 В статье об особенностях новой версии Visual Studio одним из главных нововведений (с моей точки зрения) оказалось разделение ранее монолитного процесса среды разработки (devenv.exe) на компоненты, которые будут работать в отдельных процессах. Это уже сделано для системы контроля версий (переезд с libgit на git.exe) и некоторых плагинов, а в будущем и другие части VS будут вынесены в подпроцессы. В связи с этим в комментариях возник вопрос: «А не замедлит ли это работу, ведь обмен данными между процессами требует использования IPC (Inter Process Communications) ?»
В статье об особенностях новой версии Visual Studio одним из главных нововведений (с моей точки зрения) оказалось разделение ранее монолитного процесса среды разработки (devenv.exe) на компоненты, которые будут работать в отдельных процессах. Это уже сделано для системы контроля версий (переезд с libgit на git.exe) и некоторых плагинов, а в будущем и другие части VS будут вынесены в подпроцессы. В связи с этим в комментариях возник вопрос: «А не замедлит ли это работу, ведь обмен данными между процессами требует использования IPC (Inter Process Communications) ?»
Нет, не замедлит. И вот почему.
Скорость
Для организации общения между процессами в Windows существуют различные технологии: сокеты, именованные каналы, разделяемая память, обмен сообщениями. Поскольку писать полноценный бенчмарк всего вышеуказанного мне не хочется, давайте быстренько поищем что-нибудь похожее на Хабре и найдём статью 6-летней давности, в которой adontz сравнивал производительность сокетов и именованных каналов. Результаты: сокеты — 160 мегабайт в секунду, именованные каналы — 755 мегабайт в секунду. При этом нужно делать поправку на железо 6-летней давности и использованную для тестов платфому .NET. Т.е. можно смело утверждать, что на современном железе с кодом, например, на С мы получим несколько гигабайт в секунду. При этом, как подсказывает Википедия, скорость, например, работы памяти DDR3 составляет, в зависимости от частоты, от 6400 до 19200 МБ/с — и это ведь идеальных МБ/с в вакууме, на практике всегда будет меньше.
Вывод 1: скорость работы пайпов всего в несколько раз меньше максимально возможной скорости работы оперативной памяти. Не в тысячи раз меньше, не на порядки, а всего в несколько раз. Современные ОС хорошо делают свою работу.
Объёмы данных
Давайте возьмём всё те же 755 МБ/с из абзаца выше, как скорость работы именованных каналов. Много это или мало? Ну, если бы вы, например, писали приложение, которое получало бы из именованного канала несжатое FullHD-видео с частотой 60 кадров в секунду и что-нибудь с ним делали (кодировали или стримили) — то вам бы для этого хватило бы 355 МБ/с. Т.е. даже для такой очень затратной операции скорости именованного канала хватило бы с запасом в два с лишним разом. Чем же оперирует Visual Studio в общении со своими компонентами? Ну, например, командами для git.exe и данными из его ответа. Это считанные килобайты, в очень редких случаях — мегабайты. Обмен данными с плагинами вряд ли можно точно оценить (очень разные бывают плагины). Но в любом случае, ни для одного плагина, который я видел, не нужны сотни мегабайт в секунду.
Вывод 2: с учетом специфики данных, обрабатываемых Visual Studio (текст, код, ресурсы, картинки), скорости работы именованных каналов хватает с многократным запасом.
Latency
Ну ок, скажете вы, скорость-скоростью, но есть же ещё и latency. Каждая операция ведь потребует каких-то накладных расходов на синхронизацию. Да, потребует. И об этом я недавно публиковал статью. Люди переоценивают накладные расходы на блокировки и синхронизацию. Беда там не в самих локах (они занимают наносекунды), а в том, что люди пишут плохой синхронный код, допускают дедлоки, лайвлоки, гонки и повреждение разделяемой памяти. К счастью, в случае с именованными каналами сам API намекает на преимущества асинхронного подхода и написать корректно работающий код не так уж сложно.
Вывод 3: пока в асинхронном\многопоточном коде нет багов — он работает достаточно быстро, даже с блокировками.
Практический пример
Ну ок, скажете вы, хватит теории, нужно практическое доказательство! И оно у нас имеется. Это одно из самых популярных в мире десктопных приложений — браузер Google Chrome. Созданный изначально в виде нескольких взаимодействующих процессов, Chrome сразу показал преимущества этого подхода — одна вкладка перестала вешать остальные, смерть плагина не означала больше падение браузера, нагрузка в прорисовке контента в одном окне больше не гарантировала тормозов в другом и т.д. Хром, если упрощённо, запускает один главный процесс, отдельные процессы для рендеринга вкладок, взаимодействия с GPU, плагинов (на самом деле там правила чуть хитрее, Хром умеет оптимизировать количество дочерних процессов в зависимости от разных обстоятельств, но это сейчас не очень важно).
Почитать об архитектуре Хрома можно у них в документации, но вот вам упрощённая картинка:
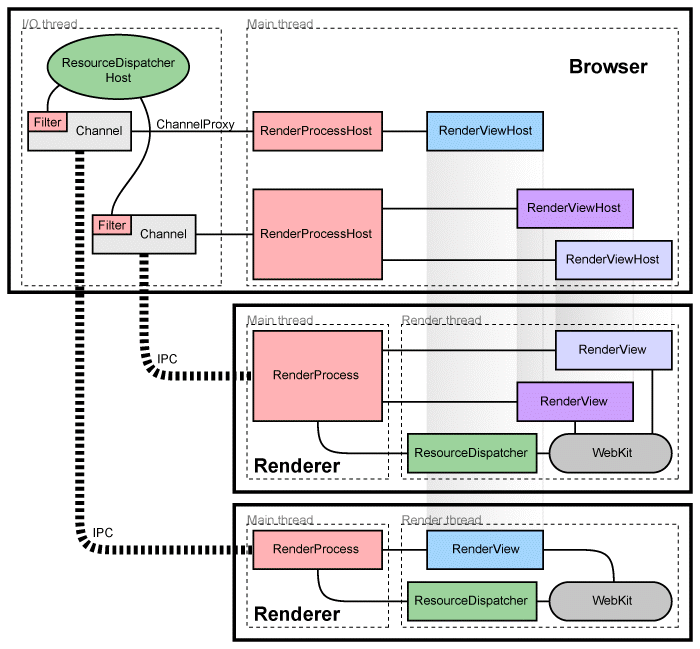
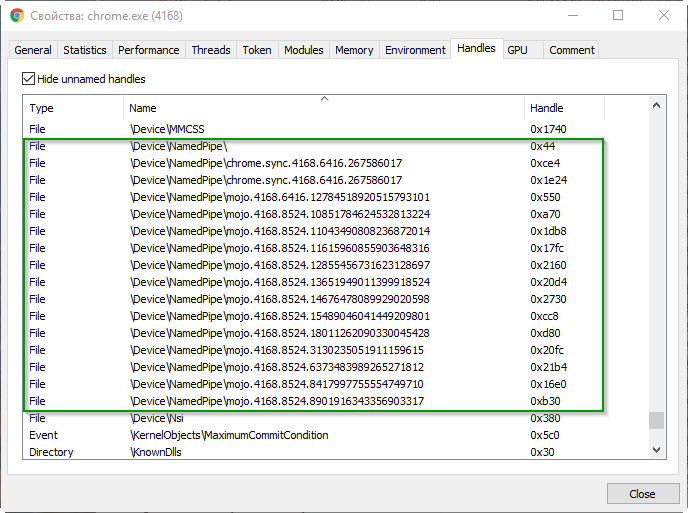
Что же на этой картинке скрывает под линией с раскраской «зебра» и надписью IPC? А вот как-раз именованные каналы и скрываются. Их можно увидеть, например, с помощью приложения Process Hacker (вкладка Handles):
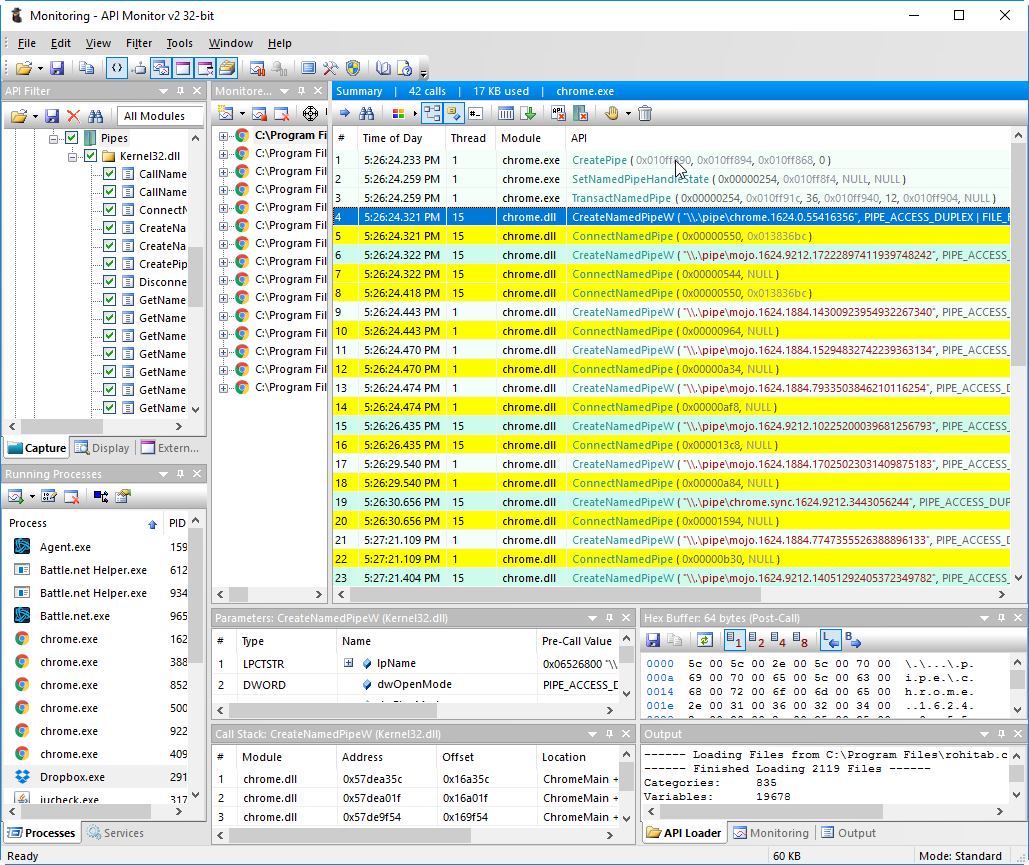
Ну или с помощью Api Monitor:
Насколько же именованные каналы тормозят Chrome? Вы и сами знаете ответ на этот вопрос: ни на сколько. Мультипроцессная архитектура ускоряет браузер, позволяя лучше распределять нагрузку между ядрами, лучше контролировать производительность процессов, эффективнее использовать память. Давайте, например, оценим, сколько данных Chrome гоняет через свои именованные каналы при проигрывании одной минуты видео с Youtube. Для этого можно воспользоваться хорошей утилитой IO Ninja (нормально поток данных по пайпу, к их стыду, не показывают ни Wireshark, ни API Monitor, ни утилиты Sysinternals — позор!):
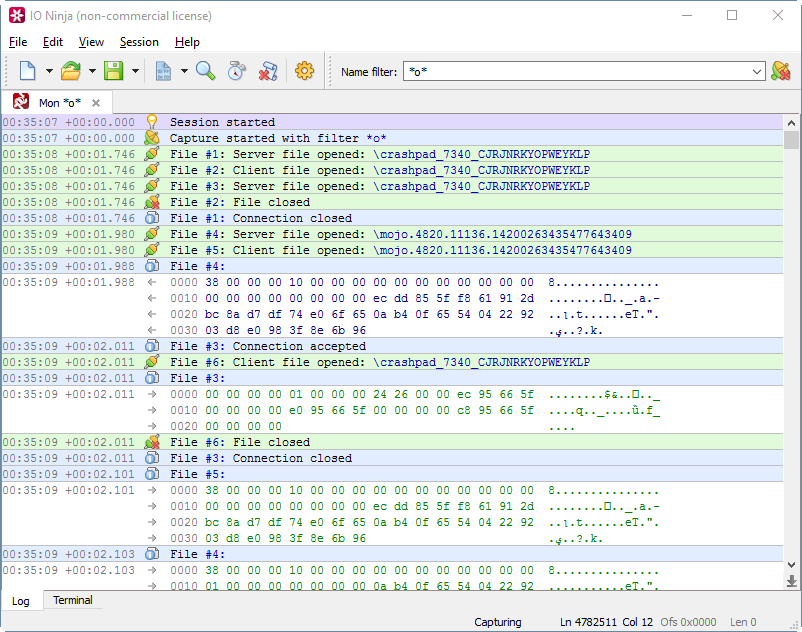
Замер показал, что за 1 минуту проигрывания Youtube-видео Chrome передаёт через именованные каналы 76 МБ данных. При этом отдельных операций чтения\записи произошло 79715 штук. Как видите, даже такую серьёзную программу, как Chrome, даже на таком неслабом сайте, как Youtube, именованные каналы ни сколько не смутили. Так что и у Visual Studio есть все шансы выиграть от разделения монолитной IDE на подпроцессы.
ссылка на оригинал статьи https://habrahabr.ru/post/313638/
Добавить комментарий