Производительность считается одним из наиболее важных нефункциональных требований приложения. Если вы читаете эту статью, то, вероятно, используете приложение, например веб-браузер или программу для чтения документов, и понимаете, насколько велико значение производительности. В этой статье я расскажу о производительности приложений и о трех ошибках разработчиков, из-за которых не удается добиться высокой производительности приложений.

Ошибочный подход № 1. Недостаточное понимание технологий разработки
Неважно, какой у вас стаж программирования: возможно, вы лишь недавно окончили школу или обладаете многолетним опытом работы, но когда возникает необходимость разработать программу, то вы, скорее всего, постараетесь найти код, который уже был разработан ранее. Желательно, разумеется, чтобы этот код был на том же языке программирования, который собираетесь использовать и вы.
В этом нет ничего плохого. Такой подход зачастую приводит к ускорению разработки. С другой стороны, при этом вы лишитесь возможности изучить что-либо новое. При использовании такого подхода крайне редко удается выкроить время, чтобы как следует проанализировать код и понять не только алгоритм, но и внутреннюю работу каждой строки кода.
Это один из примеров ситуации, когда мы, разработчики, идем по неверному пути. Впрочем, таких путей немало. К примеру, когда я был моложе и только начинал знакомство с разработкой программного обеспечения, я старался во всем подражать моему начальнику: все, что он делал, казалось мне безупречным и безусловно правильным. Когда мне нужно было что-нибудь сделать, я смотрел, как то же самое делает начальник, и стремился как можно точнее повторить все его действия. Неоднократно бывало, что я просто не понимал, почему его подход работает, но разве это важно? Главное, что все работает!
Есть такой тип разработчиков, которые будут работать как можно упорнее, чтобы решить поставленную перед ними задачу. Как правило, они ищут уже готовые составляющие, компоненты, блоки, собирают все эти кусочки воедино, и готово! Задача выполнена! Такие разработчики редко тратят время, чтобы изучить и понять найденные фрагменты кода, и совершенно не заботятся о таких «второстепенных» вещах, как масштабируемость, удобство в обслуживании или производительность.
Возможен еще один сценарий, в котором они не будут понимать, как именно работает каждый компонент программы: если разработчики никогда не сталкивались с проблемами. Если вы впервые используете какую-либо технологию и у вас возникают затруднения, то вы подробно изучаете эту технологию и в конечном итоге выясняете, как она работает.
Давайте рассмотрим несколько примеров, которые помогут нам понять разницу между пониманием технологии и обычным ее использованием. Поскольку я занимаюсь главным образом разработкой веб-решений на основе .NET*, то об этом и поговорим.
▍JavaScript* и DOM
Рассмотрим приведенный ниже пример кода. Все просто. Код всего лишь обновляет стиль одного элемента в DOM. Проблема (сейчас в современных браузерах эта проблема уже не столь актуальна, но она вполне пригодна для иллюстрации моей мысли) состоит в том, что код обходит дерево DOM три раза. Если код повторяется, а документ при этом достаточно крупный и сложный, производительность приложения ощутимо снизится.

Устранить такую проблему довольно просто. Посмотрите на следующий пример кода. Перед работой с объектом в переменной myField происходит удержание прямой ссылки. Новый код компактнее, его удобнее читать и понимать, и он быстрее работает, поскольку доступ к дереву DOM осуществляется только один раз.

Рассмотрим еще один пример. Этот пример взят отсюда.
На следующем рисунке показаны два равноценных фрагмента кода. Каждый из них создает список с 1000 элементов li. Код справа добавляет атрибут id к каждому элементу li, а код слева добавляет атрибут class к каждому элементу li.

Как видите, вторая часть фрагмента кода просто обращается к каждому из тысячи созданных элементов li. Я измерил скорость в браузерах Internet Explorer* 10 и Chrome* 48: среднее время выполнения кода, приведенного слева, составило 57 мс, а время выполнения кода, показанного справа, — всего 9 мс, существенно меньше. Разница огромна, притом что в данном случае она обусловлена лишь разными способами доступа к элементам.
К этому примеру стоит отнестись крайне внимательно. В этом примере есть еще немало интересных для анализа моментов, например порядок проверки селекторов (здесь это порядок справа налево). Если вы используете jQuery*, то почитайте и про контекст DOM. Сведения об общих принципах производительности селекторов CSS см. здесь.
Заключительный пример — код JavaScript. Этот пример более связан с памятью, но поможет понять, как все работает на самом деле. Излишнее потребление памяти в браузерах приведет к снижению производительности.
На следующем рисунке показано два разных способа создания объекта с двумя свойствами и одним методом. Слева конструктор класса добавляет два свойства в объект, а дополнительный метод добавляется через прототип класса. Справа конструктор добавляет сразу и свойства, и метод.
После создания такого объекта создаются тысячи объектов с помощью этих двух способов. Если сравнить объем памяти, используемой этими объектами, вы заметите разницу в использовании областей памяти Shallow Size и Retained Size в Chrome. Подход, где используется прототип, задействует примерно на 20 % меньше памяти (20 КБ по сравнению с 24 КБ) в области Shallow Size и на 66 % меньше в области Retained Memory (20 КБ по сравнению с 60 КБ).
Для получения дополнительных сведений о характеристиках памяти Shallow Size и Retained Size см. здесь.
Можно создавать объекты, зная, как использовать нужную технологию. Понимая, как та или иная технология работает, вы сможете оптимизировать приложения с точки зрения управления памятью и производительности.

▍LINQ
При подготовке к выступлению на конференции по описываемой теме я решил подготовить пример с серверным кодом. Я решил использовать LINQ*, поскольку LINQ получил широкое распространение в мире .NET для новых разработок и обладает значительным потенциалом для повышения производительности.
Рассмотрим следующий распространенный сценарий. На следующем рисунке показано два функционально равноценных фрагмента кода. Цель кода — создать список всех отделений и всех курсов для каждого отделения в школе. В коде под названием Select N+1 мы выводим список всех отделений, а для каждого отделения — список курсов. Это означает, что при наличии 100 отделений нам потребуется 1 + 100 вызовов к базе данных.

Эту задачу можно решить и иначе. Один из простых подходов показан во фрагменте кода с правой стороны. При использовании метода Include (в этом случае я задействую жестко заданную строку для простоты понимания) будет всего один вызов к базе данных, и этот единственный вызов выдаст сразу все отделения и курсы. В этом случае при выполнении второго цикла foreach все коллекции Courses для каждого отделения уже будут в памяти.
Таким образом, можно повысить производительность в сотни раз, просто избегая подхода Select N+1.
Рассмотрим менее очевидный пример. На приведенном ниже рисунке вся разница между двумя фрагментами кода заключается в типе данных списка назначения во второй строке. Тут вы можете удивиться: разве тип данных назначения на что-нибудь влияет? Если изучить работу этой технологии, то вы поймете: тип данных назначения на самом деле определяет момент, в который выполняется запрос к базе данных. А от этого, в свою очередь, зависит момент применения фильтров каждого запроса.
В примере Code #1, где ожидается тип данных IEnumerable, запрос выполняется непосредственно перед выполнением Take Employee (10). Это означает, что при наличии 1000 сотрудников они все будут получены из базы данных, после чего из них будет выбрано 10.

В примере Code #2 запрос выполняется после выполнения Take Employee (10). Из базы данных при этом извлекается всего 10 записей. В следующей статье подробно поясняются различия при использовании разных типов коллекций.
▍SQL Server
В SQL необходимо изучить множество особенностей, чтобы добиться наивысшей производительности базы данных. Работать с SQL Server непросто: нужно понимать, как используются данные, какие таблицы запрашиваются чаще всего и какими именно полями.
Тем не менее для повышения производительности можно применять и ряд общих принципов, например:
- кластерные либо некластерные индексы;
- правильный порядок инструкций JOIN;
- понимание, когда следует использовать таблицы #temp и таблицы переменных;
- использование представлений либо индексированных представлений;
- использование заранее скомпилированных инструкций.
Для краткости я не буду приводить конкретных примеров, но эти принципы можно использовать, анализировать и оптимизировать.
▍Изменение образа мышления
Итак, как мы, разработчики, должны изменить образ мышления, чтобы избегать ошибочного подхода №1?
- Перестаньте думать: «Я — разработчик интерфейсов» или «Я — разработчик внутреннего кода». Возможно, вы инженер, вы специализируетесь на какой-то одной области, но не используете эту специализацию, чтобы отгораживаться от изучения и других областей.
- Перестаньте думать: «Пусть этим занимается специалист, потому что у него получится быстрее». В современном мире в ходу гибкость, мы должны быть многофункциональными ресурсами, мы должны изучать области, в которых наши знания недостаточны.
- Перестаньте говорить себе: «Я этого не понимаю». Разумеется, если бы это было просто, то все уже давно стали бы специалистами. Не стесняйтесь тратить время на чтение, консультации и изучение. Это нелегко, но рано или поздно окупится.
- Перестаньте говорить: «Мне некогда». Это возражение я могу понять. Так бывает нередко. Но однажды один коллега в Intel сказал: «Если тебе действительно интересно что-либо, то и время на это найдется». Вот эту статью я пишу, например, в субботу в полночь!
Ошибочный подход № 2. Предпочтение определенных технологий
Я занимаюсь разработкой на .NET с версии 1.0. Я в мельчайших подробностях знаю все особенности работы веб-форм, а также множества клиентских библиотек .NET (некоторые из них я самостоятельно изменил). Когда я узнал о выпуске Model View Controller (MVC), то не хотел его использовать: «Это нам не нужно».
Собственно говоря, этот список можно продолжать довольно долго. Я имею в виду список вещей, которые сначала мне не понравились и которыми сейчас я часто и уверенно пользуюсь. Это лишь один из примеров ситуации, когда разработчики склоняются в пользу одних технических решений и избегают других, что мешает добиваться более высокой производительности.
Мне часто приходится слышать обсуждения, касающиеся либо связи LINQ с объектами в Entity Framework, либо хранимых процедур SQL при запросе данных. Люди настолько привыкли использовать одно или другое решение, что пытаются использовать их везде.
Еще один фактор, влияющий на предпочтения разработчиков (преимущественный выбор одних технологий и отказ от других), — личное отношение к ПО с открытым исходным кодом. Разработчики зачастую выбирают не то решение, которое лучше всего подходит для текущей ситуации, а то, которое лучше согласуется с их жизненной философией.
Иногда внешние факторы (например, жесткие сроки) вынуждают нас принимать неоптимальные решения. Для выбора наилучшей технологии требуется время: нужно читать, пробовать, сравнивать и делать выводы. При разработке нового продукта или новой версии существующего продукта часто бывает, что мы уже опаздываем: «Крайний срок — вчера». Два очевидных выхода из такой ситуации: затребовать дополнительное время или работать сверхурочно для самообразования.
▍Изменение образа мышления
Как мы, разработчики, должны изменить образ мышления, чтобы избегать ошибочного подхода №2.
- Перестаньте говорить: «Этот способ всегда работал», «Мы всегда делали именно так» и т. д. Нужно знать и использовать и другие варианты, особенно если эти варианты в чем-то лучше.
- Не пытайтесь использовать неподходящие решения! Бывает, что разработчики упорно пытаются применять какую-то определенную технологию, которая не дает и не может дать нужных результатов. Разработчики тратят много времени и сил, стараясь все же как-то доработать эту технологию, подогнать её под результат, не рассматривая иных вариантов. Такой неблагодарный процесс можно назвать «попыткой натянуть сову на глобус»: это стремление ценой любых усилий приспособить существующее неподходящее решение вместо того, чтобы сосредоточиться на проблеме и отыскать другое, более изящное и быстрое решение.
- «Мне некогда». Разумеется, у нас всегда не хватает времени на изучение нового. Это возражение я могу понять.
Ошибочный подход № 3. Недостаточное понимание инфраструктуры приложения
Итак, мы приложили немало усилий и создали самое лучшее приложение. Пора перейти к его развертыванию. Мы все протестировали. На наших машинах все превосходно работает. Все 10 тестировщиков были полностью довольны и самим приложением, и его производительностью.
Следовательно, теперь уж точно никаких проблем не может возникнуть, все в полнейшем порядке?
Отнюдь, все может быть вовсе не в порядке!
Задали ли вы себе следующие вопросы?
- Пригодно ли приложение для работы в среде с балансировкой нагрузки?
- Приложение будет размещено в облаке, где будет много экземпляров этого приложения?
- Сколько других приложений работают на машине, для которой предназначено мое приложение?
- Какие еще программы выполняются на этом сервере? SQL Server? Службы Reporting Services? Какие-либо расширения SharePoint*?
- Где находятся конечные пользователи? Они распределены по всему миру?
- Сколько пользователей будет у моего приложения в течение следующих пяти лет?
Я понимаю, что не все эти вопросы относятся непосредственно к инфраструктуре, но всему свое время. Как правило, итоговые фактические условия, в которых наше приложение будет работать, отличаются от условий на серверах на промежуточном этапе.
Давайте рассмотрим несколько возможных факторов, которые могут повлиять на производительность нашего приложения. Предположим, что пользователи находятся в разных странах мира. Быть может, приложение будет работать очень быстро, без каких-либо жалоб со стороны пользователей в США, но вот пользователи из Малайзии будут жаловаться на низкую скорость.
Решать подобные проблемы можно разными способами. Например, можно использовать сети распространения данных (CDN) и разместить в них статические файлы. После этого загрузка страниц у пользователей, находящихся в разных местах, будет происходить быстрее. То, о чем я говорю, показано на следующем рисунке.
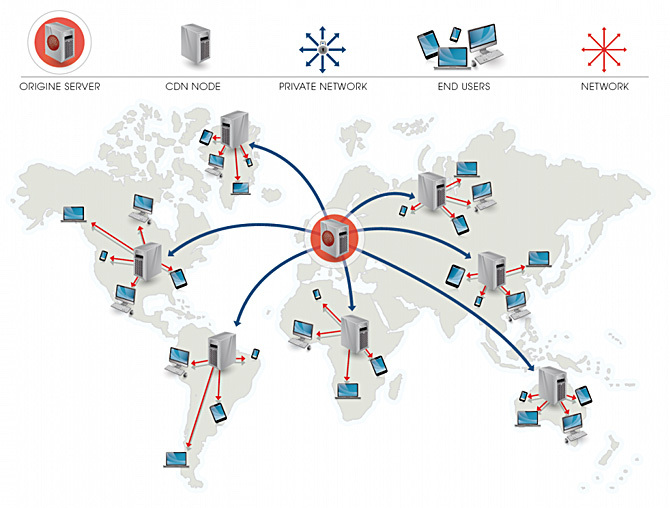
Возможна еще одна ситуация: предположим, что приложения работают на серверах, на которых одновременно запущена СУБД SQL Server и веб-сервер. В этом случае на одном физическом сервере выполняются одновременно две серверных системы с интенсивной нагрузкой на ЦП. Как решить эту проблему? Если мы говорим о приложении .NET на сервере Internet Information Services (IIS), то можно воспользоваться соответствием процессоров. Соответствие процессоров — это привязка одного процесса к одному или нескольким определенным ядрам ЦП компьютера.
К примеру, предположим, что на компьютере с четырьмя процессорами выполняется SQL Server и веб-сервер IIS.

Если позволить операционной системе решить, какой ЦП будет использоваться для SQL Server, а какой — для IIS, ресурсы могут распределяться по-разному. Возможно, что каждой серверной нагрузке будет назначено по два процессора.

А возможно, что все четыре процессора будут выделены только одной нагрузке.

В этом случае может возникнуть взаимная блокировка: IIS может обслуживать слишком много запросов и займет все четыре процессора, при этом для некоторых запросов может потребоваться доступ к SQL, который в этом случае будет невозможен. На практике такой сценарий маловероятен, но он прекрасно иллюстрирует мою мысль.
Еще одна возможная ситуация: один процесс не будет все время работать на одном и том же ЦП. Будет часто возникать переключение контекста. Частое переключение контекста приведет к снижению производительности сначала самого сервера, а затем и приложений, работающих на этом сервере.
Один из способов решить эту проблему — использовать «соответствие процессоров» для IIS и SQL. В этом случае мы сами решаем, сколько процессоров нужно для SQL Server, а сколько — для IIS. Для этого нужно настроить параметры в разделе «Соответствие процессоров» в категории ЦП в IIS и «маску соответствия» в базе данных SQL Server. Оба этих случая показаны ниже.
| ЦП | |
|---|---|
| Ограничение (проценты) | 0 |
| Действие ограничения | Действие отсутствует |
| Период ограничения (минут) | 5 |
| Соответствие процессоров разрешено | False |
| Маска соответствия процессоров | 4294967295 |
| Маска соответствия процессоров (64-разрядная версия) | 4294967295 |

Эту тему можно продолжать и дальше с другими особенностями инфраструктуры, относящимися к повышению производительности, например при использовании веб-ферм.
▍Изменение образа мышления
Как мы, разработчики, должны изменить образ мышления, чтобы избегать ошибочного подхода №3?
- Перестаньте думать: «Это не моя работа». Мы, инженеры, должны стремиться расширять кругозор, чтобы предоставлять заказчикам наилучшее решение.
- «Мне некогда». Разумеется, нам всегда некогда. Это самое распространенное обстоятельство. Выделение времени — то, что отличает успешного, опытного, выдающегося профессионала.
▍Не оправдывайтесь!
Вам не в чем себя упрекнуть. Не все зависит только от вас. Действительно бывает некогда. У всех семьи, у всех хобби, всем нужно отдыхать.
Но важно понимать, что хорошая работа — это не только написание хорошего кода. Мы все в определенное время использовали некоторые или все описанные ошибочные подходы.
Вот как их можно избежать.
- Выделяйте время, если нужно — с запасом. Когда у вас просят оценить сроки, необходимые для работы над проектом, не забудьте выделить время для исследования и тестирования, для подготовки выводов и принятия решений.
- Постарайтесь одновременно создать и личное приложение для тестирования. В этом приложении вы сможете пробовать разные решения перед их воплощением (или отказом от их воплощения) в разрабатываемом приложении. Мы все порой ошибаемся.
- Найдите людей, уже владеющих нужной технологией, и попробуйте программировать вместе. Поработайте со специалистом, который разбирается в инфраструктуре, когда он будет развертывать приложение. Это время будет потрачено с пользой.
- Избегайте переполнения стека! Большая часть моих проблем уже решена. Если просто копировать ответы, не анализируя их, вы в итоге получите неполное решение.
- Не считайте себя узким специалистом, не ограничивайте свои возможности. Разумеется, если вам удастся стать экспертом в какой-либо области, это замечательно, но вы должны уметь поддержать разговор на должном уровне и в том случае, если разговор касается областей, в которых вы пока не являетесь экспертом.
- Помогайте другим! Это, пожалуй, один из лучших способов обучения. Если вы помогаете другим решать их проблемы, то в конечном итоге вы сэкономите собственное время, поскольку уже будете знать, что делать, если столкнетесь с подобными проблемами.
Дополнительные сведения об оптимизации компиляторов см. в нашем уведомлении об оптимизации.
ссылка на оригинал статьи https://habrahabr.ru/post/281823/
Добавить комментарий