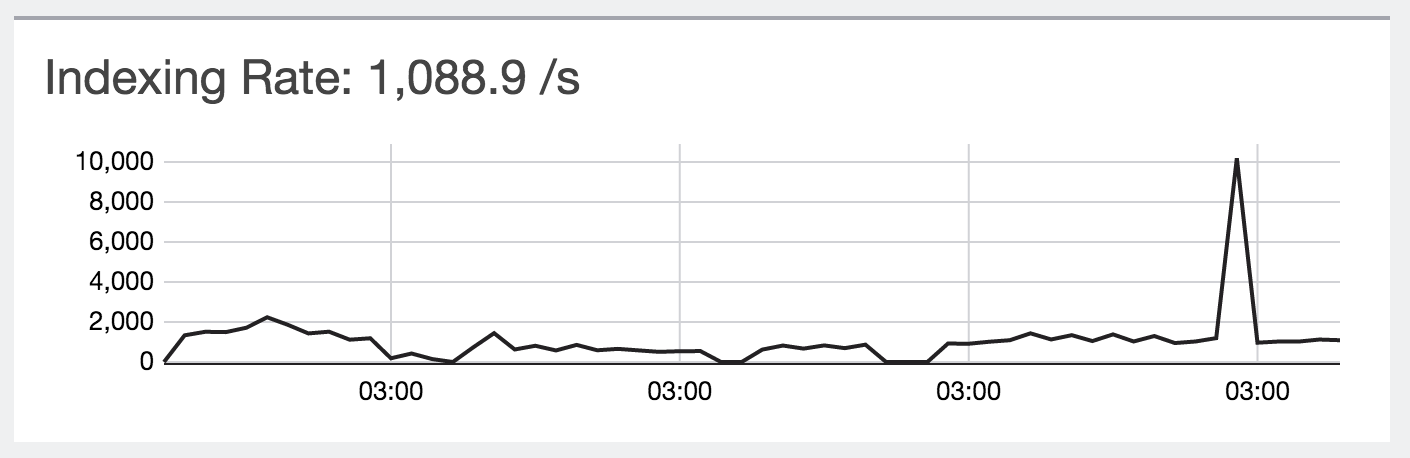
Если говорить о нагрузке, то на данный момент в течение дня приходит от 600 до 2000 строчек с логами в секунду, с периодическими всплесками до 10 тысяч строчек. Данную нагрузку система переваривает без каких-либо проблем.
{kind=link}
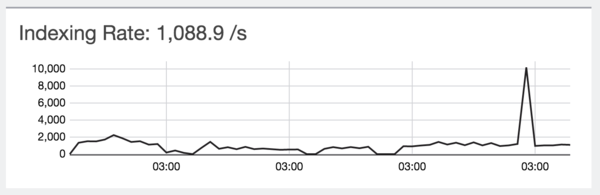
Размер дневного индекса варьируется от десятка до сотни гигабайт.
{kind=link}

Кто-то может сказать, что в этой системе есть недостатки и что некоторые «грабли» можно было бы обойти, сделав что-то иначе. Это правда. Но программируем мы не ради программирования. Наша цель была достигнута за разумно минимальное время и система настолько гибка, что неустраивающие нас в будущем части можно будет довольно легко улучшить или поменять.
Марко Кевац, программист в отделе C/C++ разработки
ссылка на оригинал статьи https://habrahabr.ru/post/280606/
Добавить комментарий