
Метод Монте-Карло это алгоритм принятия решений, часто используемый в играх в качестве основы искусственного интеллекта. Сильное влияние он оказал на программы для игры в Го, хотя находит свое применение и в других играх, как настольных, так и обычных компьютерных (например Total War: Rome II). Так же, стоит отметить, что метод Монте-Карло используется в нашумевшей программе AlphaGo, победившей го-профессионала 9-го дана Ли Седоля в серии из 5 игр.
В данной статье хотелось бы рассказать про версию алгоритма Монте-Карло под названием Upper Confidence bound applied to Trees (UCT). Именно после публикации этого алгоритма в 2006-м году, программы для игры в Го сильно усилили свои позиции и достигли значительных успехов в игре против человека.
Основой алгоритма UCT является решение задачи многоруких бандитов. В частности используется алгоритм Upper-Confidence-Bound (UCB). Он уже был описан на хабре здесь, но я все же повторю основные моменты.
Задача звучит так: есть набор игровых автоматов, каждый со своей вероятностью выигрыша. Требуется определить автомат, который принесет больший выигрыш.
Алгоритм UCB:
1. Инициализация. Сыграть на каждой машине один раз
2. На каждой следующей итерации выбрать машину с максимальным значением величины 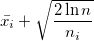 , где
, где 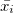 это средний выигрыш i-й машины,
это средний выигрыш i-й машины, 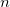 количество игр на всех машинах, а
количество игр на всех машинах, а  количество игр сыгранных на i-й машине.
количество игр сыгранных на i-й машине.
На практике для поиска в дереве ходов настольных игр часто используется модификация формулы UCB.
Например, такая: 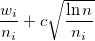 ,
,
здесь  это количество побед i-го узла. — количество посещений i-го узла, а количество посещений всех соседних узлов. c это константа, используемая для установки нужного баланса между шириной и глубиной поиска. Чем она больше, тем более глубокий будет поиск.
это количество побед i-го узла. — количество посещений i-го узла, а количество посещений всех соседних узлов. c это константа, используемая для установки нужного баланса между шириной и глубиной поиска. Чем она больше, тем более глубокий будет поиск.
Как видно из названия, алгоритм UCT (Upper Confidence bound applied to Trees) использует подход UCB для поиска по дереву. Рассмотрим пошагово каждую фазу алгоритма:
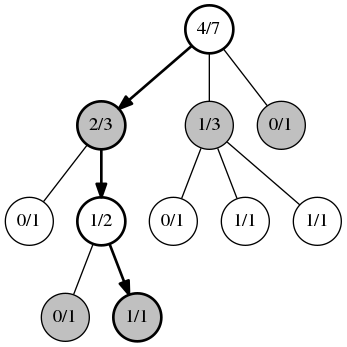
Первая фаза, выбор. Каждую позицию мы рассматриваем как задачу многорукого бандита. Узлы на каждом этапе выбираются согласно алгоритму UCB. Эта фаза действует до тех пор, пока не будет найден узел в котором еще не все дочерние узлы имеют статистику побед. На рисунке первое значение в узле это количество побед, второе общее количество игр в этом узле.
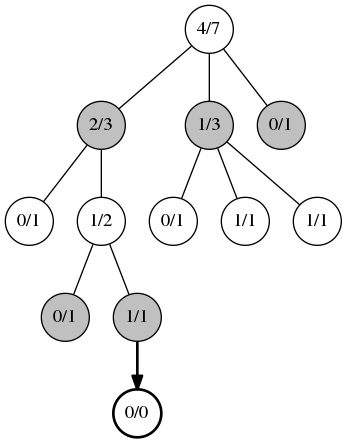
Вторая фаза, расширение. Когда алгоритм UCB больше не может быть применим, добавляется новый дочерний узел.
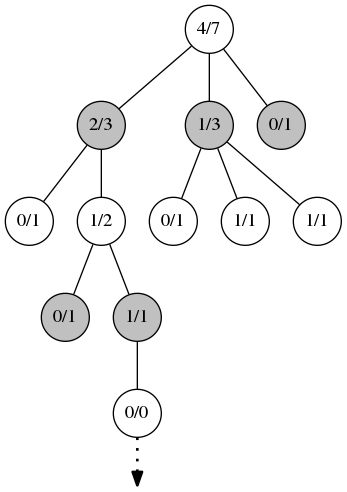
Третья фаза, симуляция. Из созданного на предыдущем этапе узла запускается игра со случайными или, в случае использования эвристик, не совсем случайными ходами. Игра идет до конца партии. Здесь важна только информация о победителе, оценка позиции не имеет значения.

Четвертая фаза, обратное распространение. На этом этапе информация о сыгранной партии распространяется вверх по дереву, обновляя информацию в каждом из ранее пройденных узлов. Каждый из этих узлов увеличивает показатель количества игр, а узлы, совпадающие с победителем, увеличивают также и количество побед. В конце алгоритма выбирается узел, посещенный наибольшее количество раз.
UCT не всегда выбирает только самый лучший ход, но так же периодически исследует и менее успешные узлы. Второй параметр формулы медленно растет для тех узлов, которые посещаются не так часто. И в итоге на каком-то этапе алгоритм выберет именно такой ход в качестве предпочтительного. Если ход оправдал ожидания, в следующий раз он будет выбран с большей вероятностью.
По сравнению с другими алгоритмами для поиска оптимальных ходов, UCT обладает следующими преимуществами:
- UCT может быть безболезненно остановлен на любом этапе работы. И на момент остановки он просчитает равномерно все варианты ходов из корневого узла

Пример остановки алгоритма альфа-бета. Видно, что узлы со знаком «?» так и не были исследованы - Дерево растет асимметрично, исследуя предпочтительные ходы глубже остальных. Таким образом, достигается большая эффективность в сравнении с другими алгоритмами в играх со значительным количеством вариантов для перебора.
Т.к. ходы, выбранные случайно в большинстве своем бессмысленны и не имеют какого-то общего направления, то для улучшения работы алгоритма используются различные эвристические методы, основанные на информации о конкретной игре. Один из таких методов это применение шаблонов.
Вот пример шаблона 3×3 для разрезания камней в Го:
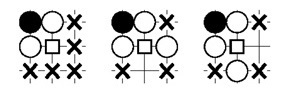
Ход будет расценен как интересный, когда первый шаблон совпадает, а второй и третий нет. То есть белую группу можно «разрезать». Квадратиком изображена интересующая нас позиция.
Шаблоны могут использоваться как на этапе выбора хода в дереве, так и на этапе симуляции. Зачастую такие шаблоны ищутся где-то в окрестностях последнего сделанного хода. Это делается, потому, что текущий ход не редко является ответом на предыдущий и скорее всего, будет сделан где-то поблизости.
Пример из серии до и после. Слева игровая ситуация с использованием обычного UCT, справа UCT c применением шаблонов:
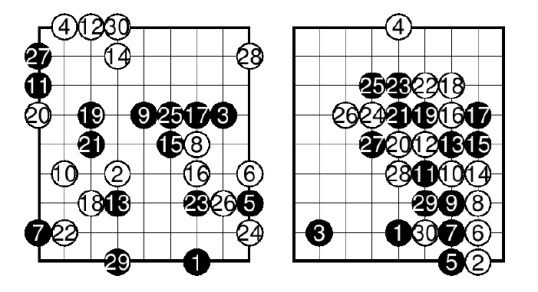
Видно, что на первом рисунке камни бессистемно расставлены по всей доске.
В большинстве случаев шаблоны пишутся вручную, но есть так же и примеры автоматической генерации.
Для того чтобы не распылятся на всю доску и не тратить время на просчет лишних вариантов. Можно выделить наиболее важную область, в которой уже и исследовать ходы. Очевидно, что если в данный момент вся борьба сосредоточена вокруг одной группы в определенном углу доски, то не имеет смысла рассматривать пустующие области вокруг. Алгоритмы определения таких областей выходят за рамки статьи, но те, кому интересно могут почитать подробно здесь: Common Fate Graph.
Алгоритм UCT может быть одновременно запущен в нескольких потоках. Вот некоторые способы параллелизации вычислений:
- Распараллеливание узлов, одновременная симуляция игр из одного и того же узла.
- Распараллеливание корня, построение независимых деревьев.
- Распараллеливание дерева, совместное построение одного дерева несколькими потоками.
Это наверное все, что хотелось бы сказать про алгоритм Монте-Карло и в частности UCT. В целом алгоритм с учетом дополнительных модификаций показывает неплохие результаты игры. В пользу этого утверждения говорит, то, что все современные Го-программы используют именно его. Надеюсь, что для кого-то из вас он тоже окажется полезен.
ссылка на оригинал статьи https://habrahabr.ru/post/282522/
Добавить комментарий