На сегодняшний день процедура реализации «failover» в Postgresql является одной из самых простых и интуитивно понятных. Для ее реализации необходимо определиться со сценариями файловера — это залог успешной работы кластера, протестировать его работу. В двух словах — настраивается репликация, чаще всего асинхронная, и в случае отказа текущего мастера, другая нода(standby) становится текущем «мастером», другие ноды standby начинают следовать за новым мастером.
На сегодняшний день repmgr поддерживает сценарий автоматического Failover — autofailover, что позволяет поддерживать кластер в рабочем состоянии после выхода из строя ноды-мастера без мгновенного вмешательства сотрудника, что немаловажно, так как не происходит большого падения UPTIME. Для уведомлений используем telegram.
Появилась необходимость в связи с развитием внутренних сервисов реализовать систему хранения БД на Postgresql + репликация + балансировка + failover(отказоустойчивость). Как всегда в интернете вроде бы что то и есть, но всё оно устаревшее или на практике не реализуемое в том виде, в котором оно представлено. Было решено представить данное решение, чтобы в будущем у специалистов, решивших реализовать подобную схему было представление как это делается, и чтобы новичкам было легко это реализовать следуя данной инструкции. Постарались описать все как можно подробней, вникнуть во все нюансы и особенности.
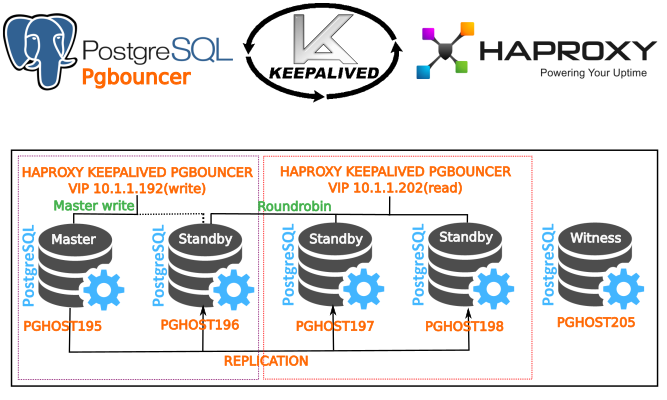
Итак, что мы имеем: 5 VM с debian 8,Postgresql 9.6 + repmgr (для управления кластером), балансировка и HA на базе HAPROXY (ПО для обеспечения балансировки и высокой доступности web приложения и баз данных) и легковесного менеджера подключений Pgbouncer, keepalived для миграции ip адреса(VIP) между нодами,5-я witness нода для контроля кластера и предотвращения “split brain” ситуаций, когда не могла быть определена следующая мастер нода после отказа текущего мастера. Уведомления через telegram( без него как без рук).
Пропишем ноды /etc/hosts — для удобства, так как в дальнейшем все будет оперировать с доменными именами.
10.1.1.195 - pghost195 10.1.1.196 - pghost196 10.1.1.197 - pghost197 10.1.1.198 - pghost198 10.1.1.205 - pghost205
VIP 10.1.1.192 — запись, 10.1.1.202 — roundrobin(балансировка/только чтение).
Установка Postgresql 9.6 pgbouncer haproxy repmgr
Ставим на все ноды
touch /etc/apt/sources.list.d/pgdg.list echo “deb http://apt.postgresql.org/pub/repos/apt/ jessie-pgdg main” > /etc/apt/sources.list.d/pgdg.list wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | apt-key add - apt-get update wget http://ftp.ru.debian.org/debian/pool/main/p/pkg-config/pkg-config_0.28-1_amd64.deb dpkg -i pkg-config_0.28-1_amd64.deb apt-get install postgresql-9.6-repmgr libevent-dev -y
Отключаем автозапуск Postgresql при старте системы — всеми процессами будет управлять пользователь postgres. Так же это необходимо, для того, чтобы бы не было ситуаций, когда у нас сможет оказаться две мастер-ноды, после восстановления одной после сбоя питания, например.
nano /etc/postgresql/9.1/main/start.conf заменяем auto на manual
Настройка ssh соединения без пароля — между всеми нодами(делаем на всех серверах)
Настроим подключения между всеми серверами и к самому себе через пользователя postgres(через пользователя postgres подключается также repmgr).
Установим пакеты, которые нам понадобятся для работы(сразу ставим)
apt-get install openssh-server rsync -y
Для начала установим ему локальный пароль для postgres (сразу проделаем это на всех нодах).
passwd postgres
Введем новый пароль.
Ок.
Далее настроим ssh соединение
su postgres cd ~ ssh-keygen
Генерируем ключ — без пароля.
Ставим ключ на другие ноды
ssh-copy-id -i ~/.ssh/id_rsa.pub postgres@pghost195 ssh-copy-id -i ~/.ssh/id_rsa.pub postgres@pghost196 ssh-copy-id -i ~/.ssh/id_rsa.pub postgres@pghost197 ssh-copy-id -i ~/.ssh/id_rsa.pub postgres@pghost198 ssh-copy-id -i ~/.ssh/id_rsa.pub postgres@pghost205
Для того чтобы ssh не спаршивала доверяете ли вы хосту и не выдавала другие предупреждения и ограничения, касающиеся политики безопасности, можем добавить в файл
nano /etc/ssh/ssh_config StrictHostKeyChecking no UserKnownHostsFile=/dev/null
Рестартуем ssh.
Данная опция удобная когда вы не слишком заботитесь о безопасности, например для тестирования кластера.
Перейдем на ноду 2,3,4 и всё повторим. Теперь мы можем гулять без паролей между нодами для переключения их состояния(назначения нового мастера и standby).
Ставим pgbouncer из git
Установим необходимые пакеты для сборки
apt-get install libpq-dev checkinstall build-essential libpam0g-dev libssl-dev libpcre++-dev libtool automake checkinstall gcc+ git -y cd /tmp git clone https://github.com/pgbouncer/pgbouncer.git cd pgbouncer git submodule init git submodule update ./autogen.sh wget https://github.com/libevent/libevent/releases/download/release-2.0.22-stable/libevent-2.0.22-stable.tar.gz tar -xvf libevent-2.0.22-stable.tar.gz cd libevent* ./configure checkinstall cd ..
Если хотите postgresql с PAM авторизацией — то ставим еще дом модуль и при configure ставим —with-pam
./configure --prefix=/usr/local --with-libevent=libevent-prefix --with-pam make -j4 mkdir -p /usr/local/share/doc; mkdir -p /usr/local/share/man; checkinstall
Ставим версию — 1.7.2 (на ноябрь 2016 года).
Готово. Видим
Done. The new package has been installed and saved to /tmp/pgbouncer/pgbouncer_1.7.2-1_amd64.deb You can remove it from your system anytime using: dpkg -r pgbouncer_1.7.2-1_amd64.deb
Обязательно настроим окружение — добавим переменную PATH=/usr/lib/postgresql/9.6/bin:$PATH(на каждой ноде).
Добавим в файл ~/.bashrc
su postgres cd ~ nano .bashrc
Вставим код
PATH=$PATH:/usr/lib/postgresql/9.6/bin export PATH export PGDATA="$HOME/9.6/main"
Сохранимся.
Скопируем файл на .bashrc другие ноды
su postgres cd ~ scp .bashrc postgres@pghost195:/var/lib/postgresql scp .bashrc postgres@pghost196:/var/lib/postgresql scp .bashrc postgres@pghost197:/var/lib/postgresql scp .bashrc postgres@pghost198:/var/lib/postgresql scp .bashrc postgres@pghost205:/var/lib/postgresql
Настройке сервера в качестве мастера(pghost195)
Отредактируем конфиг /etc/postgresql/9.6/main/postgresql.conf — Приводим к виду необходимые опции(просто добавим в конец файла).
listen_addresses='*' wal_level = 'hot_standby' archive_mode = on wal_log_hints = on archive_command = 'cd .' max_wal_senders = 10 max_replication_slots = 1 # Такой же в /etc/repmgr.conf !!must be!! hot_standby = on shared_preload_libraries = 'repmgr_funcs, pg_stat_statements' ####подключаемая библиотека repmgr и статистики postgres max_connections = 800 max_wal_senders = 10 wal_keep_segments = 3000 # чем больше, тем длиннее будет журнал тем проще будет standby ноде догнать master’a. max_replication_slots = 8 port = 5433 pg_stat_statements.max = 10000 pg_stat_statements.track = all
Как мы видим — будем запускать postgresql на порту 5433 — потому-что дефолтный порт для приложений будем использовать для других целей — а именно для балансировки, проксирования и failover’a. Вы же можете использовать любой порт, как вам удобно.
Настроим файл подключений
nano /etc/postgresql/9.6/main/pg_hba.conf
Приведем к виду
# IPv6 local connections: host all all ::1/128 md5 local all postgres peer local all all peer host all all 127.0.0.1/32 md5 #######################################Тут мы настроили соединения для управления репликацией и управления состоянием нод (MASTER, STAND BY). local replication repmgr trust host replication repmgr 127.0.0.1/32 trust host replication repmgr 10.1.1.0/24 trust local repmgr repmgr trust host repmgr repmgr 127.0.0.1/32 trust host repmgr repmgr 10.1.1.0/24 trust ###################################### host all all 0.0.0.0/32 md5 #######Подключение для всех по паролю #####################################
Применим права к конфигам, иначе будет ругаться на pg_hba.conf
chown -R -v postgres /etc/postgresql
Стартуем postgres(от postgres user).
pg_ctl -D /etc/postgresql/9.6/main --log=/var/log/postgresql/postgres_screen.log start
Настройка пользователей и базы на Master-сервере(pghost195).
su postgres cd ~
Создадим пользователя repmgr.
psql # create role repmgr with superuser noinherit; # ALTER ROLE repmgr WITH LOGIN; # create database repmgr; # GRANT ALL PRIVILEGES on DATABASE repmgr to repmgr; # ALTER USER repmgr SET search_path TO repmgr_test, "$user", public;
Создадим пользователя test_user с паролем 1234
create user test_user; ALTER USER test_user WITH PASSWORD '1234';
Конфигурируем repmgr на master
nano /etc/repmgr.conf
Содержимое
cluster=etagi_test node=1 node_name=node1 use_replication_slots=1 conninfo='host=pghost195 port=5433 user=repmgr dbname=repmgr' pg_bindir=/usr/lib/postgresql/9.6/bin
Сохраняемся.
Регистрируем сервер как мастер.
su postgres repmgr -f /etc/repmgr.conf master register
Смотрим наш статус
repmgr -f /etc/repmgr.conf cluster show
Видим
Role | Name | Upstream | Connection String ----------+-------|----------|-------------------------------------------------- * master | node1 | | host=pghost195 port=5433 user=repmgr dbname=repmgr
Идем дальше.
Настройка слейвов(standby) — pghost196,pghost197,pghost198
Конфигурируем repmgr на slave1(pghost197)
nano /etc/repmgr.conf — создаем конфиг
Содержимое
cluster=etagi_test node=2 node_name=node2 use_replication_slots=1 conninfo='host=pghost196 port=5433 user=repmgr dbname=repmgr' pg_bindir=/usr/lib/postgresql/9.6/bin
Сохраняемся.
Регистрируем сервер как standby
su postgres cd ~/9.6/ rm -rf main/* repmgr -h pghost1 -p 5433 -U repmgr -d repmgr -D main -f /etc/repmgr.conf --copy-external-config-files=pgdata --verbose standby clone pg_ctl -D /var/lib/postgresql/9.6/main --log=/var/log/postgresql/postgres_screen.log start
Будут скопированы конфиги на основании которых будет происходит переключение состояний master и standby серверов.
Просмотрим файлы, которые лежат в корне папки /var/lib/postgresql/9.6/main — обязательно должны быть эти файлы.
PG_VERSION backup_label pg_hba.conf pg_ident.conf postgresql.auto.conf postgresql.conf recovery.conf
Регистрируем сервер в кластере
su postgres repmgr -f /etc/repmgr.conf standby register; repmgr -f /etc/repmgr.conf cluster show Просмотр состояния кластера repmgr -f /etc/repmgr.conf cluster show Видим <spoiler title=""> <source lang="bash"> Role | Name | Upstream | Connection String ----------+-------|----------|-------------------------------------------------- * master | node195 | | host=pghost195 port=5433 user=repmgr dbname=repmgr standby | node196 | node1 | host=pghost196 port=5433 user=repmgr dbname=repmgr
Настройка второго stand-by — pghost197
Конфигурируем repmgr на pghost197
nano /etc/repmgr.conf — создаем конфиг
Содержимое
cluster=etagi_test node=3 node_name=node3 use_replication_slots=1 conninfo='host=pghost197 port=5433 user=repmgr dbname=repmgr' pg_bindir=/usr/lib/postgresql/9.6/bin
Сохраняемся.
Регистрируем сервер как standby
su postgres cd ~/9.6/ rm -rf main/* repmgr -h pghost195 -p 5433 -U repmgr -d repmgr -D main -f /etc/repmgr.conf --copy-external-config-files=pgdata --verbose standby clone
или
repmgr -D /var/lib/postgresql/9.6/main -f /etc/repmgr.conf -d repmgr -p 5433 -U repmgr -R postgres --verbose --force --rsync-only --copy-external-config-files=pgdata standby clone -h pghost195
Данная команда с опцией -r/—rsync-only — используется в некоторых случаях, например, когда копируемый каталог данных — это каталог данных отказавшего сервера с активным узлом репликации.
Также будут скопированы конфиги на основании которых будет происходит переключение состояний master и standby серверов.
Просмотрим файлы, которые лежат в корне папки /var/lib/postgresql/9.6/main — обязательно должны быть следующие файлы:
PG_VERSION backup_label pg_hba.conf pg_ident.conf postgresql.auto.conf postgresql.conf recovery.conf
Стартуем postgres(от postgres)
pg_ctl -D /var/lib/postgresql/9.6/main --log=/var/log/postgresql/postgres_screen.log start
Регистрируем сервер в кластере
su postgres repmgr -f /etc/repmgr.conf standby register
Просмотр состояния кластера
repmgr -f /etc/repmgr.conf cluster show
Видим
Role | Name | Upstream | Connection String ----------+-------|----------|-------------------------------------------------- * master | node1 | | host=pghost1 port=5433 user=repmgr dbname=repmgr standby | node2 | node1 | host=pghost2 port=5433 user=repmgr dbname=repmgr standby | node3 | node1 | host=pghost2 port=5433 user=repmgr dbname=re
Настройка каскадной репликации.
Вы также можете настроить каскадную репликацию. Рассмотрим пример.
Конфигурируем repmgr на pghost198 от pghost197
nano /etc/repmgr.conf — создаем конфиг
Содержимое
cluster=etagi_test node=4 node_name=node4 use_replication_slots=1 conninfo='host=pghost198 port=5433 user=repmgr dbname=repmgr' pg_bindir=/usr/lib/postgresql/9.6/bin upstream_node=3
Сохраняемся. Как мы видим, что в upstream_node мы указали node3, которой является pghost197.
Регистрируем сервер как standby от standby
su postgres cd ~/9.6/ rm -rf main/* repmgr -h pghost197 -p 5433 -U repmgr -d repmgr -D main -f /etc/repmgr.conf --copy-external-config-files=pgdata --verbose standby clone
Стартуем postgres(от postgres)
pg_ctl -D /var/lib/postgresql/9.6/main --log=/var/log/postgresql/postgres_screen.log start
Регистрируем сервер в кластере
su postgres repmgr -f /etc/repmgr.conf standby register
Просмотр состояния кластера
repmgr -f /etc/repmgr.conf cluster show
Видим
Role | Name | Upstream | Connection String ----------+-------|----------|-------------------------------------------------- * master | node1 | | host=pghost195 port=5433 user=repmgr dbname=repmgr standby | node2 | node1 | host=pghost196 port=5433 user=repmgr dbname=repmgr standby | node3 | node1 | host=pghost197 port=5433 user=repmgr dbname=repmgr standby | node4 | node3 | host=pghost198 port=5433 user=repmgr dbname=repmgr
Настройка Автоматического Faiover’а.
Итак мы закончили настройку потоковой репликации. Теперь перейдем к настройка автопереключения — активации нового мастера из stand-by сервера. Для этого необходимо добавить новые секции в файл /etc/repmgr.conf на stand-by серверах. На мастере этого быть не должно!!!
!!! Конфиги на standby(slave’s) должны отличаться — как в примере ниже. Выставим разное время(master_responce_timeout)!!!
Добавляем строки на pghost196 в /etc/repmgr.conf
#######АВТОМАТИЧЕСКИЙ FAILOVER#######ТОЛЬКО НА STAND BY################## master_response_timeout=20 reconnect_attempts=5 reconnect_interval=5 failover=automatic promote_command='sh /etc/postgresql/failover_promote.sh' follow_command='sh /etc/postgresql/failover_follow.sh' #loglevel=NOTICE #logfacility=STDERR #logfile='/var/log/postgresql/repmgr-9.6.log' priority=90 # a value of zero or less prevents the node being promoted to master
Добавляем строки на pghost197 в /etc/repmgr.conf
#######АВТОМАТИЧЕСКИЙ FAILOVER#######ТОЛЬКО НА STAND BY################## master_response_timeout=20 reconnect_attempts=5 reconnect_interval=5 failover=automatic promote_command='sh /etc/postgresql/failover_promote.sh' follow_command='sh /etc/postgresql/failover_follow.sh' #loglevel=NOTICE #logfacility=STDERR #logfile='/var/log/postgresql/repmgr-9.6.log' priority=70 # a value of zero or less prevents the node being promoted to master
Добавляем строки на pghost198 в /etc/repmgr.conf
#######АВТОМАТИЧЕСКИЙ FAILOVER#######ТОЛЬКО НА STAND BY################## master_response_timeout=20 reconnect_attempts=5 reconnect_interval=5 failover=automatic promote_command='sh /etc/postgresql/failover_promote.sh' follow_command='sh /etc/postgresql/failover_follow.sh' #loglevel=NOTICE #logfacility=STDERR #logfile='/var/log/postgresql/repmgr-9.6.log' priority=50 # a value of zero or less prevents the node being promoted to master
Как мы видим все настройки автофейолвера идентичны, разница только в priority. Если 0, то данный Standby никогда не станет Master. Данный параметр будет определять очередность срабатывания failover’a, т.е. меньшее число говорит о большем приоритете, значит после отказа master сервера его функции на себя возьмет pghost197.
Также необходимо добавить следующие строки в файл /etc/postgresql/9.6/main/postgresql.conf (только на stand-by сервера!!!!!!)
shared_preload_libraries = 'repmgr_funcs'
Для запуска демона детектирования автоматического переключения необходимо:
su postgres repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v >> /var/log/postgresql/repmgr.log 2>&1
Процесс repmgrd будет запущен как демон. Смотрим
ps aux | grep repmgrd
Видим
postgres 2921 0.0 0.0 59760 5000 ? S 16:54 0:00 /usr/lib/postgresql/9.6/bin/repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v postgres 3059 0.0 0.0 12752 2044 pts/1 S+ 16:54 0:00 grep repmgrd
Всё ок. Идём дальше.
Проверим работу автофейловера
su postgres psql repmgr repmgr # SELECT * FROM repmgr_etagi_test.repl_nodes ORDER BY id; id | type | upstream_node_id | cluster | name | conninfo | slot_name | priority | active ----+---------+------------------+------------+-------+---------------------------------------------------+---------------+----------+-------- 1 | master | | etagi_test | node1 | host=pghost195 port=5433 user=repmgr dbname=repmgr | repmgr_slot_1 | 100 | t 2 | standby | 1 | etagi_test | node2 | host=pghost196 port=5433 user=repmgr dbname=repmgr | repmgr_slot_2 | 100 | t 3 | standby | 1 | etagi_test | node3 | host=pghost197 port=5433 user=repmgr dbname=repmgr | repmgr_slot_3 | 100 | t
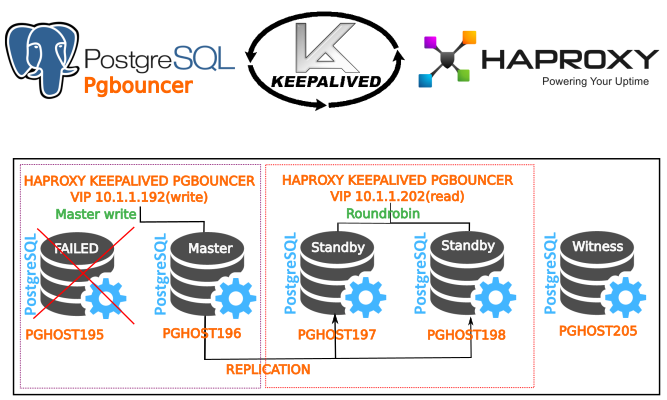
Пока все нормально — теперь проведем тест. Остановим мастер — pghost195
su postgres pg_ctl -D /etc/postgresql/9.6/main -m immediate stop
В логах на pghost196
tail -f /var/log/postgresql/*
Видим
[2016-10-21 16:58:34] [NOTICE] promoting standby [2016-10-21 16:58:34] [NOTICE] promoting server using '/usr/lib/postgresql/9.6/bin/pg_ctl -D /var/lib/postgresql/9.6/main promote' [2016-10-21 16:58:36] [NOTICE] STANDBY PROMOTE successful
В логах на pghost197
tail -f /var/log/postgresql/*
Видим
2016-10-21 16:58:39] [NOTICE] node 2 is the best candidate for new master, attempting to follow... [2016-10-21 16:58:40] [ERROR] connection to database failed: could not connect to server: Connection refused Is the server running on host "pghost195" (10.1.1.195) and accepting TCP/IP connections on port 5433? [2016-10-21 16:58:40] [NOTICE] restarting server using '/usr/lib/postgresql/9.6/bin/pg_ctl -w -D /var/lib/postgresql/9.6/main -m fast restart' [2016-10-21 16:58:42] [NOTICE] node 3 now following new upstream node 2
Всё работает. У нас новый мастер — pghost196, pghost197,pghost198 — теперь слушает stream от pghost2.
Возвращение упавшего мастера в строй!!!

Нельзя просто так взять и вернуть упавший мастер в строй. Но он вернется в качестве слейва.
Postges должна быть остановлена перед процедурой возвращения.
На ноде, которая отказала создаем скрипт, в этом спирте уже настроено уведомление телеграмм, и настроена проверка по триггеру — если создан файл /etc/postgresql/disabled, то восстановление не произойдет. Так же создадим файл /etc/postgresql/current_master.list с содержимым — именем текущего master.
pghost196
Назовем скрипт «register.sh» и разместим в каталоге /etc/postgresql
Скрипт восстановления ноды в кластер в качестве standby
trigger="/etc/postgresql/disabled" TEXT="'`hostname -f`_postgresql_disabled_and_don't_be_started.You_must_delete_file_/etc/postgresql/disabled'" TEXT if [ -f "$trigger" ] then echo "Current server is disabled" sh /etc/postgresql/telegram.sh $TEXT else pkill repmgrd pg_ctl stop rm -rf /var/lib/postgresql/9.6/main/*; mkdir /var/run/postgresql/9.6-main.pg_stat_tmp; repmgr -D /var/lib/postgresql/9.6/main -f /etc/repmgr.conf -d repmgr -p 5433 -U repmgr -R postgres --verbose --force --rsync-only --copy-external-config-files=pgdata standby clone -h $(cat /etc/postgresql/current_master.list); /usr/lib/postgresql/9.6/bin/pg_ctl -D /var/lib/postgresql/9.6/main --log=/var/log/postgresql/postgres_screen.log start; /bin/sleep 5; repmgr -f /etc/repmgr.conf --force standby register; echo "Вывод состояния кластера"; repmgr -f /etc/repmgr.conf cluster show; sh /etc/postgresql/telegram.sh $TEXT sh /etc/postgresql/repmgrd.sh; ps aux | grep repmgrd; fi
Как вы видите у нас также есть в скрипте файл repmgrd.sh и telegram.sh. Они также должны находится в каталоге /etc/postgresql.
#!/bin/bash pkill repmgrd rm /var/run/postgresql/repmgrd.pid; repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v >> /var/log/postgresql/repmgr.log 2>&1; ps aux | grep repmgrd;
USERID="Юзер_ид_пользователей_телеграм_через_пробел" CLUSTERNAME="PGCLUSTER_RIES" KEY="Ключ_бота_телеграм" TIMEOUT="10" EXEPT_USER="root" URL="https://api.telegram.org/bot$KEY/sendMessage" DATE_EXEC="$(date "+%d %b %Y %H:%M")" TMPFILE='/etc/postgresql/ipinfo-$DATE_EXEC.txt' IP=$(echo $SSH_CLIENT | awk '{print $1}') PORT=$(echo $SSH_CLIENT | awk '{print $3}') HOSTNAME=$(hostname -f) IPADDR=$(hostname -I | awk '{print $1}') curl http://ipinfo.io/$IP -s -o $TMPFILE #ORG=$(cat $TMPFILE | jq '.org' | sed 's/"//g') TEXT=$1 for IDTELEGRAM in $USERID do curl -s --max-time $TIMEOUT -d "chat_id=$IDTELEGRAM&disable_web_page_preview=1&text=$TEXT" $URL > /dev/null done rm $TMPFILE
Отредактируем конфиг repmgr на упавшем мастере
cluster=etagi_cluster1 node=1 node_name=node195 use_replication_slots=8 conninfo='host=pghost195 port=5433 user=repmgr dbname=repmgr' pg_bindir=/usr/lib/postgresql/9.6/bin #######АВТОМАТИЧЕСКИЙ FAILOVER#######ТОЛЬКО НА STAND BY################## master_response_timeout=20 reconnect_attempts=5 reconnect_interval=5 failover=automatic promote_command='sh /etc/postgresql/failover_promote.sh' follow_command='sh /etc/postgresql/failover_follow.sh' #loglevel=NOTICE #logfacility=STDERR #logfile='/var/log/postgresql/repmgr-9.6.log' priority=95 # a value of zero or less prevents the node being promoted to master
Сохранимся.
Теперь запустим наш скрипт, на отказавшей ноде. Не забываем про права(postgres) для файлов.
sh /etc/postgresq/register.sh
Увидим
[2016-10-31 15:19:53] [NOTICE] notifying master about backup completion... ЗАМЕЧАНИЕ: команда pg_stop_backup завершена, все требуемые сегменты WAL заархивированы [2016-10-31 15:19:54] [NOTICE] standby clone (using rsync) complete [2016-10-31 15:19:54] [NOTICE] you can now start your PostgreSQL server [2016-10-31 15:19:54] [HINT] for example : pg_ctl -D /var/lib/postgresql/9.6/main start [2016-10-31 15:19:54] [HINT] After starting the server, you need to register this standby with "repmgr standby register" сервер запускается [2016-10-31 15:19:59] [NOTICE] standby node correctly registered for cluster etagi_cluster1 with id 2 (conninfo: host=pghost196 port=5433 user=repmgr dbname=repmgr) Вывод состояния кластера Role | Name | Upstream | Connection String ----------+---------|----------|---------------------------------------------------- * standby | node195 | | host=pghost195 port=5433 user=repmgr dbname=repmgr master | node196 | node195 | host=pghost197 port=5433 user=repmgr dbname=repmgr standby | node197 | node195 | host=pghost198 port=5433 user=repmgr dbname=repmgr standby | node198 | node195 | host=pghost196 port=5433 user=repmgr dbname=repmgr postgres 11317 0.0 0.0 4336 716 pts/0 S+ 15:19 0:00 sh /etc/postgresql/repmgrd.sh postgres 11322 0.0 0.0 59548 3632 ? R 15:19 0:00 /usr/lib/postgresql/9.6/bin/repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v postgres 11324 0.0 0.0 12752 2140 pts/0 S+ 15:19 0:00 grep repmgrd postgres 11322 0.0 0.0 59548 4860 ? S 15:19 0:00 /usr/lib/postgresql/9.6/bin/repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v postgres 11327 0.0 0.0 12752 2084 pts/0 S+ 15:19 0:00 grep repmgrd
Как мы видим скрипт отработал, мы получили уведомления и увидели состояние кластера.
Реализации процедуры Switchover(смены мастера вручную).
Допустим наступила такая ситуация, когда вам необходимо поменять местами мастер и определенный standby.
Допустим хотим сделать мастером pghost195 вместо ставшего по фейловеру pghost196, после его восстановления в качестве слейва. Наши шаги.
На pghost195
su postgres repmgr -f /etc/repmgr.conf standby switchover Видим [2016-10-26 15:29:42] [NOTICE] replication slot "repmgr_slot_1" deleted on former master [2016-10-26 15:29:42] [NOTICE] switchover was successful
Теперь нам необходимо дать команду репликам, кроме старого мастера, дать команду на перенос на новый мастер
На pghost197
su postgres repmgr -f /etc/repmgr.conf standby follow repmgr -f /etc/repmgr.conf cluster show;
Видим что мы следуем за новым мастером.
На pghost198 — то же самое
su postgres repmgr -f /etc/repmgr.conf standby follow repmgr -f /etc/repmgr.conf cluster show;
Видим что мы следуем за новым мастером.
На pghost196 — он был предыдущим мастером, у которого мы отобрали права
su postgres repmgr -f /etc/repmgr.conf standby follow
Видим ошибку
[2016-10-26 15:35:51] [ERROR] Slot 'repmgr_slot_2' already exists as an active slot
Cтопаем pghost196
pg_ctl stop
Для ее исправления идем на phgost195(новый мастер)
su postgres psql repmgr #select pg_drop_replication_slot('repmgr_slot_2');
Видим
pg_drop_replication_slot -------------------------- (1 row)
Идем на pghost196, и делаем все по аналогии с пунктом.
Создание и использование witness ноды

Witness нода используется для управления кластером, в случае наступления файловера и выступает своего рода арбитром, следит за тем чтобы не наступали конфликтные ситуации при выборе нового мастера. Она не является активной нодой в плане использования как standby сервера, может быть установлена на той же ноде что и postgres или на отдельной ноде.
Добавим еще одну ноду pghost205 для управления кластером( настройка абсолютно аналогична настройке слейва), толь будет отличаться способ копирования:
repmgr -h pghost195 -p 5433 -U repmgr -d repmgr -D main -f /etc/repmgr.conf --force --copy-external-config-files=pgdata --verbose witness create; или repmgr -D /var/lib/postgresql/9.6/main -f /etc/repmgr.conf -d repmgr -p 5433 -U repmgr -R postgres --verbose --force --rsync-only --copy-external-config-files=pgdata witness create -h pghost195;
Увидим вывод
2016-10-26 17:27:06] [WARNING] --copy-external-config-files can only be used when executing STANDBY CLONE [2016-10-26 17:27:06] [NOTICE] using configuration file "/etc/repmgr.conf" Файлы, относящиеся к этой СУБД, будут принадлежать пользователю "postgres". От его имени также будет запускаться процесс сервера. Кластер баз данных будет инициализирован с локалью "ru_RU.UTF-8". Кодировка БД по умолчанию, выбранная в соответствии с настройками: "UTF8". Выбрана конфигурация текстового поиска по умолчанию "russian". Контроль целостности страниц данных отключен. исправление прав для существующего каталога main... ок создание подкаталогов... ок выбирается значение max_connections... 100 выбирается значение shared_buffers... 128MB выбор реализации динамической разделяемой памяти ... posix создание конфигурационных файлов... ок выполняется подготовительный скрипт ... ок выполняется заключительная инициализация ... ок сохранение данных на диске... ок ПРЕДУПРЕЖДЕНИЕ: используется проверка подлинности "trust" для локальных подключений. Другой метод можно выбрать, отредактировав pg_hba.conf или используя ключи -A, --auth-local или --auth-host при следующем выполнении initdb. Готово. Теперь вы можете запустить сервер баз данных: /usr/lib/postgresql/9.6/bin/pg_ctl -D main -l logfile start ожидание запуска сервера....СООБЩЕНИЕ: система БД была выключена: 2016-10-26 17:27:07 YEKT СООБЩЕНИЕ: Защита от наложения мультитранзакций сейчас включена СООБЩЕНИЕ: система БД готова принимать подключения СООБЩЕНИЕ: процесс запуска автоочистки создан готово сервер запущен Warning: Permanently added 'pghost1,10.1.9.1' (ECDSA) to the list of known hosts. receiving incremental file list pg_hba.conf 1,174 100% 1.12MB/s 0:00:00 (xfr#1, to-chk=0/1) СООБЩЕНИЕ: получен SIGHUP, файлы конфигурации перезагружаются сигнал отправлен серверу [2016-10-26 17:27:10] [NOTICE] configuration has been successfully copied to the witness /usr/lib/postgresql/9.6/bin/pg_ctl -D /var/lib/postgresql/9.6/main -l logfile start
Готово. Идем далее. Правим файл repmgr.conf для witness ноды
Отключаем автоматический файловер на ноде witness
cluster=etagi_test node=5 node_name=node5 use_replication_slots=1 conninfo='host=pghost205 port=5499 user=repmgr dbname=repmgr' pg_bindir=/usr/lib/postgresql/9.6/bin #######FAILOVER#######ТОЛЬКО НА WITNESS NODE####### master_response_timeout=50 reconnect_attempts=3 reconnect_interval=5 failover=manual promote_command='repmgr standby promote -f /etc/repmgr.conf' follow_command='repmgr standby follow -f /etc/repmgr.conf'
На witness ноде обязательно изменить порт на 5499 в conninfo.
Обязательно (пере)запускаем repmgrd на всех нодах, кроме мастера
su postgres pkill repmgr repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v >> /var/log/postgresql/repmgr.log 2>&1 ps aux | grep repmgr
Настройка менеджера соединений Pgbouncer и балансировки через Haproxy. Отказоустойчивости через Keepalived.
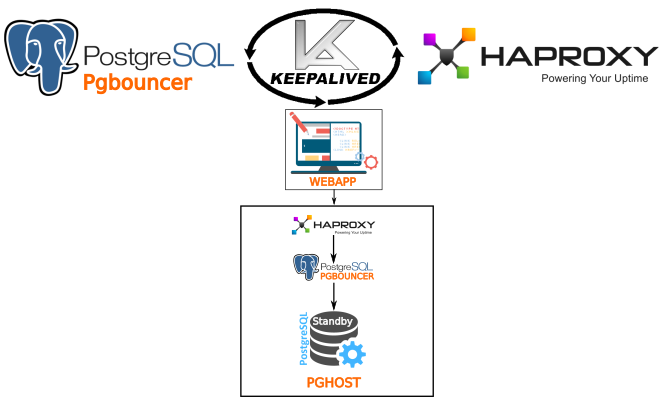
Настройка Pgbouncer
Pgbouncer мы уже установили заранее. Для чего он нужен…
Мультиплексором соединений. Он выглядит как обычный процесс Postgres, но внутри он управляет очередями запросов что позволяет в разы ускорить работу сервера. Из тысяч запросов поступивших к PgBouncer до базы данных дойдет всего несколько десятков.
Перейдем к его настройке.
Скопируем установленный pgbouncer в папку /etc/(для удобства)
cp -r /usr/local/share/doc/pgbouncer /etc cd /etc/pgbouncer
Приведем к виду файл в
[databases] ################################ПОДКЛ К БАЗЕ########### web1 = host = localhost port=5433 dbname=web1 web2 = host = localhost port=5433 dbname=web2 ####################################################### [pgbouncer] logfile = /var/log/postgresql/pgbouncer.log pidfile = /var/run/postgresql/pgbouncer.pid listen_addr = * listen_port = 6432 auth_type = trust auth_file = /etc/pgbouncer/userlist.txt ;;; Pooler personality questions ; When server connection is released back to pool: ; session - after client disconnects ; transaction - after transaction finishes ; statement - after statement finishes pool_mode = session server_reset_query = DISCARD ALL max_client_conn = 500 default_pool_size = 30
Отредактируем файл
"test_user" "passworduser" "postgres" "passwordpostgres" "pgbouncer" "fake"
Применим права
chown -R postgres /etc/pgbouncer
После редактирования запустим командой как демон (-d)
su postgres pkill pgbouncer pgbouncer -d --verbose /etc/pgbouncer/pgbouncer.ini
Смотрим порт
netstat -4ln | grep 6432
Смотрим лог
tail -f /var/log/postgresql/pgbouncer.log
Пробуем подключиться. Повторяем все тоже на всех нодах.
Установка и настройка Haproxy.
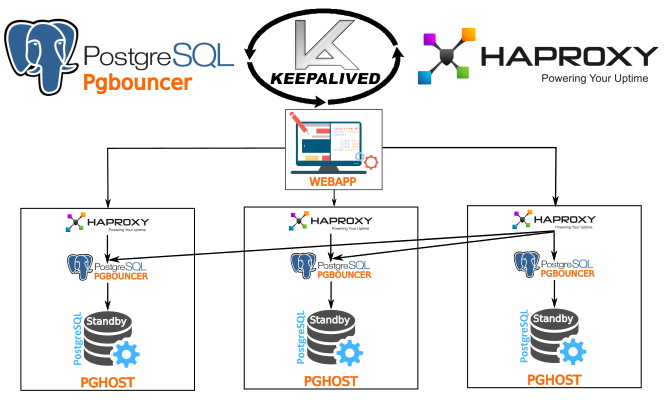
Ставим Xinetd и Haproxy
apt-get install xinetd haproxy -y
Добавляем строку в конец файла
nano /etc/services pgsqlchk 23267/tcp # pgsqlchk
Устанавливаем скрипт для проверки состояния postgres — pgsqlcheck
#!/bin/bash # /opt/pgsqlchk # This script checks if a postgres server is healthy running on localhost. It will # return: # # "HTTP/1.x 200 OK\r" (if postgres is running smoothly) # # - OR - # # "HTTP/1.x 500 Internal Server Error\r" (else) # # The purpose of this script is make haproxy capable of monitoring postgres properly # # # It is recommended that a low-privileged postgres user is created to be used by # this script. # For eg. create user pgsqlchkusr login password 'pg321'; # PGSQL_HOST="localhost" PGSQL_PORT="5433" PGSQL_DATABASE="template1" PGSQL_USERNAME="pgsqlchkusr" export PGPASSWORD="pg321" TMP_FILE="/tmp/pgsqlchk.out" ERR_FILE="/tmp/pgsqlchk.err" # # We perform a simple query that should return a few results :-p # psql -h $PGSQL_HOST -p $PGSQL_PORT -U $PGSQL_USERNAME \ $PGSQL_DATABASE -c "show port;" > $TMP_FILE 2> $ERR_FILE # # Check the output. If it is not empty then everything is fine and we return # something. Else, we just do not return anything. # if [ "$(/bin/cat $TMP_FILE)" != "" ] then # Postgres is fine, return http 200 /bin/echo -e "HTTP/1.1 200 OK\r\n" /bin/echo -e "Content-Type: Content-Type: text/plain\r\n" /bin/echo -e "\r\n" /bin/echo -e "Postgres is running.\r\n" /bin/echo -e "\r\n" else # Postgres is down, return http 503 /bin/echo -e "HTTP/1.1 503 Service Unavailable\r\n" /bin/echo -e "Content-Type: Content-Type: text/plain\r\n" /bin/echo -e "\r\n" /bin/echo -e "Postgres is *down*.\r\n" /bin/echo -e "\r\n" fi
Соответственно нам необходимо добавить пользователя pgsqlchkusr для проверки состояния postgres
plsq #create user pgsqlchkusr; #ALTER ROLE pgsqlchkusr WITH LOGIN; #ALTER USER pgsqlchkusr WITH PASSWORD 'pg321'; #\q
Делаем скрипт исполняемым и даем права временных файлам — иначе check не сработает.
chmod +x /opt/pgsqlchk;touch /tmp/pgsqlchk.out; touch /tmp/pgsqlchk.err; chmod 777 /tmp/pgsqlchk.out; chmod 777 /tmp/pgsqlchk.err;
Создаем конфиг файл xinetd для pgsqlchk
# /etc/xinetd.d/pgsqlchk # # default: on # # description: pqsqlchk service pgsqlchk { flags = REUSE socket_type = stream port = 23267 wait = no user = nobody server = /opt/pgsqlchk log_on_failure += USERID disable = no only_from = 0.0.0.0/0 per_source = UNLIMITED }
Сохраняемся.
Настраиваем haproxy.
Редактируем конфиг — удалим старый и вставим это содержимое. Этот конфиг для первой ноды, на которой крутится мастер, на данный момент допустим, что это pghost195. Соответственно для данного хоста мы сделаем активным в пуле соединений свой-же хост, работающий на порте 6432(через pgbouncer).
global log 127.0.0.1 local0 log 127.0.0.1 local1 notice #chroot /usr/share/haproxy chroot /var/lib/haproxy pidfile /var/run/haproxy.pid user postgres group postgres daemon maxconn 20000 defaults log global mode http option tcplog option dontlognull retries 3 option redispatch timeout connect 30000ms timeout client 30000ms timeout server 30000ms frontend stats-front bind *:8080 mode http default_backend stats-back frontend pxc-onenode-front bind *:5432 mode tcp default_backend pxc-onenode-back backend stats-back mode http stats uri / stats auth admin:adminpassword backend pxc-onenode-back mode tcp balance leastconn option httpchk default-server port 6432 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxqueue 128 weight 100 server pghost195 10.1.1.195:6432 check port 23267
Сам порт haproxy для подключения к базе крутится на порте 5432. Админка доступна на порте 8080. Пользователь admin с паролем adminpassword.
Рестартим сервисы
/etc/init.d/xinetd restart; /etc/init.d/haproxy restart;
Тоже самое делаем еще на всех нодах.
На той ноде, которую вы хотите сделать балансировщиком, например pghost198(запросы на нее будут идти только на чтение) конфиг haproxy приводим к такому виду.
global log 127.0.0.1 local0 log 127.0.0.1 local1 notice #chroot /usr/share/haproxy chroot /var/lib/haproxy pidfile /var/run/haproxy.pid user postgres group postgres daemon maxconn 20000 defaults log global mode http option tcplog option dontlognull retries 3 option redispatch timeout connect 30000ms timeout client 30000ms timeout server 30000ms frontend stats-front bind *:8080 mode http default_backend stats-back frontend pxc-onenode-front bind *:5432 mode tcp default_backend pxc-onenode-back backend stats-back mode http stats uri / stats auth admin:adminpassword backend pxc-onenode-back mode tcp balance roundrobin option httpchk default-server port 6432 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxqueue 128 weight 100 server pghost196 10.1.1.196:6432 check port 23267 server pghost197 10.1.1.196:6432 check port 23267 server pghost198 10.1.1.196:6432 check port 23267
Статистику смотри на hostip:8080
Установка keepalived.
Keepalived позволяет использовать виртуальный ip адрес (VIP) и в случае выходы из строя одной из нод(выключение питания или другое событие) ip адрес перейдет на другую ноду. Например у нас будет VIP 10.1.1.192 между нодой pghost195,pghost196,pghost197. Соответвенно при выключение питании на ноде pghost195 нода pghost196 автоматически присвоит себе ip addr 10.1.1.192 и так как она является второй в приоритете на продвижение к роли мастера станет доступной для записи благодаря или haproxy или pgbouncer — тут все зависит от вашего выбора. В нашем сценарии — это Haproxy.
Ставим keepalived
apt-get install keepalived -y
Настраиваем keepalived. Приводим к виду. НА 1-ой ноде(pghost195)
! this is who emails will go to on alerts notification_email { admin@domain.com ! add a few more email addresses here if you would like } notification_email_from servers@domain.com ! I use the local machine to relay mail smtp_server smt.local.domain smtp_connect_timeout 30 ! each load balancer should have a different ID ! this will be used in SMTP alerts, so you should make ! each router easily identifiable lvs_id LVS_HAPROXY-pghost195 } } vrrp_instance haproxy-pghost195 { interface eth0 state MASTER virtual_router_id 192 priority 150 ! send an alert when this instance changes state from MASTER to BACKUP smtp_alert authentication { auth_type PASS auth_pass passwordforcluster } track_script { chk_http_port } virtual_ipaddress { 10.1.1.192/32 dev eth0 } notify_master "sh /etc/postgresql/telegram.sh 'MASTER pghost195.etagi.com получил VIP'" notify_backup "sh /etc/postgresql/telegram.sh 'BACKUP pghost195.etagi.com получил VIP'" notify_fault "sh /etc/postgresql/telegram.sh 'FAULT pghost195.etagi.com получил VIP'" }
Рестартим
/etc/init.d/keepalived restart
Настраиваем keepalived на 2-ой ноде(pghost196)
! this is who emails will go to on alerts notification_email { admin@domain.com ! add a few more email addresses here if you would like } notification_email_from servers@domain.com ! I use the local machine to relay mail smtp_server smt.local.domain smtp_connect_timeout 30 ! each load balancer should have a different ID ! this will be used in SMTP alerts, so you should make ! each router easily identifiable lvs_id LVS_HAPROXY-pghost196 } } vrrp_instance haproxy-pghost196 { interface eth0 state MASTER virtual_router_id 192 priority 80 ! send an alert when this instance changes state from MASTER to BACKUP smtp_alert authentication { auth_type PASS auth_pass passwordforcluster } track_script { chk_http_port } virtual_ipaddress { 10.1.1.192/32 dev eth0 } notify_master "sh /etc/postgresql/telegram.sh 'MASTER pghost196.etagi.com получил VIP'" notify_backup "sh /etc/postgresql/telegram.sh 'BACKUP pghost196.etagi.com получил VIP'" notify_fault "sh /etc/postgresql/telegram.sh 'FAULT pghost196.etagi.com получил VIP'" }
Настраиваем keepalived на 3-ой ноде(pghost197)
! this is who emails will go to on alerts notification_email { admin@domain.com ! add a few more email addresses here if you would like } notification_email_from servers@domain.com ! I use the local machine to relay mail smtp_server smt.local.domain smtp_connect_timeout 30 ! each load balancer should have a different ID ! this will be used in SMTP alerts, so you should make ! each router easily identifiable lvs_id LVS_HAPROXY-pghost197 } } vrrp_instance haproxy-pghost197 { interface eth0 state MASTER virtual_router_id 192 priority 50 ! send an alert when this instance changes state from MASTER to BACKUP smtp_alert authentication { auth_type PASS auth_pass passwordforcluster } track_script { chk_http_port } virtual_ipaddress { 10.1.1.192/32 dev eth0 } notify_master "sh /etc/postgresql/telegram.sh 'MASTER pghost197.etagi.com получил VIP'" notify_backup "sh /etc/postgresql/telegram.sh 'BACKUP pghost197.etagi.com получил VIP'" notify_fault "sh /etc/postgresql/telegram.sh 'FAULT pghost197.etagi.com получил VIP'" }
Рестартим
/etc/init.d/keepalived restart
Как мы видим, мы также можем использовать скрипты, например для уведомления при изменении состояния. Смотрим следующую секцию
notify_master "sh /etc/postgresql/telegram.sh 'MASTER pghost195.etagi.com получил VIP'" notify_backup "sh /etc/postgresql/telegram.sh 'BACKUP pghost195.etagi.com получил VIP'" notify_fault "sh /etc/postgresql/telegram.sh 'FAULT pghost195.etagi.com получил VIP'"
Так же из конфига видно что мы настроили VIP на 10.1.8.111 который будет жить на eth0. В случае падения ноды pghost195 он перейдет на pghost196, т.е. подключение мы так же будем настраивать через IP 10.1.1.192. так же установим на pghost197, только изменим vrrp_instance и lvs_id LVS_.
На нодах pghost196,pghost197 отключим keepalived. Он будет запускаться только после процедуры failover promote, которая описана в файле. Мы указали
promote_command='sh /etc/postgresql/failover_promote.sh' follow_command='sh /etc/postgresql/failover_follow.sh'
в файле /etc/repmgr.conf (см. в конфигах выше).
Данные скрипты будут запускаться при возникновении failover ситуации -отказе мастера.
promote_command=’sh /etc/postgresql/failover_promote.sh — выпоняет номинированный на master host,
follow_command=’sh /etc/postgresql/failover_follow.sh’ — исполняют ноды, которые следуют за мастером.
Конфиги
#!/bin/bash CLHOSTS="pghost195 pghost196 pghost197 pghost198 pghost205 " repmgr standby promote -f /etc/repmgr.conf; echo "Отправка оповещений"; sh /etc/postgresql/failover_notify_master.sh; echo "Выводим список необходимых хостов в файл" repmgr -f /etc/repmgr.conf cluster show | grep node | awk ' {print $7} ' | sed "s/host=//g" | sed '/port/d' > /etc/postgresql/cluster_hosts.list repmgr -f /etc/repmgr.conf cluster show | grep FAILED | awk ' {print $6} ' | sed "s/host=//g" | sed "s/>//g" > /etc/postgresql/failed_host.list repmgr -f /etc/repmgr.conf cluster show | grep master | awk ' {print $7} ' | sed "s/host=//g" | sed "s/>//g" > /etc/postgresql/current_master.list repmgr -f /etc/repmgr.conf cluster show | grep standby | awk ' {print $7} ' | sed "s/host=//g" | sed '/port/d' > /etc/postgresql/standby_host.list ####КОПИРУЮ ИНФО ФАЙЛЫ И ФАЙЛЫ-ТРИГГЕРЫ НА ДРУГИЕ НОДЫ КЛАСТЕРА##################### for CLHOST in $CLHOSTS do rsync -arvzSH --include "*.list" --exclude "*" /etc/\postgresql/ postgres@$CLHOST:/etc/postgresql/ done echo "Начинаю процедуру восстановления упавшего сервера,если не триггера /etc/postgresql/disabled" for FH in $(cat /etc/postgresql/failed_host.list) do ssh postgres@$FH <<OFF sh /etc/postgresql/register.sh; echo "Рестартуем repmgrd на других нодах" sh /etc/postgresql/repmgrd.sh; sh /etc/postgresql/failover_notify_restoring_ended.sh; OFF done echo "Стопаем repmgrd на ноде, ставшей мастером" pkill repmgrd echo "Работаем с Keepalived"
repmgr standby follow -f /etc/repmgr.conf; echo "Отправка оповещений"; sh /etc/postgresql/failover_notify_standby.sh; pkill repmgrd; repmgrd -f /etc/repmgr.conf -p /var/run/postgresql/repmgrd.pid -m -d -v >> /var/log/postgresql/repmgr.log 2>&1;
Скрипт остановки мастрера — принудительного failover, удобно использовать для тестирования процедур «перевыборов» в кластере.
repmgr -f /etc/repmgr.conf cluster show | grep master | awk ‘ {print $7} ‘ | sed «s/host=//g» | sed «s/>//g» > /etc/postgresql/current_master.list
for CURMASTER in $(cat /etc/postgresql/current_master.list)
do
ssh postgres@$CURMASTER <<OFF
cd ~/9.6;
/usr/lib/postgresql/9.6/bin/pg_ctl -D /etc/postgresql/9.6/main -m immediate stop;
touch /etc/postgresql/disabled;
OFF
sh /etc/postgresql/telegram.sh «ТЕКУЩИЙ МАСТЕР ОСТАНОВЛЕН»
done
С помощью скриптов можно понять логику работу и настроить сценарии под себя. Как мы видим из кода, нам будет необходим доступ к root пользователю от пользователя postgres. Получаем его таким же образом — через ключи.
su postgres ssh-copy-id -i ~/.ssh/id_rsa.pub root@pghost195 ssh-copy-id -i ~/.ssh/id_rsa.pub root@pghost196 ssh-copy-id -i ~/.ssh/id_rsa.pub root@pghost197 ssh-copy-id -i ~/.ssh/id_rsa.pub root@pghost198 ssh-copy-id -i ~/.ssh/id_rsa.pub root@pghost205
Повторяем на всех нодах.
Для особых параноиков, можем настроить скрипт проверки состояний и добавить его в крон например раз в 2 минуты. Сделать это можно без, используя конструкции и используя полученные значения из файлов.
repmgr -f /etc/repmgr.conf cluster show | grep node | awk ' {print $7} ' | sed "s/host=//g" | sed '/port/d' > /etc/postgresql/cluster_hosts.list repmgr -f /etc/repmgr.conf cluster show | grep FAILED | awk ' {print $6} ' | sed "s/host=//g" | sed "s/>//g" > /etc/postgresql/failed_host.list repmgr -f /etc/repmgr.conf cluster show | grep master | awk ' {print $7} ' | sed "s/host=//g" | sed "s/>//g" > /etc/postgresql/current_master.list repmgr -f /etc/repmgr.conf cluster show | grep standby | awk ' {print $7} ' | sed "s/host=//g" | sed '/port/d' > /etc/postgresql/standby_host.list
Дополнения и устранение неисправностей.
Сбор статистики запросов в базу
Мы добавили библиотеку pg_stat_statements( необходимо сделать рестарт)
su postgres cd ~ pg_ctl restart;
Далее активируем расширение:
# CREATE EXTENSION pg_stat_statements;
Пример собранной статистики:
# SELECT query, calls, total_time, rows, 100.0 * shared_blks_hit / nullif(shared_blks_hit + shared_blks_read, 0) AS hit_percent FROM pg_stat_statements ORDER BY total_time DESC LIMIT 10;
Для сброса статистики есть команда pg_stat_statements_reset:
# SELECT pg_stat_statements_reset();
Удаление ноды из кластера если она ‘FAILED’
DELETE FROM repmgr_etagi_test.repl_nodes WHERE name = 'node1';
где — etagi_test — название кластера;
node1 — имя ноды в кластере
Проверка состояния репликации
plsq #SELECT EXTRACT(EPOCH FROM (now() - pg_last_xact_replay_timestamp()))::INT; 00:00:31.445829 (1 строка)
Если в базе давно не было Insert’ов — то это значение будет увеличиваться. На hiload базах это значение будет стремиться к нулю.
Устранение ошибки Slot ‘repmgr_slot_номер слота’ already exists as an active slot
Останавливаем postgresql на той ноде, на которой возникла ошибка
su postgres pg_ctl stop;
На ноде master’e
su postgres psql repmgr #select pg_drop_replication_slot('repmgr_slot_4');
Устранение ошибки INSERT или UPDATE в таблице «repl_nodes» нарушает ограничение внешнего ключа ОШИБКА: INSERT или UPDATE в таблице «repl_nodes» нарушает ограничение внешнего ключа «repl_nodes_upstream_node_id_fkey»
DETAIL: Ключ (upstream_node_id)=(-1) отсутствует в таблице «repl_nodes».
Если у вас возникла данная ошибка при попытке ввести упавшую ноду обратно в кластер то необходимо сделать Процедуру switchover любой ноды в кластере(standby)
repmgr -f /etc/repmgr.conf standby switchover
Standby станет мастером
На “Старом Мастере” ставшем standby
repmgr -f /etc/repmgr.conf standby follow
Ошибка ВАЖНО: не удалось открыть каталог "/var/run/postgresql/9.6-main.pg_stat_tmp":
Просто создаем каталог
su postgres mkdir -p /var/run/postgresql/9.6-main.pg_stat_tmp
Устранение ошибки при регистрации кластера no password supplied.
При регистрации кластера после того как мы слили с ноды данные бывает возникает ошибка
“no password supplied”
Не стали с ней долго разбираться, помогла перезагрузка, видимо какой-то сервис не смог нормально загрузиться.
Backup кластера
pg_dumpall dbname > gzip > filename.gz
Скрипт бэкапа баз данных Postgres
#!/bin/bash DBNAMES="db1 db2 db3" DATE_Y=`/bin/date '+%y'` DATE_M=`/bin/date '+%m'` DATE_D=`/bin/date '+%d'` SERVICE="pgdump" #DB_NAME="repmgr"; #`psql -l | awk '{print $1}' ` for DB_NAME in $DBNAMES do echo "CREATING DIR /Backup/20${DATE_Y}/${DATE_M}/${DATE_D}/${DB_NAME} " BACKUP_DIR="/Backup/20${DATE_Y}/${DATE_M}/${DATE_D}/${DB_NAME}" mkdir -p $BACKUP_DIR; pg_dump -Fc --verbose ${DB_NAME} | gzip > $BACKUP_DIR/${DB_NAME}.gz # Делаем dump базы без даты, для того что дальше извлечь их нее функции pg_dump -Fc -s -f $BACKUP_DIR/${DB_NAME}_only_shema ${DB_NAME} /bin/sleep 2; # Создаем список функция pg_restore -l $BACKUP_DIR/${DB_NAME}_only_shema | grep FUNCTION > $BACKUP_DIR/function_list done ##Как восстановить функции ######################### #pg_restore -h localhost -U username -d имя_базы -L function_list db_dump ######################## ### КАК ВОССТАНОВИТЬ ОДНУ ТАБЛИЦУ ИЗ БЭКАПА, например таблицу payment. #pg_restore --dbname db1 --table=table1 имядампаБД ####ЕСЛИ ЖЕ ВЫ ХОТИТЕ СЛИТЬ ТАБЛИЦУ В ПУСТУЮ БАЗУ, ТО НЕОБХОДИМО ВОССОЗДАТЬ СТРУКТУРУ БД ###pg_restore --dbname ldb1 имядампаБД_only_shema
Заключение
Итак, что мы получили в итоге:
-кластер master-standby из четырех нод;
-автоматический failover в случае отказа мастера(с помощью repmgr’a);
-балансировку нагрузки(на чтение) через haproxy и pgbouncer(менеджер сеансов);
-отсутствие единой точки отказа — keepalived переносит ip адрес на другую ноду, которая была автоматически “повышена” до мастера в случае отказа;
— процедура восстановления(возвращение отказавшего сервера в кластер) не является трудоемкой — если разобраться);
— гибкость системы — repmgr позволяет настроить и другие события в случае наступления инцидента с помощью bash скриптов;
— возможность настроить систему “под себя”.
Для начинающего специалиста настройка данной схемы может показаться немного сложной, на практике же, один раз стоит со всем хорошо разобраться и вы сможете создать HA системы на базе Postgresql и сами управлять сценариями реализации механизма Faiover.
ссылка на оригинал статьи https://habrahabr.ru/post/314000/
Добавить комментарий