В этой заметке я расскажу о нашей демонстрационной базе данных для PostgreSQL: почему она важна для нас и как может пригодиться вам, как устроена схема и какие данные в ней содержатся.
Сразу приведу ссылку на полное описание (там же написано, где взять демо-базу и как ее установить): https://edu.postgrespro.ru/bookings.pdf.
Зачем?
С нашей точки зрения, необходимость в демонстрационной базе назрела давно. Чтобы обсудить практически любую возможность СУБД, нужны какие-то данные, нужна таблица или несколько таблиц. Изобретать этот велосипед каждый раз заново — впустую тратить и внимание слушателя, и свое собственное время. Недаром каждый производитель СУБД имеет базу, которую и использует каждый раз, когда нужно что-либо продемонстрировать.
Для чего может понадобиться такая база данных?
Во-первых, для самостоятельного изучения SQL. Допустим, вы студент, осваиваете SQL и прочитали, скажем, про рекурсивные запросы. Надо ведь на чем-то потренироваться?
С другой стороны, чтобы студент смог прочитать про рекурсивные запросы, нужно, чтобы кто-нибудь об этом написал. Наша компания сотрудничает с несколькими авторами и сейчас идет работа над университетским курсом по технологиям баз данных и учебным пособием по SQL — обе книги будут использовать демонстрационную базу. Можно будет не просто прочитать книгу, а тут же воспроизвести приведенные в ней примеры, «поиграться» с ними, выполнить практические задания.
Другой вариант — проведение практики по курсу баз данных в вузе (или даже чтение коммерческого курса по SQL: лицензия PostgreSQL, под которой выпущена демо-база, это разрешает). Примеры такого использования уже есть.
Демонстрационную базу полезно задействовать и для написания заметок в блог или статей про PostgreSQL и его возможности. Вместо того, чтобы каждый раз начинать со слов «создадим табличку и вставим какие-нибудь данные с помощью generate_series», можно сразу приступать к делу.
Мы думаем и над переработкой со временем документации PostgreSQL, чтобы и она максимально опиралась на схему и данные демо-базы.
Что нужно?
К демонстрационной базе данных мы выдвинули несколько требований:
- Схема данных должна быть достаточно простой, чтобы быть понятной без особых пояснений.
- В то же время схема данных должна быть достаточно сложной, чтобы позволять строить не самые тривиальные запросы.
- База данных должна быть наполнена данными, напоминающими реальные, с которыми будет интересно работать.
Разумеется, первым делом мы посмотрели, какие базы уже существуют, но ни одна из них нас не устроила. Ни в коем случае не хочу сказать, что они «плохие», но создавались для других задач: в каких-то слишком простая схема, какие-то слишком специализированы, в каких-то слишком примитивное наполнение.
Схема данных
Поэтому базу данных в итоге мы сделали свою собственную. Как вы, возможно, уже догадались по картинке, в качестве предметной области были выбраны авиаперевозки: речь идет о нашей дочерней авиакомпании (пока, увы, еще несуществующей). Схема данных приведена на рисунке:
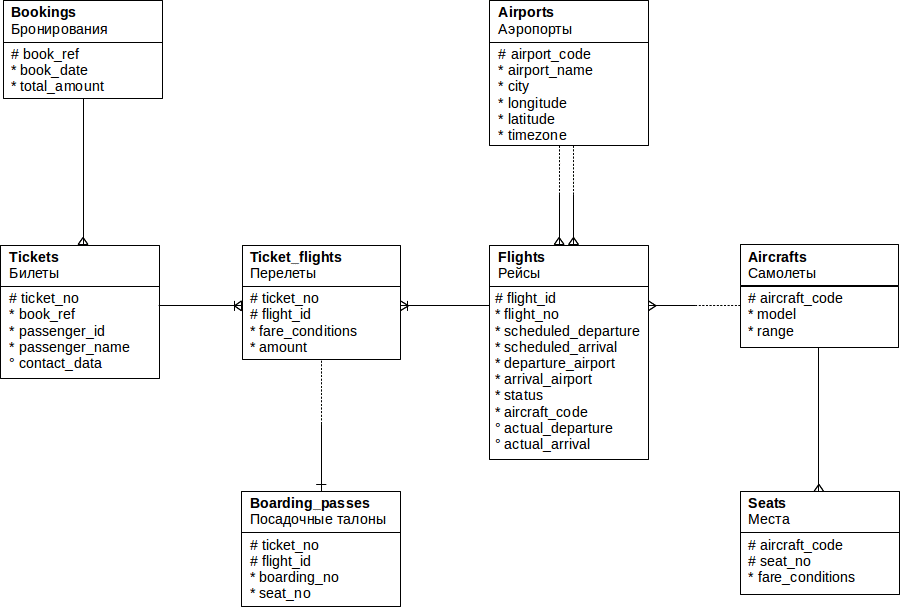
Основной сущностью здесь является бронирование (bookings).
В одно бронирование можно включить несколько пассажиров, каждому из которых выписывается отдельный билет (tickets). Как таковой пассажир не является отдельной сущностью: для простоты можно считать, что все пассажиры уникальны.
Билет включает один или несколько перелетов (ticket_flights). Несколько перелетов могут включаться в билет в нескольких случаях:
- Нет прямого рейса, соединяющего пункты отправления и назначения (полет с пересадками);
- Взят билет «туда и обратно».
В схеме данных нет жесткого ограничения, но предполагается, что все билеты в одном бронировании имеют одинаковый набор перелетов.
Каждый рейс (flights) следует из одного аэропорта (airports) в другой. Рейсы с одним номером имеют одинаковые пункты вылета и назначения, но будут отличаться датой отправления.
При регистрации на рейс пассажиру выдается посадочный талон (boarding_passes), в котором указано место в самолете. Пассажир может зарегистрироваться только на тот рейс, который есть у него в билете. Комбинация рейса и места в самолете должна быть уникальной, чтобы не допустить выдачу двух посадочных талонов на одно место.
Количество мест (seats) в самолете и их распределение по классам обслуживания зависит от модели самолета (aircrafts), выполняющего рейс. Предполагается, что каждая модель имеет только одну компоновку салона. Схема данных не контролирует, что места в посадочных талонах соответствуют имеющимся в самолете.
Все объекты схемы подробно описаны в документе, на который я уже ссылался в начале статьи. Там же приведен «путеводитель» по таблицам в виде простых запросов.
Что внутри?
Чтобы учиться писать запросы, нужно, чтобы база данных уже содержала какие-то данные, и не пару строк, а достаточно большой массив. Наша демонстрационная база доступна в трех вариантах, отличающихся объемом данных:
- Небольшая база содержит данные о полетах за один месяц; она не занимает много места на диске, но вполне позволяет писать запросы.
- Средняя база распространяется на три месяца.
- Большая база по полетам за год уже позволит непосредственно ощутить нюансы, связанные с производительностью.
Вообще, генерация тестовых данных — само по себе увлекательное занятие и дальше речь пойдет именно о ней. А что же тут интересного, ведь давно существуют инструменты (например, DataFiller), которые решают эту задачу? Да, существуют, но все зависит от того, какое качество информации вас устраивает.
Например, в билете есть имя и фамилия пассажира. Как можно сгенерировать данные для этого поля? Можно придумать несколько вариантов.
Самый простой — формировать строки заданной длины из случайных символов. Рей Бредбери мог позволить себе мистера Ааа, но готовы ли вы встретиться с QDEMFI TGBSWAJVZH (это, к слову, не выдуманный пример)?
Можно выбирать значения из заранее заготовленного списка имен и фамилий. Это будет больше похоже на правду, но есть еще и такая штука, как распределение данных. Если выбирать одно из имен равновероятно, то Александров в базе окажется примерно столько же, сколько и Полуэктов. Казалось бы, какая разница? А разница есть, и большая: если нужно получить всех Александров, в реальной базе данных вам придется отобрать порядка 10% всех строк, а Полуэктов может и вовсе не найтись. А это значит, что планы запросов в одном и в другом случаях должны отличаться — именно для этого СУБД собирают статистику по распределению данных в столбцах.
Более честный способ состоит в использовании частотных характеристик для каждого имени и для каждой фамилии. Именно так мы и поступили. (Можно было бы еще учесть национальные особенности и изменение популярности имен со временем, но тут важно вовремя остановиться.)
Вот другой пример. В нашей базе данных содержится порядка ста аэропортов. Прямые рейсы соединяют далеко не все аэропорты, но из любого можно добраться в любой другой с несколькими пересадками. Говоря иначе: граф связей должен быть неполным, но связным. Как его сгенерировать? И снова все зависит от того, какое качество данных нас устраивает.
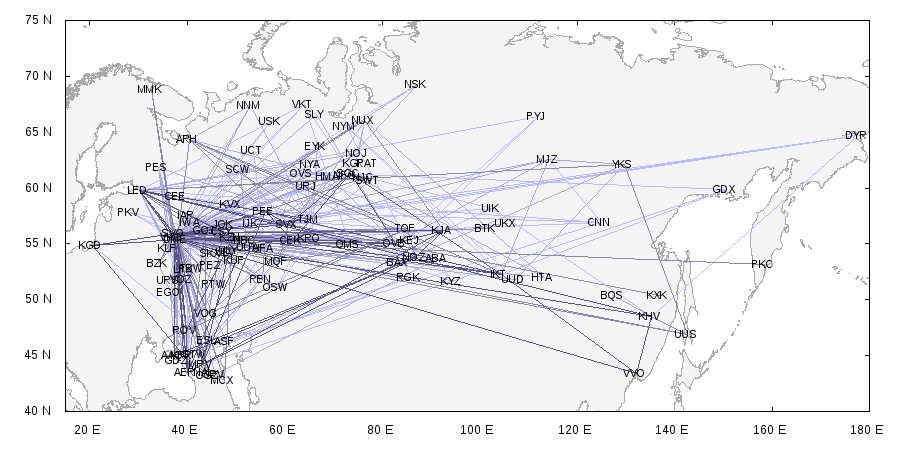
В простом случае можно связать первый произвольный аэропорт со вторым не менее произвольным аэропортом, затем связать второй со следующим и так далее несколько раз. Если каждый раз отдавать предпочтение еще не связанным аэропортам, то формально мы получим подходящий граф. Будет ли он похож на правду? Ни в малейшей степени. Вот что у нас может получиться (цвет линий зависит от пассажиропотока: чем темнее, тем более нагружен маршрут):

Если приглядеться, то видно, что все города связаны друг с другом довольно равномерной паутиной. А вот как выглядит реальный граф авиарейсов по России (по данным OpenFlights.org):
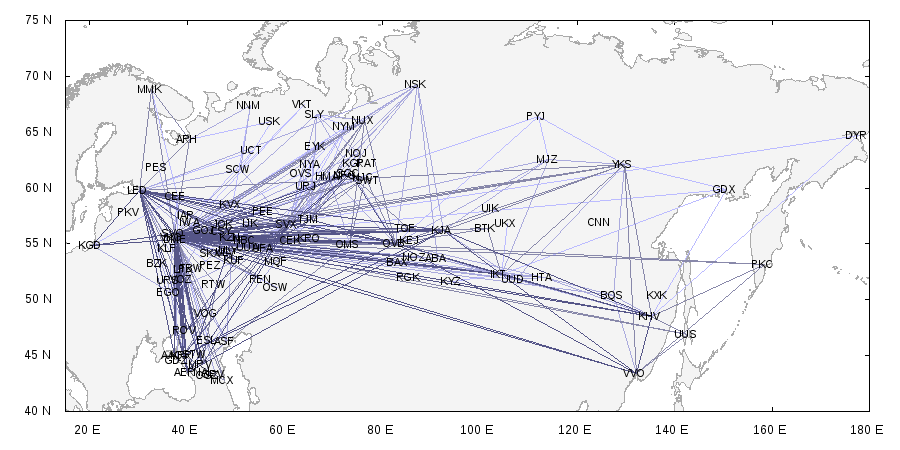
Характерная особенность здесь состоит в том, что основная масса связей сосредоточена в небольшом числе узлов. Такие графы называются безмасштабными; по ссылке можно найти и алгоритмы их генерации.
В нашем же случае нужно не просто сгенерировать граф, но и наложить его на реальные города (ведь понятно, что при любом раскладе самым большим хабом в России будет Москва). На самом деле это упрощает задачу, если выйти за рамки собственно демо-базы и посмотреть чуть шире: для описания каждого аэропорта мы используем не только координаты, но и еще несколько характеристик. Одна из них — объем пассажиропотока, а сгенерированный с ее помощью граф вы видели в самом начале статьи.
А почему бы просто не взять маршруты какой-нибудь существующей авиакомпании? Можно, конечно, и так, но потеряется гибкость: имея алгоритм, можно сгенерировать правдоподобный граф для любого числа городов, или для вымышленной страны, или вообще для межгалактических перелетов.
— Кстати, какое максимальное число пересадок необходимо, чтобы добраться из любого аэропорта в любой другой? (Конечно, ответом на этот вопрос должен быть запрос на SQL.)
Ну хорошо, вот мы сгенерировали граф маршрутов, но его еще надо превратить в расписание регулярных рейсов. Причем рейсов между пунктами А и Б должно быть достаточно, чтобы перевезти всех желающих, но и не слишком много, иначе самолеты будут летать пустыми. А еще надо принять во внимание тип воздушного судна. Можно взять самолет поменьше, а рейсов сделать побольше.
— Есть ли в демо-базе рейсы, превышающие максимальную дальность назначенного на них самолета?
А можно наоборот — рейсов поменьше, зато самолет побольше. Вот только не все аэропорты могут принимать тяжелые широкофюзеляжные суда; это тоже при желании можно проверить, хотя в саму демо-базу мы не выносили информацию о классах аэропортов.
Ну и так далее. Вот еще несколько вопросов, которые намекают на то, что генерация данных не столь тривиальна, как это могло бы показаться на первый взгляд:
— Как реальное время полета отличается от запланированного?
— Обычно полеты с запада на восток длинные (вылетаем ночью, прилетаем утром следующего дня), а с востока на запад — короткие (прилетаем в тот же день почти в то же время). А что происходит в демо-базе?
— Как распределено время бронирования и время регистрации по отношению к дате и времени рейса?
— Сколько человек обычно входит в одно бронирование?
— Бывают ли пассажиры, летящие туда-обратно? Всегда ли маршрут «туда» совпадает с маршрутом «обратно»?
— У всех ли пассажиров места в посадочных талонах соответствуют классу обслуживания, выбранному при бронировании?
— Может ли получиться, что пассажиру выдан билет на место, которого нет в салоне? Могут ли два пассажира претендовать на одно место?
— Всегда ли билеты на места одного класса обслуживания на одном рейсе стоят одинаково (и почему)?
Напоследок
Надеемся, что вам будет не менее интересно работать с этими данными, чем нам было интересно работать над ними. В дальнейшие (хоть и не ближайшие) планы входит развитие схемы, чтобы охватить более «продвинутые» области: полнотекстовый поиск, слабоструктурированную информацию, темпоральные данные, различные стратегии индексирования.
Если вы обнаружите какие-либо несоответствия демонстрационных данных со здравым смыслом (а такое вполне может случиться — ведь сложно предусмотреть все на свете), не постесняйтесь написать нам на edu@postgrespro.ru.
Нам также очень интересно услышать о реальном использовании схемы данных. Поделитесь вашим опытом, а мы, в свою очередь, открыты для общения и готовы делиться своим.
ссылка на оригинал статьи https://habrahabr.ru/post/316428/
Добавить комментарий