Для экспериментов с долговременным хранением данных
Корпорация Microsoft закупает 10 миллионов нитей синтетической ДНК у биологического стартапа Twist Bioscience. Такое количество биоматериала требуется для проверки, насколько генетический материал подходит для долговременного хранения информации.
Плотность информации в ДНК давно привлекает внимание учёных: в одном грамме ДНК помещается 1 зеттабайт (миллион терабайт) данных и хранится без изменений тысячи лет в соответствующих условиях. Дело за малым: научиться дёшево и надёжно считывать и записывать информацию.
В минувшие годы неоднократно проводились успешные эксперименты с записью бинарных данных в пары оснований ДНК. Ещё в 2010 году биологи из Гонконга сумели внедрить в клетку бактерии E.coli синтетическую ДНК, а в 2012 году учёные из Гарварда записали 643 килобайта данных в ДНК, поставив новый рекорд по количеству записанной информации.
Для кодирования информации в ДНК используется четверичная система счисления, по количеству нуклеотидов (0 = A, 1 = T, 2 = C, 3 = G). Например, специалисты из Китайского университета Гонконга переводили текст в цифры по таблице ASCII (i = 105; G = 71; E = 69; M = 77), затем в четверичную систему (105 → 1221; 71 → 0113; 69 → 0111; 77 → 0131), а потом в цепочку нуклеотидов.
iGem → 1221011301110131 → ATCTATTGATTTATGT
Специалисты из Гарварда использовали другой метод. Во-первых, они принципиально отказались от использования живых организмов, а внедряли синтетическую ДНК в молекулу, сгенерированную на коммерческом ДНК-чипе. Таким образом, записанная информация не может быть потеряна из-за генетических мутаций при эволюции организма-носителя. Во-вторых, они использовали не текст ASCII, а бинарный код — файл с книгой, с сохранением форматирования HTML и иллюстраций JPEG. Код разбили на 96-битные блоки, включая 19-битный уникальный адрес каждого блока (на диаграмме показан красным цветом).
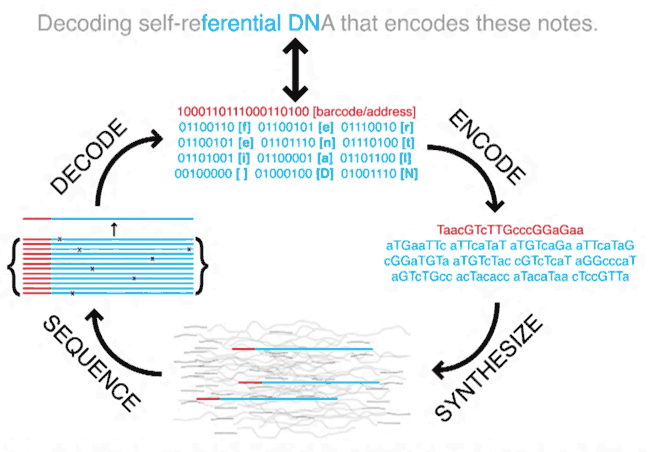
С тех пор методы кодирования данных постепенно совершенствовались. Улучшались и технологии считывания информации из ДНК. Свою лепту внесли и исследователи из Microsoft Research: недавно они опубликовали научную работу на эту тему.
Twist Bioscience специализируется на технологиях записи информации в ДНК с помощью специальной машины для массового производства синтетических ДНК, которую сконструировали в компании. Основные клиенты Twist Bioscience — исследовательские лаборатории, которые занимаются изготовлением генетически изменённых бактерий, необходимых в определённых химических реакциях для производства специфических препаратов. Использование генетического материала для хранения информации — новое направление в деятельности Twist Bioscience.
Сделанные по заказу синтетические ДНК заданной конфигурации стоят около 10 центов за базовую пару. Компания Twist Bioscience рассчитывает в ближайшем будущем снизить цену до 2 центов.
«Они сообщают нам последовательность ДНК, мы производим цепочку с нуля», — сказала исполнительный директор Twist Bioscience Эмили Лепруст (Emily Leproust) по поводу контракта с Microsoft. Изготовленный биоматериал отправляют в Microsoft, при этом биоинженеры Twist Bioscience даже не знают, какая конкретно информация закодирована в молекулах, поскольку у них отсутствует ключ для расшифровки.
В лабораторных условиях с помощью искусственного старения Microsoft проверит, сохранит ли ДНК информацию в течение 1000 лет.
Считывание информации с ДНК производится методом генетического секвенирования. За последние 20 лет стоимость этой процедуры значительно снизилась. Например, проект секвенирования человеческого генома продолжался с 1993 по 2003 годы и обошёлся примерно в $3 млрд. Сегодня такую процедуру можно выполнить за $1000.
Если падение цен продолжится такими темпами и удастся снизить уровень ошибок считывания, то ДНК действительно можно будет рассматривать как приемлемый носитель информации. Нужно снизить цены ещё в 10 000 раз — и технология пойдёт в массы, уверена Эмили Лепруст.
ссылка на оригинал статьи https://geektimes.ru/post/275060/
Добавить комментарий