
В последнее время появилось некоторое количество альтернативных технологий сжатия текстовых данных (в дополнение к gzip), которые не только работают (=жмут) лучше (судя по официальным сравнениям), но и доступны в браузерах (преимущественно, в Chrome-based, но это уже 40-60% аудитории сайтов).
Ниже я расскажу, зачем может быть полезно дельта-сжатие данных (SDCH, SanDwiCH) и как его настроить на вашем сервере.
Zopfli, brotli, sdch
Небольшая сводка, что за звери такие zopfli, brotli и sdch. Zopfli — «улучшенная» версия zlib, которая создает полностью совместимые с алгоритмом LZ77 файлы, но улучшает сжатие на 3-8%. Т.е. это «gzip на стероидах». Плюсами является полная совместимость создаваемых архивов с любыми распаковщиками, которые понимает формат gzip, включая все браузеры (и скорость распаковки не отличается от распаковки обычного архива). Минусом является большое время (примерно в 50-100 раз больше) архивации данных. Это ограничивает использование zopfli только для gzip_static решений (когда данные предварительно сжимаются, и отдаются уже в сжатом виде клиенту, а не архивируются «на лету»).
Brotli является маленькой революцией в сжатии текстовых данных веб-сайтов. В самой спецификации заложен словарь (2/3 размера самой спецификации) с наиболее употребляемыми фразами (включая HTML-теги, CSS-инструкции и JavaScript-код). Этот словарь имеется у всех клиентов, которые поддерживают этот формат сжатия, за счет чего существенно сокращается размер передаваемых данных (zlib-архив содержит весь словарь, который требуется для его распаковки, brotli-архив не содержит всего словаря). За счет устранения передачи словаря достигается выигрыш еще в 15-20% относительно zopfli-архива (или в 20-25%, если брать gzip-9). Минусом является то, что brotli должен поддерживаться браузерами (сейчас Chrome, Android + Firefox). И скорость сжатия данных тоже достаточно низкая.
Brotli может использоваться как дополнение к gzip-сжатию статических архивов для тех клиентов, которые его понимают. Это позволяет, в среднем, сократить размер передаваемых текстовых данных еще на 10%. Здесь подробное руководство, как прикрутить brotli для nginx.
SDCH является дополнительным подходом, этаким поворотом на 90 градусов относительно основной парадигмы, и реализацией дельта-кодирования данных. В чем суть: мы передаем пользователю (браузеру) некоторый набор исходных данных (первый HTML-документ), а затем начинаем отправлять только изменения относительно этого документа (дельта-чанки). На практике это приводит к сокращению передаваемых данных еще в 1,5-3 раза. И полностью совместимо с дополнительным gzip-сжатием дельта-чанков.
Теперь по порядку.
Как работает SDCH
Первое, что я рекомендую сделать, — это просмотреть презентацию LinkedIn про SDCH (и ее текстовую расшифровку), общее введение в SDCH и прикладное использование с «подводными камнями».
Вся суть коммуникаций между браузером и сервером представлена в этой схеме:
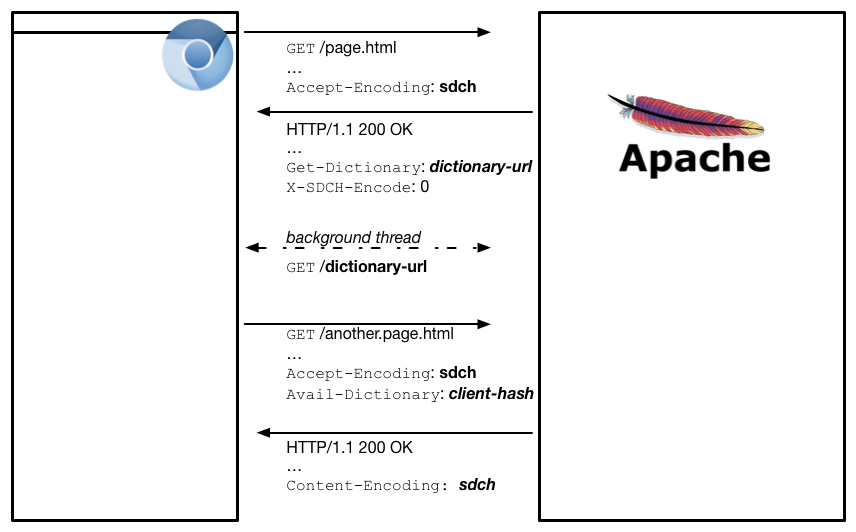
5-шаговое взаимодействие реализуется так:
- Браузер запрашивает страницу сайта, сообщая, что поддерживаем sdch-кодировку (
Accept-Encoding: sdch). - Сервер отвечает, что текущий контент страницы еще не сжат (
X-SDCH-Encode: 0), но словарь для сжатия можно загрузить по адресу (Get-Dictionary: ...) - Браузер получает страницу сайта и словарь для загрузки. Загружает словарь параллельно загрузке контента текущей страницы.
- Браузер делает запрос к следующей странице сайта, отправляя хэш загруженного словаря (
Avail-Dictionary). - Сервер отвечает sdch-кодированной страницей, которая может быть дополнительно gzip-сжата (
Content-Encoding: sdch, gzip= сначала нужно распаковать с помощью gzip, а потом декодировать с помощью SDCH-словаря).
Заводим SDCH на сервере
Я предполагаю, что читатель в курсе, как собирать nginx (и не только) из исходных кодов, как его настраивать (nginx.conf) и как тестировать запросы/ответы (в браузере или консоли). Дальше будет более-менее детальное руководство, как запустить SDCH для своего сайта.
Нам потребуется:
- Пакет open-vcdiff (аккуратно собираем, включая репозитории в third_party), реализующий само кодирование.
- Пакет femtozip для сборки SDCH-словаря.
- (Опционально, если есть cmake LVL80+) SInGe как альтернативная утилита для сборки и пересборки словарей.
- Nginx-модуль sdch_module
- (Опционально, если хотим zopfli-сжатие словаря) Zopfli
- (Опционально, если хотим brotli-сжатие словаря) Brotli + brotli_static
Собираем и настраиваем
Собираем open-vcdiff
Собираем femtozip
Загружаем модули nginx из репозиториев и добавляем их при сборке nginx в configure
—add-module=/путь_до_исходных_кодов_модуля/sdch_module \
Создаем словарь
Правильный словарь — единственный аспект SDCH, требующий существенного внимания. При большом размере словаря он будет сильно замедлять загрузку первой страницы для пользователя (поскольку загружается браузером параллельно ключевым ресурсам — CSS и JavaScript — сразу после получения HTML-ответа). При малом размере словаря значительного выигрыша при использовании SDCH не будет.
Правильная стратегия в свете всех озвученных условий выглядит примерно следующим образом:
- Использовать SDCH-словари только для динамического (HTML) контента. Для статических файлов отлично работает zopfli+brotli, они загружаются один раз (почти все ресурсные файлы попадают в браузер при загрузке первой страницы сайта), размер SDCH-словаря для статических ресурсов может быть на порядок больше HTML.
- Держать SDCH-словарь в пределах от 0,5 до 3 размеров средней HTML-страницы сайта.
- Собирать SDCH-словарь для сайта не чаще, чем раз в неделю.
Для сборки словаря нам потребуются некоторые (не очень много) характерные страницы сайта. При простой сквозной структуре дизайна можно просто взять 3-5 актуальных страниц и скопировать их в папку для сборки словаря.
После этого запускаем femtozip (или SInGe, если удалось собрать его):
fzip --dictonly --build --model website.dict --maxdict 36000 html_folder
Здесь 36000 — магическое число, ограничивающее размер словаря сверху (наши 0,5-3 размера HTML-файла), website.dict — результирующий файл словаря, html_folder — папка, куда скопировали HTML-страницы.
Внимание, магия! В выходной файл — website.dict — нужно добавить 3 строки заголовков и перевод строки после них (для передачи в браузер). После этого использовать этот словарь как входящий для vcdiff будет нельзя, поэтому рекомендую иметь два файла для тестирования: сам словарь (например, website.raw.dict) и словарь для браузера ( (например, website.dict).
Полученный файл словаря можно дополнительно сжать через brotli (сейчас brotli поддерживается во всех браузерах, которые поддерживают sdch):
bro --quality 11 --input website.dict --output website.dict.br
Настраиваем nginx
После сборки nginx с модулем SDCH нам остается только положить все файлы словаря в папку сайта, например, в корень и задать конфигурацию SDCH (минимальный размер в 3 Кб — из приведенных выше исследований про эффективность SDCH для малых файлов):
sdch_dict /full_path_to_sdch_dictionary/website.dict;
sdch_url /website.dict;
sdch_min_length 3096;
sdch_nodict_types text/plain application/xhtml+xml text/richtext text/xsd text/xsl text/xml application/xml application/json image/x-icon application/rss+xml;
sdch_nodict_types text/css;
sdch_nodict_types application/msword application/vnd.ms-excel application/vnd.ms-powerpoint text/csv;
sdch_nodict_types text/javascript application/javascript application/x-javascript text/x-js text/ecmascript application/ecmascript text/vbscript text/fluffscript;
sdch_nodict_types image/vnd.microsoft.icon image/bmp image/x-ms-bmp;
sdch_nodict_types image/svg+xml application/x-font-ttf font/truetype application/x-font font/opentype font/otf font/ttf application/x-font-truetype application/x-font-opentype application/vnd.ms-fontobject application/font-woff application/font-woff2 application/pdf;
sdch_nodict_types application/vnd.groove-tool-template;
sdch_nodict_types image/gif image/png image/jpeg image/tiff;
Если при перезапуске nginx выдается ошибка «не могу загрузить SDCH-словарь» — проверьте, правильно ли добавили в словарь 4 строки заголовков. Они обязательно должны присутствовать.
Тестирование и проверка
Для тестирования нам нужно получить SHA256-хэш словаря (точнее, первые 8 символов), чтобы сразу отправить на сервер — типа словарь у нас уже есть. Сделать это можно, например, так (в папке с финальным словарем):
a=$(cat website.dict | sha256sum | awk '{print $1}' | xxd -len 6 -r -p | base64);echo ${a:0:8}
Далее запрашиваем SDCH-кодированный контент, используя полученный хэш.
curl -v «127.0.0.1» —insecure -o sdch.html —header «Host: website.ru» —header «Accept-Encoding: sdch» —header «Avail-Dictionary: HASH»
Получившийся файл — sdch.html — можно раскодировать через vcdiff (используя исходный словарь, без заголовков):
cat sdch.html | vcdiff decode -dictionary website.raw.dict > result.html
Теперь сравниваем result.html с исходной страницей и радуемся уменьшению размера.
При возникновении каких-либо проблем с раскодировкой данных нужно пересобрать словарь (используя другой размер, например, или другой набор файлов).
Практический выхлоп
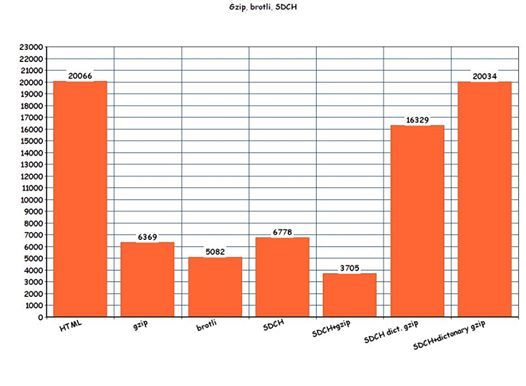
Относительно стабильный результат работы SDCH (+gzip) «на лету» дал уменьшение HTML-файлов в 1,5-2 раза (3 Кб против 5,5-6 Кб gzip-сжатых). В некоторых «экстремальных» условиях (при увеличении SDCH-словаря в brotli-сжатом виде до 2 сжатых HTML-страниц) удалось добиться выигрыша в 3 раза (1,9 Кб против 5,7 Кб) или в 10 раз относительно минимизированного HTML-документа (19,6 Кб). С учетом существенного размера ресурсных файлов (100+ Кб CSS / JavaScript) «довесок» в виде 10 Кб SDCH-словаря выглядит несущественно, но «окупается» только через 3 просмотра страницы (не включая самую первую запрошенную страницу).
Также возможен и обратный эффект от SDCH, когда при средней глубине просмотра в 3 страницы пользователь загрузит больше данных, чем при обычном сжатии:
Заключение
SDCH реально использовать для сайта, чтобы еще в разы сократить объем передаваемых данных. Но при неверном размере словаря это будет анти-паттерном ускорения сайта.
ссылка на оригинал статьи https://habrahabr.ru/post/315784/
Добавить комментарий