В предыдущей статье из цикла «Deep Learning» вы узнали о сравнении фреймворков для символьного глубокого обучения. В этом материале речь пойдет о глубокой настройке сверточных нейронных сетей для повышения средней точности и эффективности классификации медицинских изображений.

Цикл статей «Deep Learning»
1. Сравнение фреймворков для символьного глубокого обучения.
2. Transfer learning и тонкая настройка глубоких сверточных нейронных сетей.
3. Cочетание глубокой сверточной нейронной сети с рекуррентной нейронной сетью.
Примечание: далее повествование будет вестись от имени автора.
Введение
Распространенной причиной потери зрения является диабетическая ретинопатия (ДР) — заболевание глаз при диабете. Исследование пациентов с помощью флюоресцентной ангиографии потенциально способно снизить риск слепоты. Существующие тенденции исследований показывают, что глубокие сверточные нейросети (ГСНС) весьма эффективны для автоматического анализа больших наборов изображений и для выявления отличительных признаков, по которым можно распределить изображения на разные категории практически без ошибок. Обучение ГСНС редко происходит с нуля из-за отсутствия заранее заданных наборов с достаточным количеством изображений, относящихся к определенной области. Поскольку для обучения современных ГСНС требуется 2–3 недели, центр Berkley Vision and Learning Center (BVLC) выпустил итоговые контрольные точки для ГСНС. В этой публикации мы используем заранее обученную сеть: GoogLeNet. Сеть GoogLeNet обучена на большом наборе естественных изображений ImageNet. Мы передаем распознанные весовые данные ImageNet в качестве начальных для сети, затем настраиваем заранее обученную универсальную сеть для распознавания изображений флюоресцентной ангиографии глаз и повышения точности предсказания ДР.
Использование явного выделения отличительных признаков для предсказания диабетической ретинопатии
В настоящий момент уже проделана обширная работа по разработке алгоритмов и методик обработки изображений для явного выделения отличительных признаков, характерных для пациентов с ДР. В стандартной классификации изображений применяется следующий универсальный рабочий процесс:
- Методики предварительной обработки изображений для удаления шума и повышения контрастности.
- Методика выделения отличительных признаков.
- Классификация.
- Предсказание.
Оливер Фауст и другие его коллеги предоставляют очень подробный анализ моделей, использующих явное выделение отличительных признаков ДР. Вуйосевич с коллегами создали двоичный классификатор на основе набора данных 55 пациентов, явным образом выделив отдельные отличительные признаки поражений. Некоторые авторы использовали методики морфологической обработки изображений для извлечения отличительных признаков кровеносных сосудов и кровотечений, а затем обучили машину опорных векторов на наборе данных из 331 изображения. Другие специалисты сообщают о точности 90% и чувствительности 90% в задаче двоичной классификации на наборе данных из 140 изображений.
Тем не менее все эти процессы связаны со значительными затратами времени и усилий. Для дальнейшего повышения точности предсказаний требуются огромные объемы маркированных данных. Обработка изображений и выделение отличительных признаков в наборах данных изображений — весьма сложный и длительный процесс. Поэтому мы решили автоматизировать обработку изображений и этап выделения отличительных признаков, используя ГСНС.
Глубокая сверточная нейросеть (ГСНС)
Для выделения отличительных признаков в изображениях требуются экспертные знания. Функции выделения в ГСНС автоматически формируют изображения для определенных областей, не используя никакие функции обработки отличительных признаков. Благодаря этому процессу ГСНС пригодны для анализа изображений:
- ГСНС обучают сети с множеством слоев.
- Несколько слоев работают вместе для формирования улучшенного пространства отличительных признаков.
- Начальные слои изучают первостепенные признаки (цвет, края и пр.).
- Дальнейшие слои изучают признаки более высокого порядка (в соответствии с входным набором данных).
- Наконец, признаки итогового слоя подаются в слои классификации.

Слои C — свертки, слои S — пулы и выборки
Свертка. Сверточные слои состоят из прямоугольной сети нейронов. Весовые данные при этом одинаковые для каждого нейрона в сверточном слое. Весовые данные сверточного слоя определяют фильтр свертки.
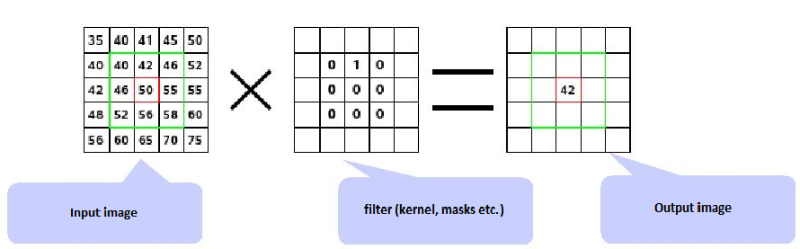
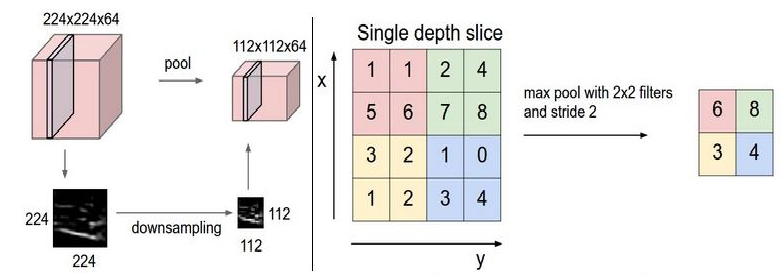
Опрос. Опрашивающий слой берет небольшие прямоугольные блоки из сверточного слоя и проводит подвыборку, чтобы сделать из этого блока один выход.
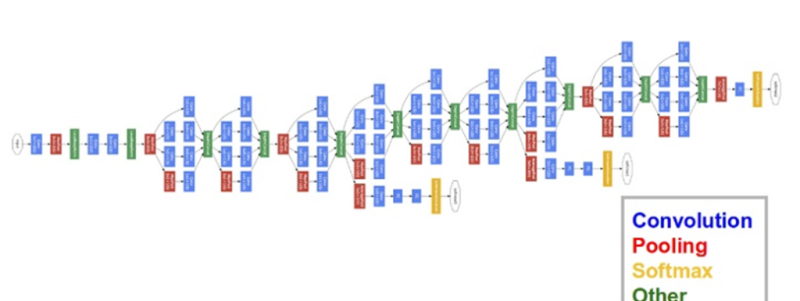
В этой публикации мы используем ГСНС GoogLeNet DCNN, разработанную в Google. Нейросеть GoogLeNet выиграла конкурс ImageNet в 2014 году, поставив рекорд по наилучшим единовременным результатам. Причины выбора этой модели — глубина работы и экономное использование ресурсов архитектуры.
Transfer learning и тонкая настройка глубоких сверточных нейросетей
На практике обучение целых ГСНС обычно не производится с нуля с произвольной инициализацией. Причина состоит в том, что обычно не удается найти набор данных достаточного размера, требуемого для сети нужной глубины. Вместо этого чаще всего происходит предварительное обучение ГСНС на очень крупном наборе данных, а затем использование весовых данных обученной ГСНС либо в качестве инициализации, либо в качестве выделения отличительных признаков для определенной задачи.
Тонкая настройка. Стратегии переноса обучения зависят от разных факторов, но наиболее важными являются два: размер нового набора данных и его схожесть с исходным набором данных. Если учесть, что характер работы ГСНС более универсален на ранних слоях и становится более тесно связанным с конкретным набором данных на последующих слоях, можно выделить четыре основных сценария:
- Новый набор данных меньше по размеру и аналогичен по содержанию исходному набору данных. Если объем данных невелик, то нет смысла проводить тонкую настройку ГСНС из-за чрезмерной подгонки. Поскольку данные схожи с изначальными, можно предполагать, что отличительные черты в ГСНС будут релевантны и для этого набора данных. Поэтому оптимальным решением является обучение линейного классификатора отличительным признаком СНС.
- Новый набор данных относительно крупный и аналогичен по содержанию исходному набору данных. Поскольку у нас больше данных, можно не беспокоиться о чрезмерной подгонке, если мы попытаемся провести тонкую настройку всей сети.
- Новый набор данных меньше по размеру и существенно отличается по содержанию от исходного набора данных. Поскольку объем данных невелик, будет вполне достаточно только линейного классификатора. Так как данные существенно отличаются, лучше обучать классификатор не с вершины сети, где содержатся более конкретные данные. Вместо этого лучше обучить классификатор, активировав его на более ранних слоях сети.
- Новый набор данных относительно крупный и существенно отличается по содержанию от исходного набора данных. Поскольку набор данных очень крупный, можно позволить себе обучить всю ГСНС с нуля. Тем не менее на практике зачастую все равно оказывается выгоднее использовать для инициализации весовые данные из заранее обученной модели. В этом случае мы будем располагать достаточным объемом данных для тонкой настройки всей сети.
Тонкая настройка ГСНС. Решая вопрос предсказания ДР, мы действуем по сценарию IV. Мы проводим тонкую настройку весовых данных заранее обученной ГСНС, продолжая обратное распространение. Можно либо провести тонкую настройку всех слоев ГСНС, либо оставить некоторые из ранних слоев неизменными (во избежание чрезмерной подгонки) и настроить только высокоуровневую часть сети. Это обусловлено тем, что на ранних слоях ГСНС содержатся более универсальные функции (например, определение краев или цветов), полезные для множества задач, а более поздние слои ГСНС уже ориентированы на классы набора данных ДР.
Ограничения transfer learning. Поскольку мы используем заранее обученную сеть, наш выбор архитектуры модели несколько ограничен. Например, мы не можем произвольным образом убрать сверточные слои из заранее обученной модели. Тем не менее благодаря совместному использованию параметров можно с легкостью запустить заранее обученную сеть для изображений разного пространственного размера. Это наиболее очевидно в случае сверточных и выборочных слоев, поскольку их функция перенаправления не зависит от пространственного размера входных данных. В случае с полносвязанными слоями этот принцип сохраняется, поскольку полносвязанные слои можно преобразовать в сверточный слой.
Скорость обучения. Мы используем уменьшенную скорость обучения для весовых данных ГСНС, подвергаемых тонкой настройке, исходя из того, что качество весовых данных заранее обученной ГСНС относительно высоко. Не следует искажать эти данные слишком быстро или слишком сильно, поэтому и скорость обучения, и спад скорости должны быть относительно низкими.
Дополнение данных. Одним из недостатков нерегулярных нейросетей является их чрезмерная гибкость: они одинаково хорошо обучаются распознаванию как деталей одежды, так и помех, из-за чего повышается вероятность чрезмерной подгонки. Мы применяем регулирование на уровне 2, чтобы избежать этого. Впрочем, даже после этого был значительный разрыв в производительности между обучением и проверкой изображений ДР, что указывает на чрезмерную подгонку в процессе тонкой настройки. Чтобы устранить этот эффект, мы применяем дополнение данных для набора данных изображений ДР.
Существует множество способов дополнения данных, например, зеркальное отображение по горизонтали, случайная обрезка, изменение цветов. Поскольку цветовая информация этих изображений очень важна, мы применяем лишь поворот изображений на разные углы: на 0, 90, 180 и 270 градусов.
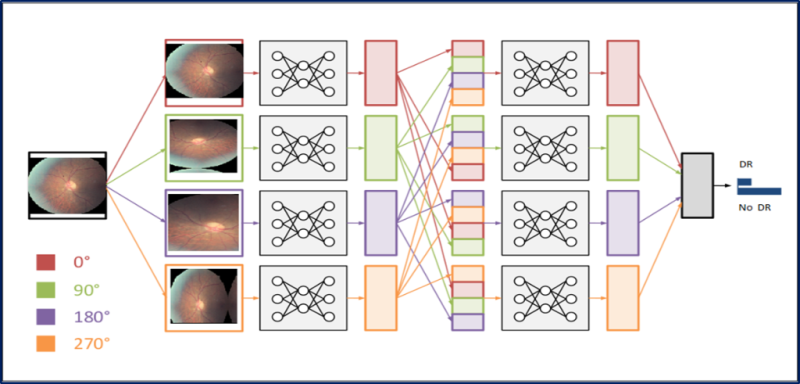
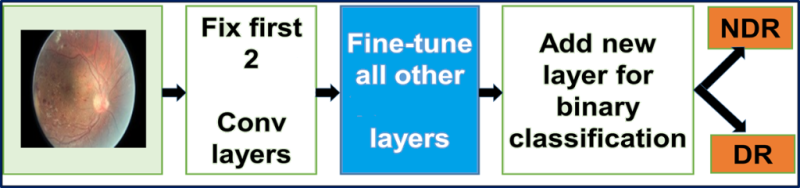
Замена входного слоя заранее обученной сети GoogLeNet на изображения ДР. Мы проводим тонкую настройку всех слоев, кроме двух верхних заранее обученных слоев, содержащих универсальные весовые данные.
Тонкая настройка GoogLeNet. Используемая нами сеть GoogLeNet изначально была обучена на наборе данных ImageNet. Набор данных ImageNet содержит около 1 млн естественных изображений и 1000 меток/категорий. В нашем размеченном наборе данных ДР содержится около 30 000 изображений, относящихся к рассматриваемой области, и четыре метки/категории. Следовательно, этого набора данных ДР недостаточно для обучения сложной сети, какой является GoogLeNet: мы будем использовать весовые данные из сети GoogLeNet, обученной по ImageNet. Мы проводим тонкую настройку всех слоев, кроме двух верхних заранее обученных слоев, содержащих универсальные весовые данные. Первоначальный слой классификации loss3/classifier выводит предсказания для 1000 классов. Мы заменяем его новым двоичным слоем.
Заключение
Благодаря тонкой настройке можно применять усовершенствованные модели ГСНС в новых областях, где их было бы невозможно использовать иначе из-за недостатка данных или ограничений по времени и стоимости. Такой подход позволяет добиться существенного повышения средней точности и эффективности классификации медицинских изображений.
Если вы увидели неточность перевода, сообщите пожалуйста об этом в личные сообщения.
ссылка на оригинал статьи https://habrahabr.ru/post/314934/
Добавить комментарий