
Bat’s post delivery by sashulka
Электронная почта используется для решения широкого круга задач: мы получаем информацию о банковских счетах, обсуждаем рабочие проекты, планируем путешествия и еще много чего, что требует от нас обмена ценной информацией. Таким образом, почта содержит в себе много важных и конфиденциальных данных. И конечно, наша задача — надежно их защищать.
Мы постоянно работаем над системами, которые обеспечивают аккаунтам несколько ступеней защиты и значительно усложняют жизнь злоумышленникам. Но есть одно слабое звено. Это пароль, который можно угадать или, например, украсть на стороннем сервисе. Подробнее о способах кражи паролей и о безопасности почты можно прочесть в посте на эту тему.
Наша задача — защитить ящик пользователя, даже если злоумышленник узнал пароль и может войти в аккаунт. Для этого мы разработали систему машинного обучения, которая анализирует поведение в аккаунте и пытается определить, кто в нем находится — владелец или взломщик.
Как распознать взломщика?
Работая над задачами обеспечения безопасности, мы рассмотрели такой сценарий: у злоумышленника есть логин, пароль и возможность успешно пройти аутентификацию. При этом владелец ящика по-прежнему может работать в аккаунте и ничего не подозревать о взломе. Перед нами встал вопрос: можно ли как-то понять, что в аккаунте действует злоумышленник? Мы проанализировали множество примеров краж аккаунтов и убедились, что взлому почти всегда сопутствует изменение поведения. Мы решили использовать поведенческие характеристики в качестве признаков и на их основе делать вывод — взломан аккаунт или нет. И конечно, при решении этой задачи мы не могли обойтись без машинного обучения.
Как описать поведение?
Разные пользователи по-разному используют электронную почту. Кто-то начинает рабочий день в десять утра, входит в почту, удаляет рассылки, чистит папку «Спам», потом переходит в Облако Mail.Ru, а после идет читать Новости Mail.Ru. А кто-то работает поздно вечером, никогда не удаляет писем и ведет переписку только с мобильных устройств.
Для описания подобной активности используют ряд разнообразных признаков. Например, пользовательские действия (чтение и отправка писем, удаление, перемещение между папками), устройства, с которых пользователь работает в аккаунте, его географическое местоположение. Также можно учесть переходы в смежные сервисы и время суток, на которые приходится пик активности пользователя. Помимо этого, существуют более сложные признаки, например, такие, как печатный почерк. Этот подход учитывает скорость набора символов и паузы между нажатиями клавиш. С помощью печатного почерка можно отличить двух людей так же, как если бы мы попросили их написать несколько предложений на бумаге.
На этапе проектирования системы мы решили начать с анализа пользовательских действий, устройств и географического местоположения. На наш взгляд, это минимальный необходимый набор признаков, без которого трудно обойтись, и который легко дополнить, если в дальнейшем к системе будут предъявлены новые требования.
Как построить профиль?
В основу нашей системы заложен следующий принцип: у каждого пользователя есть свои привычки, и любую активность в почте нужно сравнивать с этими привычками. Если поведение существенно отклоняется от сформировавшихся паттернов, это повод заподозрить взлом аккаунта.
Набор устойчивых привычек назовем профилем. Чтобы проанализировать поведение в аккаунте, для каждого пользователя мы решили строить:
- профиль действий в аккаунте;
- профиль географического положения;
- профиль используемых устройств.
Рассмотрим на примере построение самого сложного профиля — профиля действий. Например, у нас есть часть лога, из которого мы хотим извлечь характерные привычки пользователя.

В данном примере check — это проверка почты, read — чтение сообщения, send — отправка сообщения.
На первом шаге алгоритма сгенерируем все возможные комбинации действий, которые пользователь может совершать в почте. Назовем их возможными паттернами. Далее нужно проверить частотные характеристики возможных паттернов. Наиболее частотные паттерны отражают привычки пользователя. Те, которые встречаются редко, привычками не являются, поэтому мы исключаем их из дальнейшего рассмотрения.
Все возможные паттерны, которые соответствуют примеру рассматриваемого лога, выглядят так.
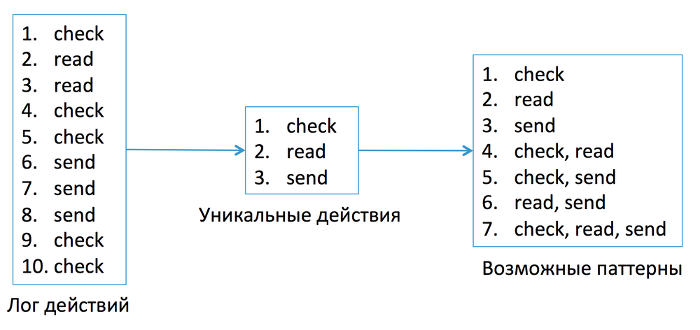
В общем случае для построения профиля может использоваться лог за длительный период времени: за несколько недель, например. За это время пользователь много раз входил в почту и решал множество задач. Но при этом очевидно, что анализировать нужно краткосрочные сеансы активности, во время которых пользователь решал конкретную задачу: писал письмо, чистил какую-либо папку, создавал фильтры и так далее.
Выделение таких сеансов представляет собой сложную самостоятельную задачу, которую нам хотелось упростить. Мы решили попробовать нарезать сеансы из лога случайным образом: брать любое действие в логе с равной вероятностью за начало сеанса, а его длительность получать при помощи некоторой случайной величины. При этом длина сеанса должна удовлетворять двум требованиям:
- она должна быть положительной;
- длительные сеансы должны иметь небольшую вероятность, поскольку пользователи решают свои задачи в почте за небольшие промежутки времени.
Мы решили получать искомые длины сеансов при помощи гамма-распределения, поскольку именно его реализации удовлетворяют указанным требованиям.
Полученные таким образом цепочки действий далее будем называть транзакциями. Если взять достаточно большое количество транзакций, то многие из них будут пересекаться с реальными сеансами активности пользователя, а значит, отражать его поведение в почтовом ящике. Пример сэмплирования лога приведен ниже.

Таким образом, мы уходим от исходного лога к набору транзакций, и именно этот набор используем в качестве данных для построения профиля.
Теперь настал тот момент, когда нужно проверить, какие из возможных паттернов действительно являются привычками пользователя, а какие нет. Здесь нам и пригодится набор транзакций.
Для каждого возможного паттерна мы вычисляем уровень опоры. Это величина, которая показывает, насколько часто паттерн встречается в действиях пользователя. Чтобы вычислить уровень опоры конкретного паттерна, нужно посчитать количество транзакций, которые содержат этот паттерн, и поделить его на общее количество транзакций. Попробуем вычислить уровень опоры паттерна «check + read».

Паттерн «check + read» встретился в четырех транзакциях, всего транзакций десять, а значит, уровень опоры этого паттерна 0,4.
Подобные вычисления проводим для всех паттернов.

Таким образом мы получаем частотные характеристики каждого паттерна. Чем выше уровень опоры паттерна, тем сильнее он отражает привычку пользователя. В профиль включаются те паттерны, уровень опоры которых превышает некоторый порог. Если взять порог, равный 0,5, то в профиль войдут паттерны «check», «send» и «check + send». Они отмечены красным цветом на рисунке.
Так мы получили набор паттернов, которые характеризуют привычные для пользователя действия в аккаунте. Описанный подход называется алгоритмом поиска ассоциативных правил и используется для извлечения закономерностей из данных.
По такому же алгоритму мы строим профиль характерной для пользователя географической зоны. А вот построение профиля по устройствам дало неожиданный результат. Но об этом чуть позже.
Теперь, когда мы знаем, как строить профиль, требуется понять, как сравнивать активность в почте с этим профилем.
Как сравнить действия с профилем?
Мы получили наборы привычек пользователя. Теперь нужно понять, насколько его активность в почте совпадает с этими привычками. Рассмотрим транзакцию «search + search + send» и попробуем численно оценить, насколько она соответствует профилю привычек (в этой транзакции «search» — это поиск по содержимому почты).

Чтобы вычислить меру похожести транзакции на профиль, нужно проверить, какие паттерны из профиля в ней содержатся, сложить уровни опор этих паттернов и поделить на общее количество всех паттернов в профиле. В рассматриваемом примере в транзакции содержится только паттерн «send», который имеет уровень опоры 0,7, а всего в профиле три паттерна. Тогда меру схожести, которую называют outlier factor (OF), можно вычислить вот так:
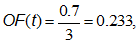
где t — тестируемая транзакция. Но у этой меры есть один недостаток — она не учитывает зашумленность транзакции.
Рассмотрим транзакцию «delete filter + move message + create folder + search + send» (удаление фильтра, перемещение сообщения между папками, создание папки, поиск в почте и отправка письма) и обозначим ее за r. Очевидно, что транзакции t и r имеют равные значения меры outlier factor:
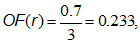
что не совсем верно, поскольку транзакция r сильно зашумлена действиями, которых нет в профиле. Для устранения этого недостатка вводят еще одну меру — long outlier factor, которая отражает, насколько транзакция схожа с паттернами профиля по длине. Чтобы вычислить long outlier factor, требуется найти паттерн максимальной длины, который содержится в транзакции, и поделить его длину на длину транзакции. Под длиной транзакции стоит понимать количество уникальных действий, которые в ней содержатся. Тогда получаем:

Метрика LOF наглядно демонстрирует, что транзакция r гораздо менее похожа на профиль, чем транзакция t.
Далее на основе метрик outlier factor и long outlier factor вычислим индекс подозрительности транзакции:

который будет учитывать схожесть транзакции с профилем как по содержанию, так и по длине паттернов. Чем ближе индекс подозрительности к значению 1, тем сильнее транзакция нехарактерна для пользователя. А чем ближе его значение к 0, тем больше транзакция совпадает с профилем. Вычислим индексы подозрительности для рассмотренных примеров:
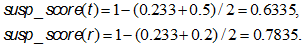
Теперь нам нужен порог, с которым мы могли бы сравнить полученные значения и принять решение, является ли транзакция аномальной или нет. На этом этапе нужно вернуться к набору транзакций, полученных при сэмплировании лога, и вычислить индекс подозрительности для них.

Для пользователя, которого мы рассматриваем в качестве примера, уровень подозрительности 0,6 является нормой. Мы можем использовать это значение как граничное и сравнивать с ним индексы подозрительности новых транзакций.
Для транзакций t и r мы получили значения индекса подозрительности 0,6335 и 0,7835 соответственно. Оба значения превышают порог 0,6, а значит, обе транзакции мы принимаем за подозрительные.
Таким образом, мы научились определять, насколько действия пользователя соответствуют его привычкам.
Если возникает необходимость анализа длительной цепочки действий (например, поведение пользователя за сутки), то мы нарезаем цепочку действий на транзакции по описанному выше алгоритму, а далее проверяем каждую транзакцию на подозрительность. Если количество подозрительных транзакций превысит определенный порог, то поведение за рассматриваемый период стоит считать аномальным.
Описанные алгоритмы мы используем для построения профиля действий пользователя и профиля его географического местоположения.
Как быть с устройствами?
При помощи алгоритмов обработки паттернов мы научились выделять привычные для пользователя действия в аккаунте и характерный для него географический регион. Таким же образом мы попробовали строить профиль использования устройств. И выяснили, что изменение паттерна по этому признаку не является подозрительным. У каждого человека есть свой набор девайсов и определенные паттерны их использования. Например, в течение дня мы работаем в почте с ноутбука, вечером — с планшета, а на выходных — только со смартфона. Устройства меняются в зависимости от времени суток и от дня недели, и обусловлено это предпочтениями пользователя.
Но все же этот признак оказался очень ценным. Проанализировав сценарии взломов и сравнив их с поведением обычных пользователей, мы заметили, что о взломе может говорить количество устройств. И именно этот признак мы решили использовать в дальнейшем. Мы сравниваем количество устройств пользователя с некоторым критическим порогом и на основе этого принимаем решение, является ли это количество характерным для взломщика или для обычного пользователя.
Как детектировать взлом?
В итоге для каждого пользователя мы получаем три признака: индекс подозрительности по действиям, индекс подозрительности по смене географического положения и количество устройств. В самом начале мы планировали строить классификатор над этими признаками. Тут стоит заметить, что классификатор требует дополнительных издержек: для него нужно собрать обучающую выборку, поддерживать ее в актуальном состоянии и бороться с переобучением.
Анализируя тестовые выборки, мы заметили следующую закономерность: с высокой точностью взлому соответствовало превышение критических порогов у двух признаков из трех.
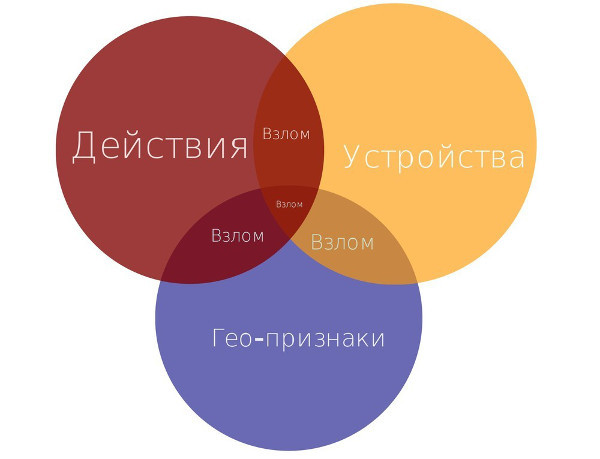
Таким образом, у нас появилась возможность использовать логические правила и отказаться от классификатора, что существенно упростило разработку, отладку и сопровождение всей системы.
Как оценивать ложные срабатывания?
В Антиспаме есть одно очень важное требование — мы не должны вредить нашим пользователям. Ограничить пользователю доступ в аккаунт, который на самом деле не взломан, — это то, чего нужно избегать всеми силами. Поэтому необходимо было придумать, как отслеживать такие ложные срабатывания системы и как вести по ним статистику.
Для этого мы разработали следующий подход. Например, в аккаунте произошла существенная смена поведения. Мы заподозрили, что аккаунт взломан, и попросили владельца подтвердить личность и сменить пароль. После смены пароля мы полагаем, что в аккаунте находится только его владелец и никто другой. Если же после восстановления доступа к аккаунту в нем продолжается то же самое поведение, которое ранее вызвало у нас подозрения, то мы полагаем, что данное поведение теперь характерно для пользователя и система сработала ложно. Мы включаем подобные случаи в статистику для дальнейшего исследования, а профили пользователя пополняем новыми поведенческими паттернами.
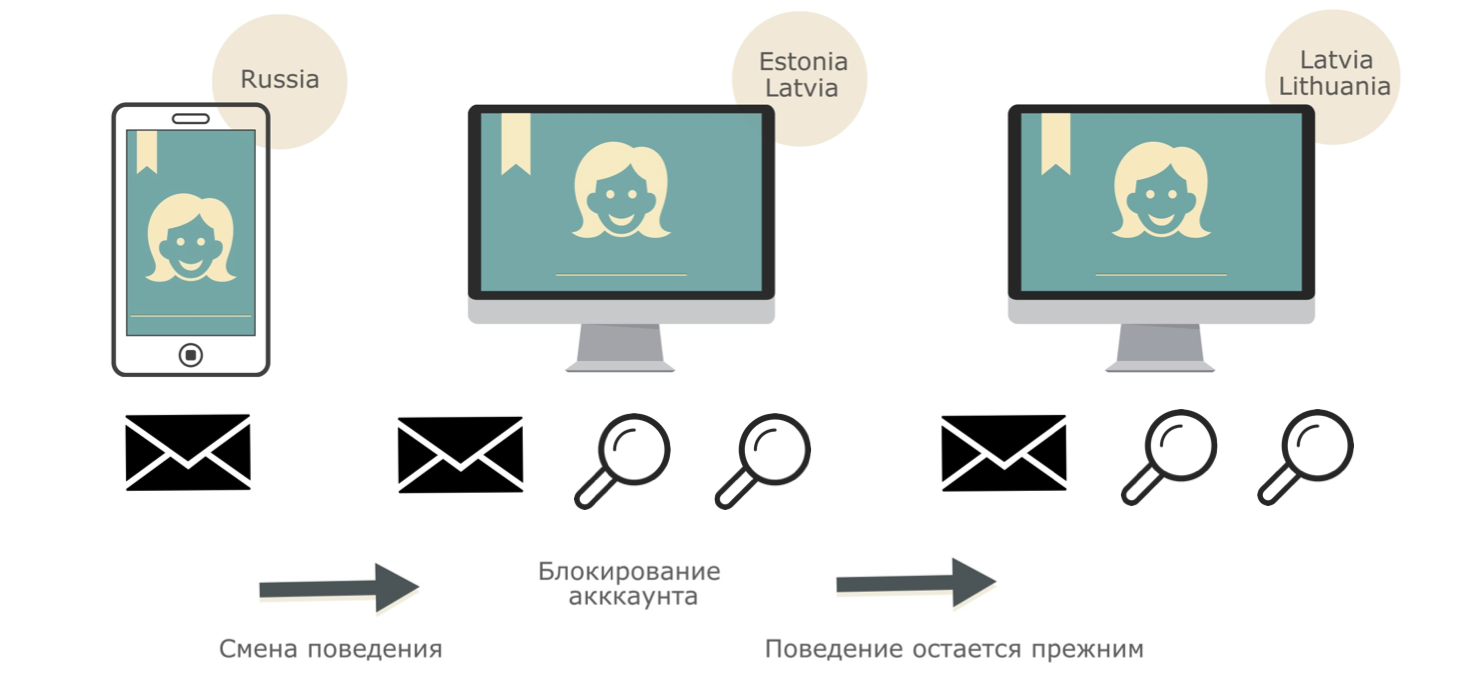
Как работает этот подход, можно рассмотреть на примере. Характерное поведение пользователя в почте: регулярная отправка писем с мобильного устройства из России. В определенный момент поведение полностью меняется: в ящике начинаются массовые поиски из Прибалтики с персонального компьютера. Система анализа поведения просит пользователя сменить пароль. После смены пароля в аккаунте продолжаются операции поиска и отправки писем из Прибалтики. В таком случае мы пополняем профиль пользователя новыми поведенческими паттернами, а первое срабатывание системы рассматриваем как ложное.
Результаты
Мы разработали систему машинного обучения, которая пытается детектировать взлом, анализируя поведение пользователя в аккаунте. Конечно, пока рано говорить о законченном решении: впереди еще много работы, и нам предстоит разгадать немало головоломок. Но тем не менее, те результаты, которые мы имеем уже сейчас, говорят о перспективности данного подхода, поэтому мы планируем развивать его, чтобы сделать наши сервисы еще более надежными.
P. S.: Система получила название Marshal (сокращенно от Mail.Ru Suspicious Hacking Alert). Мы подробно рассказали о ней на Data Fest, который прошел в московском офисе Mail.Ru Group 5 и 6 марта 2016 года. Видео выступления и презентацию можно найти здесь.
ссылка на оригинал статьи https://habrahabr.ru/post/282375/
Добавить комментарий