Евгений (Джим) Брикман является автором книги «Hello, Startup» («Привет, стартап») и основателем компании «Atomic Squirrel», которая специализируется на помощи стартапам. До этого он больше десяти лет работал в таких компаниях, как Linkedln, TripAdvisor, Cisco Systems, Thomson Financial. Он также имеет степени бакалавра и магистра компьютерных наук Корнелльского университета.
Представьте себе, ваша работа состоит в том, чтобы все автомобили на автостраде ехали быстрее. Что произошло бы, если бы вы просто сказали всем водителям вдавить до упора педаль газа?
Ясно, что результатом была бы катастрофа. И, всё же, это — точно тот тип отношений, который многие разработчики пытаются реализовать, стремясь создать программное обеспечение быстрее. Здесь несколько из причин, почему они делают так:
«Мы пытаемся быть действительно динамичными, поэтому мы не тратим время напрасно на разработку структуры или документации.»
«Я должен отправить это на производство немедленно, поэтому у меня нет времени писать тесты!»
«У нас не было времени автоматизировать что-либо, поэтому мы просто развёртываем наш код вручную.»
Для автомобилей на автостраде вождение с высокой скоростью требует особого внимания к обеспечению безопасности. Чтобы можно было вести автомобиль быстро, на нём должны быть соответствующие устройства, например, тормоза, ремни и подушки безопасности, сберегающие водителя, если что-то пойдёт не так.
Для программного обеспечения динамичность также требует обеспечения безопасности. Есть разница между достижением разумных компромиссов и устремлённостью вперёд вслепую без мыслей об осторожности. Должны быть механизмы обеспечения безопасности, которые минимизируют потери при неблагоприятном развитии событий. Опрометчивый двигается, в конечном счёте, медленнее, а не быстрее:
• Один час, «сэкономленный» на ненаписании тестов, будет стоить вам пяти часов на поиск ошибки, вызывающей сбой на производстве, и ещё пяти часов, если ваша «заплата» породит новую ошибку.
• Вместо того чтобы затратить тридцать минут на написание документации, вы будете по часу учить каждого сотрудника, как использовать вашу программу, и тратить часы на разбирательства, если сотрудники начнут работать с вашим продуктом неправильно.
• Можно сэкономить немного времени, не заботясь об автоматизации, но будет затрачено намного больше времени на повторяющийся ввод кода вручную и ещё больше времени на поиск ошибок, если какой-то этап окажется случайно пропущенным.
Каковы ключевые механизмы обеспечения безопасности в мире программного обеспечения? В этой статье будут представлены три механизма обеспечения безопасности в мире автомобилей и аналогичные механизмы из мира программ.
Тормоза / непрерывная интеграция
Хорошие тормоза останавливают автомобиль до того, как проблема станет действительно серьёзной. В программном обеспечении непрерывная интеграция останавливает неправильную программу до того, как она уйдёт в производство. Чтобы понять термин «непрерывная интеграция», рассмотрим сначала его противоположность: поздняя интеграция.
Рис. 1. Международная космическая станция
Представьте себе, что вы отвечаете за постройку международной космической станции (МКС), состоящей из множества компонентов, как показано на рис. 1. Команды из разных стран должны изготовить тот или иной компонент, и вы решаете, как всё организовать. Есть два варианта:
• Заранее разработать все компоненты, после чего каждая команда уйдёт и будет работать со своим компонентом в полной изоляции. Когда все компоненты будут готовы, вы запустите их все вместе в космос и попытаетесь свести воедино.
• Разработать первоначальную исходную конструкцию для всех компонентов, после чего каждая команда приступит к работе. Каждая команда по мере разработки своего компонента непрерывно тестирует каждый компонент вместе с другими и изменяет подход, структуру, конструкцию, если возникают какие-либо проблемы. Компоненты по готовности уходят поодиночке в космос, где их последовательно собирают.
В варианте №1 попытка в конце собрать всю МКС приведёт к большому количеству конфликтов и конструкторских проблем: выяснится, что немецкая команда, оказывается, думала, что кабельную разводку должны делать французы, тогда как последние были уверены, что это задача англичан; вдруг обнаружится, что все команды использовали метрическую систему измерения, а вот одна — британскую; ни одна команда не посчитала для себя важной операцию установки туалета. Выявление всего этого, когда всё уже изготовлено и летает в космосе, означает, что решение проблем будет очень трудным и дорогим.
К сожалению, именно этот путь многие компании используют при создании программного обеспечения. Разработчики действуют в полной изоляции в течение многих недель или месяцев непрерывно по своим направлениям и затем пытаются свести вместе свои разработки в выходной продукт в самую последнюю минуту. Этот процесс известен как «поздняя интеграция», и он часто приводит к большой потере времени (дни, недели) на устранение конфликтов слияния (см. рис. 2), поиск трудно обнаруживаемых ошибок и попытки застабилизировать выходные (релизные) ветки проекта.
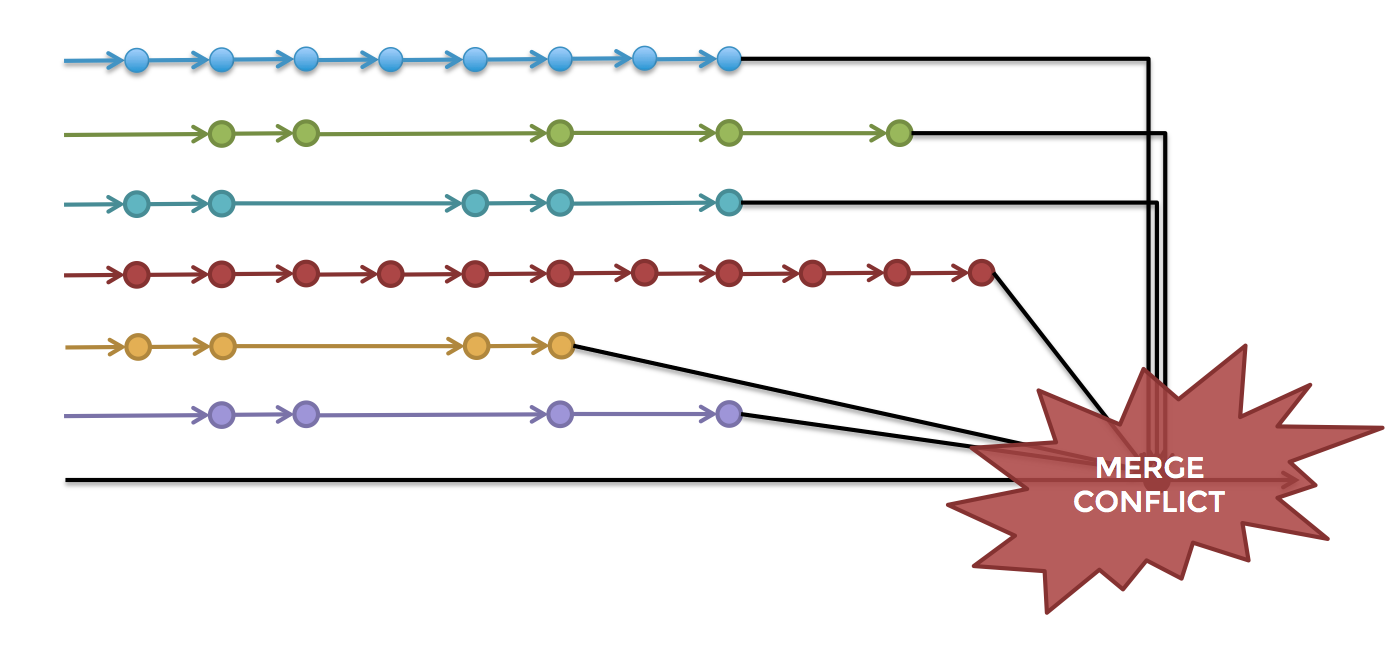
Рис. 2. Сведение вместе функциональных веток в выходную (релизную) ветку проекта приводит к тяжёлым конфликтам слияния
Альтернативным подходом, описанным как вариант №2, является непрерывная интеграция, когда все разработчики регулярно сводят вместе результаты своей работы. Это выявляет проблемы в проекте до того, как разработчики продвинулись слишком далеко в неправильном направлении, и позволяет последовательно наращивать разработку. Наиболее распространённым способом непрерывной интеграции является использование модели «стволовой разработки».
В этой модели разработчики выполняют всю свою работу в одной и той же ветке, называемой «ствол» или «мастер» — в зависимости от системы управления версиями (Version Control System = VCS). Идея в том, что каждый регулярно загружает свой код в эту ветку, возможно даже несколько раз в день. Может ли работа всех разработчиков на одной единственной ветке, действительно, быть ценной? Стволовую разработку используют тысячи программистов на LinkedIn, Facebook и Google. Особенно впечатляет стволовая («транковая») статистика Гугла: каждый день на одной единственной ветке они координируют более чем 2 миллиарда строк кода и более 45 тысяч операций подтверждения.

Рис. 3. В стволовой разработке каждый загружает свой код в одной и той же ветке.
Как тысячи разработчиков могут часто загружать свои коды в одну и ту же ветку без конфликтов? Оказывается, что при частом выполнении небольших операций подтверждения вместо выполнения огромных монолитных слияний число конфликтов довольно мало, а возникающие конфликты являются желательными. Это связано с тем, что конфликты неизбежно будут существовать независимо от используемой стратегии интеграции, но легче разрешить конфликт, представляющий один-два дня работы (при непрерывной интеграции), чем конфликт, представляющий месяцы работы (при поздней интеграции).
А как обстоит дело со стабильностью ветки? Если все разработчики работают в одной и той же ветке и какой-либо разработчик загружает код, который не компилируется или вызывает серьёзные ошибки, то может быть заблокирован весь процесс. Чтобы предотвратить это, необходимо иметь самотестируемую компоновку. Самотестируемая компоновка является полностью автоматизированным процессом (т.е. её можно запустить одной командой), содержащим достаточное количество автоматизированных тестов; если все они проходят, то можно быть уверенным в стабильности кода. Обычный подход состоит в добавлении перехватчика операции подтверждения к вашей системе контроля версий (VCS), который принимает каждую такую операцию, проводит её через компоновку на каком-то сервере непрерывной интеграции (CI), таком как, например, Jenkins или Travis, и отвергает, если компоновка не проходит. Сервер CI является контролёром, проверяя каждую партию кода прежде, чем разрешить её загрузку в ствол; он действует как хороший тормоз, останавливающий плохой код до его ухода в производство.
Без непрерывной интеграции ваше программное обеспечение считается неработающим, пока кто-то не покажет, что оно работает, — это происходит обычно на этапе тестирования или интеграции. При непрерывной интеграции считается, что ваше программное обеспечение работает (если, конечно, имеется достаточно комплексный набор автоматизированных тестов) при каждом новом изменении — и разработчик знает момент, когда происходит нарушение, будучи в состоянии немедленно устранить ошибку.
— Джез Хамбли и Дэвид Фарли, авторы книги «Continuous Delivery» («Непрерывная поставка ПО»)
Как можно использовать непрерывную интеграцию, чтобы вносить большие изменения? Т.е., если вы работаете над характеристикой, которая требует недели, как можно осуществлять загрузку в ствол несколько раз в день? Одним из решений является использование выключателей характеристик (feature toggles).
Предохранительные защёлки / Выключатели характеристик
В начале 19-го века большинство людей избегало лифтов, опасаясь, что, если трос оборвётся, то пассажиры лифта погибнут. Чтобы решить проблему, Элиша Отис изобрёл «безопасный лифт» и провёл смелую демонстрацию его эффективности. Для этого Отис построил большую открытую шахту лифта, поднял открытый лифт на несколько этажей и перед собравшимися приказал помощнику обрезать трос, как показано на рис. 4. Лифт начал было падать, но сразу же был остановлен.

Рис. 4. Элиша Отис демонстрирует «безопасный лифт».
Как это работает? Ключевым элементом безопасного лифта является предохранительная защёлка, показанная на рис. 5. В исходном положении предохранительные защёлки полностью выдвинуты так, что они входят в фиксаторы на шахте лифта и не позволяют лифту двигаться. Только когда трос лифта достаточно натянут, предохранительные защёлки выходят из зацепления. Другими словами, защёлки находятся во втянутом состоянии только при неповреждённом тросе.
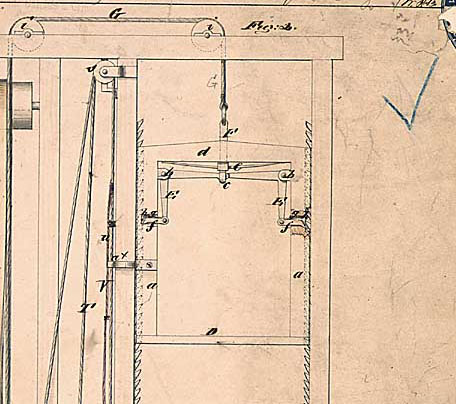
Рис. 5. Рисунок из патента по безопасному лифту показывает шахту лифта с лифтом посередине (D), с предохранительными защёлками по бокам (f) и тросом наверху (G).
В этой великолепной конструкции предохранительные защёлки обеспечивают безопасность по умолчанию. В программном обеспечении такую же функцию выполняют выключатели характеристик. Способ использовать выключатели характеристик состоит в том, чтобы заключить весь новый код в «if»-оператор, который ищет названный выключатель характеристики (например, showFeatureXYZ) в конфигурационном файле или базе данных.
if (featureToggleEnabled(“showFeatureXYZ”)) {showFeatureXYZ()}
Ключевая идея в том, что по умолчанию все выключатели характеристик находятся в положении «выкл.». Т.е. положение по умолчанию является безопасным. Это означает, что, пока действует оболочка выключателя характеристики, можно загружать и даже разворачивать незавершённые или ошибочные коды, поскольку «if»-оператор обеспечивает, что код не будет выполнен или не окажет какое-либо видимое воздействие.
После завершения работы над характеристикой можно перевести указанный выключатель характеристики в положение «вкл.». Проще всего сохранить названные выключатели характеристик и их значения в конфигурационных файлах. Таким образом, можно разрешить данную характеристику в конфигурации среды разработки, но запретить её для использования, пока она не будет завершена.
# config.yml
dev:
showFeatureXYZ: true
prod:
showFeatureXYZ: false
Более мощной опцией является наличие динамической системы, в которой можно задавать значение выключателя характеристики для каждого пользователя, и наличие пользовательского веб-интерфейса, в котором ваши сотрудники могут динамично изменять значения выключателей характеристик, чтобы разрешать или запрещать какие-то характеристики для определённых пользователей, как показано на рис. 6.
Например, при разработке можно первоначально разрешить какую-то характеристику только для сотрудников вашей компании. Когда характеристика завершена, можно разрешить её для 1% всех пользователей. Если всё нормально, то можно дать разрешение для 10% пользователей, затем для 50% и т.д. Если в какой-то момент возникает проблема, то пользовательский веб-интерфейс позволяет выключить рассматриваемую характеристику. Выключатели характеристик можно использовать даже для сравнительного тестирования.
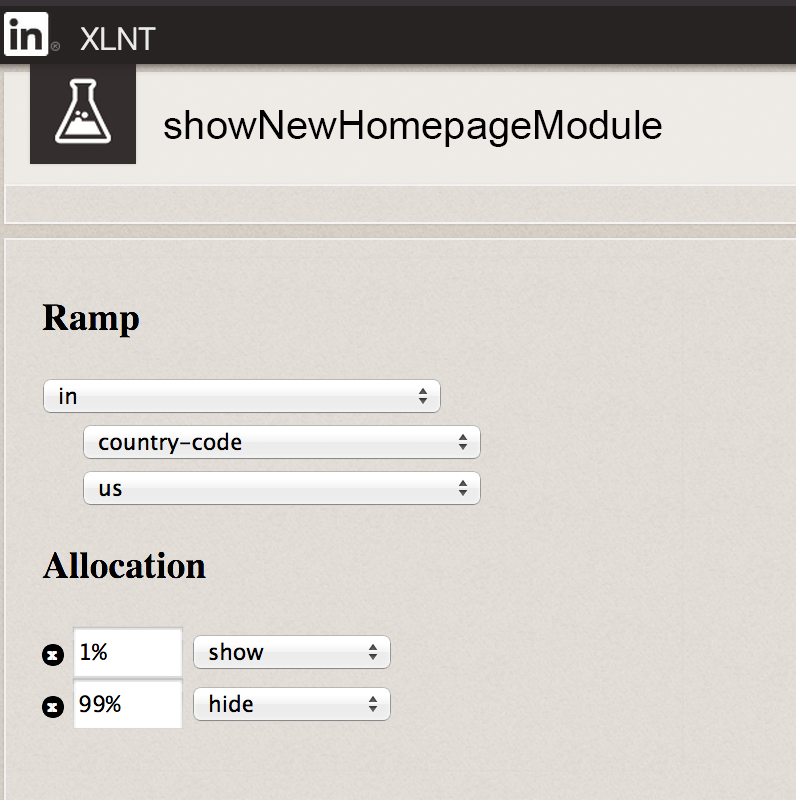
Рис. 6. Использование инструмента выключения характеристик XLNT в LinkedIn для включения некоторой характеристики для 1% пользователей США
Переборки / Разделение базы исходного кода
На кораблях используют переборки для создания изолированных водонепроницаемых отсеков. Благодаря этому при разрушении корпуса происходит затопление только одного единственного отсека.
Точно так же в программном обеспечении можно разделить базу исходного кода на изолированные компоненты, благодаря чему проблема, если она возникнет, будет действовать в пределах только этого компонента.
Разделение базы исходного кода является важным, поскольку худшим свойством для базы исходного кода является избыточный размер. Чем больше размер программы, тем медленнее идёт её разработка. Например, рассмотрим табличку из книги Стива Макконелла «Совершенный код» (Steve McConnell «Code Complete», 2004), показывающую связь размера проекта (в строках кода) с плотностью ошибок (количество ошибок на тысячу строк кода):

Здесь видно, что по мере увеличения кодовой базы плотность ошибок растёт. Если база исходного кода увеличивается в 2 раза, то количество ошибок возрастает в 4-8 раз. И когда приходится работать более чем с полумиллионом кодовых строк, плотность ошибок может достигать одной ошибки на каждые 10 строк!
Причина этого состоит в том — если использовать цитату из книги Венката Субраманиама, Энди Ханта «Этюды на тему быстрой разработки программного обеспечения. Работа в реальном мире.» — что «разработка программного обеспечения происходит не на какой-то схеме, не в какой интегрированной среде разработки или в каком-то средстве проектирования; она происходит в вашей голове». База исходного кода, содержащая сотни тысяч кодовых строк, намного превышает то, что человек может удержать в голове. Невозможно рассмотреть все взаимодействия и тупиковые ситуации в такой огромной программе. Поэтому необходима стратегия для разделения программы так, чтобы можно было в данный момент времени сфокусироваться на какой-то одной её части и безопасно оставить в стороне всё остальное.
Имеются две главные стратегии для разделения кодовой базы: одна — введение зависимостей от искусственных признаков, а другая — введение архитектуры микросервисов.
Идея зависимостей от искусственных признаков состоит в таком изменении ваших модулей, чтобы они вместо зависимости от исходного кода других модулей (зависимость от источника) подчинялись версионированным искусственным признакам, выдаваемыми другими модулями (зависимость от искусственных признаков). Это, возможно, вы уже делаете с библиотеками открытых кодов. Чтобы использовать jQuery в вашей JavaScript-программе или Apache Kafka в вашем Java-коде, вы опираетесь не на исходный код соответствующих библиотек открытых кодов, а на версионированный искусственный признак, который эти библиотеки предоставляют, например, jquery-1.11-min.js или kafka-clients-0.8.1.jar. Если используется фиксированная версия каждого модуля, то изменения, осуществляемые разработчиками на таких модулях, не будут сказываться на вас, пока вы не выберете в явном виде обновление. Такой подход — подобно переборкам на корабле — изолирует вас от проблем в других компонентах.
Идея микросервисов состоит в переходе от единого монолитного приложения, в котором все ваши модули работают в одном и том же процессе и коммуницируют через функциональные вызовы, к изолированным сервисам, где каждый модуль работает в отдельном процессе — обычно на отдельном сервере — и где модули коммуницируют через сообщения. Сервисные границы действуют как границы прав собственности на программное обеспечение, поэтому микросервисы могут быть отличным способом позволить командам работать независимо от друг друга. Микросервисы также делают возможным использование множества разных технологий для создания ваших продуктов (например, один микросервис может быть построен на Python, другой — на Java, третий — на Ruby) и независимую оценку каждого сервиса.
Хотя зависимости от искусственных признаков и микросервисы имеют много достоинств, они также содержат немало существенных недостатков, не последним из которых для обоих методов является функционирование в противоречии с идеями непрерывной интеграции, описанными ранее. Полное обсуждение компромиссов см. в статье "Splitting Up a Codebase into Microservices and Artifacts" («Разделение базы исходного кода в подходах микросервисов и искусственных признаков»).
Три вопроса
Механизмы, обеспечивающие безопасность, позволяют двигаться быстрее, но — за всё приходится платить: они требуют предварительных затрат времени, когда разработка, фактически, замедляется. Как решить, сколько времени имеет смысл затратить на механизм безопасности для текущего продукта? Чтобы принять решение, необходимо поставить перед собой три вопроса:
• Какова цена проблемы, устраняемой рассматриваемым механизмом?
• Какова цена самого механизма обеспечения безопасности?
• Насколько вероятно возникновение таких проблем?
Чтобы закончить эту статью, давайте рассмотрим, как указанные выше три вопроса работают для распространённого решения: делать или нет автоматизированное тестирование.
Хотя некоторые несгибаемые энтузиасты тестирования утверждают, что следует писать тесты на всё и стремиться к 100%-му покрытию кода, чрезвычайно редко можно видеть что-нибудь близкое к этому в реальном мире. Когда я писал свою книгу «Hello, Startup» («Привет, стартап»), я интервьюировал разработчиков из некоторых наиболее успешных стартапов последнего десятилетия, включая Google, Facebook, LinkedIn, Twitter, Instagram, Stripe и GitHub. Оказалось, что все они шли на тщательно продуманные компромиссы в том, что проверять, а что не проверять, особенно в их первые годы.
Рассмотрим эти три вопроса.
Какова стоимость написания и обслуживания автоматизированных тестов?
Подготовка модульных тестов в настоящее время стоит недорого. Имеются высококачественные платформы тестирования почти для всех языков программирования; большинство компоновочных систем имеет встроенную поддержку для модульного тестирования и работает, как правило, быстро. С другой стороны, интеграционные тесты (особенно тесты пользовательского интерфейса) требуют задействования значительных частей вашей системы, что означает, что они более дорогие для настройки, медленнее работают и их тяжелее поддерживать.
Конечно, интеграционные тесты могут выловить много ошибок, которые пропустят модульные тесты. Но поскольку их настройка и проведение стоят довольно дорого, оказалось, что большинство стартапов направляет основные средства в большой комплекс модульных тестов, вкладывая лишь немного в небольшой набор чрезвычайно ценных и критических интеграционных тестов.
Какова стоимость ошибок, которые могут пройти, если нет автоматизированных тестов?
Если вы делаете прототип, который, скорее всего, выбросите через неделю, то стоимость ошибок низкая, поэтому инвестирование в тесты, вероятно, не окупится. С другой стороны, если вы создаёте систему обработки платежей, то стоимость ошибок очень высока: вы, конечно, не хотите списывать средства с кредитной карты клиента дважды или оперировать с неправильной суммой.
Хотя стартап-компании, в которых я общался с разработчиками, различались по их практике тестирования, но почти каждая определила для себя несколько частей их кодов – как правило, платежи, безопасность и хранение данных – нарушение которых является просто недопустимым и поэтому серьёзная проверка которых шла буквально с первого дня.
Какова вероятность получить ошибки без автоматизированных тестов?
Как было показано выше, по мере роста кодовой базы плотность ошибок растёт. То же самое действительно для увеличения размера команды и сложности проекта.
Для команды из двух программистов при коде из 10 000 строк будет достаточно потратить лишь 10% их времени на написание тестов; при двадцати программистах и коде из 100 000 строк на это уйдёт уже 20% их времени, а для команды из двухсот разработчиков кода с 1 млн. строк понадобится уже 50%!
По мере роста размера программы и количества разработчиков необходимо затрачивать сравнительно всё больше времени на тестирование.
ссылка на оригинал статьи https://megamozg.ru/post/25426/
Добавить комментарий