
На прошлой неделе в компании Clarifai мы формально анонсировали нашу модель распознавания непристойного контента (NSFW, Not Safe for Work).
Предупреждение и отказ от ответственности. Эта статья содержит изображения обнажённых тел в научных целях. Мы просим не читать дальше тех, кому не исполнилось 18 лет или кого оскорбляет нагота.
Автоматическое выявление обнажённых фотографий было центральной проблемой компьютерного зрения на протяжении более двух десятилетий, и из-за своей богатой истории и чётко поставленной задачи она стала отличным примером того, как развивалась технология. Я использую проблему детектирования непристойности для пояснения, как обучение современных свёрточных сетей отличается от исследований, проводившихся в прошлом.
В далёком 1996 году…

Одна из первых работ в этой области имела простое и понятное название: «Поиск обнажённых людей», авторы Маргарет Флек и др. Она была опубликована в середине 90-х и представляет собой хороший пример того, чем занимались специалисты по компьютерному зрению до массового распространения свёрточных сетей. В части 2 научной статьи они приводят обобщённое описание техники:
Алгоритм:
- Сначала найти изображения с большими областями пикселов телесного цвета.
- Затем в этих областях найти удлинённые области и сгруппировать их в возможные человеческие конечности или объединённые группы конечностей, используя специализированные модули группировки, которые вмещают значительный объём информации о структуре объекта.
Обнаружение кожи осуществлялось путём фильтрации цветового пространства, а группировка регионов кожи происходило с помощью моделирования человеческой фигуры как «набора почти цилиндрических частей, где индивидуальные очертания частей и соединения между частями ограничены геометрией скелета (раздел 2). Более понятной методы разработки такого алгоритма становятся, если изучить иллюстрацию 1 в научной статье, где авторы показали некоторые правила группировки, составленные вручную.
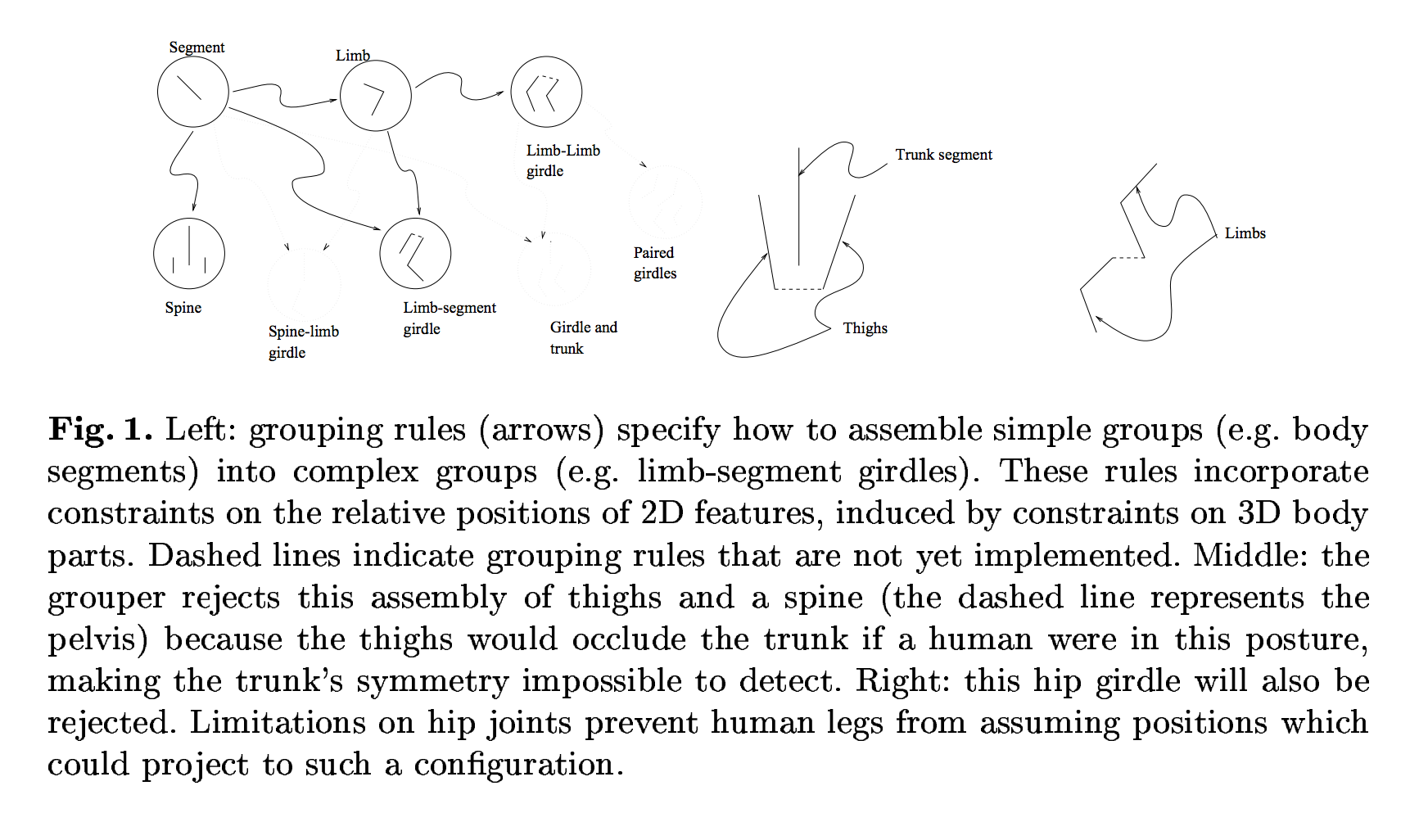
В научной статье говорится о «точности распознавания 60% и полноте (recall) 52% на неконтролируемой выборке из 138 изображений обнажённых людей». Авторы также показывают примеры корректно распознанных изображений и ложных срабатываний с визуализацией тех областей, которые обрабатывал алгоритм.


Главная проблема при составлении правил вручную — это то, что сложность модели ограничена терпением и воображением исследователей. В следующей части мы увидим, как свёрточная нейросеть, обученная для выполнения той же задачи, демонстрирует намного более сложное представление тех же данных.
Теперь в 2014 году…
Вместо изобретения формальных правил для описания, как должны быть представлены входные данные, исследователи в области глубинного обучения придумывают сетевые архитектуры и наборы данных, которые позволят системе ИИ освоить эти представления напрямую из данных. Однако из-за того, что исследователи не указывают точно, как должна реагировать сеть на заданные входные данные, возникает новая проблема: как понять, на что конкретно реагирует нейросеть?

Для понимания действий свёрточной нейросети нужно интерпретировать активность признака на различных уровнях. В остальной части статьи мы изучим раннюю версию нашей модели NSFW, подсвечивая активность с верхнего уровня вниз до уровня пиксельного пространства на входе. Это позволит увидеть, какие конкретно шаблоны на входе вызвали определённую активность на карте признаков (то есть почему, собственно, изображение помечено как "NSFW").
Чувствительность к заслону
Иллюстрация внизу показывает фотографии Лены Сёдерберг после применения скользящих окон 64х64 с шагом 3 нашей модели NSFW к обрезанным/заслонённым версиям исходного изображения.

Чтобы построить теплокарту слева, мы отправляли каждое окно в нашу свёрточную нейросеть и усредняли оценку "NSFW" для каждого пиксела. Когда нейросеть встречается с фрагментом, заполненным кожей, то склонна оценивать его как "NSFW", что приводит к появлению больших красных областей на теле Лены. Для создания теплокарты справа мы систематически заслоняли части исходного изображения и отмечали -1 как оценку "NSFW" (то есть оценку "SFW"). Когда большинство регионов NSFW закрыто, оценка "SFW" возрастает, и мы видим более высокие значения на теплокарте. Для ясности, вот примеры изображений, которые мы отдавали в свёрточную нейросеть для каждого из двух экспериментов вверху.

Одной из замечательных особенностей этих экспериментов является то, что их можно проводить даже если классификатор — абсолютный «чёрный ящик». Вот фрагмент кода, который воспроизводит эти результаты через наши API:
# NSFW occlusion experiment from StringIO import StringIO import matplotlib.pyplot as plt import numpy as np from PIL import Image, ImageDraw import requests import scipy.sparse as sp from clarifai.client import ClarifaiApi CLARIFAI_APP_ID = '...' CLARIFAI_APP_SECRET = '...' clarifai = ClarifaiApi(app_id=CLARIFAI_APP_ID, app_secret=CLARIFAI_APP_SECRET, base_url='https://api.clarifai.com') def batch_request(imgs, bboxes): """use the API to tag a batch of occulded images""" assert len(bboxes) < 128 #convert to image bytes stringios = [] for img in imgs: stringio = StringIO() img.save(stringio, format='JPEG') stringios.append(stringio) #call api and parse response output = [] response = clarifai.tag_images(stringios, model='nsfw-v1.0') for result,bbox in zip(response['results'], bboxes): nsfw_idx = result['result']['tag']['classes'].index("sfw") nsfw_score = result['result']['tag']['probs'][nsfw_idx] output.append((nsfw_score, bbox)) return output def build_bboxes(img, boxsize=72, stride=25): """Generate all the bboxes used in the experiment""" width = boxsize height = boxsize bboxes = [] for top in range(0, img.size[1], stride): for left in range(0, img.size[0], stride): bboxes.append((left, top, left+width, top+height)) return bboxes def draw_occulsions(img, bboxes): """Overlay bboxes on the test image""" images = [] for bbox in bboxes: img2 = img.copy() draw = ImageDraw.Draw(img2) draw.rectangle(bbox, fill=True) images.append(img2) return images def alpha_composite(img, heatmap): """Blend a PIL image and a numpy array corresponding to a heatmap in a nice way""" if img.mode == 'RBG': img.putalpha(100) cmap = plt.get_cmap('jet') rgba_img = cmap(heatmap) rgba_img[:,:,:][:] = 0.7 #alpha overlay rgba_img = Image.fromarray(np.uint8(cmap(heatmap)*255)) return Image.blend(img, rgba_img, 0.8) def get_nsfw_occlude_mask(img, boxsize=64, stride=25): """generate bboxes and occluded images, call the API, blend the results together""" bboxes = build_bboxes(img, boxsize=boxsize, stride=stride) print 'api calls needed:{}'.format(len(bboxes)) scored_bboxes = [] batch_size = 125 for i in range(0, len(bboxes), batch_size): bbox_batch = bboxes[i:i + batch_size] occluded_images = draw_occulsions(img, bbox_batch) results = batch_request(occluded_images, bbox_batch) scored_bboxes.extend(results) heatmap = np.zeros(img.size) sparse_masks = [] for idx, (nsfw_score, bbox) in enumerate(scored_bboxes): mask = np.zeros(img.size) mask[bbox[0]:bbox[2], bbox[1]:bbox[3]] = nsfw_score Asp = sp.csr_matrix(mask) sparse_masks.append(Asp) heatmap = heatmap + (mask - heatmap)/(idx+1) return alpha_composite(img, 80*np.transpose(heatmap)), np.stack(sparse_masks) #Download full Lena image r = requests.get('https://clarifai-img.s3.amazonaws.com/blog/len_full.jpeg') stringio = StringIO(r.content) img = Image.open(stringio, 'r') img.putalpha(1000) #set boxsize and stride (warning! a low stride will lead to thousands of API calls) boxsize= 64 stride= 48 blended, masks = get_nsfw_occlude_mask(img, boxsize=boxsize, stride=stride) #viz blended.show()Хотя такие эксперименты позволяют легко увидеть результат работы классификатора, у них есть недостаток: сгенерированные визуализации часто довольно расплывчаты. Это мешает по-настоящему понять, что в реальности делает нейросеть и понять, что может пойти неправильно во время её обучения.
Развёртывающие нейронные сети (Deconvolutional Networks)
После обучения сети на заданном наборе данных нам бы хотелось взять изображение и класс, и спросить у нейросети что-нибудь вроде «Как мы можем изменить это изображение, чтобы оно лучше соответствовало заданному классу?». Для такого мы используем развёртывающую нейросеть, как описано в разделе 2 вышеупомянутой научной статьи Зайлера и Фергуса 2014-го года:
Развёртывающую нейросеть можно представить как свёрточную нейросеть, которая использует такие же компоненты (фильтрация, пулинг), но наоборот, так что вместо отображения пикселов для признаков она делает противоположное. Для изучения конкретной активации свёрточной нейросети, мы устанавливаем все остальные активации в этом слое на ноль и пропускаем карты признаков как входящие параметры к присоединённому слою развёртывающей нейросети. Потом мы успешно производим 1) анпулинг; 2) исправление и 3) фильтрацию, чтобы восстановить активность в нижнем слое, который породил выбранную активацию. Потом процедура повторяется до тех пор, пока мы не дойдём до исходного пиксельного слоя.
[…]
Процедура похожа на обратное распространение одной сильной активации (в отличие от обычных градиентов), например, вычисление
, где
— это элемент карты признаков с сильной активацией, а
— исходное изображение.
Вот результат, полученный от развёрточной нейросети, которой дали задание показать необходимые изменения на фотографии Лены, чтобы она больше походила на порнографию (примечание: используемая здесь развёрточная нейросеть работает только с квадратными изображениями, так что мы дополнили фотографию Лены до квадрата):

Барбара — более пристойная версия Лены. Если верить нейросети, это можно исправить, добавив красного цвета на губы.

Следующий кадр с Урсулой Андресс в роли Хани Райдер из фильма «Доктор Ноу» с Джеймсом Бондом, занял первое место в опросе 2003 года на «самый сексуальный момент в истории кинематографа».
Выдающийся результат вышеописанных экспериментов состоит в том, что нейросеть смогла понять, что красные губы и пупки — это индикаторы "NSFW". Скорее всего, это означает, что мы не включили достаточное количество изображений красных губ и пупков в наш обучающий набор данных "SFW". Если бы мы оценивали нашу модель только изучая точность/полноту и кривые ROC (показаны внизу, набор тестовых изображений: 428 271), мы бы никогда не обнаружили этот факт, потому что у нашей тестовой выборки такой же недостаток. Это показывает фундаментальную разницу между классифакторами на основе правил и современными исследованиями ИИ. Вместо переработки признаков вручную, мы перекраиваем набор данных, пока признак не улучшится.

В конце концов, для проверки надёжности, мы запустили развёрточную нейросеть на хардкорной порнографии, чтобы убедиться, что усвоенные признаки действительно соответствуют объектам, которые очевидно относятся к NSFW.

Здесь мы ясно видим, что свёрточная нейросеть правильно усвоила объекты «пенис», «анус», «влагалище», «сосок» и «ягодицы» — те объекты, которая наша модель должна распознавать. Более того, обнаруженные признаки гораздо более подробны и сложны, чем могут вручную описать исследователи, и это объясняет тот значительный успех, которого мы добились при использовании свёрточных нейросетей для распознавания непристойных фотографий.
ссылка на оригинал статьи https://habrahabr.ru/post/282071/
Добавить комментарий