В определенный момент в жизни почти каждой финтех-компании настает время, когда количество приложений внутренней разработки начинает превышать число разработчиков, бизнес хочет больше новых фич, а на Bug Bounty продолжают сдавать все новые и новые уязвимости…
Но при этом есть потребность быстро выпускать качественное и безопасное ПО, а не тушить пожары от выявленных ошибок безопасности откатами версий и ночными хотфиксами.
Когда команда ИБ состоит из пары человек, кажется, что так будет всегда, но мы решили выжать из ситуации максимум позитива и раз и навсегда "засекьюрить" свои приложения.
С чего начать? Наш план был прост:
- Упорядочить процессы постановки, исполнения и выпуска задач, не став палкой в колесах разработки.
- Прикрутить модные сканеры безопасности.
- Отревьюить пару десятков приложений.
- Откинуться в кресле, наблюдая за тем, как это все само работает.
Процессы
Шаблоны процессов разработки "Software Development Lifecycle" уже давно написаны, есть даже ГОСТ и ISO. Но о шаблонах построения «безопасной» разработки в нашей стране еще пару лет назад почти не было слышно.
По началу, двигателем идеи безопасной разработки был Microsoft. В терминологии редмодовского гиганта, Security Development Lifecycle — это процесс, который помогает разработчикам строить более безопасные приложения за минимум времени, следуя определенным правилам дизайна и разработки ПО.
Как к этому прийти? В общей концепции SDLC — это замкнутый цикл процессов, например, как у Microsoft. Для себя мы выделили такие ступени процессов:
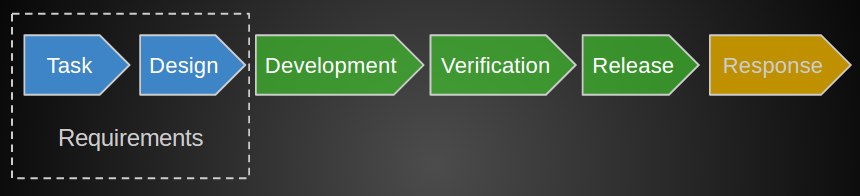
Изначально задача выглядела так, что к существующему циклу разработки нужно было достроить некоторые пункты из этого шаблона.
А именно, у нас есть устоявшийся за годы цикл, по которому задача пришедшая от одного из подразделений (бизнеса, аналитики) попадала к разработчикам, затем тестировалась. В случае выявления функциональных багов возвращалась в разработку, передавалась админам и в конечном счете выливалась в бой.
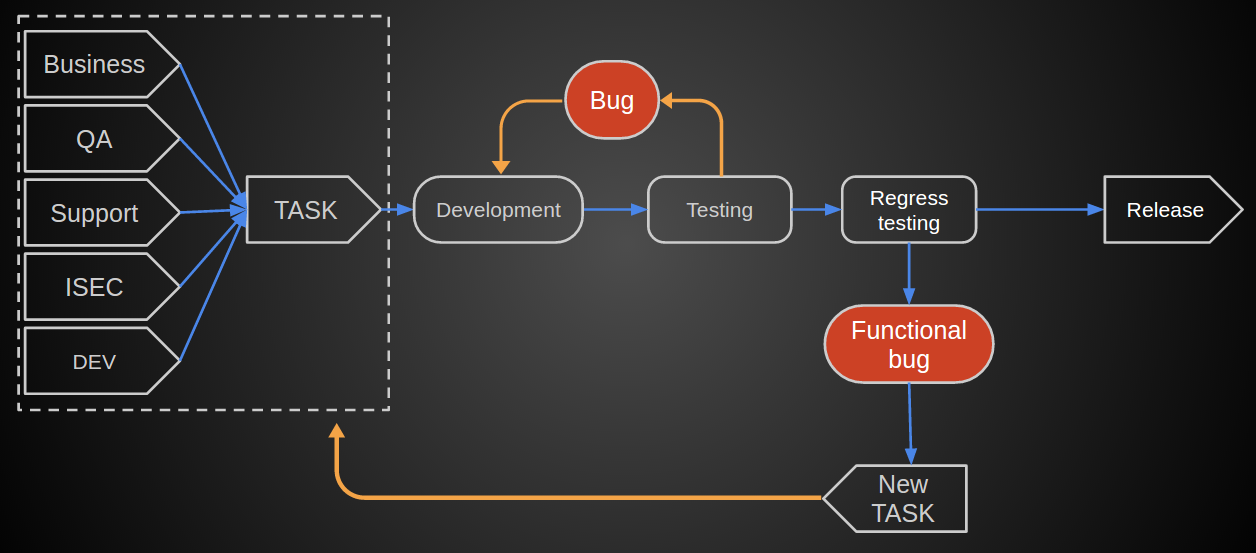
На момент старта QSDLC, у нас были:
- Ежегодные тренинги для разработчиков;
- Build-система и налаженная система деплоя с возможностью откатов версий;
- По мере сил — тестирование приложений, выходящих в релиз;
- Программа на HackerOne;
Так что следуя шаблону, мы покрывали 3 важных пункта.
Для небольшого количества релизов этих шагов было бы достаточно. Но в нашем случае нужно было доработать процессы постановки задач и автоматизировать security-тесты.
Постановка и проектирование задачи
Некоторые ошибки безопасности можно устранить на начальном этапе проектирования приложения. Возникать они могут из-за принципиально порочных схем логики или внедрения ненадежных механизмов.
Для себя мы выделили основные пункты при которых требуется ИБ-аналитика задач:
- работа со сторонними сервисами, обмен данными с партнерами/клиентами,
- работа со сторонним кодом, его внедрение в систему,
- понижение уровня приватности сервиса ,
- работа с личными данными пользователей,
- новая для системы сервис/фича, которая не является базовой.
Затраты на этот этап небольшие, но он позволяет
- на корню обезопасить отдельные части системы,
- сохранить время и силы на доработки и ловлю багов,
- повысить осведомленность в ИБ не только разработчиков, но так же аналитиков и продуктовых менеджеров.
Автоматизация
DAST
Он же Dynamic Application Security Testing. И как бы странно это не звучало, для веб-приложений мы просто взяли Burp Suite т.к. он был уже хорошо знакомым и незаменимым инструментом в работе. Помимо этого у сканера есть отличный API для доработки под наши хотелки. Возможно, кто-то скажет, что это всего -лишь настольный инструмент для пентестеров, но на деле он может покрывать и требования энтерпрайза.
В контексте SDLC это:
- Сканы по расписанию и по событию (новые релизы);
- Первичная оценка приложения;
- Точечный скан, беспорядочный fuzzing и нагрузка приложения;
- Благодаря открытому API может быть дописан под каждый определенный проект, полный контроль над инструментом;
Чего не может качественно покрыть динамическое сканирование, так это нахождение всех входных точек в приложении (впоследствии проблему решили проксированием трафика на конечных тестовых нодах и автотестах QA, но не спасет от каких-то непредусмотренных сценариев).
Чего DAST в принципе не может покрыть:
- Нахождение уязвимостей второго порядка (не 100% покрытие);
- Трудно разделить измененные и неизмененные входные точки. Соответственно, сканирование проходит по всему приложению, из-за чего время сканирования может сильно растянуться;
- Опасность искажения продуктовых данных в случае сканирования на боевых проектах.
SAST
Лучшим вариантом автоматизации на тот момент, казалось, должен быть SAST, Static Application Security Testing — статическое сканирование исходных кодов приложений на потенциальные уязвимости.
Сканер строит графы программных вызовов, анализируя входные и выходные точки, промежуточные вызовы в различные модули системы (БД, сервисы) и типы данных, попадающие из внешней среды (пользовательский ввод, выборки из БД).
По этим данным и имеющимся в сканере знаниям об антипаттернах и плохих практиках, sast-tool находит потенциальные ошибки безопасности.
Чем SAST-сканер принципиально отличается от DAST и лучше в связке SDLC:
- Можно повесить запуск сканирования на commit-hook в системе контроля версий и указать, какие именно ветки репозитория сканировать;
- В отличие от DAST не надо ждать выкладки в тестовую/боевую среду рабочего приложения;
- Одинаково хорошо подходит для сканирования всех платформ (web, desktop, mobile);
- Можно сканировать приложение итеративно — просвечивать только измененные графы вызовов. Время сканирования сильно уменьшается без потери покрытия кода.
Но помимо положительных моментов внедрения сканеров, пришлось столкнуться и с множеством подводных камней.
SDLC подразумевает непрерывный жизненный цикл разработки
Общий пункт, относящийся к любому из типов сканеров.
Сканер всего лишь инструмент, и его нужно запускать в правильный момент, желательно повесив на какие-то события во времени. Помимо этого в SAST, чтобы скан прошел по всем данным проекта и его зависимостям, нужно собрать код всех зависимостей проекта. И не все сканеры умеют делать это сами. А еще было бы здорово мониторить появления новых срабатываний на последующие сканы, получать о них рассылки, вешать метки в билд-системах о чистых сборках и сборках содержащих баги.
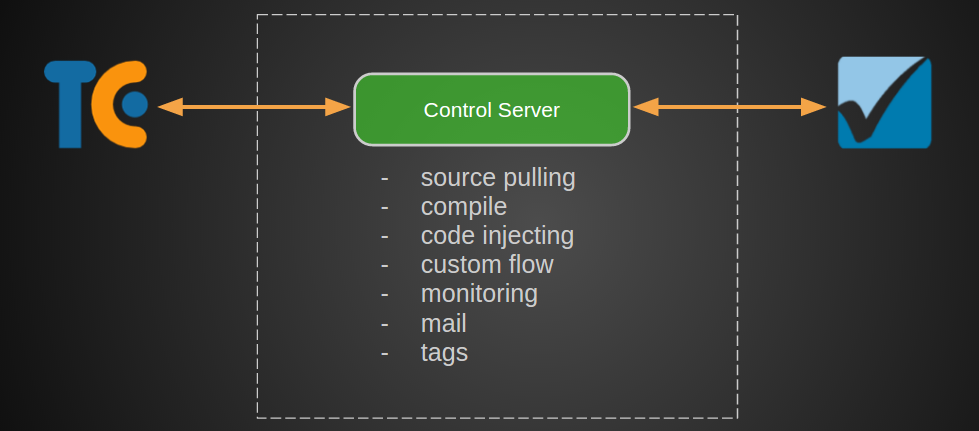
В итоге для подключения сканеров в SDLC мы сделали отдельный сервис, который занимается всеми проблемами интеграции.
В общем виде это hook на новую сборку в TeamCity, информация о которой с одного из агентов отправляется в сервис контрольного центра. Он же делает ряд манипуляций с исходниками, отправляет их в сканер и начинает мониторинг.
Обилие проектов, первоначальное сканирование
Чтобы начать удобные итеративные сканирования, нужна начальная точка для отправки — то, с чем последующие сканы можно будет сравнивать, и указывать только на те ошибки, которые появились с текущей итерацией.
Изначально придется просмотреть все срабатывания, которые появятся в отчете. В зависимости от специфики проекта/языка будет много False Positive. И пока не указаны сигнатуры точек приложения, сканер будет утверждать, что абстрактная связка методов setName — getName в классе, описывающем модель — это Reflected XSS.
Так же кастомная логика должна быть описана для всех домашних разработок. Если вы пишите свои фреймворки, придется написать и свои правила поиска. За время внедрения сканера мы собрали более сотни таких правил для разных языков и проектов.
И нужно смириться с тем, что инструмент поддерживает не все языки и фреймворки, по крайней мере, на текущий момент
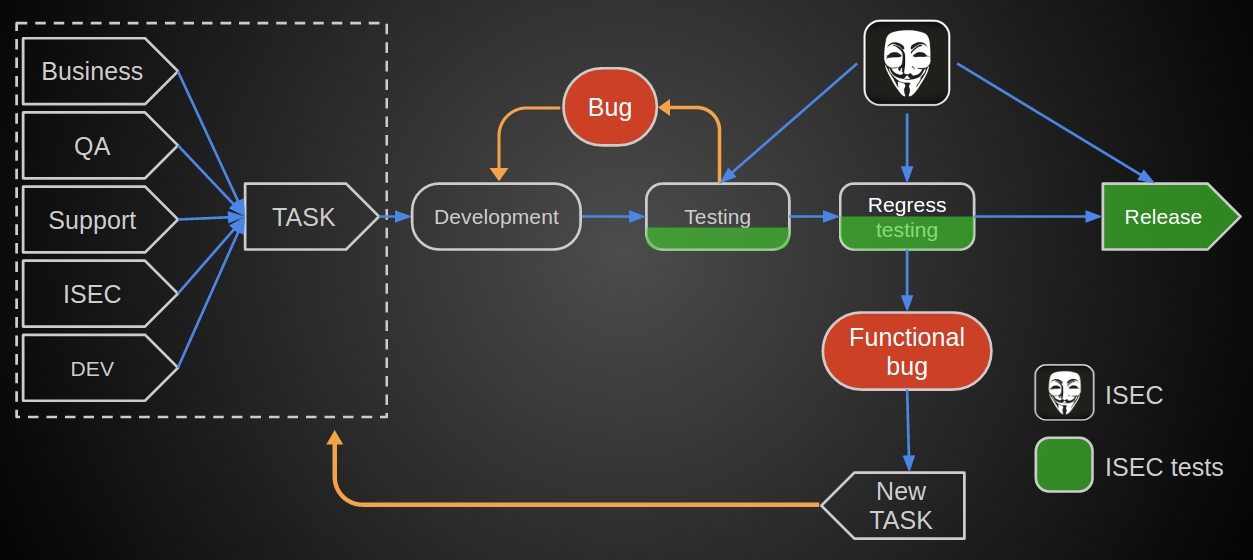
QIWI Security Development Lifecycle
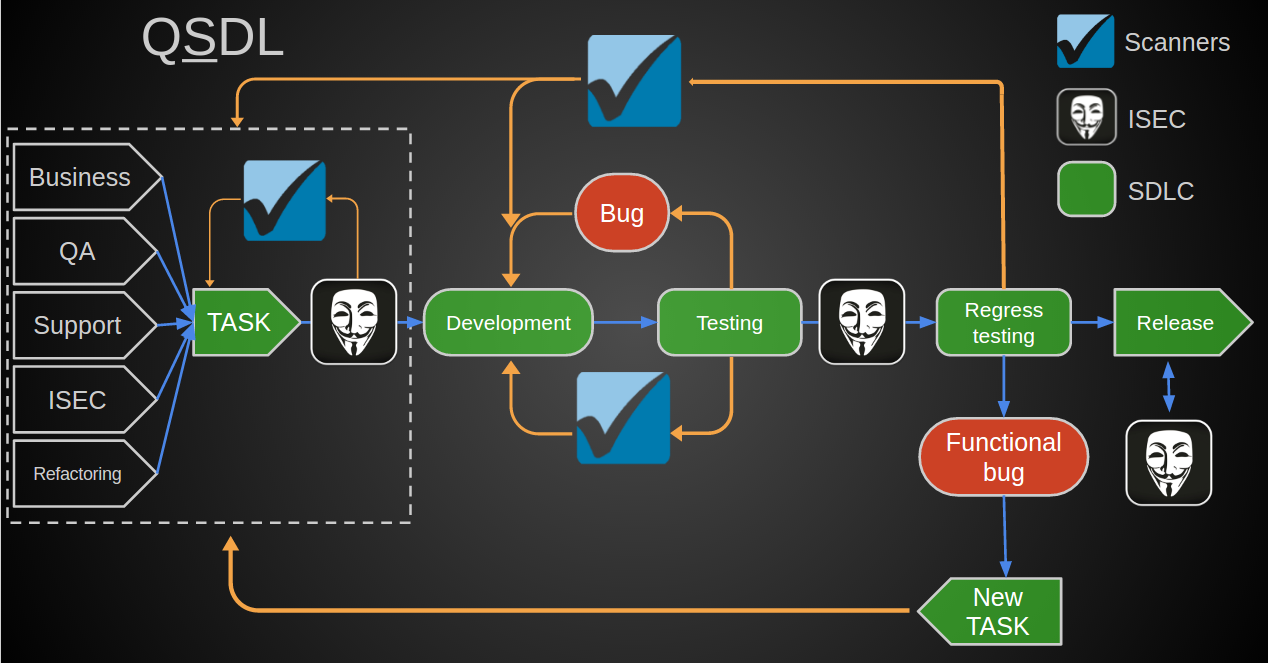
Конечная схема получилась такой:
- Постановка задачи и ее проектирование:
- Привлечение ИБ на этапе начальной аналитики,
- В случае внедрения сторонних продуктов — первоначальное тестирование (blackbox, whitebox, SAST, DAST).
- Разработка с учетом тренингов, консультаций со стороны ИБ.;
- Предрелизное автоматизированное тестирование. Итеративное SAST сканирование dev и тестовых веток в зависимости от build-ветки.;
- Security-review в ISEC:
- SAST релизных веток. В случае найденных уязвимостей ставится метка в build-системе о необходимости исправлений,
- Регрессионный DAST,
- Функциональное тестирование.
- Релиз с последующими фидбэками от участников BugBounty-программы.
Немного сухой статистики:
- На текущий момент в постоянном сканировании находится 70 проектов, помимо тех, которые приходят извне;
- Проекты включают 7 основных языков программирования и обилие платформ;
- За первые пару месяцев внедрения, нашли порядка 25ти критичных уязвимостей на основных проектах;
- На Bug Bounty в два раза снизился поток репортов, конечно учитывая факт появления новых приложений и фич;
- Ну и наверное главное, концепция была внедрена за один год силами 2х человек;
И если изначально задача была связана просто с изменениями процессов для удобства работы и внедрением автоматизированных сканеров, то теперь можно с уверенностью сказать, что она помогла избежать многих ошибок в разработке приложений. А они могли нам стоить много больше чем пара затраченных человеко-лет.
ссылка на оригинал статьи https://habrahabr.ru/post/313530/
Добавить комментарий