
В предыдущих материалах, раскрывающих главные тезисы цикла статей автора блога Financial Hacker, мы поговорили об использовании неэффективностей рынка на примере истории с ценовым ограничением для швейцарского франка и рассмотрели важные факторы, которые нужно учитывать при создании стратегий для торговли на бирже.
В этот раз речь пойдет об общих принципах разработки модель-ориентированных трейдинговых систем.
Разработка «идеальной» стратегии
Как и во многих других случаях, когда дело касается разработки стратегий для торговли на бирже, есть два пути: идеальный и реальный. Для начала рассмотрим идеальный процесс разработки стратегии.
Шаг 1. Выбор модели
Для начала трейдеру следует выбрать одну из описанных ранее неэффективностей рынка или обнаружить новую. Вполне возможно, что какие-то идеи появятся при анализе ценовой кривой, когда что-либо подозрительное будет отвечать определенной логике рынка. Годится и противоположный вариант – от теории поведенческого паттерна к его проверке на реальных данных. Правда, все закономерности и неэффективности, скорее всего, уже открыты и изучены другими участниками рынка за много лет.
Определившись с моделью, необходимо будет выбрать ценовую аномалию, которая ей соответствует. Затем, описать ее с помощью количественной формулы или, в крайнем случае, посредством качественного критерия. В качестве примера можно использовать циклическую модель из предыдущей статьи:

В нашем случае (Ci) – продолжительность, (Di) — фаза и (ai) – амплитуда. Один из самых успешных фондов в истории — Renaissance Medallion — уверяет, что смог добиться хороших результатов, используя модель циклов вместе со скрытой марковской моделью.
Шаг. 2. Поиски
Нужно также убедиться, что выбранная аномалия действительно проявляет себя в ценовой кривой активов, которыми трейдер собирается торговать. Проверить это можно с помощью исторических данных — D1, M1 и тиковые значения, показывающие распределение аномалии по временной оси. Весь вопрос, насколько глубоко в прошлое нужно копать? Ответ: насколько это возможно. Пока не выяснятся условия возникновения аномалии. Затем придется написать скрипт, который будет находить и демонстрировать аномалию на ценовой кривой. В нашем примере это будет частотный спектр для пары евро/доллар:
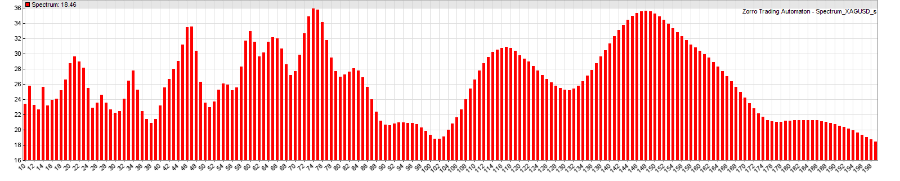
Необходимо выяснить, как меняется спектр за условные промежутки времени – месяцы и годы, а затем сравнить его со спектром случайных данных (в некоторых языках программирования, вроде Zorro, есть специальные функции для рандомизации кривых). Если никаких признаков аномалии и отличий от случайного распределения не обнаружено, трейдеру придется усовершенствовать метод обнаружения аномалии. И если ничего не выйдет – то вернуться к шагу 1.
Шаг 3. Алгоритм
Следующий шаг подразумевает написание алгоритма, который будет генерировать торговые сигналы на открытие и закрытие позиций, следуя выбранной аномалии. В обычной ситуации неэффективность рынка слабо влияет на ценовую кривую. Поэтому алгоритм должен быть настроен достаточно тонко, чтобы отделять проявление аномалии от случайного шума. В то же самое время он должен быть настолько простым, насколько это вообще возможно, и основываться на минимальном числе свободных параметров. В нашем варианте скрипт меняет позицию на каждой впадине и пике синусоиды, которая идет поверх доминирующего цикла:
function run() { vars Price = series(price()); var Phase = DominantPhase(Price,10); vars Signal = series(sin(Phase+PI/4)); if(valley(Signal)) reverseLong(1); else if(peak(Signal)) reverseShort(1); } Это ядро системы. Теперь наступает время для бэктестинга. Точность исполнения задачи в данном случае не так важна, нужно просто определить границы действия алгоритма. Сможет ли он осуществить серию выгодных сделок в конкретных рыночных ситуациях? Если нет, остается два варианта: переписать или создать заново, используя другой метод. На данном этапе не нужно пичкать алгоритм трейлинг-стопами и прочей начинкой. Они исказят результат и создадут иллюзию выгоды на пустом месте. Алгоритм должен научиться просто получать прибыль хотя бы в случае закрытия позиций по времени.
На данном этапе также нужно определиться с данными для бэктеста. Для рабочего теста достаточно M1 и тиковых котировок. Суточные данные не годятся. Объем данных зависит от продолжительности аномалии (которая была определена на втором этапе) и ее природы. Обычно, чем длиннее период, тем точнее тест. Не имеет смысла закапываться глубже, чем на 10 лет. По крайней мере, если речь идет о реально существующем поведением рынка — за десяток лет рынок меняется критически. Устаревшие данные дадут неверный результат.
Шаг 4. Фильтр
Ни одна неэффективность не длится вечно. Любой рынок проходит через периоды произвольного поведения котировок. Поэтому для каждой успешной трейдинговой системы критично иметь фильтр, который бы определял наличие или отсутствие неэффективности. Фильтр также важен, как и сигнал, если не еще важнее. Но, по разным причинам, о нем часто забывают. Ниже пример скрипта, устанавливающего фильтр для торговой системы:
function run() { vars Price = series(price()); var Phase = DominantPhase(Price,10); vars Signal = series(sin(Phase+PI/4)); vars Dominant = series(BandPass(Price,rDominantPeriod,1)); var Threshold = 1*PIP; ExitTime = 10*rDominantPeriod; if(Amplitude(Dominant,100) > Threshold) { if(valley(Signal)) reverseLong(1); else if(peak(Signal)) reverseShort(1); } } Здесь применен полосовой фильтр, центрированный по периоду доминантного цикла к ценовой кривой и измеряющий его амплитуду. Если амплитуда превышает установленный предел, то можно быть уверенным, что неэффективность есть, и действовать соответственно. Продолжительность сделки теперь также ограничена максимум 10 циклами, поскольку на втором этапе мы выяснили, что доминантный цикл появляется и исчезает на относительно небольших временных отрезках.
Что здесь может пойти не так? Ошибкой будет добавлять фильтр просто потому, что он улучшает результат теста. Любой фильтр должен иметь за собой рациональное обоснование, отталкиваясь от поведения рынка или сигналов алгоритма.
Шаг 5. Оптимизация параметров
Все параметры системы, так или иначе, влияют на результат. Но лишь несколько из них напрямую определяют точки входа и выхода из позиции, основываясь на ценовой кривой. Необходимо выявить и оптимизировать эти адаптируемые параметры. В нашем примере открытие позиции определяется фазой прогнозирования поведения кривой и порогом, установленным фильтром. Время закрытия сделки определено точкой выхода. Другие параметры, такие как постоянные фильтра DominantPhase и функция BandPass, нужно оптимизировать, поскольку их значения не зависят от ситуации на рынке.
Частенько оптимизацию трактуют неверно. Метод генетической или насильной оптимизации – это попытка найти пик выгоды в многомерном пространстве параметров. В большинстве случаев это не имеет отношения к работе живой системы. Хотя может получиться уникальная комбинация параметров, которая даст отличный результат теста. Даже совсем немного отличающиеся друг от друга исторические периоды дают совершенно разные пики. Вместо того чтобы гоняться за значением максимума прибыли на исторической кривой, оптимизация должна идти следующим путем:
- Она может определять чувствительность системы к значениям параметров. Если система пропускает свои границы при минимальном изменении параметров, лучше вернуться к шагу 3. Если исправить ситуацию не получается – обратно к первому этапу.
- Через оптимизацию можно найти активные точки параметров. Это зона, где параметры наиболее надежны, то есть, где даже небольшое изменение не оказывает существенного эффекта на положительный результат. Это не узкие пики, как можно было бы подумать, а широкие холмы в пространстве параметров.
- Она может адаптировать систему к различным активам и позволить работать с портфелем акций при минимальном изменении параметров.
- Она может увеличить срок службы системы через адаптацию параметров к текущей рыночной ситуации на регулярных интервалах, параллельно с процессом «живой» торговли.
Вот пример скрипта для оптимизации параметров:
function run() { vars Price = series(price()); var Phase = DominantPhase(Price,10); vars Signal = series(sin(Phase+optimize(1,0.7,2)*PI/4)); vars Dominant = series(BandPass(Price,rDominantPeriod,1)); ExitTime = 10*rDominantPeriod; var Threshold = optimize(1,0.7,2)*PIP; if(Amplitude(Dominant,100) > Threshold) { if(valley(Signal)) reverseLong(1); else if(peak(Signal)) reverseShort(1); } } Два оптимизированных вызова используют стартовое значение 1.0 и диапазон (0,7..2,0) для определения активных точек двух основных параметров. На диаграмме коэффициента прибыли эти точки отмечены красными столбцами:
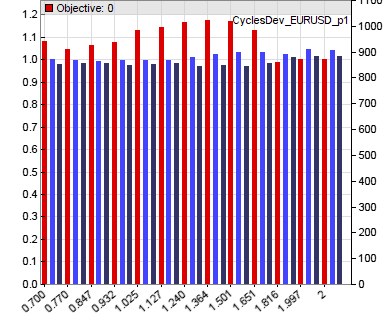
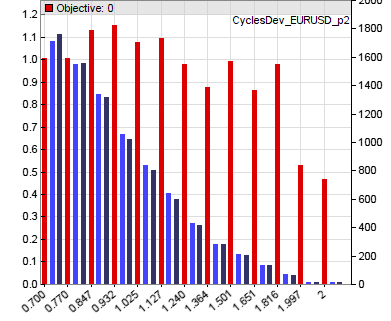
В данном варианте оптимизатор выбирает значение параметра близкое к 1,3 для фазы синусоиды и значение 1,0 (не 0,9 для пика) для амплитуды порога для текущего соотношения в паре евро/доллар. Время выхода здесь не оптимизировано.
Шаг 6. Анализ за пределами выборки
Оптимизация параметров улучшает качество проверочного теста. Но наша система все еще не подогнана к ценовой кривой. Поэтому результаты теста для пока бесполезны. Теперь нужно разделить данные на циклы в выборке и за ее пределами. Выборка используется для обучения системы, анализ за пределами выборки — для тестирования. Стандартный метод для этого – форвардный анализ. Он использует динамичную выборку или скользящее окно для исторических данных для разделения двух циклов.
К сожалению, форвардный анализ добавляет два новых параметра к системе: время обучения и время тестирования. Второе не критично, главное, чтобы оно было сравнительно небольшим. Но вот время обучения имеет значение. Слишком короткое обучение не позволит получить достаточное количество данных по цене для эффективной оптимизации. Слишком длинное также негативно отразится на результате. Рынок может уже «переварить» изменения, пока будет проходить обучение. Поэтому время обучения само по себе нуждается в оптимизации.
Форвардный анализ с шагом в пять циклов (выставим NumWFOCycles = 5 в предыдущем скрипте) снижает производительность бэктеста со 100% годовой выручки к более реалистичным 60%. Для того чтобы избежать слишком оптимистичных результатов и ошибок в анализе, можно запустить его несколько раз с немного различающимися между собой условиями симуляции. Если система имеет свой предел, результаты не должны слишком разниться. В ином случае потребуется вернуться к шагу 3.
Шаг 7. Испытание реальностью
Даже пройдя стадию анализа за пределами выборки, мы все еще имеем некие искажение результата. Вызваны ли они ограничением самой системы или недостатками в процессе разработки (выбора актива, алгоритма, времени проверки и так далее)? Выяснить это – самая сложная часть в работе над трейдинговой стратегией.
Оптимальный вариант – использовать для этого метод под названием Тестирование реальности по методу Уайта (White’s Reality Check). Он же и наименее практичный, так как требует строгого порядка при выборе параметров и алгоритма. Два других метода не так хороши, но более удобны в применении:
- Монте-Карло. Предполагает рандомизацию ценовой кривой с помощью перетасовывания данных без их изменения. Затем необходимо провести обучение системы и протестировать ее снова, а потом проделать все еще раз и сгенерировать распределение результатов. Рандомизация удалит все ценовые аномалии. Но если результат реальной ценовой кривой окажется не так далеко от пика случайного распределения, он вероятно также вызван случайностью. Что это значит? Нужно вернуться к шагу 3.
- Варианты. Этот метод является противоположностью предыдущего. Он приспосабливает обучающуюся систему к разным вариантам ценовой кривой, чтобы получить положительный результат. Варианты, поддерживающие большинство аномалий, относятся к дискретизации с повышенной частотой, устраняют влияние тренда или инвертируют ценовую кривую. Если система остается в выигрыше с такими вариантами, но не со случайными ценами, вы действительно подобрали нечто стоящее.
- ROOS-тест (Really-out-of-sample). Подразумевает полное исключение в процессе разработки данных за последний год (в примере — 2015-й) вплоть до удаления данных о движении цен с компьютера. И только, когда система будет полностью завершена, нужно загрузить данные за этот год и запустить тест. Здесь потребуется собрать всю волю в кулак, чтобы не стать переделывать систему, если она на этом последнем тесте не покажет желаемых результатов. Нужно просто отложить ее в сторону и вернуться к шагу 1.
Шаг 8. Управление рисками
Итак, система пережила все проверки. Теперь можно сконцентрировать усилия на снижении рисков и повышении ее производительности. Больше не нужно возвращаться к входным данным алгоритма и его параметрам. Нужно оптимизировать то, что будет получено на выходе. Вместо простого ограничение по времени и отмены для выхода можно использовать механизмы различных трейлинг-стопов. Например:
- Вместо выхода после заданного промежутка времени, нужно установить стоп-лосс на значение потери для каждого часа. Эффект будет схожим, но теперь закрытие неудачных сделок будет происходить быстрее, а удачных позже.
- Следует разместить стоп-лосс при достижении определенного значения профита над точкой отката значений. Даже если фиксация процента прибыли не улучшит общую производительность, это все равно будет полезно.
Вот пример скрипта, устанавливающий стоп-лоссы:
function run() { vars Price = series(price()); var Phase = DominantPhase(Price,10); vars Signal = series(sin(Phase+optimize(1,0.7,2)*PI/4)); vars Dominant = series(BandPass(Price,rDominantPeriod,1)); var Threshold = optimize(1,0.7,2)*PIP; Stop = ATR(100); for(open_trades) TradeStopLimit -= TradeStopDiff/(10*rDominantPeriod); if(Amplitude(Dominant,100) > Threshold) { if(valley(Signal)) reverseLong(1); else if(peak(Signal)) reverseShort(1); } } Разумеется, теперь придется еще раз пройти процесс оптимизации и форвардный анализ для параметров выхода.
Шаг 9. Распределение денежных средств
Процесс управления средствами преследует три цели. Во-первых, реинвестирвоать доходы. Во-вторых, грамотно распределить капитал внутри портфеля. В-третьих, вовремя понять, что торговый портфель бесполезен. В любом учебнике по трейдингу можно найти совет инвестировать 1% суммарного капитала за сделку. Эти вещи пишут люди, не заработавшие ни цента в реальной торговле.
Обозначим объем инвестиций за фиксированное время чрез V(t). Если система приносит доход, в среднем капитал C будет пропорционально расти с коэффициентом с.
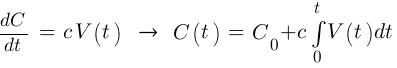
Если следовать советам авторов умных книг и инвестировать фиксированный процент p от капитала, V(t) = p C(t), то капитал должен расти по экспоненте p c.
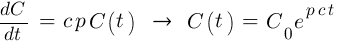
К несчастью, в это же время капитал будет испытывать на себе влияние случайных колебаний. Такие просадки будут пропорциональны торгуемому объему средств V(t). Это можно рассчитать с помощью формулы, где максимальная глубина просадки Dmax будет увеличиваться пропорционально квадратному корню от t.
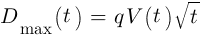
Таким образом, при фиксированном значении инвестирования получаем:

И время в данном случае T = 1/(q p)2
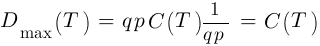
Из этих расчетов можно видеть, как за период T просадка съест все деньги на счету. Не имеет значения, насколько хороша сама торговая система, и какой процент инвестирования выставил трейдер. Поэтому совет «вкладывать за раз 1%» — плохой совет. Вот почему автор блога Financial Hacker советует своим клиентам не поднимать торговый объем пропорционально к аккумулированной прибыли, но делать это на квадратный корень. Пока сама стратегия не исчерпает себя, это будет держать трейдера на безопасном расстоянии от маржин-колла.
В зависимости от того, работает ли трейдер с одним активом и одним алгоритмом или с их наборами, оптимальный объем инвестиций можно вычислить несколькими методами. Например, по формуле OptimalF Ральфа Винса или по формуле Келли от Эда Торпа. В большинстве случаев логично уйти от тяжеловесного кода для реализации процесса реинвестирования, поэтому объем инвестиций можно рассчитать и за пределами алгоритма. Особенно, если трейдер собирается снимать или класть деньги на счет время от времени. Удобную формулу для таких вещей можно найти в мануале для языка Zorro.
Шаг 10. Подготовка к реальной торговле
Пришло время определиться с пользовательским интерфейсом для трейдинговой системы. Для этого необходимо понять, какие параметры нужно будет менять в режиме реального времени, а какие останутся постоянными. Далее следует приспособить к ней метод управления торговым объемом и реализовать «тревожную кнопку» для фиксирования прибыли и выхода в кэш при появлении плохих новостей. Необходимо отобразить все существенные параметры трейдинга в реальном времени, добавить возможности для переобучения системы и включить в нее метод сверки реальных результатов с результатами бэктеста. Трейдер должна убедиться, что сможет контролировать систему из любой точки пространства и времени. Это не означает, что ее нужно проверять каждые пять минут. Но иметь возможность за обедом взглянуть на результаты торговли с помощью мобильного телефона никогда не повредит.
Как все часто происходит в реальности
Выше мы описали разработку идеальной стратегии. Все это выглядит симпатично. Но как разработать реальную стратегию трейдинга? Понятно, что между теорией и практикой лежит пропасть — что, конечно, неправильно.
Вот как часто выглядит последовательность шагов по созданию стратегии работы на бирже, которую проделывают сотни и тысячи трейдеров:
Шаг 1. Зайти на форум трейдеров и получить подсказку о новом крутом индикаторе, который приносит баснословную выручку.
Шаг 2. Помучаться с кодом системы тестов, чтобы убедиться, что индикатор работает. Результаты бэктеста не впечатляют? В код закралась ошибка. Нужно сделать отладку, стараться еще лучше.
Шаг 3. Все еще нет результата, но трейдер уже осознает, что освоил и несколько полезных ходов. Можно еще добавить трейлинг-стоп. Теперь все выглядит немного лучше. Пора запускать недельный анализ. Вторник выпадает из стратегии? Нужно добавить фильтр, который пропускает торговлю по вторникам. Вписать еще несколько фильтров, которые блокируют открытие позиций между 10 и 12 утра, в случае, если котировка меньше $14,5, и в период полной луны. Следует подождать, пока моделирование завершится. Отлично, результаты бэктеста теперь хороши!
Шаг 4. Разумеется, никто не ведется просто на результат выборки. После оптимизации всех 23 параметров, трейдер запускает форвардный анализ. Ждет. Не нравится результат? Он пробует разные циклы этого анализа, разные периоды. Еще ждет. Наконец, нужные значения появятся.
Шаг 5. Система запускается в ходе реальных торгов.
Шаг 6. Итог не выглядит впечатляющим.
Шаг 7. После фиаско остается только ждать, пока банковский счет придет в себя. Некоторые трейдеры в такие периоды занимаются написаниями книг по торговле на бирже.
В следующем материале мы рассмотрим подход использования техники data mining в сочетании с машинным обучением для обнаружения паттернов с помощью различных алгоритмов и нейронных сетей.
ссылка на оригинал статьи https://habrahabr.ru/post/281148/
Добавить комментарий