
Есть разновидности бизнеса, где перерывы в предоставлении сервиса недопустимы. Например, если у сотового оператора из-за поломки сервера остановится биллинговая система, абоненты останутся без связи. От осознания возможных последствий этого события возникает резонное желание подстраховаться.
Мы расскажем какие есть способы защиты от сбоев серверов и какие архитектуры используют при внедрении VMmanager Cloud: продукта, который предназначен для создания кластера высокой доступности.
Предисловие
В области защиты от сбоев на кластерах терминология в Интернете различается от сайта к сайту. Для того чтобы избежать путаницы, мы обозначим термины и определения, которые будут использоваться в этой статье.
- Отказоустойчивость (Fault Tolerance, FT) — способность системы к дальнейшей работе после выхода из строя какого-либо её элемента.
- Кластер — группа серверов (вычислительных единиц), объединенных каналами связи.
- Отказоустойчивый кластер (Fault Tolerant Cluster, FTC) — кластер, отказ сервера в котором не приводит к полной неработоспособности всего кластера. Задачи вышедшей из строя машины распределяются между одной или несколькими оставшимися нодами в автоматическом режиме.
- Непрерывная доступность (Continuous Availability, CA) — пользователь может в любой момент воспользоваться сервисом, перерывов в предоставлении не происходит. Сколько времени прошло с момента отказа узла не имеет значения.
- Высокая доступность (High Availability, HA) — в случае выхода из строя узла пользователь какое-то время не будет получать услугу, однако восстановление системы произойдёт автоматически; время простоя минимизируется.
- КНД — кластер непрерывной доступности, CA-кластер.
- КВД — кластер высокой доступности, HA-кластер.
Пусть требуется развернуть кластер из 10 узлов, где на каждой ноде запускаются виртуальные машины. Стоит задача защитить виртуальные машины от сбоев оборудования. Для увеличения вычислительной плотности стоек принято решение использовать двухпроцессорные серверы.
На первый взгляд самый привлекательный вариант для бизнеса тот, когда в случае сбоя обслуживание пользователей не прерывается, то есть кластер непрерывной доступности. Без КНД никак не обойтись как минимум в задачах уже упомянутого биллинга абонентов и при автоматизации непрерывных производственных процессов. Однако наряду с положительными чертами такого подхода есть и “подводные камни”. О них следующий раздел статьи.
Continuous availability / непрерывная доступность
Бесперебойное обслуживание клиента возможно только в случае наличия в любой момент времени точной копии сервера (физического или виртуального), на котором запущен сервис. Если создавать копию уже после отказа оборудования, то на это потребуется время, а значит, будет перебой в предоставлении услуги. Кроме этого, после поломки невозможно будет получить содержимое оперативной памяти с проблемной машины, а значит находившаяся там информация будет потеряна.
Для реализации CA существует два способа: аппаратный и программный. Расскажем о каждом из них чуть подробнее.
Аппаратный способ представляет собой “раздвоенный” сервер: все компоненты дублированы, а вычисления выполняются одновременно и независимо. За синхронность отвечает узел, который в числе прочего сверяет результаты с половинок. В случае несоответствия выполняется поиск причины и попытка коррекции ошибки. Если ошибка не корректируется, то неисправный модуль отключается.
На Хабре недавно была статья на тему аппаратных CA-серверов. Описываемый в материале производитель гарантирует, что годовое время простоя не более 32 секунд. Так вот, для того чтобы добиться таких результатов, надо приобрести оборудование. Российский партнёр компании Stratus сообщил, что стоимость CA-сервера с двумя процессорами на каждый синхронизированный модуль составляет порядка $160 000 в зависимости от комплектации. Итого на кластер потребуется $1 600 000.
Программный способ.
На момент написания статьи самый популярный инструмент для развёртывания кластера непрерывной доступности — vSphere от VMware. Технология обеспечения Continuous Availability в этом продукте имеет название “Fault Tolerance”.
В отличие от аппаратного способа данный вариант имеет ограничения в использовании. Перечислим основные:
- На физическом хосте должен быть процессор:
- Intel архитектуры Sandy Bridge (или новее). Avoton не поддерживается.
- AMD Bulldozer (или новее).
- Машины, на которых используется Fault Tolerance, должны быть объединены в 10-гигабитную сеть с низкими задержками. Компания VMware настоятельно рекомендует выделенную сеть.
- Не более 4 виртуальных процессоров на ВМ.
- Не более 8 виртуальных процессоров на физический хост.
- Не более 4 виртуальных машин на физический хост.
- Невозможно использовать снэпшоты виртуальных машин.
- Невозможно использовать Storage vMotion.
Полный список ограничений и несовместимостей есть в официальной документации.
Экспериментально установлено, что технология Fault Tolerance от VMware значительно “тормозит” виртуальную машину. В ходе исследования vmgu.ru после включения FT производительность ВМ при работе с базой данных упала на 47%.
Лицензирование vSphere привязано к физическим процессорам. Цена начинается с $1750 за лицензию + $550 за годовую подписку и техподдержку. Также для автоматизации управления кластером требуется приобрести VMware vCenter Server, который стоит от $8000. Поскольку для обеспечения непрерывной доступности используется схема 2N, для того чтобы работали 10 нод с виртуальными машинами, нужно дополнительно приобрести 10 дублирующих серверов и лицензии к ним. Итого стоимость программной части кластера составит 2*(10+10)*(1750+550)+8000=$100 000.
Мы не стали расписывать конкретные конфигурации нод: состав комплектующих в серверах всегда зависит от задач кластера. Сетевое оборудование описывать также смысла не имеет: во всех случаях набор будет одинаковым. Поэтому в данной статье мы решили считать только то, что точно будет различаться: стоимость лицензий.
Стоит упомянуть и о тех продуктах, разработка которых остановилась.
Есть Remus на базе Xen, бесплатное решение с открытым исходным кодом. Проект использует технологию микроснэпшотов. К сожалению, документация давно не обновлялась; например, установка описана для Ubuntu 12.10, поддержка которой прекращена в 2014 году. И как ни странно, даже Гугл не нашёл ни одной компании, применившей Remus в своей деятельности.
Предпринимались попытки доработки QEMU с целью добавить возможность создания continuous availability кластера. На момент написания статьи существует два таких проекта.
Первый — Kemari, продукт с открытым исходным кодом, которым руководит Yoshiaki Tamura. Предполагается использовать механизмы живой миграции QEMU. Однако тот факт, что последний коммит был сделан в феврале 2011 года говорит о том, что скорее всего разработка зашла в тупик и не возобновится.
Второй — Micro Checkpointing, основанный Michael Hines, тоже open source. К сожалению, уже год в репозитории нет никакой активности. Похоже, что ситуация сложилась аналогично проекту Kemari.
Таким образом, реализации continuous availability на базе виртуализации KVM в данный момент нет.
Итак, практика показывает, что несмотря на преимущества систем непрерывной доступности, есть немало трудностей при внедрении и эксплуатации таких решений. Однако существуют ситуации, когда отказоустойчивость требуется, но нет жёстких требований к непрерывности сервиса. В таких случаях можно применить кластеры высокой доступности, КВД.
High availability / высокая доступность
В контексте КВД отказоустойчивость обеспечивается за счёт автоматического определения отказа оборудования и последующего запуска сервиса на исправном узле кластера.
В КВД не выполняется синхронизация запущенных на нодах процессов и не всегда выполняется синхронизация локальных дисков машин. Стало быть, использующиеся узлами носители должны быть на отдельном независимом хранилище, например, на сетевом хранилище данных. Причина очевидна: в случае отказа ноды пропадёт связь с ней, а значит, не будет возможности получить доступ к информации на её накопителе. Естественно, что СХД тоже должно быть отказоустойчивым, иначе КВД не получится по определению.
Таким образом, кластер высокой доступности делится на два подкластера:
- Вычислительный. К нему относятся ноды, на которых непосредственно запущены виртуальные машины
- Кластер хранилища. Тут находятся диски, которые используются нодами вычислительного подкластера.
На данный момент для реализации КВД с виртуальными машинами на нодах есть следующие инструменты:
- Heartbeat версии 1.х в связке с DRBD;
- Pacemaker;
- VMware vSphere;
- Proxmox VE;
- XenServer;
- Openstack;
- Windows Server Failover Clustering в связке с серверной ролью “Hyper-V”;
- VMmanager Cloud.
Познакомим вас с особенностями нашего продукта VMmanager Cloud.
VMmanager Cloud
Наше решение VMmanager Cloud использует виртуализацию QEMU-KVM. Мы сделали выбор в пользу этой технологии, поскольку она активно разрабатывается и поддерживается, а также позволяет установить любую операционную систему на виртуальную машину. В качестве инструмента для выявления отказов в кластере используется Corosync. Если выходит из строя один из серверов, VMmanager поочерёдно распределяет работавшие на нём виртуальные машины по оставшимся нодам.
В упрощённой форме алгоритм такой:
- Происходит поиск узла кластера с наименьшим количеством виртуальных машин.
- Выполняется запрос хватает ли свободной оперативной памяти для размещения текущей ВМ в списке.
- Если памяти для распределяемой машины достаточно, то VMmanager отдаёт команду на создание виртуальной машины на этом узле.
- Если памяти не хватает, то выполняется поиск на серверах, которые несут на себе большее количество виртуальных машин.
Мы провели тестирование на многих конфигурациях железа, опросили существующих пользователей VMmanager Cloud и на основании полученных данных сделали вывод, что для распределения и возобновления работы всех ВМ с отказавшего узла требуется от 45 до 90 секунд в зависимости от быстродействия оборудования.
Практика показывает, что лучше выделить одну или несколько нод под аварийные ситуации и не развёртывать на них ВМ в период штатной работы. Такой подход исключает ситуацию, когда на “живых” нодах в кластере не хватает ресурсов, чтобы разместить все виртуальные машины с “умершей”. В случае с одним запасным сервером схема резервирования носит название “N+1”.
VMmanager Cloud поддерживает следующие типы хранилищ: файловая система, LVM, Network LVM, iSCSI и Ceph. В контексте КВД используются последние три.
При использовании вечной лицензии стоимость программной части кластера из десяти “боевых” узлов и одного резервного составит €3520 или $3865 на сегодняшний день (лицензия стоит €320 за ноду независимо от количества процессоров на ней). В лицензию входит год бесплатных обновлений, а со второго года они будут предоставляться в рамках пакета обновлений стоимостью €880 в год за весь кластер.
Рассмотрим по каким схемам пользователи VMmanager Cloud реализовывали кластеры высокой доступности.
FirstByte
Компания FirstByte начала предоставлять облачный хостинг в феврале 2016 года. Изначально кластер работал под управлением OpenStack. Однако отсутствие доступных специалистов по этой системе (как по наличию так и по цене) побудило к поиску другого решения. К новому инструменту для управления КВД предъявлялись следующие требования:
- Возможность предоставления виртуальных машин на KVM;
- Наличие интеграции с Ceph;
- Наличие интеграции с биллингом подходящим для предоставления имеющихся услуг;
- Доступная стоимость лицензий;
- Наличие поддержки производителя.
В итоге лучше всего по требованиям подошел VMmanager Cloud.
Отличительные черты кластера:
- Передача данных основана на технологии Ethernet и построена на оборудовании Cisco.
- За маршрутизацию отвечает Cisco ASR9001; в кластере используется порядка 50000 IPv6 адресов.
- Скорость линка между вычислительными нодами и коммутаторами 10 Гбит/с.
- Между коммутаторами и нодами хранилища скорость обмена данными 20 Гбит/с, используется агрегирование двух каналов по 10 Гбит/с.
- Между стойками с нодами хранилища есть отдельный 20-гигабитный линк, используемый для репликации.
- В узлах хранилища установлены SAS-диски в связке с SSD-накопителями.
- Тип хранилища — RBD.
В общем виде система выглядит так:

Данная конфигурация подходит для хостинга сайтов с высокой посещаемостью, для размещения игровых серверов и баз данных с нагрузкой от средней до высокой.
FirstVDS
Компания FirstVDS предоставляет услуги отказоустойчивого хостинга, запуск продукта состоялся в сентябре 2015 года.
К использованию VMmanager Cloud компания пришла из следующих соображений:
- Большой опыт работы с продуктами ISPsystem.
- Наличие интеграции с BILLmanager по умолчанию.
- Отличное качество техподдержки продуктов.
- Поддержка Ceph.
Кластер имеет следующие особенности:
- Передача данных основана на сети Infiniband со скоростью соединения 56 Гбит/с;
- Infiniband-сеть построена на оборудовании Mellanox;
- В узлах хранилища установлены SSD-носители;
- Используемый тип хранилища — RBD.
Общая схема выглядит так:
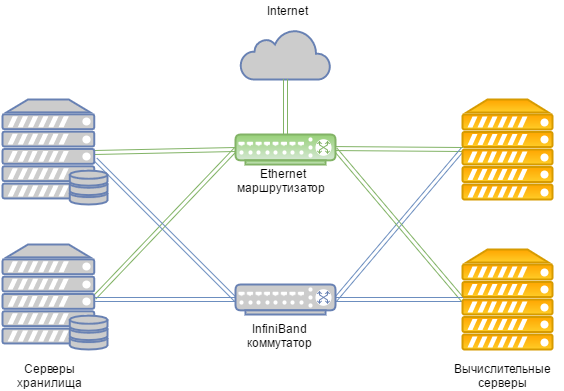
В случае общего отказа Infiniband-сети связь между хранилищем дисков ВМ и вычислительными серверами выполняется через Ethernet-сеть, которая развёрнута на оборудовании Juniper. “Подхват” происходит автоматически.
Благодаря высокой скорости взаимодействия с хранилищем такой кластер подходит для размещения сайтов со сверхвысокой посещаемостью, видеохостинга с потоковым воспроизведением контента, а также для выполнения операций с большими объёмами данных.
Эпилог
Подведём итог статьи.
Если каждая секунда простоя сервиса приносит значительные убытки — не обойтись без кластера непрерывной доступности.
Однако если обстоятельства позволяют подождать 5 минут пока виртуальные машины разворачиваются на резервной ноде, можно взглянуть в сторону КВД. Это даст экономию в стоимости лицензий и оборудования.
Кроме этого не можем не напомнить, что единственное средство повышения отказоустойчивости — избыточность. Обеспечив резервирование серверов, не забудьте зарезервировать линии и оборудование передачи данных, каналы доступа в Интернет, электропитание. Всё что только можно зарезервировать — резервируйте. Такие меры исключают единую точку отказа, тонкое место, из-за неисправности в котором прекращает работать вся система. Приняв все вышеописанные меры, вы получите отказоустойчивый кластер, который действительно трудно вывести из строя.
Если вы решили, что для ваших задач больше подходит схема высокой доступности и выбрали VMmanager Cloud как инструмент для её реализации, к вашим услугам инструкция по установке и документация, которая поможет подробно ознакомиться с системой.
Желаем вам бесперебойной работы!
P. S. Если у вас в организации есть аппаратные CA-серверы — напишите, пожалуйста, в комментариях кто вы и для чего вы их используете. Нам действительно интересно услышать для каких проектов использование такого оборудование экономически целесообразно 🙂
ссылка на оригинал статьи https://habrahabr.ru/post/313066/
Добавить комментарий