
В нашем блоге мы уже рассказывали о биллинге для операторов связи «Гидра» — наших подходах к разработке сложных продуктов, а также описывали реальные кейсы внедрения системы. Сегодня мы подробнее поговорим о стеке технологий и инструментов, которые используются в процессе разработки и эксплуатации нашего проекта.
Архитектура
Прежде, чем описывать используемые технологии, повнимательнее рассмотрим, из чего вообще состоит система биллинга.
- Данные — информация о потребленных абонентами услугах, балансы лицевых счетов, детализация платежей и списаний.
- Ядро — часть системы, в которой ведутся все операции с данными. В «Гидре» оно интегрировано с данными — бизнес-логика находится прямо в СУБД в виде хранимых процедур. Модифицировать данные напрямую внешним приложениям запрещено, это можно делать только через API.
- AAA-сервер (Authentication, Authorization, Accounting) — элемент, который отвечает за аутентификацию, авторизацию и учет важной информации о потребленных абонентами услугах.
- Платежный шлюз — принимает информацию о проведенных платежах из различных платежных систем.
- Личный кабинет абонента и веб-панель управления — интерфейсы для доступа и работы с системой.
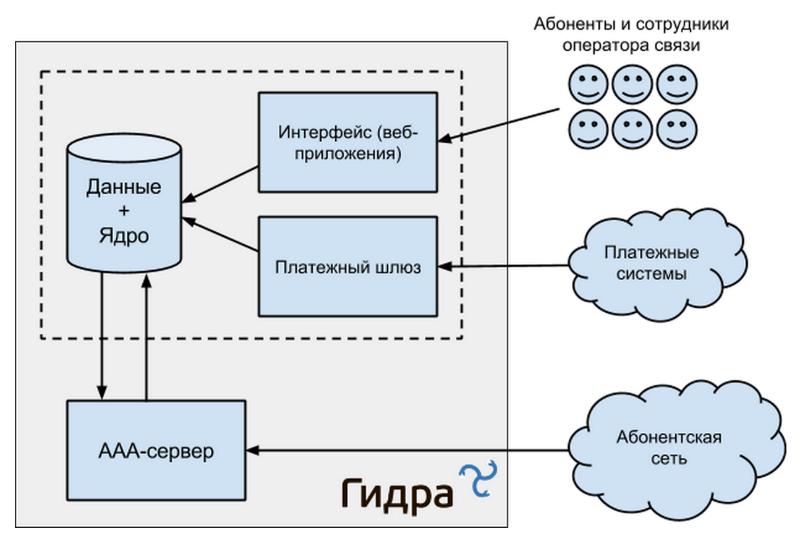
Общее представление архитектуры системы
Теперь поговорим уже о конкретных технологиях.
СУБД: Oracle и MongoDB
Наша биллинговая система использует для учета первичных данных и хранения финансовой информации реляционную СУБД Oracle. Она идеально подходит для этих целей. Основная база хранит данные и ядро системы. Мы используем вырожденную трехуровневую архитектуру — бизнес-логика (хранимые процедуры и функции в Oracle) и данные (таблицы) тесно интегрированы в СУБД, в качестве клиента выступает браузер («тонкий клиент»), а веб-интерфейс служит программной оболочкой к ядру.
Но некоторые модули Гидры, например, RADIUS-сервер, работают под высокой нагрузкой и могут получать тысячи запросов в секунду с жесткими ограничениями на время обработки запроса. Кроме того, в БД нашего автономного RADIUS-сервера данные хранятся в виде набора AVP (attribute/value pair). В таком сценарии реляционная СУБД уже не выглядит лучшим решением, и тут на помощь приходит MongoDB с ее хранилищем документов произвольной структуры, быстрой выдачей ответа и горизонтальной масштабируемостью.
При эксплуатации более чем на 100 инсталляциях Гидры на протяжении последних 5 лет серьезных проблем с Mongo мы не обнаружили. Но пара нюансов все же есть. Во-первых, после внезапного отключения сервера БД хоть и восстанавливается благодаря журналу, но происходит это медленно. К счастью, необходимость в этом возникает нечасто. Во-вторых, даже при небольшом размере БД редко используемые данные сбрасываются на диск и когда запрос к ним все же приходит, их извлечение занимает много времени. В результате нарушаются ограничения на время выполнения запроса.
Все это относится к движку MMAPv1, который применяется в Mongo по умолчанию. С другими (WiredTiger и InMemory) мы пока не экспериментировали — проблемы не настолько серьезны.
Читайте также: Когда стоит и не стоит использовать MongoDB
Работа с данными: JSON
Помимо биллинга «Гидра», мы развиваем и open-source систему управления бизнес-процессами «Гидра OMS». В этом проекте используется еще и СУБД PostgreSQL, а для работы с данными применяется JSON. В частности, мы храним в таких полях значения переменных процесса, структура которого определяется в момент внедрения продукта, а не во время его разработки.
Работа с полями таблицы производится через адаптер фреймворка Ruby On Rails для PostgreSQL. Чтение и запись работают в нативном для Ruby режиме — через хэши и списки. Таким образом, вы можете работать с данными из поля без дополнительных преобразований.
Читайте также: Как использовать ограничения JSON при работе с PostgreSQL
Оптимизация производительности: денормализация
Мы в Латере много занимаемся оптимизацией производительности биллинговой системы, что неудивительно, учитывая объемы наших клиентов и специфику телеком-отрасли.
На Хабре мы обсуждали материал зарубежных коллег об использовании денормализации баз данных. Один из представленных в этой статье примеров предполагает создание таблицы с промежуточными итогами для ускорения отчетов. Конечно, самое сложное в этом подходе — поддерживать актуальное состояние такой таблицы. Иногда можно переложить эту задачу на СУБД — например, использовать материализованные представления. Но, когда бизнес-логика для получения промежуточных результатов оказывается чуть более сложной, актуальность денормализованных данных приходится обеспечивать вручную.
Так, Гидра имеет глубоко проработанную систему привилегий для пользователей, операторов биллинга. Права выдаются несколькими способами — можно разрешить определенные действия конкретному пользователю, можно заранее подготовить роли и выдать им разные наборы прав, можно наделить определенный отдел специальными привилегиями. Только представьте, насколько медленными стали бы обращения к любым сущностям системы, если бы каждый раз нужно было пройти всю эту цепочку, чтобы убедиться: «да, этому сотруднику разрешено заключать договоры с юридическими лицами» или «нет, у этого оператора недостаточно привилегий для работы с абонентами соседнего филиала». Вместо этого мы отдельно храним готовый агрегированный список действующих прав для пользователей и обновляем его, когда в систему вносятся изменения, способные на этот список повлиять. Сотрудники переходят из одного отдела в другой намного реже, чем открывают очередного абонента в интерфейсе биллинга, а значит вычислять полный набор их прав нам приходится настолько же реже.
Конечно, денормализация хранилища — это только одна из принимаемых мер. Часть данных стоит кэшировать и непосредственно в приложении, но если промежуточные результаты в среднем живут намного дольше, чем пользовательские сессии, есть смысл всерьез задуматься о денормализации для ускорения чтения.
Читайте также: Зачем нужна денормализация баз данных, и когда ее использовать
Управление оборудованием: Clojure
Сейчас мы используем для выполнения команд по управлению оборудованием Clojure. Специфика задачи заключается в требованиях к одновременности при исполнении команд и гибких ограничениях. С одной стороны нельзя «завалить» одно устройство командами, с другой стороны — исполнять все команды последовательно неэффективно, потому что они могут параллельно исполняться на различном оборудовании. Эта задача с легкостью решается библиотекой core.async, которая добавляет поддержку go-блоков и каналов, знакомых по языку Go, где с помощью них реализованы взаимодействующие последовательные процессы (термин, больше известный как CSP).
При этом Сlojure — язык общего назначения, найти ему применение не составляет большого труда. Так как он базируется на JVM, то для него уже фактически существует огромный выбор библиотек, поэтому при его использовании не нужно писать все заново, что сильно снижает порог входа.
Даже если вы на дух не переносите Lisp, вам стоит ознакомиться с концепциями, которые заложены в язык, многие из них заставляют по-новому взглянуть на программирование.
Читайте также: Почему стоит изучать и использовать Clojure
Управление проектами и поддержка
Изначально для задач отдела внедрения и техподдержки использовалась система Jira. Однако со временем стало очевидно, что приспособить этот инструмент для разработчиков к задачам отдела внедрения и поддержки не так-то просто. В результате мы начали искать альтернативные средства.
Одним из рассматриваемых вариантов был сервис Zendesk, однако препятствием к его использованию стал неудобный одностраничный интерфейс, в котором и только в котором, по задумке авторов, должны работать сотрудники отдела поддержки. Кроме того, скорость работы Zendesk оставляла желать лучшего. С этими проблемами мы столкнулись в 2013 году, возможно сейчас проект сделал шаг вперед, однако мы уже нашли ему альтернативу.
Ей стал сервис Freshdesk — он похож на Zendesk, но обладает более дружелюбным интерфейсом и довольно активно развивается. Разработчики оперативно реагируют на запросы, в их системе реализован и API-интерфейс.
Для управления проектами внедрения мы используем PM-сервис Teamwork. В этой системе наглядно показаны все необходимые этапы проекта, задачи, которые должны быть выполнены, и те участки работы, которые будут разблокированы после этого. Также указаны ответственные за решение стоящих задач с обеих сторон.

Также для некоторых задач до сих пор используется Jira (ведение задач, которые не подходят по назначению ни в одну из других систем управления).
Кроме того, мы организовали собственное хранилище данных (Data Warehouse), в которое выгружается информация из всех существующих систем и самого биллинга «Гидра», который применяется для тарификации оплаченного времени поддержки (оно автоматически загружается в биллинг из хранилища) и выставления счетов. Эта информация затем используется для организации работы отдела поддержки.
Читайте также: Как организовать поддержку сложного продукта
Заключение
Наш проект развивается уже 9 лет, и за это время мы поучаствовали более чем в 100 проектах внедрения. Мы постоянно работаем над тем, чтобы сделать систему более надежной и удобной для клиентов.
В нашем блоге мы продолжим рассказывать об используемых нами технологиях и подходах к улучшению работы «Гидры».
Другие статьи по теме ИТ-инфраструктуры от команды «Латеры»:
- Будни биллингистов: Как мы готовились к деноминации в Белоруссии
- Как сделать миграцию на новый биллинг простой и понятной: автоматизируем перенос данных
- Автоматизируем учет адресов и привязок в IPoE-сетях
- Разработка приложения для повышения эффективности выездных сотрудников: Опыт Planado.ru
- Что еще влияет на инфраструктуру: Как обеспечить качество монтажа оборудования
ссылка на оригинал статьи https://habrahabr.ru/post/313508/
Добавить комментарий