
Я уже писал о том, с помощью Isilon можно создавать озёра данных, способные одновременно обслуживать по несколько кластеров с разными версиями Hadoop. В той публикации я упомянул, что во многих случаях системы на Isilon работают быстрее, чем традиционные кластеры, использующие DAS-хранилища. Позднее это подтвердили и в IDC, прогнав на соответствующих кластерах различные Hadoop-бенчмарки. И на этот раз я хочу рассмотреть причины более высокой производительности Isilon-кластеров, а также как она меняется в зависимости от распределения данных и балансировки внутри кластеров.
Тестовая среда
- Дистрибутив Cloudera Hadoop CDH5.
- DAS-кластер из 7 узлов (один мастер, шесть рабочих), с восемью дисками-десятитысячниками по 300 Гб.
- Isilon-кластер из 4 узлов x410, каждый из которых оснащён 57 Тб на дисках и 3,2 Тб на SSD, соединённых посредством 10 GBE.
Другие подробности вы можете найти в отчёте.
NFS-доступ
В первую очередь, в IDC протестировали чтение и запись при NFS-доступе. Как и ожидалось, Isilon продемонстрировали ГОРАЗДО более высокие результаты даже при наличии четырёх узлов.
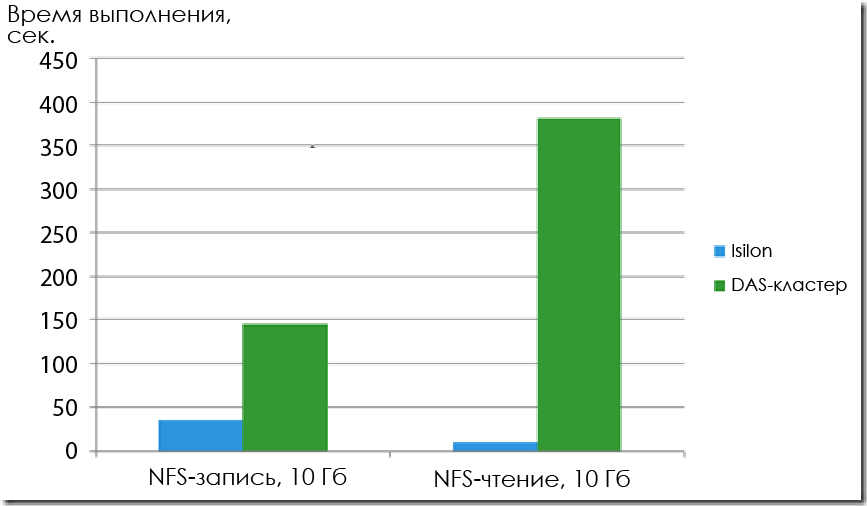
Продолжительность копирования файла размером 10 Гб (длина блока не указана, но вероятнее всего это 1 Мб или больше).
По записи Isilon оказался быстрее в 4,2 раза. Это особенно важно, если важно, если вы хотите получать данные посредством NFS. А по скорости чтения производительность в 37 раз выше.
Рабочая нагрузка Hadoop
В ходе тестирования с помощью стандартных Hadoop-бенчмарков были сравнены три типа рабочей нагрузки:
- Последовательная запись с помощью TeraGen
- Поочерёдная запись/чтение с помощью TeraSort
- Последовательное чтение с помощью TeraValidate

Время выполнения при трёх разных типах нагрузки: TeraGen, TeraSort и TeraValidate.
При записи производительность Isilon оказалась выше в 2,6 раза, а на остальных двух типах — в 1,5 раза выше. Конкретные результаты представлены в таблице:
| Isilon | Hadoop DAS | |
|---|---|---|
| TeraGen | 1681 Мб/сек. | 605 Мб/сек. |
| TeraSort | 642 Мб/сек. | 416 Мб/сек. |
| TeraValidate | 2832 Мб/сек. | 1828 Мб/сек. |
Производительность Isilon- и DAS-кластеров с одинаковыми конфигурациями вычислительных узлов (округлённо).
Данные говорят сами за себя. Давайте теперь посмотрим, каким образом OneFS удалось достичь такого превосходства в производительности по сравнению с DAS-кластером.
Чтение файлов на Isilon
Хотя в DAS-кластере операции ввода-вывода распределяются по всем узлам, каждый отдельный 64-мегабайтный блок обслуживаются лишь каким-то одним узлом. В то же время в Isilon’е рабочая нагрузка делится между узлами более мелкими порциями. Операция чтения состоит здесь из следующих этапов:
- Вычислительный узел запрашивает HDFS-метаданные у службы Name Node, работающей на всех узлах Isilon (без SPoF).
- Служба возвращает IP-адреса и номера блоков каждого из трёх узлов в той же стойке, в которой находится вычислительный узел. Это повышает эффективность локальности (locality) стойки.
- Вычислительный узел запрашивает чтение 64-мегабайтного HDFS-блока у службы Data Node, работающей на первом узле в полученном списке.
- Запрошенный узел через внутреннюю сеть Infiniband собирает все 128-килобайтные Isilon-блоки, составляющие требуемый 64-мегабайтный HDFS-блок. Если эти блоки уже отсутствуют в кэше второго уровня, то они считываются с дисков. Это фундаментальное отличие от DAS-кластера, в котором весь 64-мегабайтный блок считывается с единственного узла. Иными словами, в Isilon-кластере операция ввода-вывода обслуживается гораздо большим количеством дисков и процессоров, чем в DAS-кластере.
- Запрошенный узел возвращается вычислительному узлу полный HDFS-блок.
Запись файлов на Isilon
Когда клиент хочет записать файл в кластер, то приёмом и обработкой файла занимается именно тот узел, к которому подключился клиент.
- Узел создаёт план записи файла, включая расчёт FEC (с точки зрения объёма так получается гораздо экономнее по сравнению с DAS-кластером, в котором обычно создаётся три копии каждого блока для обеспечения сохранности данных).
- Приписанные к этому узлу блоки данных записываются в его NVRAM. Наличие NVRAM-карт является одним преимуществ Isilon’а, в DAS-кластерах их использовать нельзя.
- Блоки данных, приписанные к другим узлам, сначала передаются по сети Infiniband в кэши второго уровня этих узлов, а уже оттуда — в NVRAM.
- Как только в NVRAM всех узлов загружаются соответствующие данные и FEC-блоки, клиент получает подтверждение успешной записи. Это означает, что можно не ожидать записи данных на диски, пока все операции ввода-вывода буферизируются в NVRAM.
- Блоки данных хранятся в кэшах второго уровня каждого из узлов на тот случай, если будут поступать запросы на чтение.
- Затем данные записываются на диски.
Миф о важности локальности дисков для производительности Hadoop
Иногда мы сталкиваемся с возражениями админов, утверждающих, что для высокой производительности Hadoop важна локальность дисков. Но нужно помнить, что изначально Hadoop проектировался для работы в медленных сетях со звездообразной топологией, для которых характерна пропускная способность на уровне 1 Гбит/сек. В подобных условиях остаётся лишь стремиться осуществлять все операции ввода-вывода в рамках конкретного сервера (локальность дисков).
Ряд фактов говорят о том, что локальность дисков не имеет отношения к производительности Hadoop:
I. Быстрые сети уже стали стандартом.
- Сегодня одиночный неблокирующий 10-гигабитный порт коммутатора (полный дуплекс до 2500 Мбит/сек.) имеет более высокую пропускную способность, чем типичная дисковая подсистема с 12 дисками (360 – Мбит/сек).
- Больше нет нужды поддерживать локальность данных ради обеспечения удовлетворительного уровня операций ввода-вывода.
- В Isilon обеспечивается стоечная локальность, а не дисковая, что снижает Ethernet-трафик между стойками.
На этой иллюстрации представлен маршрут операций ввода-вывода. Очевидно, что узким местом являются диски, а не сеть (если это сеть 10 GBE).

Маршрут операции ввода-вывода в DAS-архитектуре. Даже если удвоить количество дисков, они всё равно останутся узким местом. Так что локальность дисков в большинстве случаев не влияет на производительность.
II. Локальность дисков теряется в следующих типичных ситуациях:
- В DAS-кластере с репликацией блоков все узлы выполняет максимальное количество заданий. Это крайне характерно для высоконагруженных кластеров!
- Входящие файлы сжимаются с помощью non-splittable кодеков наподобие gzip.
- «Анализ Hadoop-задач в Facebook доказывает сложность достижения дисковой локальности: лишь 34% зада выполняются на том же узле, где хранятся входные данные.»
- Локальность дисков обеспечивает очень низкую задержку при выполнении операций ввода-вывода, но она имеет очень мало значения при выполнения пакетных заданий наподобие MapReduce.
III. Репликация данных ради повышения производительности
- В высоконагруженных традиционных кластерах высокая степень репликации может быть полезна при работе с файлами, часто используемыми в многочисленных одновременных задачах. Это требуется для обеспечения локальности данных (data locality) и большой скорости параллельного чтения.
- В Isilon не требуется высокая степень репликации, потому что:
- Не нужна локальность данных.
- Операции чтения распределяются по многим узлам с глобальной когерентным кэшем (globally coherent cache), что обеспечивает очень высокую скорость параллельного чтения.
Другие технологии, влияющие на производительность Isilon
OneFS — очень зрелый продукт, который более десяти лет совершенствуется с точки зрения высокой производительности и низкой задержки при мультипротокольном доступе. Вы можете найти в сети массу информации об этом. Я упомяну лишь ключевые моменты:
- Все операции записи буферизируются с помощью резервной NVRAM, что обеспечивает очень высокую производительность.
- В OneFS для ускорения чтения используется кэш первого уровня, глобально когерентный кэш второго уровня и кэши третьего уровня на SSD.
- Можно сконфигурировать шаблоны доступа для всего кластера, для пула или даже на уровне папок. Это позволяет оптимизировать и сбалансировать процедуру предварительной выборки (pre-fetching). Шаблоны могут быть случайными, параллельными или потоковыми.
- Работы с метаданными ускоряется с помощью кэша третьего уровня, либо настраивается отдельно. OneFS хранит все метаданные на SSD.
В заключение
Isilon — это горизонтально-масштабируемое NAS-хранилище с распределённой файловой системой, созданное в расчёте на интенсивные рабочие нагрузки вроде Hadoop. HDFS реализован в виде протокола и служб Name Node и Data Node, доступ к которым обеспечивается на всех узлах. Тестирование производительности, проведённое IDC, показало 2,5-кратное преимущество Isilon-кластера перед DAS-кластером. Благодаря прогрессу в сетевых технологиях, локальность дисков не оказывает влияния на работу Hadoop на Isilon-системе. Помимо производительности, Isilon имеет и ряд других преимуществ, наподобие более эффективного использования дискового пространства и различных возможностей, характерных для корпоративных хранилищ. Более того, вычислительные узлы и узлы хранения можно масштабировать независимо друг от друга. Также вы можете обращаться к одним и тем же данным одновременно из нескольких разных версий и дистрибутивов Hadoop.
ссылка на оригинал статьи https://habrahabr.ru/post/281799/
Добавить комментарий