Представляем вам завершающую статью из цикла по Deep Learning, в которой отражены итоги работы по обучению ГСНС для изображений из определенных областей на примере распознавания и тегирования элементов одежды. Предыдущие части вы сможете найти под катом.

Цикл статей «Deep Learning»
1. Сравнение фреймворков для символьного глубокого обучения.
2. Transfer learning и тонкая настройка глубоких сверточных нейронных сетей.
3. Cочетание глубокой сверточной нейронной сети с рекуррентной нейронной сетью.
Примечание: далее повествование будет вестись от имени автора.
Введение
Если говорить о роли одежды в обществе, распознавание вещей может иметь множество областей применения. Например, работа Лю и других авторов, посвященная определению и поиску немаркированных предметов одежды на изображениях, поможет распознавать наиболее схожие элементы в базе данных электронной коммерции. Янг и Ю смотрят на процесс распознавания элементов одежды с другой стороны: они считают, что эту информацию можно использовать в контексте видеонаблюдения, для выявления подозреваемых в преступлениях.
В этой статье на основе материалов Ванга и Виньяса, мы создадим оптимизированную модель для классификации элементов одежды, краткого описания изображений и предсказания тегов к ним.
На эту работу меня вдохновили недавние усовершенствования в области машинного перевода, задача которых состоит в переводе отдельных слов или предложений. Теперь можно переводить намного быстрее с помощью рекуррентных нейросетей (РНС), добиваясь при этом высокой скорости. Кодер РНС читает исходный тег или метку и преобразует ее в векторное представление фиксированной длины, которое, в свою очередь, используется в качестве начального скрытого состояния декодера РНС, формирующего тег или метку. Мы предлагаем пойти по этому же пути, используя глубокую сверточную нейросеть (ГСНС) вместо кодера РНС. В течение последних лет стало ясно, что сети ГСНС могут создавать достаточное представление входного изображения, встраивая его в вектор фиксированной длины, который можно использовать для различных задач. Можно естественным образом использовать ГСНС в качестве кодировщика изображения: для этого сначала нужно провести предварительное обучение задаче классификации изображений, используя скрытый уровень в качестве входа для декодера РНС, формирующего теги.

Модель РНС-СНС для создания тегов изображений одежды
В этой работе будет использована заранее обученная по ImageNet модель GoogLeNet для извлечения компонентов СНС из набора данных ДР. Затем функции СНС для обучения модели РНС с длительной краткосрочной памятью для предсказания тегов ДР.
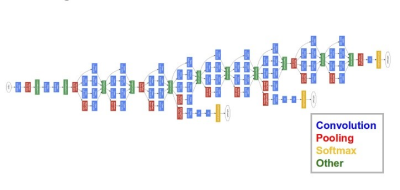
Архитектура GoogLeNet
Данные
Используем набор данных ДР: полный пайплайн для распознавания и классификации одежды людей в естественных условиях. Это решение может применяться в различных областях, например, в электронной коммерции, при проведении мероприятий, в интернет-рекламе и так далее. Пайплайн состоит из нескольких этапов: распознавания частей тела, различных каналов и визуальных атрибутов. ДР определяет 15 классов одежды и вводит эталонный набор оценочных данных для её классификации, состоящий более чем из 80 000 изображений. Также, мы используем набор данных ДР, чтобы предсказывать теги одежды для изображений, которые ранее не были проанализированы.
Изображения из тренировочных и тестовых наборов данных обладают совершенно разными показателями: разрешением, соотношением сторон, цветами и так далее. Для нейронных сетей нужны входные данные фиксированного размера, поэтому все изображения мы перевели в формат: 3 × 224 × 224.
Одним из недостатков нерегулярных нейросетей является их чрезмерная гибкость: они одинаково хорошо обучаются распознаванию как деталей одежды, так и помех, из-за чего повышается вероятность чрезмерной подгонки. Мы применяем регуляризацию Тихонова (или L2-регуляризацию), чтобы избежать этого. Впрочем, даже после этого был значительный разрыв в производительности между обучением и проверкой изображений ДР, что указывает на чрезмерную подгонку в процессе тонкой настройки. Чтобы устранить этот эффект, мы применяем дополнение данных для набора данных изображений ДР.
Существует множество способов дополнения данных, например, зеркальное отображение по горизонтали, случайная обрезка, изменение цветов. Поскольку цветовая информация этих изображений очень важна, мы применяем лишь поворот изображений на разные углы: на 0, 90, 180 и 270 градусов.

Дополненные изображения ДР
Тонкая настройка GoogleNet для ДР
Чтобы справиться с проблемой предсказания тегов ДР, мы идем по сценарию тонкой настройки из предыдущей части. Используемая нами модель GoogLeNet изначально была обучена на наборе данных ImageNet. Набор данных ImageNet содержит около 1 млн естественных изображений и 1000 меток/категорий. В нашем размеченном наборе данных ДР содержится около 80 000 изображений, относящихся к категории «одежда», и 15 меток/категорий. Набора данных ДР недостаточно для обучения столь сложной сети, как GoogLeNet. Поэтому мы используем весовые данные из модели GoogLeNet, обученной по набору данных ImageNet. Проводим тонкую настройку всех уровней заранее обученной модели GoogLeNet путем непрерывного обратного распространения.
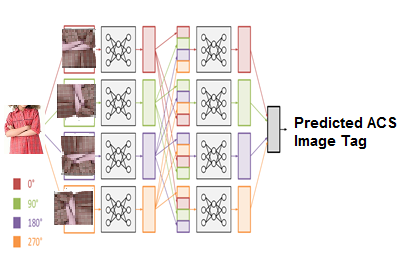
Замена входного слоя заранее обученной сети GoogLeNet на изображения ДР
Обучение РНС с длительной краткосрочной памятью
В этой работе мы используем модель РНС с длительной краткосрочной памятью, обладающей высокой производительностью при выполнении последовательных задач. В основе этой модели — ячейка памяти, кодирующая знания о наблюдаемых входных данных в каждый момент времени. Поведение ячейки управляется затворами, в роли которых используются слои, применяемые мультипликативно. Здесь используется три затвора:
- забыть текущее значение ячейки (забыть затвор f),
- прочитать входное значение ячейки (ввести затвор i),
- вывести новое значение ячейки (вывести затвор o).
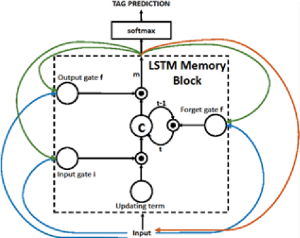
Рекуррентная нейросеть с длительной краткосрочной памятью
Блок памяти содержит ячейку «с», управляемую с помощью трех затворов. Синим показаны рекуррентные подключения: вывод «m» в момент времени (t–1) подается обратно в память во время «t» через три затвора; значение ячейки подается обратно через затвор «забыть»; предсказанное слово в момент времени (t–1) подается обратно в дополнение к выходу памяти «m» в момент времени «t» в Softmax для предсказания тега.
Модель с длительной краткосрочной памятью обучается для предсказания основных тегов для каждого изображения. В качестве входа используются функции ГСНС ДР (полученные с помощью GoogLeNet). Затем выполняется обучение модели с длительной краткосрочной памятью (LSTM) на основе сочетаний этих функций ГСНС и меток для заранее обработанных изображений.
Копия памяти LSTM создается для каждого изображения LSTM и для каждой метки таким образом, что все LSTM используют одинаковые параметры. Вывод (m)×(t−1) LSTM в момент времени (t –1) подается в LSTM в момент времени (t). Все рекуррентные подключения преобразуются в упреждающие подключения в окончательной версии. Мы видели, что подача изображения в каждый этап времени в качестве добавочного ввода дает неудовлетворительные результаты, поскольку сеть воспринимает помехи на изображениях и производит чрезмерную подгонку. Потери снижаются по отношению ко всем параметрам LSTM, верхнему уровню сверточной нейросети встраивания изображений и встраиванию меток.
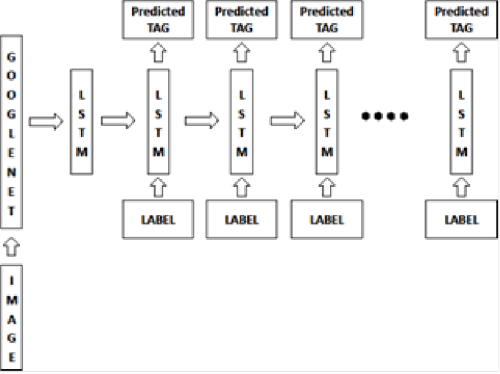
Архитектура ГСНС-РНС для предсказания тегов ДР
Результаты
Мы применяем описанную выше модель для предсказания тегов ДР. Точность предсказаний тегов в этой модели быстро повышается в первой части итераций и стабилизируется приблизительно после 20 000 итераций.
Каждое изображение в наборе данных ДР состоит только из уникальных типов одежды, нет изображений, на которых сочетаются разные типы одежды. Несмотря на это, при тестировании изображений с несколькими типами одежды наша обученная модель достаточно точно создает теги для этих не обработанных ранее тестовых изображений (точность составила около 80%).
Ниже показан пример выходных данных нашего предсказания: на тестовом изображении вы видите человека в костюме и человека в футболке.

Тестовое изображение, не анализированное ранее
На приведенном ниже рисунке показано предсказание тегов GoogLeNet с помощью модели GoogLeNet с обучением по ImageNet.
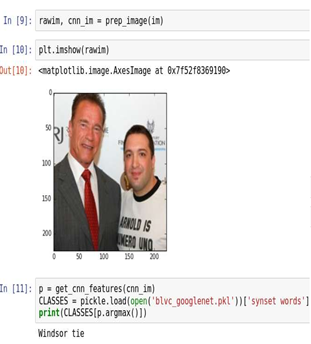
Предсказание тегов GoogLeNet для тестового изображения с помощью модели GoogLeNet с обучением по ImageNet
Как видно, предсказание по этой модели не очень точное, поскольку тестовое изображение получает тег «виндзорский галстук». На приведенном ниже рисунке показано предсказание тегов ДР с помощью описанной выше модели РНС-ГНСС с длительной краткосрочной памятью. Как видно, предсказание по этой модели весьма точное, поскольку наше тестовое изображение получает теги «сорочка, футболка, верхняя часть туловища, костюм».
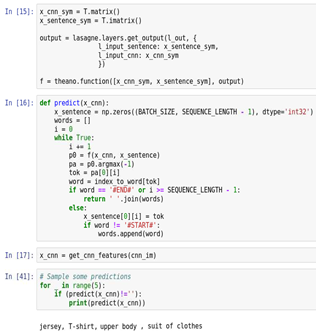
Предсказание тегов GoogLeNet для тестового изображения с помощью модели РНС-ГНСС с длительной краткосрочной памятью
Наша цель — разработка модели, способной предсказывать теги категорий одежды для изображений одежды с высокой точностью.
Заключение
В этой работе мы сравниваем точность предсказания тегов модели GoogLeNet и модели РНС-ГНСС с длительной краткосрочной памятью. Точность предсказания тегов второй модели значительно выше. Для её обучения использовали относительно небольшое количество обучающих итераций, порядка 10 000. Точность предсказаний второй модели быстро повышается с увеличением количества обучающих итераций и стабилизируется приблизительно после 20 000 итераций. Для этой работы мы использовали только один ГП.
Благодаря тонкой настройке можно применять усовершенствованные модели ГСНС в новых областях. Кроме того, объединенная модель ГСНС-РНС помогает расширять обученную модель для решения совершенно других задач, таких как формирование тегов для изображений одежды.
Надеюсь, эта серия публикаций поможет вам провести обучение ГСНС для изображений из определенных областей и многократно использовать уже обученные модели.
Если вы увидели неточность перевода, сообщите пожалуйста об этом в личные сообщения.
ссылка на оригинал статьи https://habrahabr.ru/post/316456/
Добавить комментарий