«В следующие два года нужно не пытаться изобразить из себя что-то особенное, а просто быть достаточно умным, чтобы компоновать то, что человечество уже создало» (с) bobuk
Год назад на внутреннем хакатоне (да, помимо верстальщицы Риты, у нас есть хакатоны) наши ростовские ребята за ночь скрестили визуальный текстовый редактор, «Типограф Муравьева» и антиплагиат-сервис. Получилась штука, которая помогала быстро подготовить и отправить публикацию в блог.
Одно время штука жила как сайд-проект, затем нам дали немного ресурсов — ну, как внутреннему стартапу. В итоге получилось удобное коллективное медиа без редакции.

Старик Гутенберг был бы доволен
Оно позволяет людям читать занятные истории, как дядька-водолаз 40 лет поднимает затонувшие корабли в Баренцевом море, а писателям на популярные нетехнические темы — немного зарабатывать на текстах.
Давайте посмотрим, что учитывать при разработке подобного сервиса, и что выбрать, чтобы без костылей.
По традиции, мы разбили пост на главки — в каждой есть советы и прямая речь участника проекта с минимумом внешних комментариев.
Почему из 10 редакторов стоит выбрать Medium (JS)
Спасибо Муравьеву за типограф (Python)
Как работает система антиплагиата (Pytnon)
Как автору понять, какой эффект дают тексты
Как это поддерживать (о работе с сисадминами)
История о дядьке-водолазе (на uPages)
Но начнем с начала. Когда сайд-проект стал перерастать в высоконагруженную платформу, появилось понимание, что что-то нужно дописать и переписать.
0. Как мы выбирали технологии
Мы рассчитываем, что уже до конца года платформой воспользуются 8 тысяч авторов, а читательская аудитория приблизится к 300 тысячам.
Илья devhard, CTO uPages: «При выборе технологий для проекта мы исходили из таких соображений: перспективность и устойчивость к большим нагрузкам.
Выбор пал на связку Node.js + MongoDB. На клиенте никаких ангуляров, реактов, редуксов. В качестве фреймворка выбрали Express.js из-за его минималистичности и наличия всего необходимого из коробки или с небольшими дополнительными установками.
Также у нас были ESlint — утилита, которая сильно помогла привести код нескольких разработчиков к более-менее единому стилю без долгих споров в духе «что лучше: табы или пробелы». Очень полезно на ранних этапах разработки.
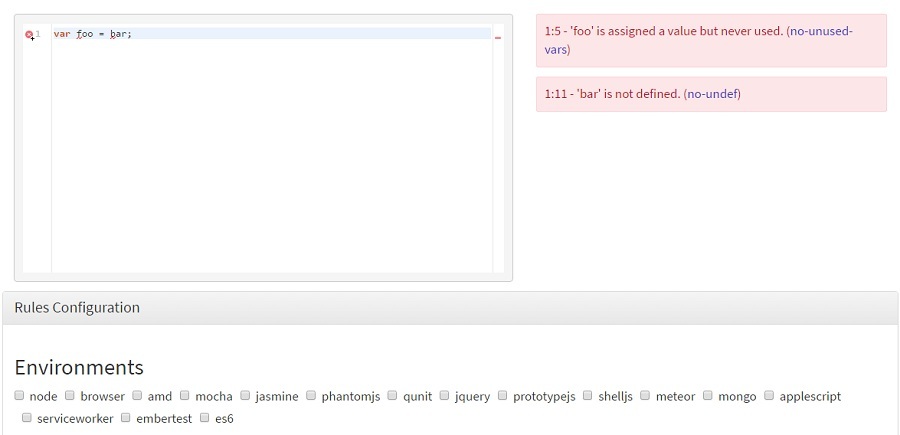
У ESlint есть демка на сайте. Скачать проект можно с GitHub.
Docker-контейнеры — в качестве рабочего окружения для приложений проекта — чтобы обезопасить себя от паранойи вроде «обновим библиотеку и всё сломается» и при необходимости быстро получить нужные версии библиотек или даже несколько абсолютно разных сборок (грубо говоря, stable и bleeding_edge сборки).
Еще у нас было 3 Git-репозитория (один локально в офисе, два — в разных дата-центрах). И я знал, что когда-нибудь мы начнем писать визуальный редактор».
1. Если вы решили написать свой собственный WYSIWYG, мы вам сочувствуем
 Сергей, наш разработчик: «Прототип с хакатона делался для блогов и сайтов на uCoz. И естественно, первым делом мы подумали взять что-то оттуда. Но, как известно, часть uCoz написана на Perl — а мы выбрали Node.js. Значит, редактор пришлось бы подключать как отдельный сервис или переписывать.
Сергей, наш разработчик: «Прототип с хакатона делался для блогов и сайтов на uCoz. И естественно, первым делом мы подумали взять что-то оттуда. Но, как известно, часть uCoz написана на Perl — а мы выбрали Node.js. Значит, редактор пришлось бы подключать как отдельный сервис или переписывать.
Отсмотрев еще с десяток вариантов, отбросили и их, потому что:
- Они либо не являлись «что-вижу-то-и-получаю» редакторами.
- Либо из коробки выглядели не современно, а как Word 2003.
- Либо кастомизировать их — все равно что костылезировать.
Список редакторов, которые мы не рекомендуем, вы найдете в первом комментарии, но один раскроем прямо сейчас:
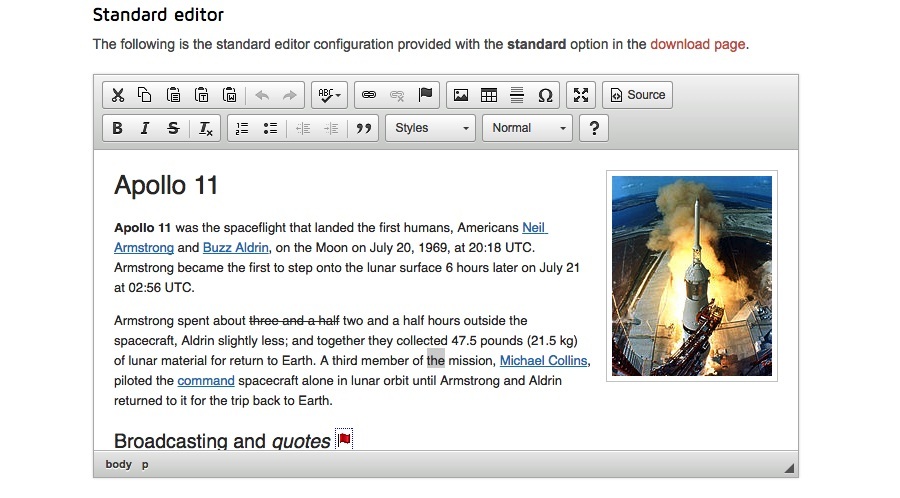
CKEDITOR — не твой бро (хотя бы по причине №2)
Авторами на площадке будут разные люди — и профи-журналисты, и копирайтеры, и совсем новички, и те, кто пробовал блогерствовать в суровые 2000-е. Хотелось сделать редактор таким, чтобы каждый мог загрузить статью быстро и без лишней возни.
Поискав еще, мы поняли, что на весну 2016-го выбор был однозначен — Medium Editor, опенсорсный редактор, вдохновленный популярной одноименной блог-платформой. На первый взгляд, в нем одни плюсы.
У ME довольно полная и понятная документация, проект постоянно допиливается, он не заброшен. Также у него были нужные функций «из коробки» (тулбар и инструменты для работы с текстом — это то, что на GitHub) и возможности кастомизации.

Инструменты редактирования появляются только тогда, когда нужны. За плюсиком сбоку скрывается вставка фото и видео.
Виджеты, которые в комплект не входили — «видео», «картинки» и «разделитель» — я писал сам, отталкиваясь от дизайна. И их создание не заняло много времени.
Но не обошлось без ложки дегтя. Первой неожиданностью стал тот факт, что ME переопределял стандартные события внутри редактора — keyup, paste и т.д., заменяя их своими. Чтобы взять контроль над ситуацией, пришлось лезть в код ME и добавлять исключение.

Обнаружив уязвимость, мы написали тем, кто использует ME в проектах, и объяснили, как ее закрыть.
Уязвимость обнаружилась при первых тестах. Мы поняли, что в ME нет защиты от опасных ссылок, таких как
javascript:alert('xss http://www.ru')Это можно решить, элементарно отслеживая и ломая последовательности вида javascript:, как мы и сделали.
С одной стороны, делаем грубо — в случае с опасной ссылкой, мы просто не пытаемся сохранить статью. Но с другой, если человек решит провести такой эксперимент, то он явно не наш пользователь.
2. Кавычки ёлочкой и тире вместо дефиса
Петр, наш разработчик: «Вообще, стоит отметить, что обработка текста на естественном языке — задача нетривиальная, особенно что касается русского языка. Было очевидно — не стоит затягивать разработку попытками сделать что-то свое, раз можно применить уже готовые инструменты с нужным нам функционалом.
Решено было внедрить знакомые нам по хакатону утилиты. Их мы запихнули в отдельный микросервис в виде Docker-контейнера — своеобразный Python-wrapper со своим API, работающий через WSGI.

Одним из инструментов стал „Типограф Муравьева“ . По моему скромному мнению, во всем Рунете нет лучшего инструмента для исправления типографики: внушительная сводка правил, реализации на PHP и Python. И что очень важно — лицензия.
К большой чести @emuragev, он распространяется как народное достояние (public domain), поэтому мы взяли его и прикрутили к нашему проекту в Python-реализации. Пока ничего не меняли, хотя есть возможность и идеи, как дополнить правила».
3. Как не стать SEO-контент-фермой
Чтобы на площадку не ломанулись графоманы и любители перепостить из уютных бложиков, мы ввели премодерацию. Текст публикаций проверяется на уникальность: выполнить такую проверку может как сам автор, так и мы.

Петр, наш разработчик: «Концепция платформы — в занятных историях и обзорах без жесткого регулирования тем и форматов. Но еще мы даем заработать на каждом тексте. И понятно, что он должен быть уникальным.
В целом, чтобы реализовать онлайн-функционал для проверки уникальности текста, вам нужна технология Яндекс.XML и, в идеале, база текстовых паттернов, чтобы сперва прогонять по ней текст, а уж потом стучаться к Y.XML.
Но количество запросов с одного домена к сервису Y.XML ограничено и напрямую зависит от тИЦ сайта. А какой же тИЦ может быть у еще не релизнутого web-проекта? Никакой. А во время разработки постоянно требовалось слать запросы, парсить ответ и что-то делать с данными.
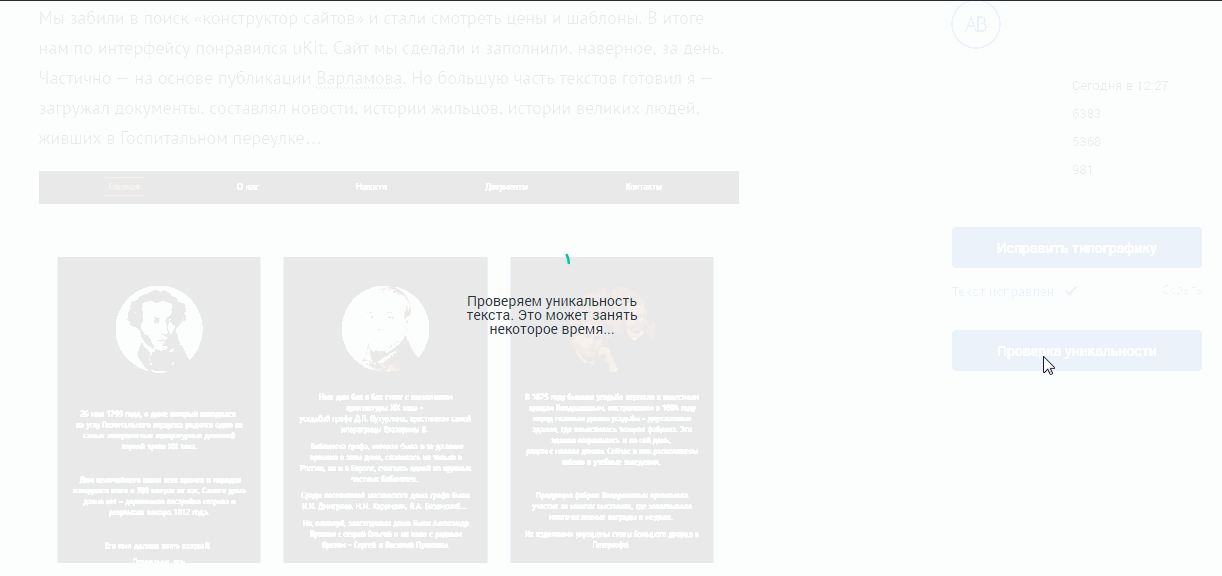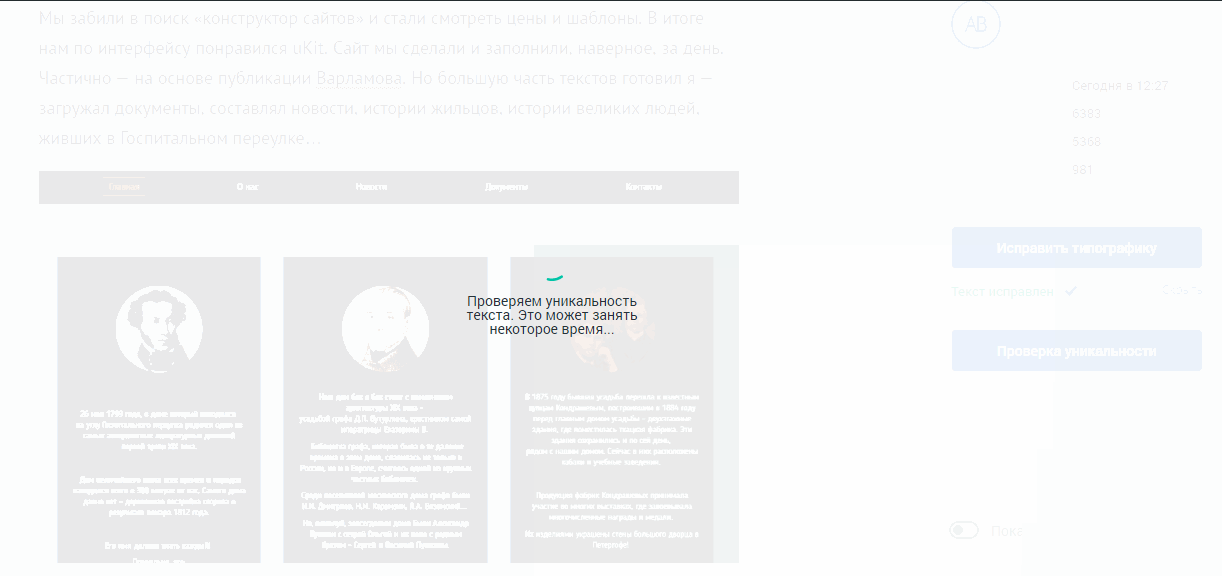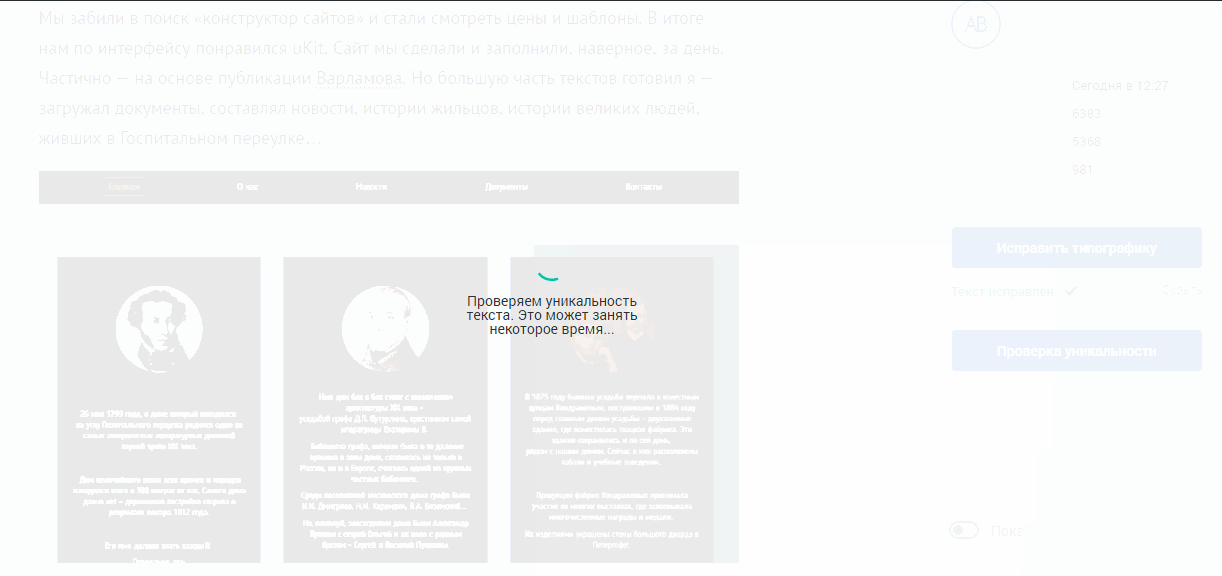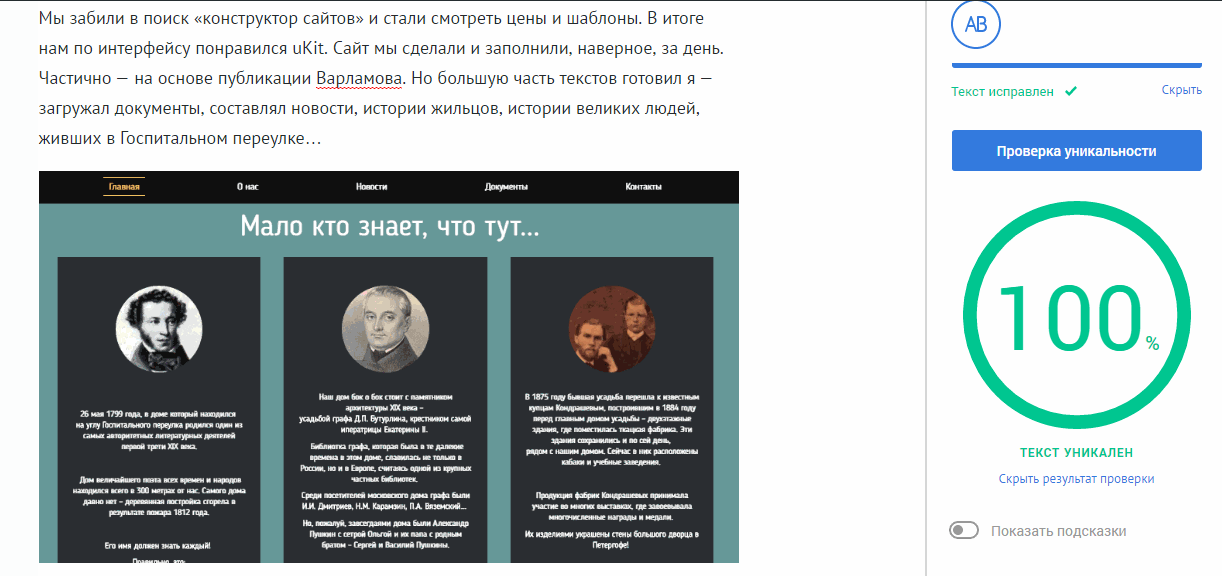
Можно было бы, конечно, слать запрос с какого-нибудь подвластного нам домена, где лежит сайт с большим тИЦ. Но в итоге мы решили так не делать и взять уже готовый API Content-Watch (CW). Система платная, но для нас ребята пошли на спецусловия.
Хотя отзывы в сети разнятся, кажется, они отлично разобрались в вопросе и запилили сервис с хорошей документацией, минималистичным API и какими-то своими алгоритмами в дополнение к Y.XML.
Для нас, как для пользователей их сервиса, все работает очень просто — мы шлем запрос на сервис CW с текстом, который нужно проверить, а затем нам возвращается ответ в виде json. В ответе содержится информация о степени уникальности текста (по ней мы показываем красивую круговую диаграмму) и ссылки на страницы в сети, где встречается тот или иной фрагмент текста — тему с ссылками пока используют только модераторы, которые проверяют статьи перед публикацией на главной».
4. Как дать авторам анализировать статьи
Чтобы авторам было интереснее, мы решили внедрить инструменты анализа текста и оплату для всех. Доход образуется так: рядом с текстом есть два баннера — рекламный и рекомендательный. У баннера есть цена клика (ее определяет рекламная система) — мы отдаем 80% от стоимости каждого клика автору.
Илья, CTO uPages: «Интересной задачей было показать автору, сколько и когда он заработал, а заодно показать факт — статью дочитают не все, и надо учиться работать над вовлечением внутри текста, а не только над тизером и заголовком.
Поэтому мы сделали модуль статистики.
Он состоит из клиентской части — мы рисуем графики через Chart.js, отдавая цифры и списки.
На стороне сервера мы что-то считаем сами — число лайков, прочтений, закладок, например.
А часть данных — о кликах на баннеры, с которых и зарабатывает автор, — берём через Google Analytics API и у сервиса рекомендаций Engageya. Удобного API у вторых нет, но удалось договориться, что раз в сутки они выгружают нам отчеты cо всей необходимой информацией. Так мы показываем клики по рекламе сбоку от статьи и доход автора.
В случае с API Google, запросы идут с определенной периодичностью, чтобы уложиться в лимиты.
Да, Google API — это боль. При таком количестве различных продуктов приходится перечитать огромное количество документации и попробовать несколько подходов. Сначала мы пытались использовать AdSense Management API для получения данных о доходе Adsense, но в их отчетах нельзя получить информацию для подробного учёта источников поступлений.
После долгого гугления и битья головой о клавиатуру, спасение пришло от аналитики.
Между аккаунтами Google Adsense и Analytics устанавливается связь, после этого данные AdSense становятся доступны при запросах к API аналитики».
5. Как это поддерживать

Руслан pys, системный администратор: «Задача тонко намекала, что это должен быть облачный сервер. Ну и не очень-то хотелось заниматься всем этим мониторингом температуры материнской платы, скорости вращения вентиляторов, следить за дисками — и менять их, не забывая переписывать серийники.
Требования к облачным виртуалкам мы взяли следующие:
- ЦОД в Москве (т.к. у нас русскоязычная аудитория),
- удобное изменение конфигурации,
- два сервера у разных провайдеров — для отказоустойчивости и возможности проведения технических работ без даунтайма.

Другой важной задачей была модель деплоя софта. Очевидно, что жизнь на сервере разработки и в бою — это две большие разницы. Это хорошо, что ребята сразу выбрали всеобщую контейнеризацию — за что им, пользуясь случаем, выражается спасибо от всея системной администрации.
В качестве системы деплоя контейнеров и управления конфигурациями мы выбрали Saltstack — поскольку уже успешно применяли его на других проектах.
По итогам приведения сервиса в боевую готовность возникло закономерное желание провести учения, т.е. стрельбы из Яндекс.Танка. В ходе экспериментов с разным соотношением запросов к ядрам процессора и настройками системного и прикладного софта, мы определили емкость одной ноды и корреляцию этой емкости с конфигурацией виртуального железа и настройками ОС. Ну и запустились 1-го ноября».
P.S.
Присылайте свои http-запросы на наш новый сервис!
ссылка на оригинал статьи https://habrahabr.ru/post/314796/
Добавить комментарий