 Несмотря на прогнозы о скором наступлении светлого безбумажного будущего, объём бумажных документов всё ещё огромен. Часть из них сканируются и продолжают свою «жизнь» уже в электронном варианте – но только в виде изображений. В среднем в организациях объем сканированных копий составляет 30% от всех документов, которые хранятся в электронном виде. В госсекторе он достигает 41,5%, в ритейле – 17%, в сфере услуг – 23%, в банках и телеком-сфере приближается к 45%. Когда сканы документов лежат себе в нужной папке или делают работу, для которой они предназначены, – это хорошо. Плохо, когда кто-то пытается использовать данные из этих сканов в мошеннических схемах или как-то иначе злоупотреблять ими. Чтобы конфиденциальная информация не «утекла», в информационные системы компаний устанавливают DLP – системы предотвращения утечек.
Несмотря на прогнозы о скором наступлении светлого безбумажного будущего, объём бумажных документов всё ещё огромен. Часть из них сканируются и продолжают свою «жизнь» уже в электронном варианте – но только в виде изображений. В среднем в организациях объем сканированных копий составляет 30% от всех документов, которые хранятся в электронном виде. В госсекторе он достигает 41,5%, в ритейле – 17%, в сфере услуг – 23%, в банках и телеком-сфере приближается к 45%. Когда сканы документов лежат себе в нужной папке или делают работу, для которой они предназначены, – это хорошо. Плохо, когда кто-то пытается использовать данные из этих сканов в мошеннических схемах или как-то иначе злоупотреблять ими. Чтобы конфиденциальная информация не «утекла», в информационные системы компаний устанавливают DLP – системы предотвращения утечек.
Сегодня мы расскажем, как в одну из таких программ – Контур информационной безопасности SearchInform – был интегрирован SDK-продукт ABBYY FineReader Engine и что из этого получилось.
Мы полагаем, что не все читатели блога ABBYY хорошо разбираются в информационной безопасности, поэтому сначала вкратце опишем, как вообще работает Контур информационной безопасности. Если вы – завсегдатай хаба «ИБ» и знакомы с принципами работы DLP-систем, этот раздел можно пропустить.
Первый модуль перехватывает и при необходимости блокирует информационные потоки на уровне сети. Он позволяет работать с зеркалируемым трафиком, прокси-серверами, почтовыми серверами и прочим корпоративным ПО, например, Lynс. Сетевой трафик перехватывается на уровне сетевых протоколов (почта, интернет, мессенджеры, FTP, облачные хранилища). Второй – перехватывает и блокирует информацию с помощью агентов, которые устанавливаются на компьютеры сотрудников. При этом контролируются: интернет, корпоративная и личная электронная почта, все популярные мессенджеры (Viber, ICQ, и др.), Skype, облачные хранилища, FTP, Sharepoint, вывод документов на принтеры, использование внешних устройств хранения. Контролируется файловая система, активность процессов и сайтов, информация, отображаемая на мониторах ПК и улавливаемая микрофонами, нажатые клавиши, доступно удаленное онлайн-наблюдение за ПК.
Система также позволяет индексировать документы «в покое» — на рабочих станциях пользователей или сетевых устройствах – и может индексировать любую текстовую информацию из любых источников, которые имеют API или возможность подключения через ODBC.
Конфиденциальную информацию, которая не должна «утечь» система ищет разными способами: по ключевым словам с учётом морфологии и синонимов, по фразам с учетом порядка слов и расстояния между ними, по атрибутам или по признакам документов (формату, имени отправителя или получателя и др.). Алгоритмы анализа настолько чувствительны, что способны найти даже серьезно измененный документ, если он близок по смыслу или содержанию с «эталоном»
В системе можно задавать политики безопасности и следить за их исполнением. DLP умеет собирать статистику и создает отчеты по случаям нарушения политик безопасности.
Архитектура системы – для интересующихся – хорошо описана в этом обзоре, не будем повторяться.
Большую часть задач в DLP решает анализ текста. Но, как мы помним, во многих компаниях хранится и передаётся по разным каналам большое количество сканов (изображений) документов. Если оставить картинку «как есть» – картинкой, DLP-система не сможет с ней работать. Чтобы система поняла, какая информация содержится на изображении и можно ли её хранить/передавать тем или иным способом, картинку нужно распознать и получить текст. При этом на вход подаются самые разные изображения, и качество их может быть совершенно разным. Если в перехват попадает нечёткая картинка, приходится работать с тем, что есть, не просить же пользователя отправить ее снова, в более высоком качестве.
DLP-система SearchInform и раньше была оснащена технологией OCR. Но этот движок имел серьезные недостатки как в качестве распознавания, так и в скорости. Разработка собственного движка для SearchInform смысла не имела, потому начали искать готовые технологии. Сейчас в модуле SearchServer в качестве движка полнотекстового распознавания можно использовать технологии ABBYY.
Как происходила интеграция FineReader Engine в систему
Разработка поделилась на два направления. Во-первых, нужно было бесшовно интегрировать технологии ABBYY и создать удобный для пользователей DLP модуль распознавания. Во-вторых, адаптировать технологии распознавания и классификации документов ABBYY под прикладные задачи.
Первая задача была решена быстро: она была реализована через собственный преднастроенный инсталлятор в DLP-системе. Развёртывание модуля OCR на базе технологии ABBYY сводится к установке дополнительного компонента в стиле «далее – далее», и активации нужной «галочки» в DLP. Компонент устанавливается на сервер DLP, поэтому никакая настройка для «соединения» DLP и OCR не требуется в принципе, больше пользователю ничего делать не нужно.
Включение FineReader Engine реализовано через интерфейс DLP, включается в один клик путем выбора соответствующего пункта из выпадающего списка. Тут же доступны более подробные настройки (при желании).

Более того, пользователю не нужно взаимодействовать с ABBYY, лицензирование FineReader Engine осуществляется SearchInform на уровне лицензии к DLP. Реализация получилась действительно дружественная пользователю и понравилась клиентам SearchInform.
Со второй задачей – адаптацией технологии ABBYY под прикладные задачи – работы было существенно больше.
Когда программисты SearchInform начали изучать технологии, то выявили массу возможностей, потенциально полезных для решения ИБ-задач. Все привыкли, что ABBYY – это, прежде всего, OCR. Но FineReader Engine умеет ещё и классифицировать документы по внешнему виду и содержанию. Чтобы настроить процесс классификации, на первом этапе надо задать категории, по которым будут распределяться документы (например, «Паспорт», «Договор», «Чек»). После этого программу нужно обучить: «показать» документы, соответствующие каждому классу во всех возможных вариантах оформления.
При работе и обучении классификатор использует набор признаков, помогающих отделить документы одного типа от документов другого типа. Все признаки можно условно разделить на графические и текстовые.
Графические признаки хорошо разделяют группы документов, сильно внешне отличающиеся друг от друга. Условно говоря, если вы смотрите издали на документ так, что не можете прочитать текст на нём, но можете понять, какой у него тип, то графические признаки тут будут хорошо работать.
Так, графические признаки могут хорошо отделять слитный и неслитный текст, например, письма и платёжные квитанции. Они смотрят на размер изображения, плотность цветов в разных его частях, разные другие характерные элементы вроде вертикальных и горизонтальных линий.
А если внешне документы похожи, или одну группу, не читая текст, нельзя отделить от другой группы, то помогают текстовые признаки. Они очень похожи на те, что используются в спам-фильтрах и позволяют по характерным словам определять принадлежность документа к тому или иному типу. Отделять письма от договоров, чеки от визитных карточек удобно именно с помощью текстовых признаков.
Также текстовые признаки помогают отделять документы похожего вида, но отличающиеся значением одного или нескольких полей. Например, чеки из Макдональдса и Теремка внешне очень похожи, но если рассматривать их как текст, то отличия будут очень заметны.
В итоге классификатор для каждой обучающей выборки даёт больший вес тем текстовым или графическим признакам, которые позволяют наилучшим образом разделять документы из этой выборки по типам.
Как реализована классификация в связке DLP + ABBYY
Разработчики SearchInform задали в программе несколько категорий документов, которые могли понадобиться пользователям в первую очередь – разные типы паспортов и банковские карты.
Категоризация паспортов и кредиток начинает работать у пользователя без обучения системы, фактически сразу после развертывания FineReader Engine. Пользователю достаточно включить в настройках классификатор – и все новые документы будут разбираться по категориям, для классификации документов из архива нужно просто перезапустить по ним проверку.
Вместе с тем, пользователю оставлена возможность создавать дополнительные категории. Он сам может задавать любые классы (категории), или добавлять свои документы в имеющиеся (паспорта и кредитки). Для этого ему нужно создать в специальной папке подпапки с названиями классов, положить туда эталоны документов и запустить процесс обучения. Эта процедура обычно выполняется совместно с инженерами SearchInform, которые все наглядно демонстрируют и рассказывают о требованиях к изображениям, совместно с заказчиком формируют базу эталонов, советуют, какие документы лучше подойдут как эталоны той или иной категории. Сразу после настройки идет проверка на реальных данных, часто после проверки нужна перенастройка, небольшая корректировка настроек или эталонов. Обычно это процедура занимает полчаса-час.
Точность классификации зависит от того, насколько система сможет «увидеть» разницу между документами в разных категориях. Если на обучение в двух разных категориях подать документы, похожие по внешнему виду и содержащие много одинаковых ключевых слов, технология начнёт путаться и точность классификации снизится.
Так, при детектировании сканов только главной страницы паспортов инженеры SearchInform столкнулись с большим количеством ложных срабатываний. Алгоритм ABBYY находил в архиве из 10 000 изображений 300 картинок, похожих на паспорта, в то время как паспортов там было всего несколько штук.
Если для произвольных категорий это допустимый процент релевантности, то для ключевых объектов, например, кредиток, это слишком большая погрешность. Чтобы улучшить уровень релевантности инженеры SearchInform разработали ещё и собственные алгоритмы проверки, которые применяются уже к результатам классификации ABBYY. Для каждой категории данных был создан индивидуальный валидатор, работающий только со своей группой.
Как система DLP + ABBYY работает с изображениями
Обработкой данных в DLP занимается специальный компонент – SearchServer. Когда этот компонент находит в перехваченных данных изображение (причем не важно, это часть документа или отдельная картинка), он передает его в модуль FineReader Engine, который выполняет оптическое распознавание и классифицирует изображения по заданным категориям. Причем вместе с категорией FineReader Engine отдает и «процент похожести» изображения на соответствующий класс, например, изображение №1 похоже на паспорт на 83%, изображение №2 похоже на водительское удостоверение на 35%. Результат передается в SearchServer. В SearchServer задан специальный параметр, для простоты понимания назовем его «минимально возможный процент» – по умолчанию он равен 40%. Если FineReader Engine присвоил процент меньше этого значения – класс удаляется, и в DLP этот документ идет без класса. Если процент выше, будет следующее:
1. Для паспортов и кредитных карт работает валидатор SearchInform, он проверяет документ как по распознанному тексту, так и графическую составляющую (например, для паспортов выясняется, есть ли на изображении лицо, в каком месте оно располагается, сколько пространства занимает, есть ли графические элементы, присущие только паспортам (для РФ – особый узор), другие характерные элементы). Чем больше «маркеров» подтвердится, тем выше будет итоговый «множитель». К примеру, классификатор FineReader Engine уверен в похожести изображения на паспорт на 63%, валидатор нашел на нем ключевые слова «Паспорт РФ», «Фамилия», «Кем выдан», а также фотографию, на которой детектировано лицо – в таком случае множитель равен, например, 1,5 – и итоговая релевантность получается 94,5%
Релевантность с такой пост-проверкой выросла в разы, а производительность осталась на прежнем уровне. Алгоритм ABBYY работает довольно быстро и применяется к большим массивам данных, что позволяет ускорить работу программы в несколько раз, валидатор категорий SearchInform работает медленнее, но благодаря классификации ABBYY он используется только при необходимости и применяется к существенно меньшему массиву данных.
Сложностью такой реализации стало то, что пришлось с нуля делать валидаторы для многих типов данных. Ведь те же паспорта разных стран имеют свои неповторимые особенности, и алгоритм поиска паспорта РФ абсолютно не подходит для поиска паспорта гражданина Украины. То же самое с кредитными картами – характеристики для VISA существенно отличаются от MasterCard.
2.Если документ похож на какую-то категорию, но она не относится к паспортам или кредиткам, релевантность, присвоенная модулем FineReader Engine, остается без изменений – валидатор SearchInform для таких категорий вообще не применяется.
После того, как вычислена итоговая релевантность, еще раз работает правило, в котором порогом служит уже не значение «минимальный процент похожести», а значение, настроенное пользователем. По умолчанию – 70%. Итого, если релевантность больше или равна этому значению – таким документам подтверждается класс, и по этому классу можно искать. Если она меньше, метка класса снимается и документ считается «без класса».
Решение прикладных задач
В «Контуре информационной безопасности» есть специализированные средства аналитики, позволяющие работать с архивом данных или выполнять заданные политики безопасности.
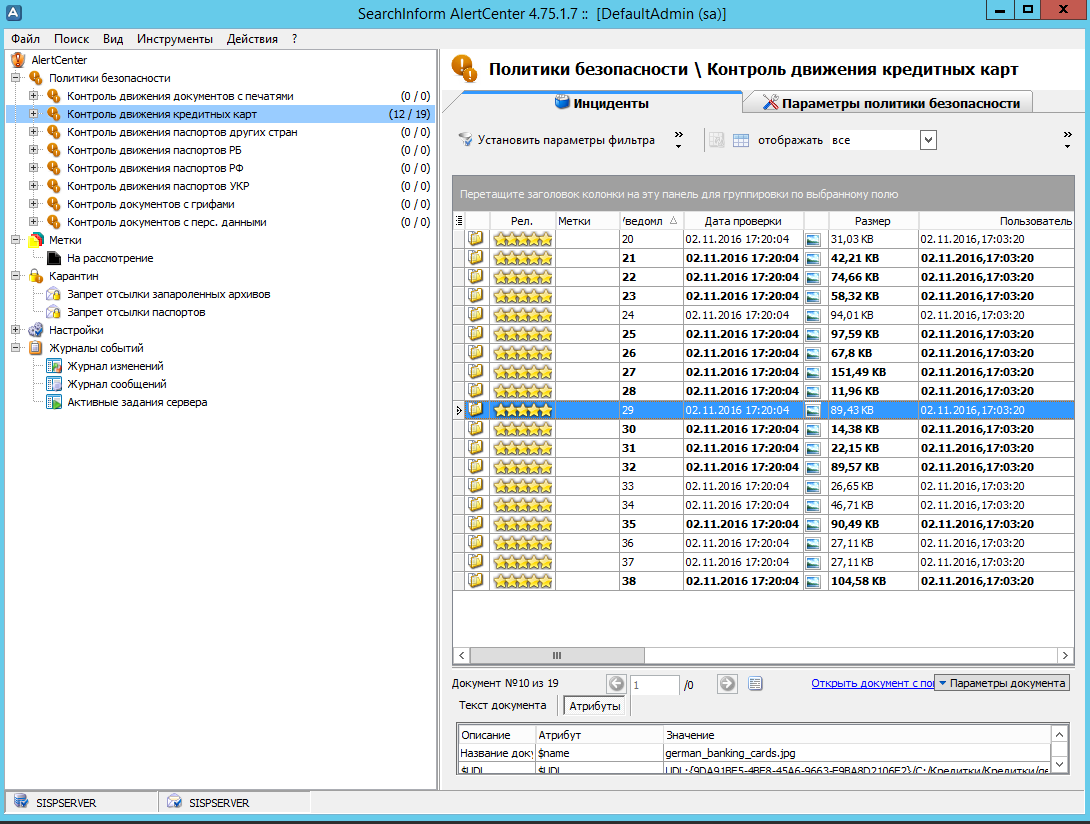
Безусловно, паспорта и кредитки относятся к критичным данным, поскольку содержат персональные данные, поэтому их контроль очень важен заказчикам. Более того, обычно крайне сложно разработать блокирующее правило, которое такие данные будет «резать» – при создании таких правил в реальных проектах возникает очень много тонкостей, которые выясняются постепенно, и каждый такой случай приводит к нарушению бизнес процессов у клиента (т.к. срабатывает блокировка). Поэтому чаще всего заказчики хотят просто видеть все движения подобных документов внутри организации и, особенно, за ее пределы. А учитывая то, что это могут быть не только паспорта\кредитки, но и любые другие типы данных – метод дает большую гибкость при анализе.
Рассмотрим реальный кейс. Компания заказчика работает со сканами паспортов. В ней есть определенный свод правил, регламентирующий, где и как положено такие вещи хранить, по каким электронным каналам и кому можно передавать. Часть данных блокируется при передаче – например, если это исходящая почта, предназначенная не сотруднику компании и в ней есть скан паспорта, текст паспортных данных или что-то даже отдаленно напоминающее паспортные данные. Отправить скан паспорта наружу можно только по согласованию с ИБ.
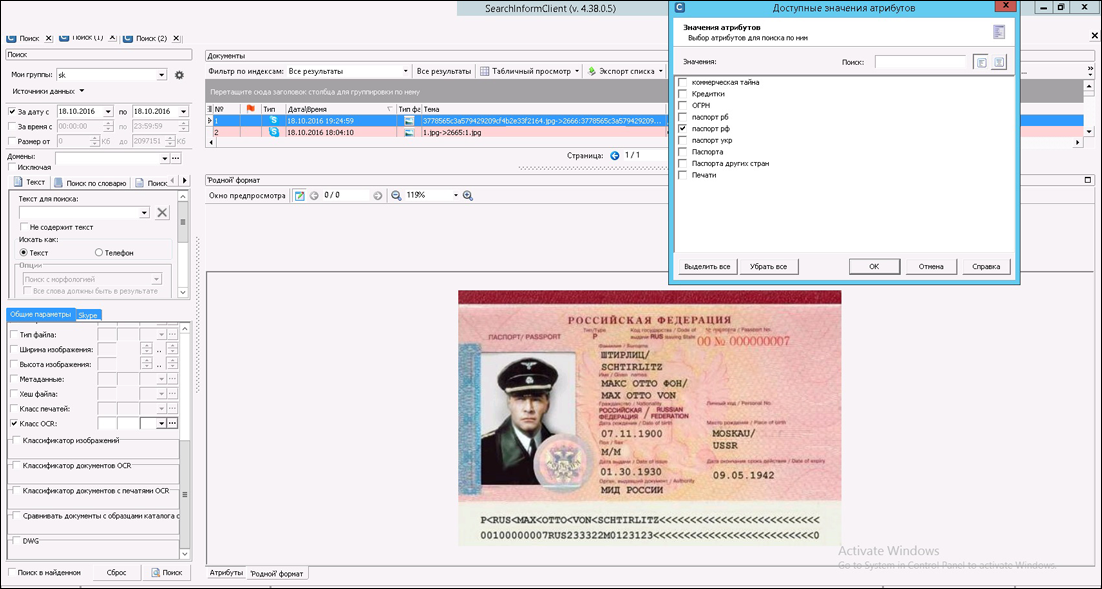
Также специалисты по информационной безопасности отслеживают передачу таких данных по «личным» каналам и хранение этих данных на носителях (хранение регламентировано, но если передача третьим лицам считается критичным нарушением, то копирование в «неправильную папочку» – незначительным нарушением).
Когда идет работа в штатном режиме, ИБ полагается на автоматику DLP и работает исключительно с отчетами системы. Когда идет какое-то расследование, начинаются пристальные проверки и с потоком данных начинают работать вручную. Если нужно выявить все действия, происходящие с объектом «паспорт», выставляется релевантность политики 70-80%, из миллиона событий отфильтровывается 500, они просматриваются вручную и принимаются соответствующие меры. Если произошло что-то серьезное, сужают политику до «сотрудник\дата\время» и релевантность сильно уменьшают (вплоть до 1%) – данных, не относящихся к делу, будет на порядок больше, но и вероятность пропустить критичные события сильно уменьшается.
Светлана Лузгина, служба корпоративных коммуникаций ABBYY,
Алексей Парфентьев, технический аналитик SearchInform
ссылка на оригинал статьи https://habrahabr.ru/post/314830/
Добавить комментарий