 Хочу признаться: я обожаю визуальные новеллы. Кто не в курсе — это такие то ли интерактивные книжки, то ли игры-в-которых-надо-в-основном-читать-текст, то ли радиоспектакли-с-картинками, преимущественно японские. Последние лет 5, наверное, художественную литературу в другом формате толком не вопринимаю: у визуальных новелл по сравнению с бумажными книгами, аудио-книгами и даже сериалами — в разы большее погружение, да и сюжет регулярно куда интереснее.
Хочу признаться: я обожаю визуальные новеллы. Кто не в курсе — это такие то ли интерактивные книжки, то ли игры-в-которых-надо-в-основном-читать-текст, то ли радиоспектакли-с-картинками, преимущественно японские. Последние лет 5, наверное, художественную литературу в другом формате толком не вопринимаю: у визуальных новелл по сравнению с бумажными книгами, аудио-книгами и даже сериалами — в разы большее погружение, да и сюжет регулярно куда интереснее.
А еще я с детства обожаю разбираться в том, как устроены вещи и что у них внутри. Начинал с первых сломанных игрушек, дорос до реверс-инжиниринга и вирусного аналитика в одной не самой маленькой компании. И пришло мне в голову — почему бы не попробовать совместить эти вещи? Посмотреть, что у визуальных новелл внутри и разобраться, на основе чего работает тот или иной движок?
А тут как раз недавно вышел релиз Kaitai Struct — это такой новый фреймворк для реверс-инжиниринга бинарных структур данных (хотя авторы активно отпираются, говоря, что они это все только в мирных целях). Идея там банальная, но подкупает: декларативно описываешь на некоем языке разметки структуру данных — и тут же получаешь готовую библиотеку классов для парсинга на любом поддерживаемом языке программирования. В комплекте прилагаются визуализатор (чтобы легче было проверять) и, собственно, компилятор. Что ж, попробуем, на что оно годится?
В качестве разминки, а заодно для того, чтобы показать типовые действия, с которыми придется столкнуться в реверс-инжиниринге, предлагаю начать с чего-нибудь не очень тривиального, а именно с чудесной визуальной новеллы Koisuru Shimai no Rokujuso (в оригинале — 恋する姉妹の六重奏) авторства широко известных в узких кругах PeasSoft. Это забавная, ненапрягающая романтическая комедия, с традиционно для PeasSoft красивой визуальной частью. С точки зрения реверсинга — меня она зацепила еще и тем, что использует не сильно распространенный и никем вроде бы еще не исследованный собственный движок. А это как минимум интереснее, чем ковыряться в уже напрочь замученных и растащенных по полочкам KiriKiri или Ren’Py.
Первым делом приведу список инструментов, которые нам потребуются:
- Kaitai Struct — компилятор и визуализатор к нему
- Java JRE — к сожалению, Kaitai Struct написан на Java и ее требует
- любой из языков программирования, поддерживаемый KS (на данный момент это Java, JavaScript, Ruby, Python) — я буду использовать Ruby, но это не столь принципиально, на нем мы напишем листер и экстратор в самом конце
- какой-нибудь хекс-редактор — по большому счету, не важно какой, они все неидеальные; в принципе, хекс-редактор есть внутри визуализатора KS, но он тоже не самый удобный; я лично пользуюсь okteta (просто потому, что там есть по-человечески удобный копи-паст) — но пойдет почти все, что угодно — была б возможность смотреть дамп, переходить по заданному адресу и быстро скопировать выделенный кусок в отдельный файл
Дальше нужен сам продукт исследования — дистрибутив визуальной новеллы. Здесь тоже повезло: PeasSoft на своем сайте выкладывает для совершенно легального бесплатного скачивания триальные версии, которых нам вполне хватит для ознакомления с форматами. На сайте нужно найти такую вот страничку:

Обведенное синим — на самом деле ссылки на мирроры (все одинаковые), где дают скачать триал.
Скачав и распаковав дистрибутив, мы начнем со сбора информации. Давай подумаем, что мы уже знаем о нашем экспонате. Во-первых, платформа. По крайней мере та версия, что раздается на сайте, работает под Windows на процессорах Intel (вообще есть еще версия под Android, но на практике она продается только в маркетах приложений у японских сотовых операторов, плюс ее нетривиально вытащить с телефона). Из того, что это Windows/Intel вытекают несколько весьма вероятных вещей:
- целые числа в бинарных форматах будут кодироваться в little-endian
- программисты под Windows в Японии до сих пор
живут в каменном векепользуются кодировкой Shift-JIS - концы строчек, если мы их когда-то встретим в явно виде, будут обозначаться "\r\n", а не просто "\n"
Беглый осмотр распакованного и установленного показывает, что добыча состоит из:
- data01.ykc — 8393294
- data02.ykc — 560418878
- data03.ykc — 219792804
- sextet.exe — 978944
- AVI/op.mpg — 122152964
Т.е. здесь один небольшой exe-шник (очевидно, с движком), нескольких гигантских файлов .ykc (вероятно, архивов с контентом) и op.mpg — видеофайл с заставкой (в чем можно убедиться сразу, открыв его любым плеером).
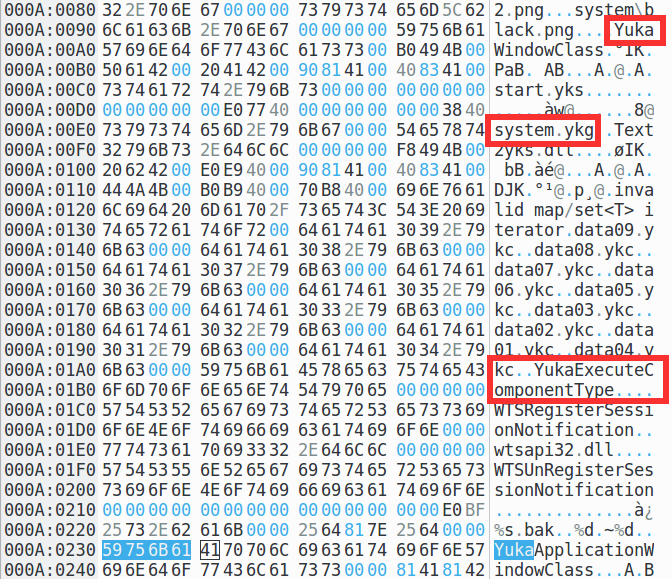
Полезно быстренько визуально осмотреть exe-файл в хекс-редакторе: современные разработчики даже достаточно адекватны и зачастую пользуются готовыми библиотеками для работы с изображениями, звуками и музыкой. А такие библиотеки, как правило, при компиляции оставляют некие видимые невооруженным глазом сигнатуры. Что стоит искать:
- "libpng version 1.0.8 — July 24, 2000" — используется libpng, значит картинки будут в формате png
- "zlib version error", "Unknown zlib error" — означает, что будет использоваться сжатие zlib; на самом деле может быть ложным следом, т.к. zlib-сжатие используется при кодировании png; пока не будем делать далекоидущих выводов
- "Xiph.Org libVorbis I 20020717" — libvorbis, а это означает, что музыка, речь и звуки будут скорее всего в ogg/vorbis
- "Corrupt JPEG data", "Premature end of JPEG file" — строчки из libjpeg; если есть — значит, движок скорее всего умеет еще и картинки в формате jpg
- "D3DX8 Shader Assembler Version 0.91" — где-то внутри что-то использует шейдеры D3DX8
- россыпь сообщений типа "Microsoft Visual C++ Runtime Library", "
local vftable'", "eh vector constructor iterator’" и т.д. говорит нам о том, что компилировалось линковалось это с Microsoft’овской C++ библиотекой, и, скорее всего, написано на C++; при желании можно покопаться и узнать даже конкретную версию, но сейчас нам это особенно ни к чему — мы не собираемся ее дизассемблировать или что-то такое, у нас абсолютно честный clean room
Еще можно поискать строчки типа "version", "copyright", "compiler", "engine", "script" — причем, т.к. это Windows-файл, не забывать делать это еще и в двухбайтовых кодировках типа UTF16-LE — иногда может найтись еще что-нибудь интересное. У нас находится, например, "Yuka Compiler Error", "YukaWindowClass", "YukaApplicationWindowClass", "YukaSystemRunning", а также упоминания "start.yks", "system.ykg". Из всего этого логично предположить, что сами программисты называли свой движок как-то типа "Yuka", а всякие типы файлы, используемые им, все начинаются с yk — ykc, yks, ykg. Еще находится "CDPlayMode" и "CDPlayTime" — из чего можно предположить, что движок умеет играть музыку с дорожек Audio CD, а еще "MIDIStop" и "MIDIPlay" — из чего можно предположить поддержку музыки в MIDI.
По нашей новелле в сухом остатке получается достаточно оптимистичная картина:
- картинки в форматах png и jpg, что сразу на порядок облегчает задачу — скорее всего не нужно будет копаться в кастомных форматах сжатия картинок
- музыка, речь и звуки — скорее всего в ogg (но может быть и MIDI, и CDDA — хотя вряд ли, т.к. физического носителя нет)
Первоначальные сведения собраны — теперь можно засучить рукава и нырять в файлы. Файлов, на самом деле, несколько — и это тоже хорошо. Вообще в реверс-инжиниринге зачастую очень важным становится чисто статистический вопрос, когда изучаемого объекта можно достать более одного в различных вариациях и посмотреть, чем же они отличаются. Гораздо сложнее гадать, что же значит очередной 7F 02 00 00, когда он у тебя ровно один.
Проверяем, один ли и тот же формат у файлов. Судя по тому, что все они — data*.ykc — один. Смотрим внутрь на начало файла: все начинается с "YKC001\0\0" — очень хорошо, похоже, что это действительно архивы одного и того же формата.
Быстро эмпирически проверим, используется ли какое-то сжатие. Берем любой архиватор, пытаемся сжать файл и смотрим, сколько было до и сколько стало после. Я тупо использовал zip:
- до — 8393294
- после — 6758313
Сжимается, но не сильно. Скорее всего таки или сжатия нет, или оно есть не для всех файлов. С другой стороны, если в архиве какие-нибудь png или ogg —они же уже сжатые, zip’ом сжиматься они сильнее не будут.
Из общих соображений, у практически любого архива есть какой-то заголовок, есть, как правило, каталог содержимого архива (относительно небольшой), и 99% архивного файла занимает, собственно содержимое — вложенные файлы или блоки данных. Заголовок, кстати, не обязательно начинается прямо с начала файла — может быть с сколько-нибудь отступив от конца файла или сколько-нибудь (обычно немного) — от начала. Крайне редко можно встретить, чтобы файл начинали с места в карьер читать из середины.
Смотрим на начало файлов. Видим примерно следующую картину:
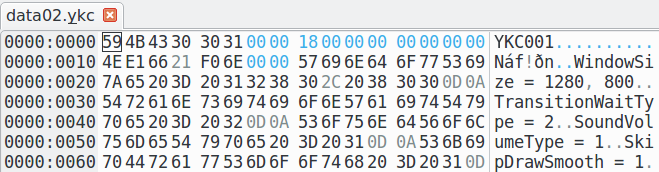
59 4B 43 30 │ 30 31 00 00— это явно просто сигнатура файла, в ASCII это "YKC001", скорее всего обозначает что-нибудь типа "Yuka Container", версии 00118 00 00 00 │ 00 00 00 00 │ 1A 00 80 00 │ 34 12 00 00— видимо, это и есть заголовок- дальше явно начинается тело какого-то файла внутри архива; особенно хорошо это видно в data02.ykc — там идут строчки какого-то то ли конфига, то ли скриптового языка: "WindowSize = 1280, 800", "TransitionWaitType = 2" и т.д.; т.е. дальше смотреть бессмысленно
Смотрим на то, как выглядит заголовок во всех трех имеющихся у нас файлах:
- data01.ykc:
18 00 00 00 │ 00 00 00 00 │ 1A 00 80 00 │ 34 12 00 00 - data02.ykc:
18 00 00 00 │ 00 00 00 00 │ 4E E1 66 21 │ F0 6E 00 00 - data03.ykc:
18 00 00 00 │ 00 00 00 00 │ 5C E1 18 0D │ 48 E4 00 00
Что такое "18 00 00 00 │ 00 00 00 00" — пока непонятно, но оно везде одинаковое. Гораздо интереснее остальные 2 поля — это явно два 4-байтовых целых числа. Кажется, пора доставать Kaitai Struct и начинать описывать полученные догадки в виде ksy-формата:
meta: id: ykc application: Yuka Engine endian: le seq: - id: magic contents: ["YKC001", 0, 0] - id: magic2 contents: [0x18, 0, 0, 0, 0, 0, 0, 0] - id: unknown1 type: u4 - id: unknown2 type: u4
Вроде бы ничего сложного. ksy — на самом деле обычные YAML-файлы. Секция "meta" описывает, над чем мы собственно работаем и что мы собрали по итогам нашего предварительно расследования — т.е. что мы разбираем файлы "ykc", предположительно обрабатывает их приложение под названием "Yuka Engine" (поле "application" вроде бы ни на что не влияет, это как комментарий), и по умолчанию целые числа будут в little endian формате (endian: le).
Дальше идет описание того, как парсить файл и какие структуры данных мы в нем обнаружили — это задается массивом полей в секции "seq". Каждое поле обязано иметь id (и это логично, мы ради этого и работаем, чтобы понять, что где лежит) и описание содержимого. Тут мы использовали две конструкции:
- Конструкция типа
contents: [0x18, 0, 0, 0, 0, 0, 0, 0]задает поле с фиксированным содержимым. Работает это так: из содержимого автоматически следует его длина, плюс KS автоматически сделает проверку и выбросит exception, если при чтении такого поля содержимое не будет соответствовать ожидаемому - Конструкция типа
type: u4задает поле типа "целое беззнаковое (_u_nsigned) число, длина 4 байта". Endianness при этом такой, как мы указали в meta.
Загружаем теперь наш новоиспеченный формат в визуализатор:
ksv data01.ykc ykc.ksy
и лицезрим для data01.ykc:
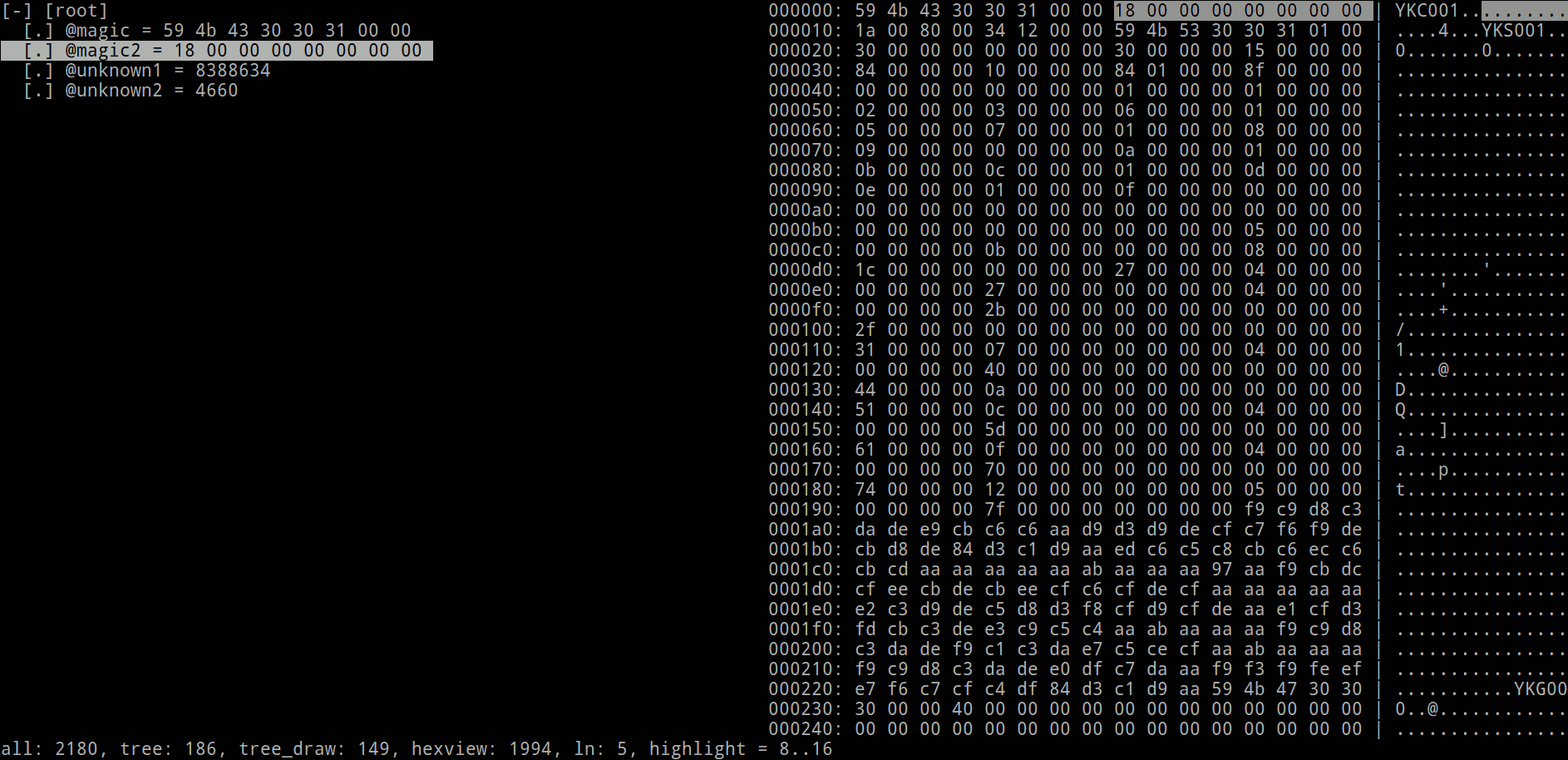
Да, визуализатор работает в консоли, можно начинать ощущать себя хакером. Но сейчас нас интересует дерево структур:
[-] [root] [.] @magic = 59 4b 43 30 30 31 00 00 [.] @magic2 = 18 00 00 00 00 00 00 00 [.] @unknown1 = 8388634 [.] @unknown2 = 4660
В визуализаторе можно стрелочками ходить по полям, можно переключаться в hex viewer и обратно нажатием Tab, а нажатием Enter можно проваливаться в содержимое полей, раскрывать instances (о них будет ниже) и просматривать хекс-дампы на полный экран. Для экономии места и времени я ниже скриншоты визуализатора больше показывать не буду, буду показывать только часть с деревом текстом.
Смотрим для data02.ykc:
[-] [root] [.] @magic = 59 4b 43 30 30 31 00 00 [.] @magic2 = 18 00 00 00 00 00 00 00 [.] @unknown1 = 560390478 [.] @unknown2 = 28400
для data03.ykc:
[-] [root] [.] @magic = 59 4b 43 30 30 31 00 00 [.] @magic2 = 18 00 00 00 00 00 00 00 [.] @unknown1 = 219734364 [.] @unknown2 = 58440
Негусто, в общем. Каталога файлов нет, где искать концы, на первый взгляд, непонятно. Тут самое время вспомнить еще раз, сколько же эти файлы занимают и прикинуть, не может ли одно из этих двух числе быть ссылкой куда-то еще:
- data01.ykc — 8393294 @unknown1 = 8388634
- data02.ykc — 560418878 @unknown1 = 560390478
- data03.ykc — 219792804 @unknown1 = 219734364
Какое поразительное сходство. Давайте проверять, что там лежит по этому смещению:
meta: id: ykc application: Yuka Engine endian: le seq: - id: magic contents: ["YKC001", 0, 0] - id: magic2 contents: [0x18, 0, 0, 0, 0, 0, 0, 0] - id: unknown_ofs type: u4 - id: unknown2 type: u4 instances: unknown3: pos: unknown_ofs size-eos: true
Мы добавили описание еще этого поля "unknown3". На этот раз оно пошло не в секцию "seq", а в секцию "instances". По сути это примерно те же поля, что можно описать в "seq", но они идут не по порядку, а имеют явное указание, откуда их читать (по какому смещению, из какого потока и т.д.). Мы указали, что хотим иметь поле с названием "unknown3" (мы пока не знаем, что там), начинающееся от смещения unknown_ofs (pos: unknown_ofs) и длящееся до конца файла (size-eos: true). Как как ты не знаем, что там — нам прочитают просто поток байт. Да, пока негусто, но с этим уже можно пробовать жить. Пробуем:
Сразу обращаем внимание на то, что длина того, что у нас прочиталась поразительно похоже на содержимое поле unknown2. Т.е. похоже, что в начале YKC-файла лежит просто указание, по какому смещению и какого размера реальный заголовок файла. Исправляем наш файл формата, чтобы отразить эту догадку:
meta: id: ykc application: Yuka Engine endian: le seq: - id: magic contents: ["YKC001", 0, 0] - id: magic2 contents: [0x18, 0, 0, 0, 0, 0, 0, 0] - id: header_ofs type: u4 - id: header_len type: u4 instances: header: pos: header_ofs size: header_len
Изменения незначительные: мы переименовали все unknown-поля, чтобы отразить их смысл, и "size-eos: true" (читать все безусловно до конца файла) изменили на "size: header_len". Скорее всего это близко соответствует замыслу того, кто придумывал этот формат. Загружаем еще раз и теперь концентрируемся на том блоке данных, что мы назвали "header". Вот как выглядит его начало для data01.ykc:
000000: 57 e7 7f 00 0a 00 00 00 18 00 00 00 13 02 00 00 | W............... 000010: 00 00 00 00 61 e7 7f 00 0b 00 00 00 2b 02 00 00 | ....a.......+... 000020: db 2a 00 00 00 00 00 00 6c e7 7f 00 11 00 00 00 | .*......l....... 000030: 06 2d 00 00 92 16 00 00 00 00 00 00 7d e7 7f 00 | .-..........}...
для data02.ykc:
000000: d1 2b 66 21 0c 00 00 00 18 00 00 00 5a 04 00 00 | .+f!........Z... 000010: 00 00 00 00 dd 2b 66 21 14 00 00 00 72 04 00 00 | .....+f!....r... 000020: 26 1a 00 00 00 00 00 00 f1 2b 66 21 16 00 00 00 | &........+f!.... 000030: 98 1e 00 00 a8 32 00 00 00 00 00 00 07 2c 66 21 | .....2.......,f!
для data03.ykc:
000000: ec 30 17 0d 26 00 00 00 18 00 00 00 48 fd 00 00 | .0..&.......H... 000010: 00 00 00 00 12 31 17 0d 26 00 00 00 60 fd 00 00 | .....1..&...`... 000020: 0d 82 03 00 00 00 00 00 38 31 17 0d 26 00 00 00 | ........81..&... 000030: 6d 7f 04 00 d0 85 01 00 00 00 00 00 5e 31 17 0d | m...........^1..
На первый взгляд, ничего не понятно и общего ничего нет. На второй взгляд, на самом деле, глаз цепляется за последовательность повторяющихся байт. В первом файле это e7 7f, во втором — 2b 66, в третьем — 30 17 и 31 17. Очень похоже, что мы имеем дело с повторяющимися записями фиксированной длины и длина эта — 0x14 (т.е. 20) байт. Кстати, это хорошо согласуется с длинами header во всех трех файлах: и 4660, и 28400, и 58440 делятся на 20. Давайте проверять такую гипотезу:
meta: id: ykc application: Yuka Engine endian: le seq: - id: magic contents: ["YKC001", 0, 0] - id: magic2 contents: [0x18, 0, 0, 0, 0, 0, 0, 0] - id: header_ofs type: u4 - id: header_len type: u4 instances: header: pos: header_ofs size: header_len type: header types: header: seq: - id: entries size: 0x14 repeat: eos
Обратите внимание на то, что стало с instance "header". Оно все так же начинается с header_ofs и имеет длину header_len, но добавилось еще указание type: header. В отличие от "u4" (целое число), мы сейчас объявим и будем использовать пользовательский тип и весь блок "header" будет разбираться этим типом. Ниже идет описание типа "header" — см. "types: header: ". Как можно догадаться по внешнему виду и слову "seq" — дальше следует ровно такой же синтаксис как на самом верхнем уровне файла. Т.е. внутри нашего нового типа header можно точно так же задать поля, которые будут читать с самого начала блока последовательно (в "seq"), поля по определенным смещениям (в "instances"), свои подтипы (в "types") и т.д.
Итак, мы задали тип "header", состоящий пока из одного поля entries, имеющего размер 0x14 байт, зато повторенного столько раз, сколько возможно до конца потока (repeat: eos). Потоком, кстати, в этом случае считается уже блок header, который мы объявили явно как блок в header_len байт, начинающийся с header_ofs. Т.е. если бы там что-то было за ним еще — оно бы не прочиталось, все в порядке.
Смотрим, что получилось:
[-] header [-] @entries (233 = 0xe9 entries) [.] 0 = 57 e7 7f 00|0a 00 00 00|18 00 00 00|13 02 00 00|00 00 00 00 [.] 1 = 61 e7 7f 00|0b 00 00 00|2b 02 00 00|db 2a 00 00|00 00 00 00 [.] 2 = 6c e7 7f 00|11 00 00 00|06 2d 00 00|92 16 00 00|00 00 00 00 [.] 3 = 7d e7 7f 00|14 00 00 00|98 43 00 00|69 25 00 00|00 00 00 00 [.] 4 = 91 e7 7f 00|15 00 00 00|01 69 00 00|d7 12 00 00|00 00 00 00 [.] 5 = a6 e7 7f 00|12 00 00 00|d8 7b 00 00|27 3f 07 00|00 00 00 00
А что, неплохо. Какая-то общность записей явно прослеживается. Из спортивного интереса посмотрим второй файл:
[-] header [-] @entries (1420 = 0x58c entries) [.] 0 = d1 2b 66 21|0c 00 00 00|18 00 00 00|5a 04 00 00|00 00 00 00 [.] 1 = dd 2b 66 21|14 00 00 00|72 04 00 00|26 1a 00 00|00 00 00 00 [.] 2 = f1 2b 66 21|16 00 00 00|98 1e 00 00|a8 32 00 00|00 00 00 00 [.] 3 = 07 2c 66 21|16 00 00 00|40 51 00 00|a2 16 00 00|00 00 00 00 [.] 4 = 1d 2c 66 21|16 00 00 00|e2 67 00 00|89 c4 00 00|00 00 00 00 [.] 5 = 33 2c 66 21|16 00 00 00|6b 2c 01 00|fa f5 00 00|00 00 00 00
Кстати, "233" и "1420" записей вполне похоже на количество файлов в архиве. Первый архив у нас маленький (8 мегабайт), на 233 файла — получается в среднем по 36022 байта на файл. Вполне похоже на какие-то скрипты, конфиги, файлы сценариев и т.п. Второй архив у нас самый большой (560 мегабайт), на 1420 файлов — по 394661 байта на файл, вполне похоже на какие-нибудь картинки или файлы с записями голоса.
57 e7 7f 00, 61 e7 7f 00, 6c e7 7f 00 и т.д. — это явно последовательность увеличивающихся чисел, что бы она могла означать? Во втором файле это, соответственно, d1 2b 66 21, dd 2b 66 21, f1 2b 66 21. Стоп, где-то я уже видел эти цифры. Смотрим в самое начало нашего исследования — точно. Это же близко к длине всего архивного файла целиком. А значит это опять указатели на что-то внутри файла. Собственно, давайте уже опишем структуру этих 20-байтовых записей. Вроде бы из внешнего вида понятно, что это банально 5 целых чисел. Описываем еще один тип "file_entry". В вашего молчаливого разрешения я не буду приводить весь ksy файл целиком, а приведу только изменившуюся секцию types:
types: header: seq: - id: entries repeat: eos type: file_entry file_entry: seq: - id: unknown_ofs type: u4 - id: unknown2 type: u4 - id: unknown3 type: u4 - id: unknown4 type: u4 - id: unknown5 type: u4
Здесь никаких новых конструкций вроде бы нет. Добавили "type" к полю entries и описали этот самый тип как 5 подряд идущих целых (типа u4). Смотрим, что получилось:
[-] header [-] @entries (233 = 0xe9 entries) [-] 0 [.] @unknown_ofs = 8382295 [.] @unknown2 = 10 [.] @unknown3 = 24 [.] @unknown4 = 531 [.] @unknown5 = 0 [-] 1 [.] @unknown_ofs = 8382305 [.] @unknown2 = 11 [.] @unknown3 = 555 [.] @unknown4 = 10971 [.] @unknown5 = 0 [-] 2 [.] @unknown_ofs = 8382316 [.] @unknown2 = 17 [.] @unknown3 = 11526 [.] @unknown4 = 5778 [.] @unknown5 = 0
Вырисовывается еще одна гипотеза: unknown3 — указатель на начало тела файла в архиве, а unknown4 — его длина. Ведь 24 + 531 = 555, а 555 + 10971 = 11526. Т.е. это файлы внутри архива, которые тупо идут последовательно. Аналогичное наблюдение можно сделать и для unknown_ofs и unknown2: 8382295 + 10 = 8382305, 8382305 + 11 = 8382316. То есть unknown2 — длина каких-то записей, начинающихся с unknown_ofs. unknown5, похоже, всегда равен 0. Вперед, добавляем внутрь каждого file_entry еще два поля: зачитаем, контент (unknown_ofs; unknown2) и тело файла на (unknown3; unknown4). Привожу только описание file_entry:
file_entry: seq: - id: unknown_ofs type: u4 - id: unknown_len type: u4 - id: body_ofs type: u4 - id: body_len type: u4 - id: unknown5 type: u4 instances: unknown: pos: unknown_ofs size: unknown_len io: _root._io body: pos: body_ofs size: body_len io: _root._io
Из нового и нетривиального здесь только одна конструкция: io: _root._io. Без нее pos: body_ofs, скажем, будет отсчитывать смещение body_ofs в текущем потоке, т.е. в потоке, состоящем из 20 байт file_entry. Разумеется, попытка прочитать 8-милионный байт из 20 приведет к ошибке. Поэтому и нужна эта самая специальная магия, которая говорит о том, что зачитывать мы будем не из текущего потока, а из того потока, который соответствует всему файлу в целом — _root._io.
Что получилось:
[-] @entries (233 = 0xe9 entries) [-] 0 [.] @unknown_ofs = 8382295 [.] @unknown_len = 10 [.] @body_ofs = 24 [.] @body_len = 531 [.] @unknown5 = 0 [-] unknown = 73 74 61 72 74 2e 79 6b 73 00 [-] body = 59 4b 53 30 30 31 01 00 30 00 00 00… [-] 1 [.] @unknown_ofs = 8382305 [.] @unknown_len = 11 [.] @body_ofs = 555 [.] @body_len = 10971 [.] @unknown5 = 0 [-] unknown = 73 79 73 74 65 6d 2e 79 6b 67 00 [-] body = 59 4b 47 30 30 30 00 00 40 00 00 00…
Даже невооруженным глазом видно, что 73 74 61 72 74 2e 79 6b 73 00 — это ASCII-строка, а посмотрев в char-представление, можно убедиться, что это "start.yks" с терминирующим 0 байтом, а 73 79 73 74 65 6d 2e 79 6b 67 00 — это "system.ykg". Ура, это похоже на имена файлов. И про них мы точно знаем, что они — строки. Давайте отразим этот факт:
file_entry: seq: - id: filename_ofs type: u4 - id: filename_len type: u4 - id: body_ofs type: u4 - id: body_len type: u4 - id: unknown5 type: u4 instances: filename: pos: filename_ofs size: filename_len type: str encoding: ASCII io: _root._io body: pos: body_ofs size: body_len io: _root._io
Из нововведений — type: str (означает, что захваченные байты надо интерпретировать, как строку) и encoding: ASCII (мы пока точно не знаем, что там за кодировка, поэтому пойдем по пути наименьшего сопротивления). Смотрим в визуализаторе:
[-] header [-] @entries (233 = 0xe9 entries) [-] 0 [.] @filename_ofs = 8382295 [.] @filename_len = 10 [.] @body_ofs = 24 [.] @body_len = 531 [.] @unknown5 = 0 [-] filename = "start.yks\x00" [-] body = 59 4b 53 30 30 31 01 00 30 00 00 00… [-] 1 [.] @filename_ofs = 8382305 [.] @filename_len = 11 [.] @body_ofs = 555 [.] @body_len = 10971 [.] @unknown5 = 0 [-] filename = "system.ykg\x00" [-] body = 59 4b 47 30 30 30 00 00 40 00 00 00… [-] 2 [.] @filename_ofs = 8382316 [.] @filename_len = 17 [.] @body_ofs = 11526 [.] @body_len = 5778 [.] @unknown5 = 0 [-] filename = "SYSTEM\\black.PNG\x00" [-] body = 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d…
Красота. Фактически, все, задачу мы уже выполнили, этого достаточно, чтобы извлекать файлы. А теперь — та магия, ради которой все затевалось. Давайте напишем скрипт, который выгрузит нам все файлы из одного архива. И для этого нам не придется писать парсинг всех этих полей еще раз. Мы просто берем компилятор ksc и делаем:
ksc -t ruby ykc.ksy
и получаем в текущей папке прекрасный файл ykc.rb, который можно тут же подключать, как библиотеку и использовать. Как? Давайте для разминки покажу, как вывести на экран листинг всех файлов архива:
require_relative 'ykc' Ykc.from_file('data01.ykc').header.entries.each { |f| puts f.filename }
Внушает? Всего одна строчка (не считая подключения библиотеки) — и готово. Запускаем и видим здоровый листинг:
start.yks system.ykg SYSTEM\black.PNG SYSTEM\bt_click.ogg SYSTEM\bt_select.ogg SYSTEM\config.yks SYSTEM\Confirmation.yks SYSTEM\confirmation_load.png SYSTEM\confirmation_no.ykg SYSTEM\confirmation_no_load.ykg ...
Давайте разберемся, что же тут происходит:
Ykc.from_file(...)— порождает объект класса Ykc из указанного файла на диске; в поля объекта автоматически парсится то, что описано в формате.header— выбирает поле "header" класса Ykc, тем самым возвращая экземпляр класса Ykc::Header.entries— выбирает поле "entries" у заголовка, возвращает массив элементов класса Ykc::FileEntry.each { |f| ... }— делает что-то с каждым элементом массиваputs f.filename— выводит поле "filename" объекта f (который класса Ykc::FileEntry)
Перед тем, как написать код, который будет извлекать из архива все файлы, обратим внимание еще на пару фактов:
- Во-первых, в путях есть папки, а т.к. этот архив делали на Windows-системе, в качестве знака разделителя элементов пути используется обратный слэш ("\"). Не знаю как где, но как минимум в Ruby это приводит к тому, что создается папка с обратными слэшами в ней. Для корректной работы всяких там mkdir_p нужно будет поменять "\" на "/".
- Во-вторых, в именах файлов в конце есть терминирующий 0, доставшийся нам, видимо, как тяжелое наследие C. При выводе на печать его не видно, но по хорошему его бы тоже стоит убрать.
- В-третьих, на самом деле вскрытие показало, что в data02.ykc находятся файлы, выглядящие как-то так:
"SE\\00050_\x93d\x98b\x82P.ogg\x00" "SE\\00080_\x83J\x81[\x83e\x83\x93.ogg\x00" "SE\\00090_\x83`\x83\x83\x83C\x83\x80.ogg\x00" "SE\\00130_\x83h\x83\x93\x83K\x83`\x83\x83\x82Q.ogg\x00" "SE\\00160_\x91\x96\x82\xE8\x8B\x8E\x82\xE9\x82Q.ogg\x00"
Вспомнив гипотезу из самого начала статьи о том, что программисты явно были японцами и это может быть ShiftJIS, меняем encoding у filename на "SJIS", активно утешая себя мыслью о том, что для тех, кто использует не-ASCII символы в именах файлах приготовлен специальный круг в аду. Не забываем перекомпилировать ksy => rb, проверяем, теперь все в порядке:
SE\00050_電話1.ogg SE\00080_カーテン.ogg SE\00090_チャイム.ogg SE\00130_ドンガチャ2.ogg SE\00160_走り去る2.ogg
Ну, не то, чтобы совсем в порядке, но это вполне похоже на японский. Воспользовавшись хотя бы гуглопереводчиком, можно проверить, что "電話" — это "телефон", и "SE\00050" — видимо, звуковой эффект звонка телефона.
Окончательный скрипт выгрузки всего выглядит так:
require 'fileutils' require_relative 'ykc' EXTRACT_PATH = 'extracted' ARGV.each { |ykc_fn| Ykc.from_file(ykc_fn).header.entries.each { |f| filename = f.filename.strip.encode('UTF-8').gsub("\\", '/') dirname = File.dirname(filename) FileUtils::mkdir_p("#{EXTRACT_PATH}/#{dirname}") File.write("#{EXTRACT_PATH}/#{filename}", f.body) } }
Уже не одна строчка, конечно, но, с другой стороны, комментировать тут тоже особенно нечего. Из аргументов командной строки получаем имена файлов с архивами (вполне можно запускать что-то типа ./extract-ykc *.ykc — сработает), приводим к нужному нам виду имя файла из f.filename, создаем, если нужно, папки в пути, берем само содержимое файла из f.body и записываем его в файл с нужным путем.
Наша задача выполнена — запустив скрипт, можно действительно убедиться в том, что файлы извлекаются. Как мы и предполагали, картинки будут преимущественно в png (и их можно сразу же смотреть), музыка и звуки — в ogg (и их можно сразу же слушать). Вот, например, что в папке BG явно получились все бэкграунды:
А в папке TA/ по разложены спрайты, которые на них накладываются. Так, например, выглядит Мика:

Отдельно обратите внимание на страшные названия файлов. Самое нетривиальное, что остается — это извлеченные файлы yks и ykg — видимо, в них и есть сценарий и текст новеллы. На первый взгляд — это бинарные файлы с непонятной структурой. Думаю, отложим их на следующий раз 🙂
Краткие выводы по итогам такого шапочного знакомства с KS:
- Kaitai Struct в целом весьма годен, достаточно близко соответствует тем действиям, которые бы делались без него и экономит кучу времени. Если делать такое руками — то, как минимум, пришлось бы писать то же самое на каком-нибудь Ruby или Python: один раз, чтобы разобраться со структурой бинарника, другой — чтобы собственно сделать распаковщик. А если делать это средствами каких-нибудь "продвинутых" редакторов типа 101 или Hexinator — то и три раза (плюс еще один раз — описать в редакторе).
- Визуализатор Kaitai Struct — весьма примитивен, и местами тормозит и подглючивает, но, в целом, это лучшее, что я видел в этой области. Ему бы еще хекс-редактор доделать до состояния okteta.
- Хекс-редактор, собственно, можно выкидывать после того, как сделан первый скелет файла. Все равно ходить по дереву куда проще и нагляднее, чем вручную вбивать смещения. Но он все еще нужен и полезен для предварительного просмотра + просмотра exe-шника.
- Экспрессивность языка ksy очень большая (в разы лучше и удобнее, чем те же языки разметки в редакторах — например, там, как правило, даже речь не идет о том, чтобы декларативно описать структуру в другом конце файла), но вот документация, мягко говоря, оставляет желать лучшего. Признаюсь честно — за последнюю неделю я, наверное, задолбал вопросами автора KS. Вот этот самый трюк с
io: _root._io— вообще отстрел мозга, который самостоятельно не придумаешь. Надеюсь, к версии 1.0 документацию таки приведут в приличный вид.
ссылка на оригинал статьи https://habrahabr.ru/post/281595/
Добавить комментарий