Последние полгода всем знакомый интерфейс поисковой выдачи Яндекса (Search Engine Result Page — SERP) переезжает на новую архитектуру, с которой разработка неспецифичных фич становится очень быстрой, а разработка специфичных фич — прогнозируемой. Для большой распределенной команды из 40 фронтендеров это большой успех. Когда все было почти готово и новый код начали обкатывать в production экспериментах, оказалось, что серверная JS-шаблонизация в новой архитектуре ощутимо замедлилась.

Новый код был проще и логичнее скомпонован, поэтому замедление было не только нежелательным, но и неожиданным. Чтобы получить «зеленый свет» для новой архитектуры, нужно было ускорить код, чтобы он работал как минимум не медленнее старого.
Простым «разглядыванием» проблему решить не удалось, нужно было разбираться, нужно было профилировать. Читайте дальше, чтобы узнать, как это было сделано.
Наша кухня
SERP написан на БЭМ. Серверная шаблонизация написана на JS и состоит из двух частей:
- код, преобразующий данные бэкенда в BEMJSON страницы (дерево блоков, элементов и модификаторов) — это PRIV-шаблонизация;
- код, превращающий BEMJSON в HTML — это BEMHTML-шаблонизация.
Вторую часть мы никак не затрагивали, архитектура заменялась в первой.
Сейчас в PRIV-шаблонизации BEMJSON генерируется для трех платформ – десктопов, планшетов и телефонов. Замедление коснулось только первых двух платформ.
PRIV-код — это большое количество функций в глобальной области видимости. Функции именуются по БЭМ и лежат в разных файликах, а в процессе сборки собираются в один файл.
Например:
// функция-блок blocks[‘my-block’] = function(arg1, arg2) { /* ... */ } // функция-элемент – может быть обычным хелпером // или может генерировать часть ответа функции-блока blocks[‘my-block__elem’] = function(arg1, arg2) { /* ... */ }
Раньше блоки-функции были равноправны и не включались ни в какую иерархию. Просто одни блоки были низкоуровневыми и собственно генерировали BEMJSON, а другие были высокоуровневыми — звали блоки уровнем ниже.
В новой архитектуре у блоков появились роли с фиксированным интерфейсом. Блоки стали объединяться в уровни абстракции, формируя конвейер переработки исходных данных в итоговый BEMJSON.
Перед началом
Беглый поиск показал, что универсального профилятора JS-кода нет и сама тема освещена мало. Пришлось разбираться в методах на ходу, попутно формируя собственное мнение о них.
Расскажем о профилировании серверного JS-кода, перебирая методы от простых к сложным. Замечание: мы работали исключительно в Node.JS 4.2.2.
GUI-подход. Chromium
Самый простой и, казалось бы, наглядный инструмент — это профилятор, встроенный в браузеры Chromium, который можно использовать с помощью модуля node-inspector.
В результате работы профилятора мы получаем три представления собранных результатов:
- Top-Down;
- Bottom-Up;
- Chart.
Все три представляют собой разные способы отображения полного дерева вызовов выполненного кода. В первом случае дерево строится сверху вниз, во втором — снизу вверх, в третьем — посмотрим на примере.
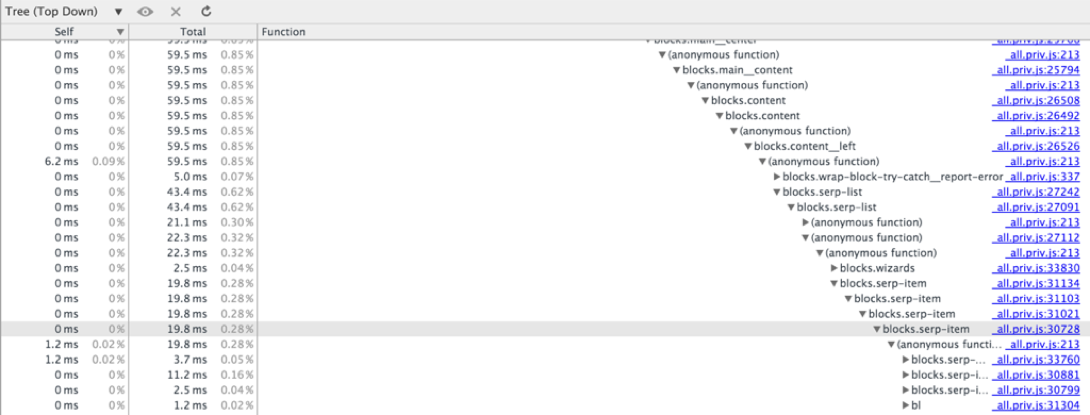
↑ Top-Down позволяет отслеживать время выполнения только тех вызовов функций, которые находятся на небольшой глубине стека вызовов. Проблема в отсутствии возможности горизонтальной прокрутки. В нашем случае при высоте дерева 182 удалось дойти до вызовов на глубине 37, остальное осталось скрыто за правым краем экрана.
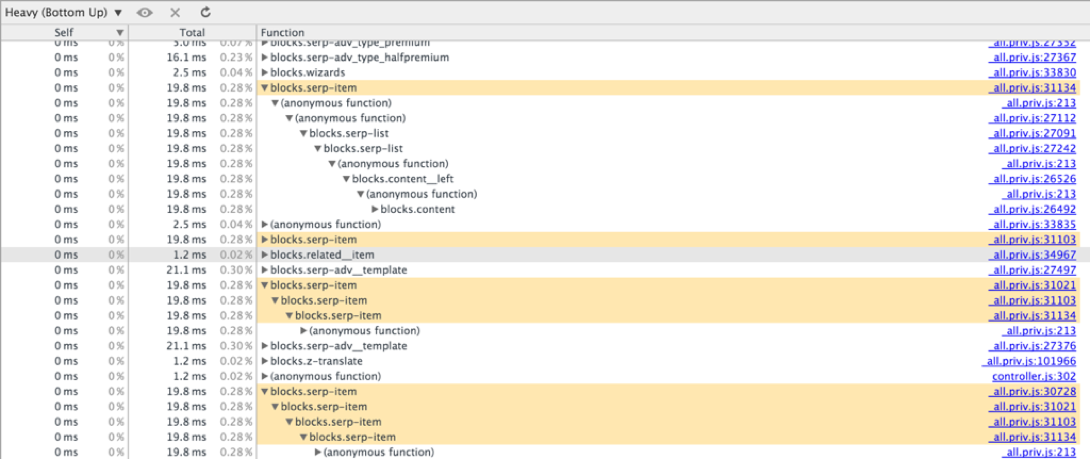
↑ Bottom-Up не требует горизонтальной прокрутки, так как можно начать просмотр дерева «с любого места». Если начали с вызова функции F, поднялись по дереву до вызова функции G и уперлись в край экрана — находим отдельно вызов G и продолжаем движение. Благо есть поиск по имени функции. Но здесь не отображаются функции, суммарное время выполнения которых оказалось меньше некоторой константы.
Если не удалось найти функцию в Bottom-Up, то она выполнялась совсем мало времени, или, что тоже бывает, ее заинлайнили при компиляции.
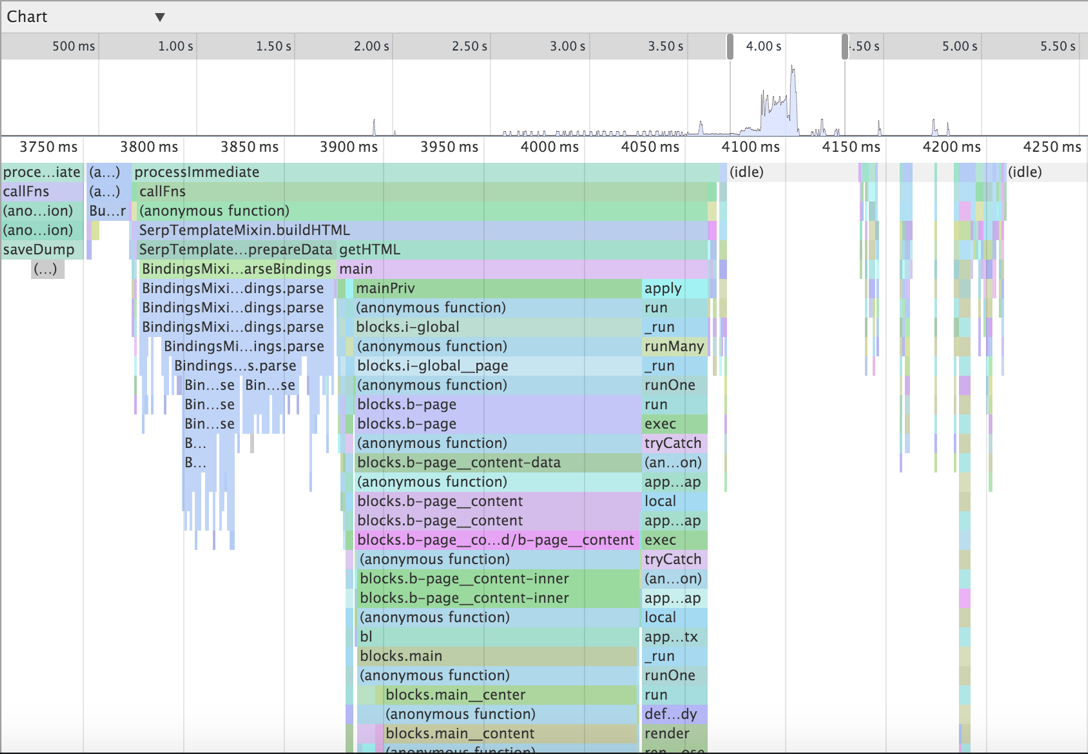
↑ Chart рисует дерево вызовов привязанным к оси времени с возможностью изменения масштаба и только горизонтальной прокруткой. Здесь мы видели вызовы на глубине 32, остальное уходило за нижний край экрана.
GUI-подход. WebStorm
Chromium & node-inspector — не единственный вариант GUI-профилятора, например, WebStorm предлагает аналогичную функциональность:
Run → Edit Configurations… → конфигурация Node.js → вкладка V8 Profiling
Здесь четыре способа отображения дерева вызовов:
- Top Calls;
- Flame chart;
- Bottom-up;
- Top-down.
Отметим сразу, что здесь можно управлять порогом фильтрации функций по времени исполнения (можно совсем не фильтровать).
Top Calls в нашем случае не показывал ничего, кроме времени выполнения shared libraries (bin/node, libsystem_kernel, libsystem_malloc, libsystem_c и libstdc++).
Flame chart похож на Charts из Chromium, только непонятный и как будто бесполезный. Масштабировать картинку, чтобы разглядеть хоть какие-то вызовы и их вложенность, не удалось.
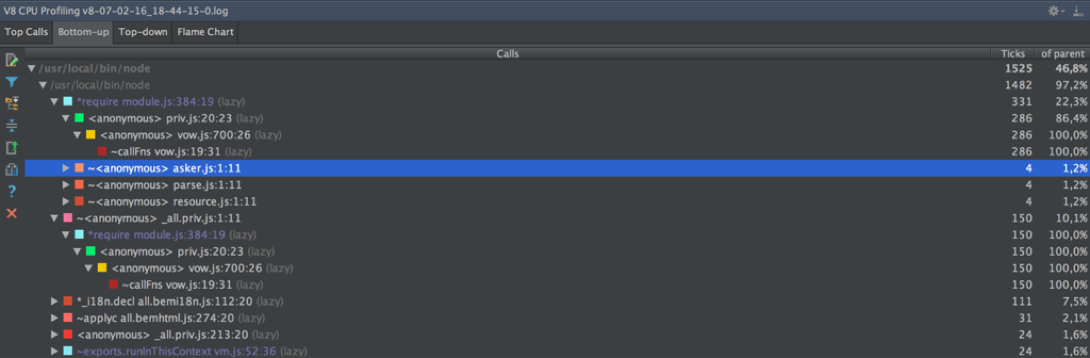
↑ Bottom-up напоминает аналогичный режим из Chromium, только здесь нет поиска и структура немного отличается. Без поиска по именам функций этим пользоваться невозможно.
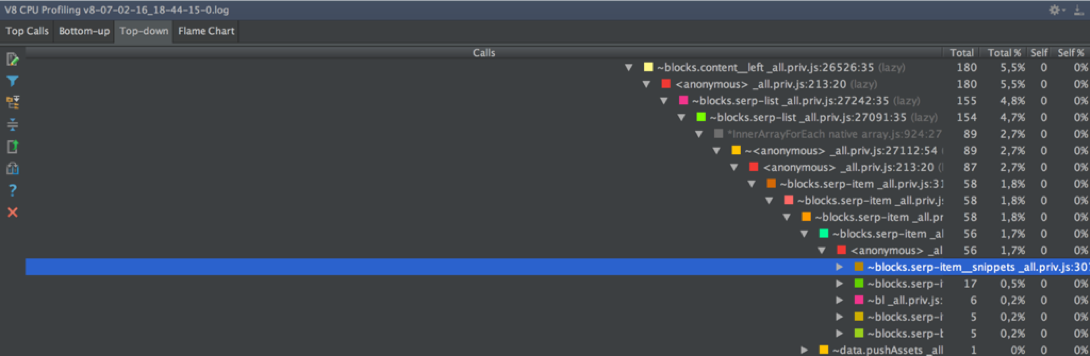
↑ Top-down страдает тем же отсутствием горизонтальной прокрутки, что и Chromium в аналогичной ситуации. Посмотреть, какие функции выполнялись ниже 37 уровня вложенности, не получается. Причем здесь стек более подробный, он включает не только JS-вызовы, но и внутренности языка (ArrayForEach, InnerArrayForEach, Module._compile, Module._load и прочие).
GUI-вывод
Из рассмотренных способов GUI-профилирования наиболее удобным кажется сбор данных через node-inspector & Chromium и их анализ в виде Bottom-Up представления полного дерева вызовов с возможностью поиска.
Остальные методы и решения могут быть с удобством использованы при высоте дерева вызовов не больше 30.
Как бы то ни было, все эти способы не подходят для профилирования серверного кода. Недостаточно запустить node-inspector, включить запись CPU-профиля, сделать пару запросов и начать анализировать данные. Нужна репрезентативная выборка характерных запросов и не только суммарное время выполнения функций, но и прочие показатели — среднее время, медиана, разные перцентили. Нужен управляемый эксперимент.
Теория профилирования
Существует два базовых подхода к профилированию: instrumentation- и sampling-профилирование.
При instumentation-профилировании мы изменяем профилируемый код, дополняя его логированием всех вызовов функций со временем их выполнения. Этот метод собирает детальную, но немного искаженную информацию, потому что в итоге профилируется не исходный код, а измененный — с логированием.
При sampling-профилировании профилируемый код не меняется, но исполняющая система периодически приостанавливает его выполнение и логирует текущий снимок стека вызовов. Суть этого метода рассмотрим позднее на примере.
Управляемый эксперимент №1.
Instrumentation-подход
Данный подход очень органично реализуется в нашем случае, когда весь код — это набор функций. Все делается за пару шагов.
Хелпер для записи времени в наносекундах с помощью process.hrtime (миллисекунд Date будет не достаточно):
function nano() { var time = process.hrtime(); return time[0] * 1e9 + time[1]; }
Обертка, запускающая исходную функцию и логирующая время ее выполнения:
function __profileWrap__(name, callback, args) { var startTime = nano(), result = callback.apply(ctx, args), time = nano() - startTime; logStream.write(name + ',' + time + '\n'); return result; }
Собственно оборачивающий код:
Object.keys(blocks).forEach(function(funcName) { var base = blocks[funcName]; if (typeof base === 'function') { blocks[funcName] = function() { return __profileWrap__(funcName, base, arguments); }; } });
Все просто.
Но в такой реализации рекурсивные вызовы обрабатывались неправильно. Например, такой случай косвенной рекурсии:
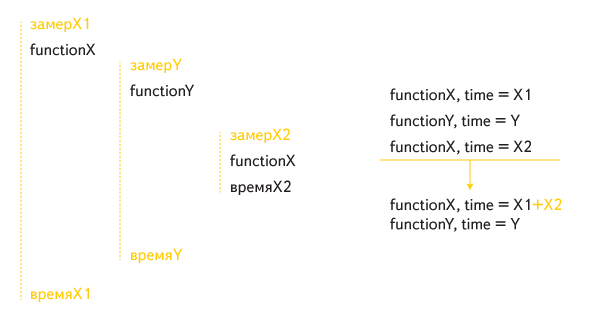
Суммарное время выполнения функции X включало внутренний ее вызов дважды: один раз как часть времени работы внешнего вызова, а второй раз отдельно.
Для правильной обработки рекурсивных вызовов, потребовалась правка:
function __profileWrap__(name, callback, args) { if (called[name]) return callback.apply(ctx, args); called[name] = true; // запоминаем контекст var startTime = nano(), result = callback.apply(ctx, args), time = nano() - startTime; delete called[name]; logStream.write(name + ',' + time + '\n'); return result; }
Кроме того, добавили в профилируемый код запись в лог маркера, означающего конец обработки одного запроса. Маркер поможет сопоставить записи лога с конкретными запросами, чтобы считать разные интересующие нас метрики.
Чтобы обработать лог для вычисления, например, медиан времени выполнения функций, потребуется такой код:
var requests = [], currentRequest = {}; function getMedians() { var funcTime = {}; requests.forEach(function(request) { Object.keys(request).forEach(function(funcName) { // группируем все замеры по имени функции (funcTime[funcName] = funcTime[funcName] || []).push(request[funcName]); }); }); Object.keys(funcTime).forEach(function(funcName) { var arr = funcTime[funcName], value; // нормализируем while (arr.length < requests.length) arr.push(0); // считаем медиану value = median(arr); if (value > 0) { // заменяем массив замеров на медиану funcTime[funcName] = value; } else { // нули не показываем delete funcTime[funcName]; } }); return funcTime; } function writeResults() { var funcMedians = getMedians(); // напечатаем результаты по убыванию медиан времени выполнения // в формате: <имя функции> <табуляция> <медиана времени в мс> console.log( Object .keys(funcMedians) .sort(function(funcNameA, funcNameB) { return funcMedians[funcNameB] - funcMedians[funcNameA]; }) .map(function(funcName) { return funcName + '\t' + nano2milli(funcMedians[funcName]); }) .join('\n'); ); } function processLine(parsedLine, isItLast) { if (parsedLine.isMarker) { requests.push(currentRequest); currentRequest = {}; } else { // суммарные данные по одному GET-запросу currentRequest[parsedLine.funcName] = (currentRequest[parsedLine.funcName] || 0) + parsedLine.time; } if (isItLast) writeResults(); } // далее запуск парсера логов с вызовом processLine(...) для каждой строки
Обстреляв сервер тысячей запросов, мы выявили блоки, из-за которых все тормозило. Но на этом не хотелось останавливаться — результаты нужно было подтвердить другим подходом.
На пути к управляемому эксперименту №2.
Sampling-профилирование из коробки
Известно, что Node.JS из коробки поддерживает этот вид профилирования. Достаточно запустить приложение с нужными параметрами, и данные будут собраны в указанный файл:
node --prof —logfile=v8.log my_app.js
man node — содержит еще много интересных опций.
Лог выглядит так:

Заметим сразу, что логирование не синхронизировано, при профилировании многопоточного кода мы получали «слепленные» строки. Обнаружив это, мы отключили на время тестов в своем проекте слой, организующий многопоточную работу PRIV-кода.
В процессе поиска ответа на вопрос, как прочитать лог, удалось найти модуль node-tick-processor. Этот модуль парсит лог и выводит в консоль уже знакомое нам полное дерево вызовов отработавшей программы в двух видах — bottom-up и top-down, только время исполнения для каждой функции считается не миллисекундах, а в тиках.
Нам захотелось узнать подробности работы алгоритма tick-processor-а и ответить на вопросы:
- Как строится дерево вызовов?
- Что значат тики?
- Почему тики, а не миллисекунды?
Сразу установили, что исходные файлы tick-processor-а — это файлы из v8/tools.
Парсинг лога происходит так.
Лог — это csv-файл, каждая строка — это команда с параметрами. Основные команды это:
- команды, привязывающие фрагменты кода к адресам (shared-library, code-creation, code-move);
- команда tick, соответствующая снимку стека (частота тиков задается опцией node —cpu_profiler_sampling_interval, по умолчанию 1 мс).
Фрагменты кода — это либо фрагменты C-кода (static или shared), либо фрагменты JS-кода (dynamic). Все фрагменты хранятся в трех splaytree-структурах соответственно.
Tick-строчки устроены так:
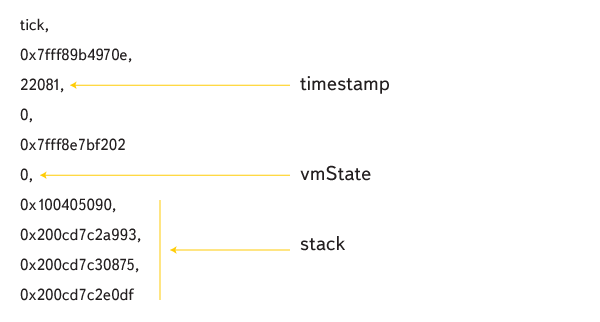
timestamp соответствует времени тика, vmState — состояние виртуальной машины (0 — выполнение JS), далее идет стек из адресов. С помощью splaytree-структур восстанавливаются имена функций в стеке.
Все полученные таким образом стеки склеиваются, составляя полное дерево вызовов:
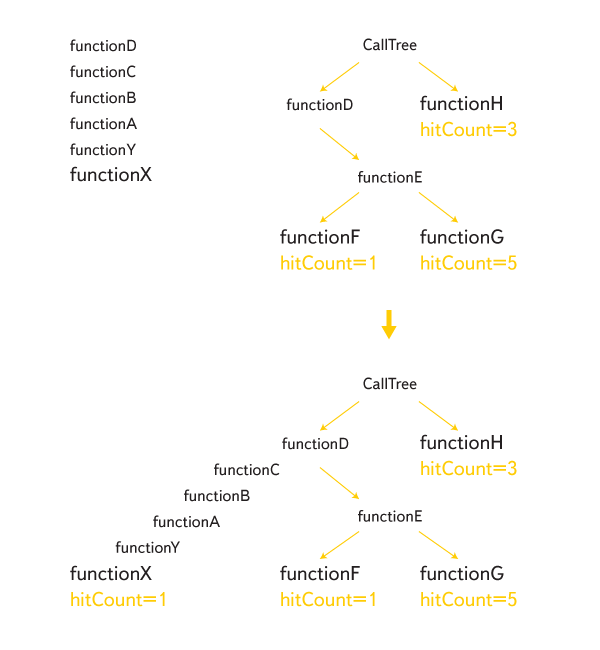
Каждому вызову-листу присваивается значение hitCount со смыслом «сколько раз функция вызывалась таким образом». Когда профилирование окончено, hitCount вычисляются для всех внутренних узлов снизу вверх. Полученные значения и являются тиками, которые показывает в своем выводе tick-processor.
Есть очевидный, но грубый способ перевода тиков в миллисекунды:
hitTime = (maxTimestamp - minTimestamp) / (timestamps.length - 1)
blockTime = hitCount * hitTime
Время между тиками в реальности не одинаковое, а тот факт, что мы были внутри функции F во время T и во время T + 1 мс, совершенно не означает, что функция выполнялась 2 мс. Возможно, между этими моментами времени выполнялись совсем другие функции, которые такой метод профилирования «не заметит». Тем не менее, именно так время исполнения считается в Chromium — https://code.google.com/p/chromium/codesearch#chromium/src/third_party/WebKit/Source/devtools/front_end/sdk/CPUProfileDataModel.js&sq=package:chromium&type=cs&l=31
В любом случае нам был необходим альтернативный способ профилирования для проверки результатов instrumentation-метода.
Управляемый эксперимент №2.
Sampling-подход
К счастью, не пришлось долго копаться в node-tick-processor, так как нашелся модуль v8-profiler, который работает так:
var profiler = require(‘v8-profiler’); profiler.startProfiling('profilingSession'); doSomeWork(); console.log(profiler.stopProfiling('profilingSession'));
При этом в консоль напечатается объект такого вида:

Наш профилирующий код при использовании v8-profiler выглядит так:
var hitTime; function checkoutTime(node) { var hits = node.hitCount || 0; node.children.forEach(function(childNode) { hits += checkoutTime(childNode); }); logStream.write(node.functionName + ',' + (hits * hitTime) + '\n'); return hits; } function getTime(profile) { var timestamps = profile.timestamps, lastTimestampIndex = timestamps.length - 1; // среднее время тика, переведенное из микросекунд в наносекунды hitTime = 1000 * (timestamps[lastTimestampIndex] - timestamps[0]) / lastTimestampIndex; checkoutTime(profile.head); }
По аналогии с instrumentation нужна правка для правильной обработки рекурсии:
function stackAlreadyHas(node, name) { return node && (node.functionName === name || stackAlreadyHas(node.parent, name)); } function checkoutTime(node) { var name = node.functionName, hits = node.hitCount || 0; node.children.forEach(function(childNode) { // добавляем связи childNode.parent = name; hits += checkoutTime(childNode); }); // записываем результат только для первого вызова данной функции if (!stackAlreadyHas(node.parent, name)) { logStream.write(name + ',' + (hits * hitTime) + '\n'); } return hits; }Управляемые эксперименты. Результаты
Медиана времени выполнения блока serp-item — основного блока, соответствующего одному результату поисковой выдачи (страница содержит 10 таких результатов):
| метод | desktop | tablet |
|---|---|---|
| Instrumentation | 38.4 мс | 35.9 мс |
| Sampling | 25.3 мс | 25.0 мс |
Из-за фундаментальных отличий в методиках абсолютные значения ожидаемо получились разными.
На следующем шаге мы попытались максимально уменьшить вклад профилирующей логики в instrumentation-методе с помощью мелких оптимизаций. В sampling-методе мы сокращали время между тиками (метод setSamplingInterval). Картина не менялась. У вызовов, близких к корню дерева, получались похожее показатели, но чем дальше находились вызовы от корня, тем больше они отличались.
Выводы
Более глубокие вызовы соответствуют функциям, вызываемым много раз. Для них погрешность замеров равна произведению погрешности метода и числа вызовов, поэтому небольшие правки общей картины не меняют.
Можно считать, что sampling-метод чаще занижает показатели. Instrumentation-метод завышает показатели по построению. Вероятно, при профилировании кода с невысоким деревом вызовов оба метода будут показывать близкие результаты, но в общем случае этого ждать не стоит.
Несмотря на разницу в абсолютных результатах, относительные значения по конкретным блокам получались близкими. Оба метода показывали одинаковый список «тормозящих» блоков. «Управляемые эксперименты» были оформлены в виде «тулзы» для профилирования нашего PRIV-кода.
Цикл оптимизации в общих чертах выглядел так:
- Запустить тулзу.
- Если необходимый уровень быстродействия кода достигнут — конец.
- Найти тормозящие блоки-функции.
- Оптимизировать блоки-функции.
- В начало.
В итоге мы оптимизировали ряд блоков, и обновленный код перестал уступать в скорости старой реализации.
Вот текущие цифры для serp-item (напомню, показатель для всей страницы поисковой выдачи получается умножением на 10):
| метод | desktop | tablet |
|---|---|---|
| Instrumentation | 35.1 мс (-3.3) | 34.8 мс (-1.1) |
| Sampling | 24.9 мс (-0.4) | 24.8 мс (-0.2) |
Вместо заключения
Строго говоря, у нас был простой случай – профилирование простых плоских функций. В случае профилирования кода с объектами и наследованием или асинхронного кода будет куда труднее понимать зависимости и делать выводы о вкладе отдельных частей в общее время выполнения программы.
Если у нас появится задача на профилирование более сложного кода – будет соответствующее решение, о котором мы обязательно расскажем здесь.
ссылка на оригинал статьи https://habrahabr.ru/post/282159/
Добавить комментарий