
В нашем блоге на Хабре мы рассказываем не только про технологические аспекты работы облачного сервиса 1cloud, но и затрагиваем вопросы огранизации работы тех. поддержки.
Сегодня мы решили разнообразить пятничную ленту Хабра разбором материалов по теме устройства сервиса Netflix, поставляющего зрителям фильмы и сериалы на основе технологий потокового мультимедиа.
Компания Netflix была основана в 1997 году Марком Рэндольфом (Marc Randolph) и Ридом Гастингсом (Reed Hastings) в Скотс-Вэлли, штат Калифорния. Поначалу в ней работали 30 сотрудников, занимавшихся предоставлением 925 фильмов и сериалов по подписке. Сегодня Netflix является ведущей мировой сетью интернет-телевидения, обслуживающей десятки миллионов клиентов.
Компания достаточно активно выкладывает в Сеть информацию о применяемых технологиях, инфраструктуре и необычных решениях. Например, в своем блоге сотрудники Netflix рассказали о том, что компания делает, чтобы предоставляемый контент всегда был качественным. Для этого ими была разработана целая методология. Сеть доставки контента (CDN) компании учитывает то, какими устройствами пользуются ее клиенты, и поддерживает широкий диапазон интернет-соединений – от мобильного интернета со скоростью менее 0,5 Мб/с до высокоскоростного интернета (более 100 Мб/с).
Netflix использует технологию адаптивного стриминга, которая регулирует качество аудио и видео в соответствии со скоростью интернета пользователя, но компания также предоставляет клиентам возможность установить качество видео самостоятельно. Большое число комбинаций кодеков и значений битрейта в Netflix подразумевает «обязательность кодирования одного фильма 120 различными способами перед его передачей на любую стриминговую платформу».
Весь процесс кодирования видео осуществляется в облаке, что дает компании большие возможности по масштабированию: если резко возникает необходимость в обработке большего количества фильмов, то облачные технологии позволяют без труда задействовать дополнительные ресурсы. Справедливо и обратное – если нужно, объем вычислительных мощностей можно и уменьшить.
Задачи по обработке длинных видеозаписей разбиваются на более мелкие и выполняются параллельно. Это позволяет значительно сократить время на их выполнение. На рисунке ниже показана схема всего процесса. После получения исходников видео кодируется в разных форматах и в разном качестве и только потом попадает в CDN.
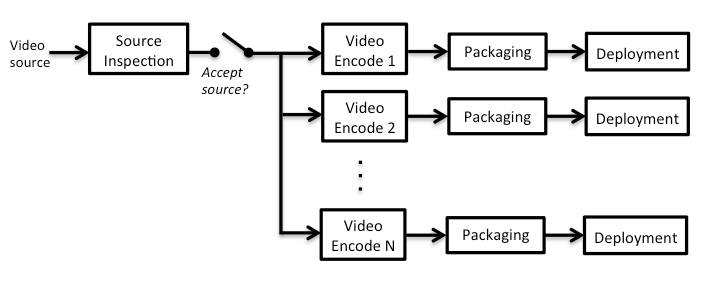
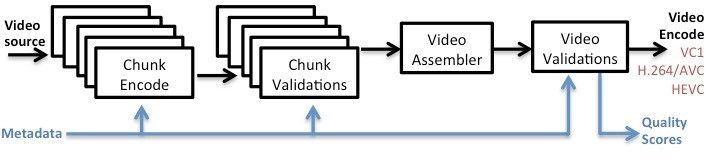
Netflix получает исходные файлы с видеоматериалами из собственной киностудии или от своих партнеров, но это не исключает вероятность того, что часть полученных файлов будет иметь дефекты, возникшие в процессе хранения или многократной обработки данных. По этой причине на начальном этапе проверяется, соответствуют ли исходники необходимым требованиям: так выявляется контент, который может вызвать негативные впечатления от просмотра.
Если исходный файл не удовлетворяет требованиям, система автоматически уведомляет партнеров компании о проблеме и запрашивает новый исходник. Если все в порядке, к файлу прикрепляются метаданные для кодирования. Чтобы повысить эффективность работы с крупными файлами (например, видео с разрешением 4K), их фрагментируют – файл условно разбивается на небольшие части, проверка которых осуществляется параллельно.
В ходе проверки выявляются ошибки и формируются метаданные, содержащие временные характеристики фрагмента. По завершению анализа все кусочки собираются в специальном агрегаторе, который принимает решение о том, стоит ли передавать файл на следующий этап производственного процесса. Как результат, видео с разрешением 4K проверяется на наличие дефектов менее чем за 15 минут.

Что касается кодирования видеофайла, то оно так же, как в случае с проверкой качества, осуществляется параллельно. После успешной обработки фрагментов специальная программа собирает все части в единое целое.
До применения методик параллельной обработки система обрабатывала фильм с разрешением 1080p в течение нескольких дней. Сегодня этот же фильм можно полностью проверить и закодировать в различных форматах всего за несколько часов.
До того как в систему Netflix был интегрирован контроль качества, все ошибки «всплывали», когда клиенты обращались в службу технической поддержки. Чаще всего пользователи были сильно недовольны, а это сказывалось на финансовом положении компании. После введения системы контроля качества команда Netflix стала своевременно выявлять все ошибки, а надежность кодирования исходника, прошедшего проверку, сегодня составляет более 99,99%. Если компания сталкивается с проблемой, которую не удалось выявить с помощью алгоритмов автоматизации, сотрудники приступают к разработке новых механизмов проверки, чтобы не допускать подобного в будущем.
На основе своей системы получения и доставки контента Netflix проводит крупномасштабные эксперименты над видеофайлами, к примеру, сравнивая различные типы кодеков и оптимизируя процесс кодирования. По словам сотрудников компании, Netflix решает задачи, необходимые для оптимальной поставки качественных видеопотоков, в то же время принося пользу сообществу.
Сеть доставки контента Netflix Open Connect предоставляет свои услуги более крупным интернет-провайдерам, имеющим более 100 000 клиентов. Специальное встроенное оборудование с низкой мощностью и высокой плотностью записи за определенную плату может передать с сайта Netflix контент, хранящийся в дата-центах интернет-провайдеров, тем самым сокращая затраты на передачу данных из Сети. Это оборудование работает на операционной системе FreeBSD, используя сервер nginx и службу маршрутизации BIRD.
Мониторинг неисправных серверов
На данный момент сервис Netflix работает на нескольких десятках тысяч серверов, и менее одного процента из них работают неисправно. Неисправный сервер необязательно отключен, и в этом заключается основная опасность: он отвечает на запросы во время проверок работоспособности, а его системные метрики остаются в пределах нормы, однако функционирует он на уровне далеком от оптимального.
Медленный или неисправный сервер гораздо хуже неработоспособного. Даже малого негативного воздействия может быть достаточно, чтобы вызывать дискомфорт у клиентов сервиса. По этой причине Netflix занимается вопросами автоматизации поиска неисправных серверов, не выявляемых системами мониторинга.
В представленном ниже видео Коди Риу (Cody Rioux) рассказывает о том, что подтолкнуло компанию заниматься этими проблемами, а также делится техническими подробностями используемых алгоритмов (с примерами).
Компанией широко используется так называемый кластерный анализ, который является методом машинного «обучения без учителя». Выбирая кластерный алгоритм, парни из Netflix остановили свой выбор на алгоритме кластеризации пространственных данных с присутствием шума DBSCAN (Density-Based Spatial Clustering of Applications with Noise).
DBSCAN принимает на входе набор точек и маркирует как точки кластера те из них, которые имеют большое количество соседей. Точки, которые находятся в областях с меньшей плотностью, считаются статистическими выбросами. Если определенная точка принадлежит кластеру, то она должна находиться на определённом расстоянии от других точек этого кластера, которое определяется по специальной функции (Нафтали Харрис (Naftali Harris) в своем блоге привел отличную визуализацию метода DBSCAN).
DBSCAN используется следующим образом: основная платформа динамической телеметрии Atlas отслеживает заданную метрику и формирует окно данных. Затем эти данные передаются алгоритму DBSCAN, который возвращает набор серверов с подозрением на неисправность. На изображении ниже показаны данные, которые поступают на вход алгоритма DBSCAN. Область, выделенная красным – это текущее окно данных.

Когда серверы определены, управление передается системе оповещения, которая предпринимает одно (или несколько) из следующих действий: связаться с владельцем сервиса по email, отключить сервер от сервиса, не останавливая его, собрать экспертные данные для дальнейшего расследования, остановить сервер, позволив заменить его.
Невозможно идеально точно определить неисправные серверы, однако вероятность этого достаточно высока. Неидеальное решение вполне допустимо в облачной среде, так как стоимость ошибки здесь достаточно мала. Поскольку отключаемые серверы сразу же заменяются «свежими», то ошибочная остановка сервера или его отключение оказывает незначительное воздействие на систему, если оказывает вообще.
Облачная инфраструктура Netflix постоянно расширяется, а автоматизирование операционных решений открывает новые возможности, улучшая доступность сервиса и снижая количество ситуаций, когда требуется вмешательство человека. Определение неисправных серверов – это всего лишь один из примеров подобной автоматизации.
Рекомендательные алгоритмы
В 2009 году компания Netflix провела конкурс под названием Netflix Prize. Она открыла доступ к своим личным данным и дала участникам возможность попытаться усовершенствовать алгоритм предсказания оценки, которую зритель поставит фильму, на основе оценок других зрителей. Команде-победителю удалось поднять эффективность алгоритма на 10,06%.
Что касается рекомендательной системы – она состоит из нескольких алгоритмов, часть из которых ответственна за процесс формирования персонализированной домашней страницы. Например, алгоритм предсказания оценки, которую поставит фильму пользователь, алгоритм ранжирования видеозаписей в каждом ряду и алгоритм группировки фильмов.
На данный момент фильмы и шоу на домашней странице Netflix организованы в виде тематических строк (каждая из которых имеет определённое название), а пользователи сервиса могут прокручивать страницу как в горизонтальной, так и вертикальной плоскости. Такой подход дает пользователю возможность быстро для себя решить, стоит ли целая группа фильмов его внимания, или он может перейти к следующей строке.
Для создания персонализированной страницы используется машинное обучение – тренировка алгоритма проходит на основании исторической информации о всех когда-либо созданных домашних страницах и информации о взаимодействии пользователей с ними.
У Netflix имеется достаточно большой выбор признаков, которыми можно представить строку для обучающего алгоритма. Поскольку строка – это набор видео, то можно использовать в качестве признаков все свойства, которыми они обладают как вкупе, так и по отдельности. Это могут быть обычные метаданные или более полезные рекомендации, показывающие насколько та или иная картина будет интересна конкретному пользователю.
Крайне важно при генерации страницы каким-либо алгоритмом оценить её качество. Придумывая метрики оценки, сотрудники Netflix черпали идеи в такой области деятельности, как информационный поиск. Например, компания нашла применение величине, называемой «полнота» (Recall), которая является отношением числа релевантных объектов (фильмов, которые выбрал клиент) в выборке, к общему числу релевантных объектов.
Было принято решение использовать величину Rec[m;n], которая являет собой число релевантных объектов в первых m строках и n колонках на странице, разделенное на общее число релевантных объектов. Таким образом, Rec[3;4] – это качество видеозаписей (для конкретного пользователя), представленных на устройстве, дисплей которого позволяет отобразить всего 3 строки по 4 видео в каждой. Достоинством такой метрики является то, что, зафиксировав одну из величин (m или n) и изменяя другую, можно увидеть, как меняется значение полноты при прокрутке страницы.
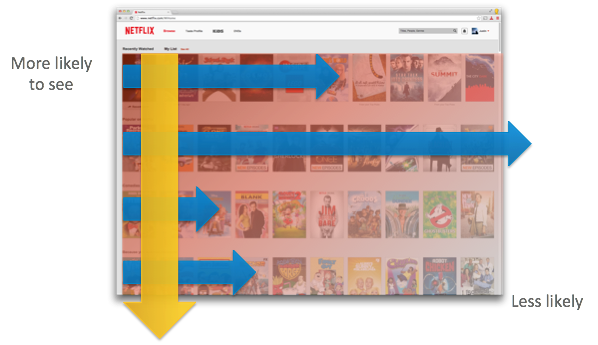
При формировании домашней страницы также очень важно понимать, как пользователи её просматривают, то есть каким точкам на экране они уделяют больше всего внимания. Размещение самых актуальных видео в наиболее часто просматриваемых местах (чаще всего это левый верхний угол экрана) должно помочь сократить время поиска фильма на вечер.
Что же касается разнообразия жанров, то это целая отдельная история. Если вы – пользователь Netflix, то, скорее всего замечали, что бывает вам предлагаются фильмы странных, порой абсурдных, жанров. Документальные драматические фильмы про борцов с системой? Пьеса про королевскую семью, основанная на реальных событиях? Зарубежные истории про сатанистов 80-х?
И вот что интересно, оказывается, Netflix имеет 76897 разных способов описания фильмов. Компания создала специальные команды, члены которых помечали метатегами каждый предложенный им фильм. Этот процесс оказался настолько сложен, что участникам выдали 36-страничное руководство, в котором было расписано, как оценивать фильмы по наличию сексуального содержания, количеству крови, как определить романтичность фильма и оценить уровень актерской игры. Оценивалась даже нравственность персонажей.
Журналист издания The Atlantic Алексис Мадригал (Alexis Madrigal) решил разобраться в ситуации поподробнее и обнаружил, что у Netflix абсурдно большое количество жанров (их количество превышало 90000). Чтобы пролить немного света на ситуацию, Алексис написал скрипт, который «вытянул» все существующие жанры с сайта компании.
«Я сразу обратил внимание, что на сайте есть фильмы не всех представленных жанров», – отмечает Мадригал. – Наличие жанра в базе означает, что, по данным алгоритма, такие фильмы могут появиться позже, или уже есть материалы, которые подпадают под описание, но еще не добавлены на сайт». Например, категория №91300 называлась «Добрые романтические ТВ-шоу на испанском языке» и была пустой, категория №91307 носила заголовок «Красивые латиноамериканские комедии» и содержала два фильма, а в категории №6307 «Красивые романтические драмы» были представлены 20 фильмов.
Однако если постараться проанализировать все жанры, то грамматика Netflix станет достаточно прозрачной. К примеру, информация об «оскораносности» картины всегда записывается вначале: «Оскароносные романтические драмы», но временные периоды всегда следуют в конце: «Оскароносные романтические драмы 50-х годов». Категории, раскрывающие содержание фильма, тоже ставятся ближе к концу: «Оскароносные романтические фильмы о свадьбе».
Оказалось, что для каждого дескриптора существует строгая иерархия. Короче говоря, жанр формируется по установленному паттерну:
Откуда + Прилагательные + Существительное + Основан на … + Снят в … + От режиссера … + О… + Для возрастов от X до Y
Все 76897 жанров, которые нашел бот Мадригала, были созданы из этих основных компонентов. Подробнее о процессе формирования «микрожанров» рассказал вице-президент Netflix Тодд Йеллин. В 2006 году Йеллин с командой инженеров начал работу над документацией, получившей название «Квантовая теория Netflix». В этом контексте квант – это небольшой «пакет энергии» (микро-тег), являющийся частью каждого фильма.
Йеллин сказал, что жанры ограничиваются тремя основными факторами:
- Название жанра не должно превышать 50 знаков из-за особенностей пользовательского интерфейса.
- Чтобы алгоритм сформировал жанр, должна накопиться «критическая масса» контента, который бы подошел под его описание.
- Регистрируемые жанры – синтаксически правильные.
В мире Netflix нет жанров, состоящих из более чем пяти дескрипторов. Четыре дескриптора очень редки, но их можно встретить: «Культовые ужастики про безумных ученых 1970-х годов». Три дескриптора встречаются достаточно часто: «Добрые зарубежные комедии для неисправимых романтиков». Два дескриптора используются очень часто: «Фильмы, насыщенные загадками». Очень часто встречаются одиночные дескрипторы: «Необычные фильмы».
Однако магия Netflix заключается в том, что, оказывается, не все теги были расставлены людьми, часть из них выработана самой системой. Например, прилагательное «ободряющий» прикрепляется к фильмам, которые обладают определенным набором особенностей, наиболее важной среди которых является счастливая концовка. Получается, что «ободряющий» – это не прямой тег, а вычисленная категория, основанная на наборе тегов.
ссылка на оригинал статьи https://habrahabr.ru/post/281228/
Добавить комментарий