
Казалось бы, Chromium был рассмотрен нами неоднократно. Внимательный читатель задастся логичным вопросом: «Зачем нужна еще одна проверка? Разве было недостаточно?». Бесспорно, код Chromium отличается чистотой, в чем мы убеждались каждый раз при проверке, однако ошибки неизбежно продолжают выявляться. Повторные проверки хорошо демонстрируют, что чем чаще будет применяться статический анализ, тем лучше. Хорошо, если проект проверяется каждый день. Ещё лучше, если анализатор используется программистами непосредственно при работе (автоматический анализ изменённого кода).
Немного предыстории
Chromium проверялся с помощью PVS-Studio уже четыре раза:
- первая проверка (23.05.2011)
- вторая проверка (13.10.2011)
- третья проверка (12.08.2013)
- четвертая проверка (02.12.2013)
Ранее все проверки были произведены Windows-версией анализатора PVS-Studio. С недавнего времени PVS-Studio работает и под Linux, поэтому для анализа использовалась именно эта версия.
За это время проект вырос в размерах: в третью проверку число проектов достигало отметки 1169. На момент написания статьи их стало 4420. Заметно вырос и объем исходного кода до 370 Мб (на 2013 год размер составлял 260 Мб).
За четыре проверки было отмечено высочайшее качество кода для столь большого проекта. Изменилась ли ситуация спустя два с половиной года? Нет. Качество по-прежнему на высоте. Однако из-за большого объема кода и постоянного его развития мы вновь находим много ошибок.
А как проверять?
Остановимся подробнее на том, как произвести проверку Chromium. На этот раз мы сделаем это в Linux. После загрузки исходников с помощью depot_tools и подготовки (подробнее здесь, до раздела Building) собираем проект:
pvs-studio-analyzer trace -- ninja -C out/Default chromeДалее выполняем команду (это одна строка):
pvs-studio-analyzer analyze -l /path/to/PVS-Studio.lic -o /path/to/save/chromium.log -j<N>где флаг "-j" запускает анализ в многопоточном режиме. Рекомендуемое число потоков — число физических ядер CPU плюс один (например, на четырехъядерном процессоре флаг будет выглядеть как "-j5").
В результате будет получен отчет анализатора PVS-Studio. При помощи утилиты PlogConverter, которая идет в составе дистрибутива PVS-Studio, его можно перевести в один из трех удобочитаемых форматов: xml, errorfile, tasklist. Мы будем использовать для просмотра сообщений формат tasklist. В текущей проверке будут просматриваться только предупреждения общего назначения (General Analysis) всех уровней (High, Medium, Low). Команда конвертации будет выглядеть следующим образом (одной строкой):
plog-converter -t tasklist -o /path/to/save/chromium.tasks -a GA:1,2,3 /path/to/saved/chromium.logПодробнее о всех параметрах PlogConverter’а можно прочитать здесь. Загрузку tasklist’а «chromium.tasks» в QtCreator (должен быть предварительно установлен) выполним при помощи команды:
qtcreator path/to/saved/chromium.tasksКрайне рекомендуется начать просмотр отчета с предупреждений уровней High и Medium — вероятность, что найдутся ошибочные инструкции в коде, будет очень высока. Предупреждения уровня Low также могут указывать на потенциальные ошибки, но вероятность ложного срабатывания у них выше, поэтому при написании статей они, как правило, не изучаются.
Сам же просмотр отчета в QtCreator будет выглядеть следующим образом:
{kind=link}
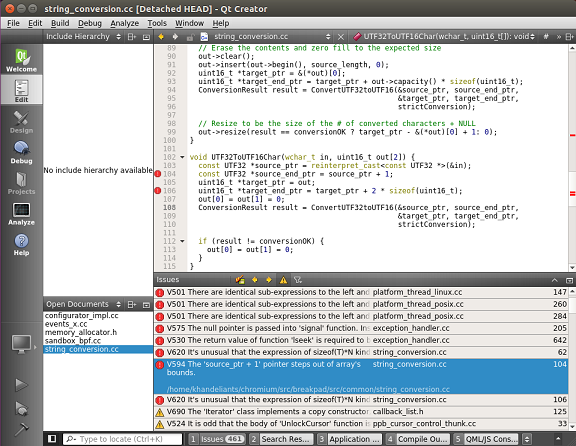
Рисунок 1 — Работа с результатами анализатора из-под QtCreator (нажмите на картинку для увеличения)
Что поведал анализатор?
После проверки проекта Chromium было получено 2312 предупреждений. На следующей диаграмме представлено распределение предупреждений по уровням важности:
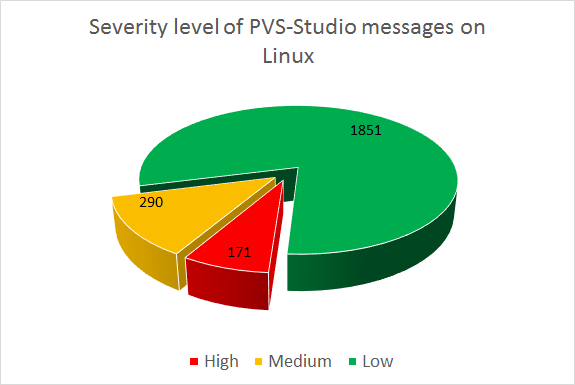
Рисунок 2 — Распределение предупреждений по уровням важности
Кратко прокомментируем приведенную диаграмму: было получено 171 предупреждений уровня High, 290 предупреждений уровня Medium, 1851 предупреждение уровня Low.
Несмотря на достаточно большое число предупреждений, для такого гигантского проекта это немного. Суммарное количество строк исходного кода (SLOC) без библиотек — 6468751. Если учитывать только предупреждения уровня High и Medium, то среди них я, пожалуй, могу указать на 220 настоящих ошибок. Цифры цифрами, а на деле получаем плотность ошибок, равной 0,034 ошибки на 1000 строк кода. Это, конечно, плотность не всех ошибок, а только тех, которые находит PVS-Studio. А вернее — тех ошибок, которые заметил я, просматривая отчет.
Как правило, на других проектах мы получаем большую плотность найденных ошибок. Разработчики Chromium молодцы! Впрочем, расслабляться не стоит: ошибки есть, и они далеко небезобидные.
Рассмотрим подробнее наиболее интересные ошибки.
Новые найденные ошибки
Copy-Paste

Предупреждение анализатора: V501 There are identical sub-expressions ‘request_body_send_buf_ == nullptr’ to the left and to the right of the ‘&&’ operator. http_stream_parser.cc 1222
bool HttpStreamParser::SendRequestBuffersEmpty() { return request_headers_ == nullptr && request_body_send_buf_ == nullptr && request_body_send_buf_ == nullptr; // <= }Классика жанра. Программист дважды сравнил указатель request_body_send_buf_ с nullptr. Вероятно, это опечатка, и с nullptr следовало сравнить ещё какой-то член класса.
Предупреждение анализатора: V766 An item with the same key ‘«colorSectionBorder»’ has already been added. ntp_resource_cache.cc 581
void NTPResourceCache::CreateNewTabCSS() { .... substitutions["colorSectionBorder"] = // <= SkColorToRGBAString(color_section_border); .... substitutions["colorSectionBorder"] = // <= SkColorToRGBComponents(color_section_border); .... }Анализатор сообщает о подозрительной двойной инициализации объекта по ключу «colorSectionBorder». Переменная substitutions в данном контексте является ассоциативным массивом. В первой инициализации переменная color_section_border типа SkColor (определен как uint32_t) переводится в строковое представление RGBA (судя из названия метода SkColorToRGBAString) и сохраняется по ключу «colorSectionBorder». При повторном присваивании color_section_border конвертируется уже в другой строковый формат (метод SkColorToRGBComponents) и записывается по тому же самому ключу. Это означает, что предыдущее значение по ключу «colorSectionBorder» будет уничтожено. Возможно, так и задумывалось, но тогда одну из инициализаций следует убрать. В ином случае следует сохранять компоненты цвета по другому ключу.
Примечание. Кстати, это первая ошибка, найденная с помощью диагностики V766 в реальном проекте. Тип ошибки достаточно специфичен, но проект Chromium столь велик, что в нём можно повстречать и экзотические дефекты.
Неверная работа с указателями

Предлагаю читателям немного размяться и попытаться найти ошибку самостоятельно.
// Returns the item associated with the component |id| or nullptr // in case of errors. CrxUpdateItem* FindUpdateItemById(const std::string& id) const; void ActionWait::Run(UpdateContext* update_context, Callback callback) { .... while (!update_context->queue.empty()) { auto* item = FindUpdateItemById(update_context->queue.front()); if (!item) { item->error_category = static_cast<int>(ErrorCategory::kServiceError); item->error_code = static_cast<int>(ServiceError::ERROR_WAIT); ChangeItemState(item, CrxUpdateItem::State::kNoUpdate); } else { NOTREACHED(); } update_context->queue.pop(); } .... }Предупреждение анализатора: V522 Dereferencing of the null pointer ‘item’ might take place. action_wait.cc 41
Здесь программист решил явным способом прострелить себе ногу. В коде последовательно обходится очередь queue, содержащая идентификаторы в строковых представлениях. Из очереди извлекается идентификатор, затем метод FindUpdateItemById должен вернуть указатель на объект типа CrxUpdateItem по идентификатору. Если в методе FindUpdateItemById произойдет ошибка, то будет возвращен nullptr, который затем разыменуется в ветке then оператора if.
Корректный код может выглядеть следующим образом:
.... while (!update_context->queue.empty()) { auto* item = FindUpdateItemById(update_context->queue.front()); if (item != nullptr) { .... } .... } ....Предупреждение анализатора: V620 It’s unusual that the expression of sizeof(T)*N kind is being summed with the pointer to T type. string_conversion.cc 62
int UTF8ToUTF16Char(const char *in, int in_length, uint16_t out[2]) { const UTF8 *source_ptr = reinterpret_cast<const UTF8 *>(in); const UTF8 *source_end_ptr = source_ptr + sizeof(char); uint16_t *target_ptr = out; uint16_t *target_end_ptr = target_ptr + 2 * sizeof(uint16_t); // <= out[0] = out[1] = 0; .... }Анализатор обнаружил код с подозрительной адресной арифметикой. Как видно из названия, функция конвертирует символ из кодировки UTF-8 в UTF-16. Действующий стандарт Unicode 6.х предполагает расширение символа UTF-8 до четырех байт. В связи с этим, UTF-8 символ декодируется как 2 символа UTF-16 (UTF-16 символ кодируется жестко двумя байтами). Для декодирования используются 4 указателя — указатели на начало и конец массивов in и out. Указатели на конец массивов в коде действуют подобно итераторам STL: они ссылаются на область памяти за последним элементом в массиве. Если в случае с source_end_ptr указатель был получен верно, то с target_end_ptr все не так «радужно». Подразумевалось, что он должен был ссылаться на область памяти за вторым элементом массива out (то есть сместиться относительно указателя out на 4 байта), однако вместо этого указатель будет ссылаться на область памяти за четвертым элементом (смещение out на 8 байт).
Проиллюстрируем сказанные слова, как должно было быть:
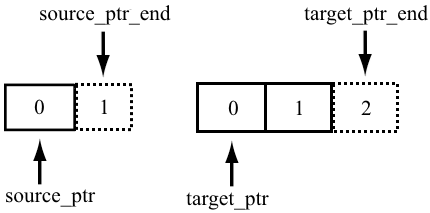
Как получилось на самом деле:

Корректный код должен выглядеть следующим образом:
int UTF8ToUTF16Char(const char *in, int in_length, uint16_t out[2]) { const UTF8 *source_ptr = reinterpret_cast<const UTF8 *>(in); const UTF8 *source_end_ptr = source_ptr + 1; uint16_t *target_ptr = out; uint16_t *target_end_ptr = target_ptr + 2; out[0] = out[1] = 0; .... }Анализатор также обнаружил еще одно подозрительное место:
- V620 It’s unusual that the expression of sizeof(T)*N kind is being summed with the pointer to T type. string_conversion.cc 106
Различные ошибки

Предлагаю снова размяться и попробовать найти ошибку в коде самостоятельно.
CheckReturnValue& operator=(const CheckReturnValue& other) { if (this != &other) { DCHECK(checked_); value_ = other.value_; checked_ = other.checked_; other.checked_ = true; } }Предупреждение анализатора: V591 Non-void function should return a value. memory_allocator.h 39
В коде выше имеет место неопределенное поведение: стандарт C++ говорит, что любой non-void метод должен возвращать значение. Что же в коде выше? В операторе присваивания происходит проверка на присваивание самому себе (сравнение объектов по их указателям) и копирование полей (если указатели разные). Однако, метод не вернул ссылку на самого себя (return *this).
Нашлось еще пару мест в проекте, где non-void метод не возвращает значения:
- V591 Non-void function should return a value. sandbox_bpf.cc 115
- V591 Non-void function should return a value. events_x.cc 73
Предупреждение анализатора: V583 The ‘?:’ operator, regardless of its conditional expression, always returns one and the same value: 1. configurator_impl.cc 133
int ConfiguratorImpl::StepDelay() const { return fast_update_ ? 1 : 1; }Код всегда возвращает задержку, равной единице. Возможно, это задел на будущее, но пока от такого тернарного оператора нет пользы.
Предупреждение анализатора: V590 Consider inspecting the ‘rv == OK || rv != ERR_ADDRESS_IN_USE’ expression. The expression is excessive or contains a misprint. udp_socket_posix.cc 735
int UDPSocketPosix::RandomBind(const IPAddress& address) { DCHECK(bind_type_ == DatagramSocket::RANDOM_BIND && !rand_int_cb_.is_null()); for (int i = 0; i < kBindRetries; ++i) { int rv = DoBind(IPEndPoint(address, rand_int_cb_ .Run(kPortStart, kPortEnd))); if (rv == OK || rv != ERR_ADDRESS_IN_USE) // <= return rv; } return DoBind(IPEndPoint(address, 0)); }Анализатор предупреждает о возможном избыточном сравнении. В коде происходит привязка случайного порта к IP адресу. Если привязка произошла успешно, то останавливается цикл (который означает число попыток привязки порта к адресу). Исходя из логики, можно оставить одно из сравнений (сейчас цикл останавливается, если привязка произошла успешно, или не возвращена ошибка использования порта другим адресом).
Предупреждение анализатора: V523 The ‘then’ statement is equivalent to the ‘else’ statement.
bool ResourcePrefetcher::ShouldContinueReadingRequest( net::URLRequest* request, int bytes_read ) { if (bytes_read == 0) { // When bytes_read == 0, no more data. if (request->was_cached()) FinishRequest(request); // <= else FinishRequest(request); // <= return false; } return true; }Анализатор сообщил об одинаковых операторах в ветвях then и else оператора if. К чему это может привести? Исходя из кода, некэшированный URL запрос (net::URLRequest *request) будет завершен также, как и кэшированный. Если так и должно быть, тогда можно убрать оператор ветвления:
.... if (bytes_read == 0) { // When bytes_read == 0, no more data. FinishRequest(request); // <= return false; } ....Если же подразумевалась другая логика, то будет вызван не тот метод, что может привести к «бессонным ночам» и «морю кофе».
Предупреждение анализатора: V609 Divide by zero. Denominator range [0..4096]. addr.h 159
static int BlockSizeForFileType(FileType file_type) { switch (file_type) { .... default: return 0; // <= } } static int RequiredBlocks(int size, FileType file_type) { int block_size = BlockSizeForFileType(file_type); return (size + block_size - 1) / block_size; // <= }Что же мы видим здесь? Данный код может привести к трудноуловимой ошибке: в методе RequiredBlocks происходит деление на значение переменной block_size (вычисляется при помощи метода BlockSizeForFileType). В методе BlockSizeForFileType по переданному значению перечисления FileType в switch-операторе происходит возврат некоторого значения, однако было также предусмотрено значение по умолчанию — 0. Представим, что перечисление FileType решили расширить и добавили новое значение, но не добавили новую case-ветвь в switch-операторе. Приведет это к неопределенному поведению: по стандарту C++ деление на ноль не вызывает программного исключения. Вместо него будет вызвано аппаратное исключение, которое не отловить стандартным блоком try/catch (вместо этого применяются обработчики сигналов, подробнее можно почитать тут и тут).
Предупреждение анализатора: V519 The ‘* list’ variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 136, 138. util.cc 138
bool GetListName(ListType list_id, std::string* list) { switch (list_id) { .... case IPBLACKLIST: *list = kIPBlacklist; break; case UNWANTEDURL: *list = kUnwantedUrlList; break; case MODULEWHITELIST: *list = kModuleWhitelist; // <= case RESOURCEBLACKLIST: *list = kResourceBlacklist; break; default: return false; } .... }Типичная ошибка при написании switch-оператора. Ожидается, что если переменная list_id примет значение MODULEWHITELIST из перечисления ListType, то строка по указателю list инициализируется значением kModuleWhitelist и прервется выполнение switch-оператора. Однако из-за пропущенного оператора break произойдет переход на следующую ветку RESOURCEBLACKLIST, и в *list на самом деле будет сохранена строка kResourceBlacklist.
Выводы
Chromium остается «крепким орешком». И всё равно анализатор PVS-Studio вновь и вновь может находить в нем ошибки. При использовании методов статического анализа ошибки могут быть найдены еще на этапе написания кода, до этапа тестирования.
Какие инструменты можно использовать для статического анализа кода? На самом деле инструментов много. Я же естественно предлагаю попробовать PVS-Studio: продукт очень удобно интегрируется в среду Visual Studio, или возможно его применение с любой системой сборки. А с недавнего времени стала доступна и версия для Linux. Подробнее с информацией про Windows и Linux версии можно ознакомиться здесь и здесь.
ссылка на оригинал статьи https://habrahabr.ru/post/313670/
Добавить комментарий